整取零存_字段级迁移工具
6月份的大部分时间在完成一个特殊的数据迁移工具,将文件中的标签整合到关系型数据库的表字段中。从近几年的技术趋势和参与的项目看,基本都是从关系型数据库往大数据组件迁移。在这个项目中,主要是客户和相关应用的供应商依赖于PostgreSQL的GIS插件。因此我也有幸使用了一次PostgreSQL数据库。本文简要讲解了工具开发的背景和难点,并给出了程序逻辑和源代码链接。
01 需求和背景
a). 为什么说这是一个字段级别的迁移?
作为数据源的标签文件数量非常多,根据标签的分类和加工的便利程度,有大量含有各位数据标签列的文件。而同时在PG库表中,为了减少join,提升数据库查询速度,大量标签字段又合在一张表中。结果就是存在,一个文件的不同列可能映射到不同的表中,一张表的不同字段来自于不同的文件。文件和表存在的是多对多的关系。这就造成不能简单地做出某个文件到某张表的映射关系,然后使用导入工具导入即可。
同时,对于客户和使用者而言,他们希望看到的是就是标签值(即对应数据库中的字段)。通过展示标签级别的映射关系,最终用户可以知晓每个标签的业务含义和数据来源;通过展示每个标签的加工状态,管理员可以快速获取整体标签的可用性。
最后,数据源结构上是半结构化的csv文件,列的数量和存放顺序可能发生改变。文件和表的将是动态的,维护起来的工作量也过于巨大。
b). 开发中依赖的一些业务说明
首先,对于标签类数据的存放表,认为是有业务主键的,这些主键也是其他应用查询数据时的条件。程序中使用这些主键来完成新标签数据的插入和旧标签数据的更新。
对于明细类数据,数据源的定义认为是没有主键的日志类数据,只有插入的操作无更新的操作。
同时,标签的更新方式还分为增量和全量。增量即常规的merge操作,而全量方式需要将表中的指定标签字段置空后再进行merge操作。
02 遇到的问题和解决方法
a). 文件的导入和并发控制
虽然每一个任务都是字段级别操作的,但是对于数据源文件的导入存在多个标签对应同一源文件的情况,所以在文件导入操作上有一个专门的状态表记录文件导入的状态。如果有其它标签任务在执行相同的文件导入了,状态就会变成processing。作为一个后来的任务,必须等待状态为success或者fail时才能进行文件的再次导入。
同时为了避免文件的再次导入,每次导入还会比较HDFS中文件的时间戳和状态表中的时间戳,如果时间戳一致,则直接使用已导入的文件即可。
b). 文件的动态入库
csv文件的首行列名作为字段名,文件名作为表明在临时库创建一张临时表,然后使用copy_expert函数避免双引号分界符内容中存在逗号的问题。
c). 明细和标签的整合
为了让两者使用同一套字段级别的merge方法,对于明细的数据在传到本地文件系统后,调用shell命令根据每一行的内容加行号md5 hash之后作为一行明细的主键。从而每一行数据都是唯一的,保证了数据在调用merge操作时只有insert行为。
d). 派生字段的处理
这里的派生字段是指,在原文件的列名中包含了一层数据,比如说同一个文件存在一列名「甲品牌_销售额」和「乙品牌_销售额」,而最终的标签需求为「销售额」,「品牌」。即一列将变成两列,同时数据行数将变成原有行数的(品牌枚举值个数)倍。
这个扩展的操作,是在源文件入临时库之后,通过遍历「品牌」枚举值,将其它列数据进行union all操作实现。
e). 字段类型转换
因为原始文件导入都是以文本形式入库,实际标签值可能有数字、布尔、地理坐标等类型,需要有一个专门的函数对标签值进行类型转换操作。
f). PostgreSQL中的merge操作
在PostgreSQL中,merge操作通过insert into on conflict () do update set = excluded.实现。
工具的处理逻辑
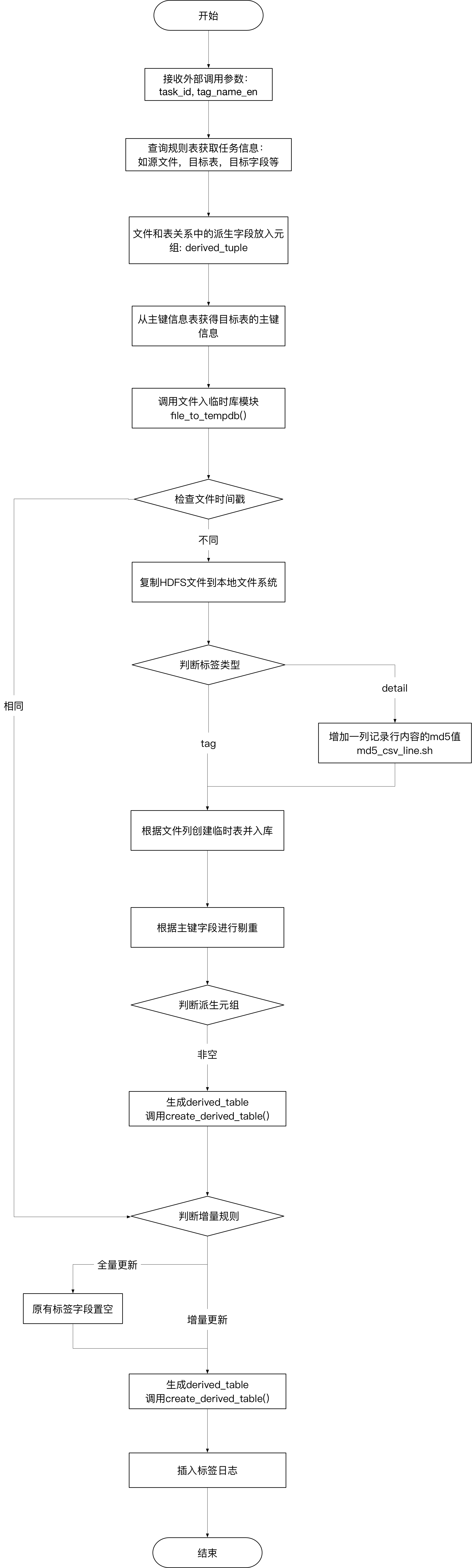
代码和遗留问题
代码github链接github
遗留问题:
- 对于主键的要求的强制的,但是程序没有主动去目标表中增加主键;
- 对于派生字段只能提供增加一个字段,不支持多个;
- 在几千条数据源情况下,单个标签导入的时间为2秒左右,未对千万级数据源做性能测试;
- 未提供多标签同时导入的接口
- 执行信息用了print()打印在屏幕,需要使用log模块优化输出和分类。
总结
本文分享近期开发的一个标签/字段级别数据迁移的工具,通过Python实现。介绍了工具的一些背景和实现的一些难点。同时分享了工具的核心代码,抛砖引玉,希望跟有兴趣的同学共同探讨更高效的实现方式。
欢迎扫描二维码关注公众号



 浙公网安备 33010602011771号
浙公网安备 33010602011771号