数据仓库知识点梳理(1)
近几年随着「大数据」、「数据驱动」、「数据中台」等概念在互联网界的热炒,懂数据的获取、处理到算法推荐、模型预测等人才也得到热捧。观感上,这些技能领域是随着大数据时代而来的。而实际上,早在上世纪80年到90年代初数据仓库和数据决策支持系统概念已经提出,本质上都是将多源头的数据集中起来,采用统计学的方法来进行数据分析以支持企业的各种决策。
既然换汤不换药,我们可以通过数据仓库知识来指导在大数据工程的实践。本文将对数据仓库的发展历史和背景进行介绍,作为「数据仓库知识梳理」系列的第一篇文章。
01 数据存储的发展历程
从狭义上讲,数据仓库也是一种数据的存储形式。从电子计算机出现以来,数据的数字化存储大致经历了下面的几个阶段。
- 1950s
打孔卡(Punch cards),首个存储数据的介质 - 1960s
磁性存储(磁带、磁盘) - 1970s
首个数据库管理软件(IMS), 层次型数据库
DBTG,网状数据库 - 1980s早期
关系数据模型,RDBMS的实现 - 1980s末-1990s
数据挖掘,数据仓库(W. H. Inmon)
95年数据仓库流行:IBM的dw方案,Oracle/SQL Server绑定OLAP服务 - 2000s
随着线上数据增长,成为BI解决方案的一部分
与大数据,NoSQL系统的结合
02 企业的决策层级
企业中部署数据仓库,其目的还是要用数据来说明现在的情况,并对下一步的动作计划提供支持。企业的决策可以分成三个层级,如下图所示。
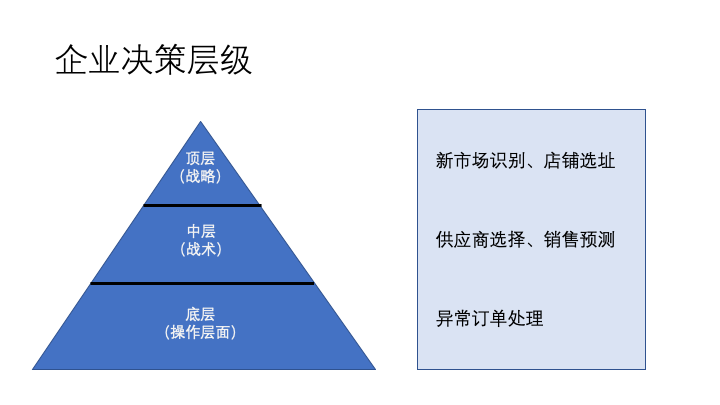
底层可能有操作员就可以执行,比如一个电商订单物流长期处于「发出」状态,可能是出现丢件异常,就需要联系物流进行处理。中层的销售预测,需要根据历史的销售记录为主对未来一段时间的销售进行预测,这一层级可能在特定部门内使用。顶层的新市场识别或者店铺选址等动作,需要考虑整个公司的数据甚至是外部的数据,如地理、人口、经济数据等结合起来而作出决策。
因此,在建立数据仓库或者数据中台的时候,不是说越复杂的系统就越好,关键是看需要支持怎么样的决策层级。其次还要考虑实施难度和建设周期等多个方面的因素。
03 数据库技术的限制
上一小节中的「异常订单处理」,如果单纯考虑超时提醒功能,可以直接在关系型数据库中实现。但是上层的决策,在关系型数据库上开发可能会遇到以下的3个问题。
1.性能限制:
1.不能同时保证事物处理和BI决策类型的统计查询;
2.集成度不够:
1.C/S,B/S架构,数据库独立服务特定应用,数据是分散的
2.还有外部数据源的数据
3.各系统间的名称、单位口径的统一
3.方法工具的缺失
1.统计查询的优化
2.数据建模的方法论
3.配套的统计查询和统计分析工具
基于以上原因,数据仓库与业务数据库有不同的底层设计。
04 数据仓库的定义
数据仓库是一个面向主题的、集成的、非易失的,随时间变化的用来支持管理人员决策的数据集合。
——《数据仓库(第4版)》
-
面向主题,是指对应企业中某一宏观分析领域所涉及的分析对象
-
例如:"销售分析"就是一个分析领域
-
这个"销售分析"所涉及到的分析对象为商品、供应商、顾客、仓库等,那么数仓主题可以确定为商品主题、供应商主题、顾客主题、仓库主题
-
数据层面来说,主题之间可能存在数据重叠关系
-
-
集成
- 数据来自于多个异构数据源
- 标准化的数据集成方法
-
非易失
- 与数据源的数据分离保存
- 一旦数据写入数据仓库,不进行更新
- 数据仓库的数据只支持数据的初次加载和访问
-
随时间变化
-
保留历史数据(数据的快照)
-
数据仓库的数据包含时间元素(记录时间戳)
-
数据追加方式通过不同时间上数据的变化实现
-
05 数据建模方式
既然数据仓库最基本的功能是存储数据,数据如何存储就是下一个问题了。数据建模方式即对数据的存储方式进行设计,目前的主流的方式为维度建模,相对而言业务数据库通常采用关心建模的方式。
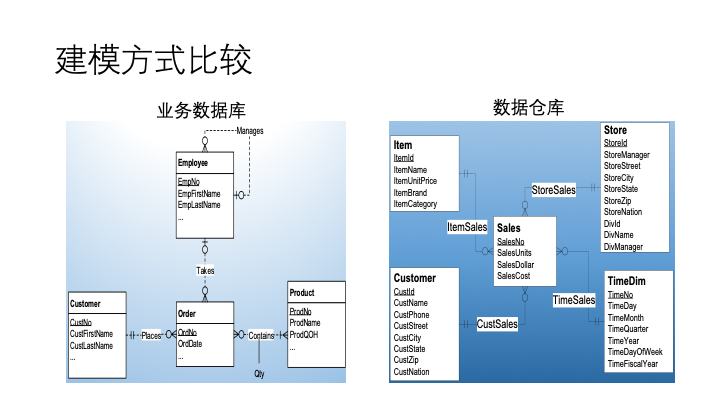
上图中,左边是业务数据库模型,订单、顾客、产品表等都对于与业务中的实体,方面业务系统的数据查询和新增,减少sql的查询。其通常符合「范式」建模要求。
右边是数仓的星型模型,以一个销售主题,通过一个fact表,对接其他维度表信息。其特点是数据冗余小,大量的属性都存放在维度表中,结构清晰,便于使用相关的工具做数据分析。这里先提一下,数据仓库查询语言的工业标准其实不是sql,而是mdx,后面会单独出一篇讲下mdx的工具和简单语法。

06 架构设计
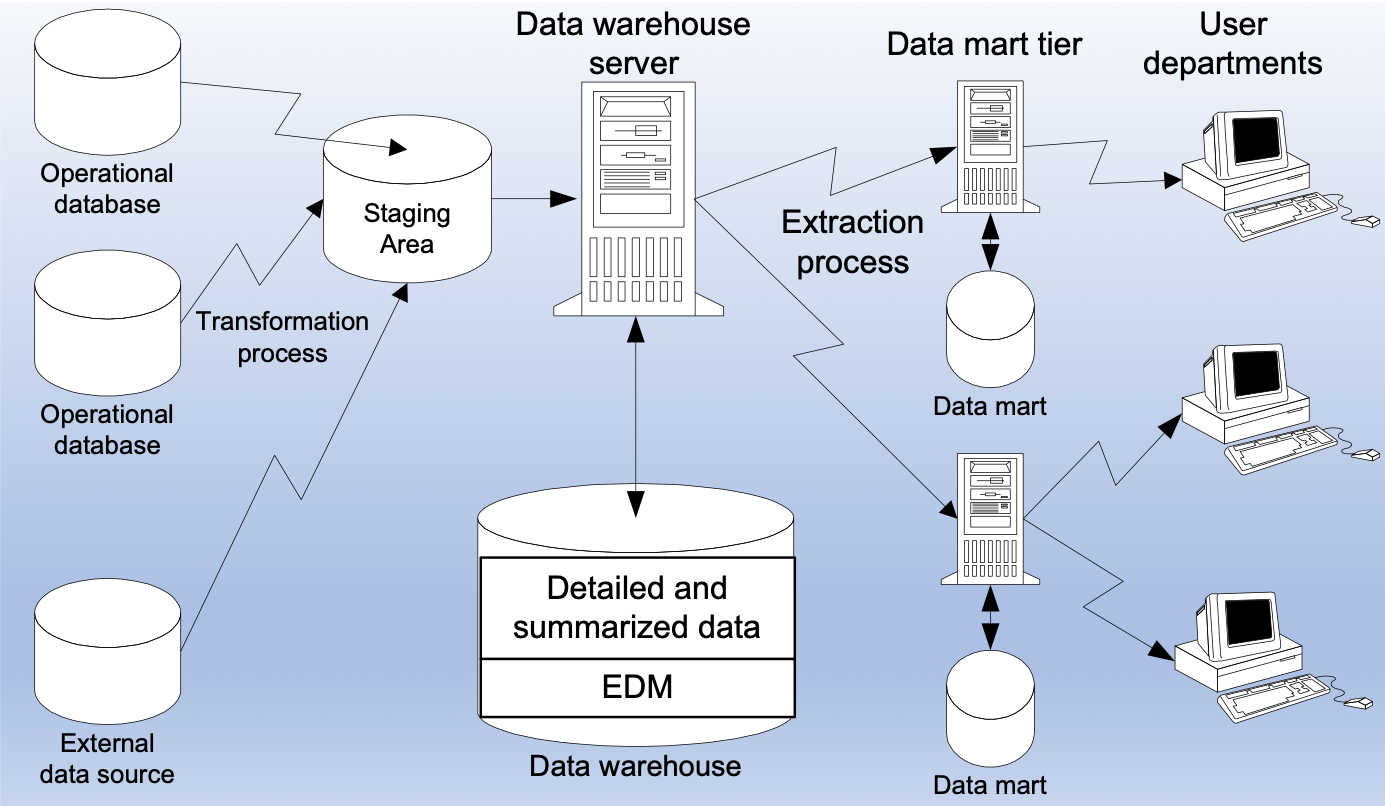
数据仓库架构设计有自顶向下构建和自底向上构建两种方式。
其中自顶向下构建方式需要从企业总体需求开始设计出整体的数据模型,然后将所有需要的数据汇集起来ETL到相应的模型对象之中,这是一种大一统的方式。最后再通过特定的权限设置,将数据的访问提供给企业下面的部门。
自底向上的方式,可以在子部门中获得特定主题的小型数据模型,建立服务于特定部门的数据仓库,它们也被称为数据集市。
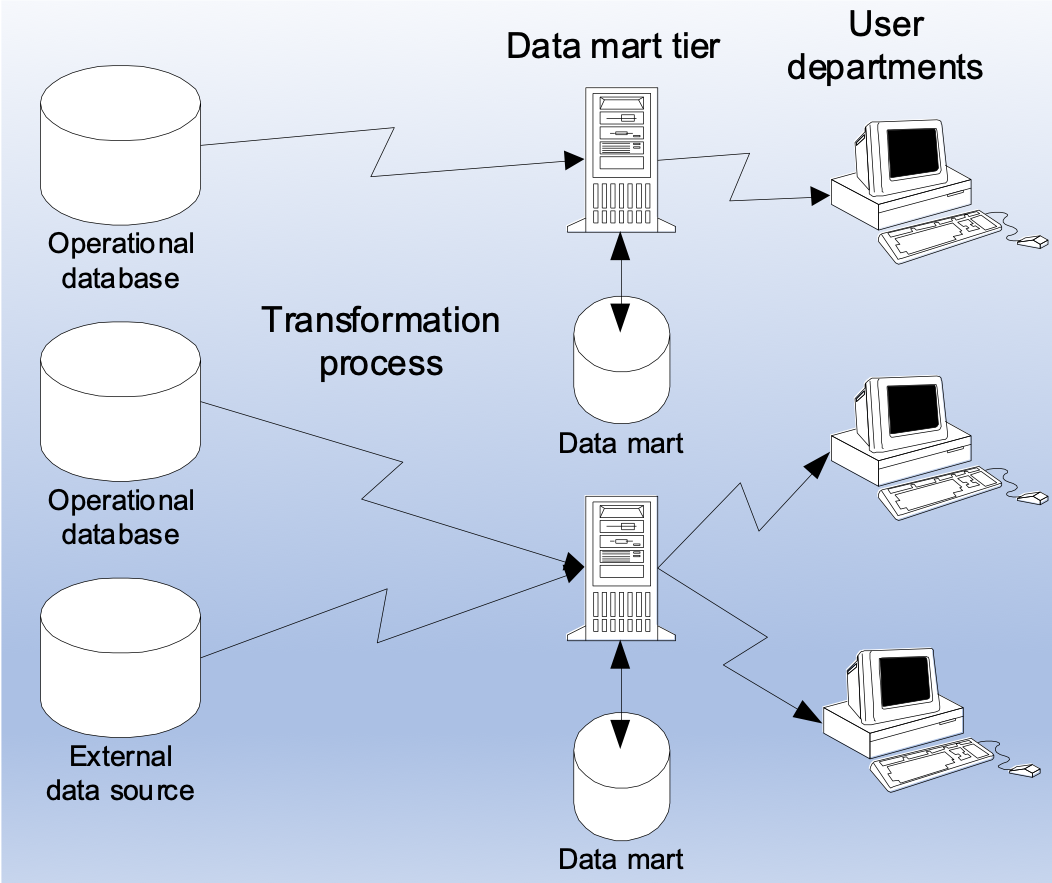
至于如何选择自己的架构,可以从以下两个方面进行考虑。
-
ROI
- 项目风险:自顶向下方式可能周期较长,部门间数据的流转必然成为制肘
- 商业价值:数据更集中更有可能发现其中蕴含的关系
-
IT部分角度
- 资金政策的来源:明确项目的出资方和收益方
- 数据信息的来源:明确谁能够提供出数据
07 总结
本文简要介绍了数据储存的发展历史,数据仓库产生的原因,数据仓库的定义、数据建模方式和数仓的架构设计。
欢迎扫描二维码关注公众号



 浙公网安备 33010602011771号
浙公网安备 33010602011771号