1,MapReduce基础
MapReduce基础
目录
一、关于MapReduce
1.1 为什么要MapReduce
- 单机资源有限:由于单台计算机的资源有限,计算能力不足以处理海量数据;所以需要多台计算机组成分布式集群来处理海量数据。
- 分布式计算较复杂:在分布式计算中,计算任务的分发,各个主机之间的协作;程序的启动以及运行过程中的监控、容错、重试等都会变得很复杂。所以引入了MapReduce框架,框架解决了分布式开发中的复杂性,开发人员只需要将大部分工作集中在业务逻辑的开发上,从而极大的提高了工作效率。
1.2 MapReduce的定义
- MapReduce是一个分布式运算程序的编程框架,用于大规模数据集(大于1TB)的并行计算;Map(映射)和reduce(归约)是它的主要思想;它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
二、MapReduce的优缺点
2.1 优点:
- 易于编程:只需要实现一些接口,就可以完成一个分布式程序的编写;跟编写一个串行程序一样;
- 良好的扩展性:当计算资源不足时,只需要简单的增加机器来扩展它的计算能力;
- 高容错性:当一个机器挂了之后,会自动把上面的计算任务转移到另一个节点上运行,无需人工干预;
- 海量:适合PB级海量数据的离线处理。
2.2 缺点:
- 不适合实时计算:MapReduce由于过程较为复杂,IO次数较多,所以无法做到毫秒或秒级响应;
- 不适合流式计算:流式计算的输入是动态的,可以不断添加,而MapReduce的输入是静态的;
- 不适合DAG(有向图)计算:对于多个程序之间有依赖关系,即后一个程序的输入是前一个程序的输出;虽然MapReduce也可以完成,但都是通过磁盘来传递中间数据,造成大量的磁盘IO,性能极低。
三、MapReduce的执行阶段
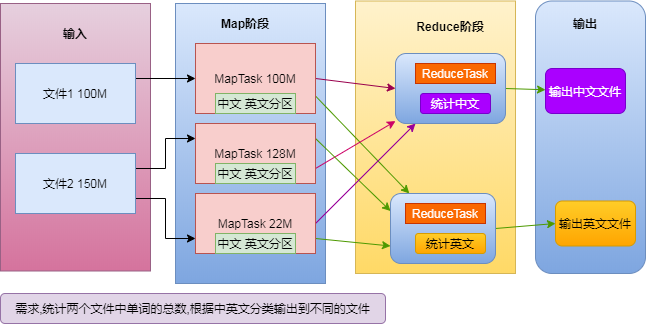
3.1 执行的两个阶段
-
Map阶段:若干个maptask并发实例,完全并行运行,互不相干。
-
Reduce阶段:若干个reducetask并发实例,完全并行运行,但是他们的数据依赖于Map阶段的输出。
-
注意:MapReduce模型只能包含一个map阶段和一个reduce阶段;如果业务逻辑非常复杂,就只能使用多个MapReduce程序,串行运行。
四、编写MapReduce程序
-
用户需要编写的三个部分:Mapper、Reducer、Driver(提交MR程序)。
4.1 以WordCount为例:
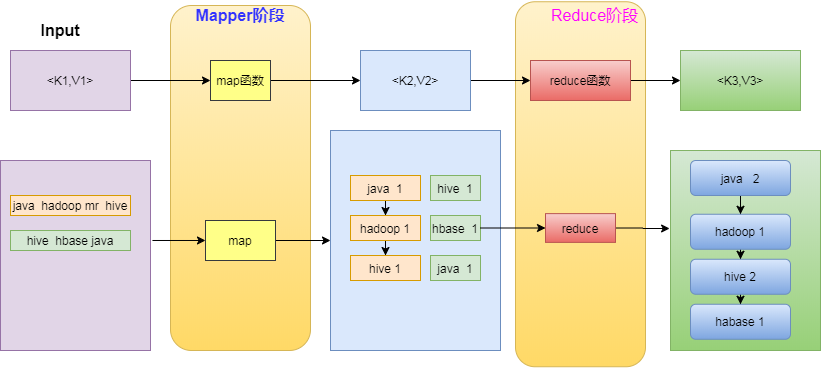
1. 编写Mapper
// 注意:hadoop1.0版本中是mapred下包,hadoop2.0是mapreduce下的包
import org.apache.hadoop.mapreduce.Mapper;
// 继承Mapper父类,泛型为输入和输出的<K, V>;并重写父类的map方法
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
/**
* 每行文本都会执行一次map方法.
*
* @param key 文本偏移量.
* @param value 一行文本.
* @param context 上下文对象.
* @throws IOException .
* @throws InterruptedException 当阻塞方法收到中断请求时抛出.
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split("\\s+"); // 拆分一行中的单词
for (String word : words) {
context.write(new Text(word), new IntWritable(1)); // 输出一个<K, V>
}
}
}
2. 编写Reducer
// 继承Reducer类,输入的<K, V>类型为map端输出<K, V>类型
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
/**
* 相同的key只会执行一次reduce方法
*
* @param key map端输出的key
* @param values 相同key的value集合
* @param context 上下文对象
* @throws IOException .
* @throws InterruptedException .
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 当前的 key出现了多少次
int count = 0;
// values中的数据是反序列化过来的,最好不要直接使用values中的bean
for (IntWritable value : values) {
count += value.get();
}
context.write(key, new IntWritable(count)); // 输出
}
}
3. 编写Driver
// Driver的作用是将这个Mapper和Reducer程序打包成一个Job,并提交该Job
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 不需要为 conf设置HDFS等参数,因为conf会调用系统默认的配置文件,
// 所以这个mr程序在哪里运行就会调用哪里的配置文件,在集群上运行就会使用集群的设置文件。
Configuration conf = new Configuration();
// 删除输出文件,或者手动删除
// FileHelper.deleteDir(args[1], conf);
// 根据配置文件实例化一个 Job,并取个名字
Job job = Job.getInstance(conf, "MyWordCount");
// 设置 Jar的位置
job.setJarByClass(WordCountDriver.class);
// 设置 Mapper运行类,以及输出的key和value的类型
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置 Reducer的运行类,以及输出的key和value的类型
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置分区(可以不用设置)
// 当设置的分区数大于实际分区数时,可以正常执行,多出的分区为空文件;
// 当设置的分区数小于实际分区数时,会报错。
job.setNumReduceTasks(4);
// 如果设置的 numReduceTasks大于 1,而又没有设置自定义的 PartitionerClass
// 则会调用系统默认的 HashPartitioner实现类来计算分区。
job.setPartitionerClass(WordCountPartitioner.class);
// 设置combine
job.setCombinerClass(WordCountCombiner.class);
// 设置输入和输出文件的位置
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 提交任务,等待执行结果,参数为 true表示打印信息
boolean result = job.waitForCompletion(true);
// 根据 job的返回值自定义退出
System.exit(result?0:1);
}
}
4. 运行
- 如果在Hadoop集群上运行还需要将这个project打包成jar包,所以一般是先在windows上运行调试。
- 由于要从命令行输入input和output参数,所以这里配置一下输入和输出的位置。
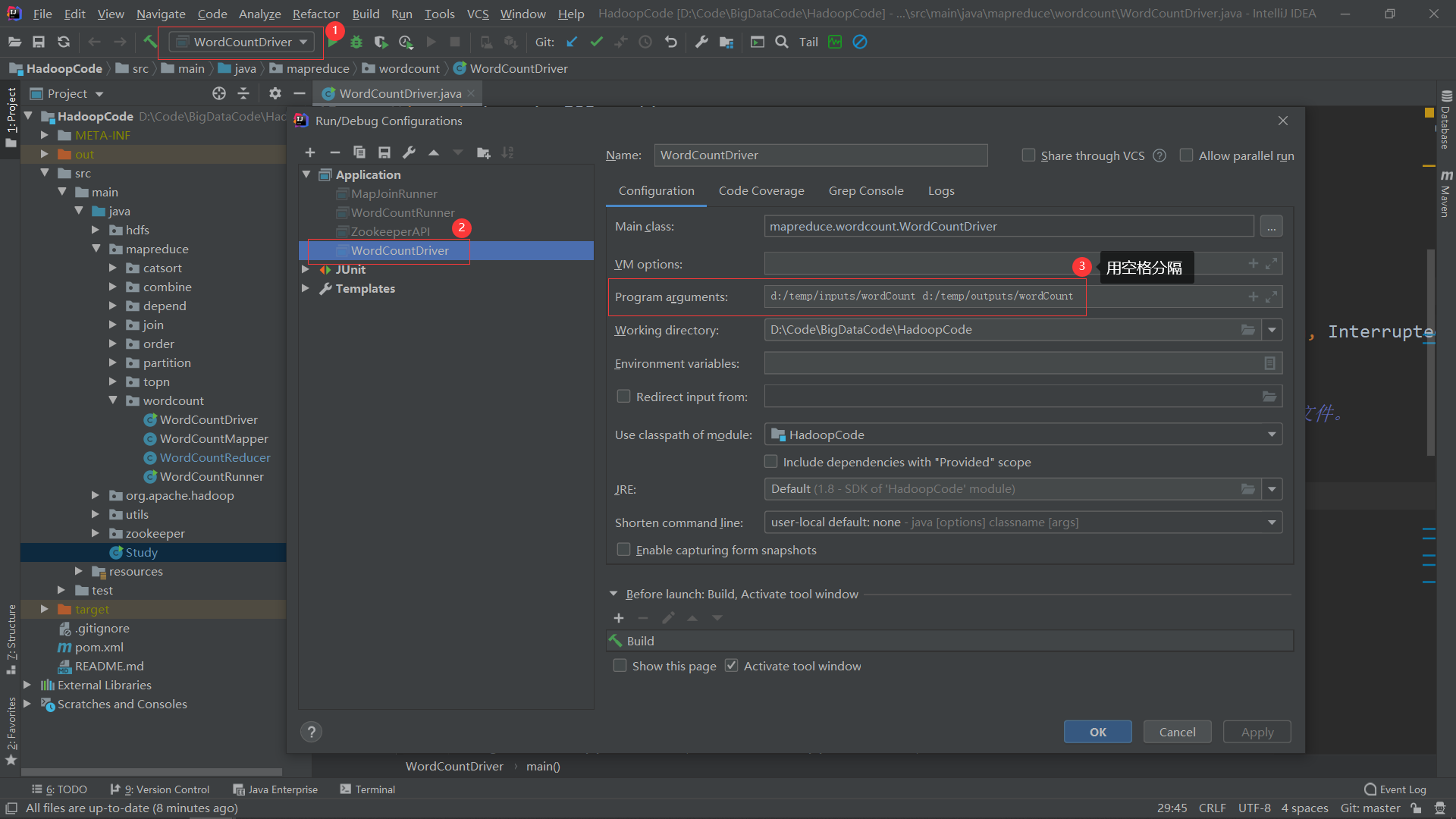
五、MapReduce的主要执行流程
- job.waitForCompletion(true):将这个MapReduce任务(Job)提交,默认是提交到本地运行;部署到集群时,是提交给YARN运行。
- map():在父类Mapper的run()方法中会调用子类重写的map()方法。输入文件的每一行都会调用一次map()方法,map()方法的参数中:key为当前输入行的偏移量,LongWritable类型;value为当前输入行的数据,Text类型;context为上下文对象。父类Mapper是一个泛型类,泛型的类型表示map()方法输入和输出的<K, V>类型,子类在继承时要传入实际输入输出的<K, V>类型。map()使用context.write(k, v)来输出数据到shuffle阶段的环形缓冲区。
- shuffle阶段简述:shuffle阶段起到承上启下的作用;从接收map()方法的输出,到执行reduce()方法之前都属于shuffle阶段。shuffle接收map()输出<K,V>并通过K计算出分区号,然后与元数据一起写入环形缓存区;环形缓冲区溢写时会将数据排序并写入小文件,然后归并成一个大的分区文件。一个ReducerTask主机会到所有MapTask主机上拉取对应的分区文件,归并所有分区文件后会对相同的key进行合并,再执行reduce方法。
- reduce():在父类Reducer的run()方法中会调用子类重写的reduce()方法。相同的key只会调用一次reduce()方法,reduce()方法的参数中:key为相同key合并后的第一个key,与map()的输出key类型相同;values为相同key的value列表,类型是Iterable<map()的输出value类型>。与Mapper类类似,子类在继承Reducer时输入的<K, V>类型是Mapper输出的<K, V>类型、Reducer输出的<K, V>类型是context.write(K, V)中<K, V>的类型。reduce中的context.write(K, V)最终会写入到输出文件中,就是这次MapReduce的结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号