Transformer
Reference:
https://builtin.com/artificial-intelligence/transformer-neural-network
1. Introduction
A paper called “Attention Is All You Need,” published in 2017, introduced an encoder-decoder architecture based on attention layers, which the authors called the transformer.
Advantages over RNN
- Overcomes the vanishing gradient issue by multi-headed attention layer;
- Input sequence can be passed and processed parallelly so that GPU can be used effectively.
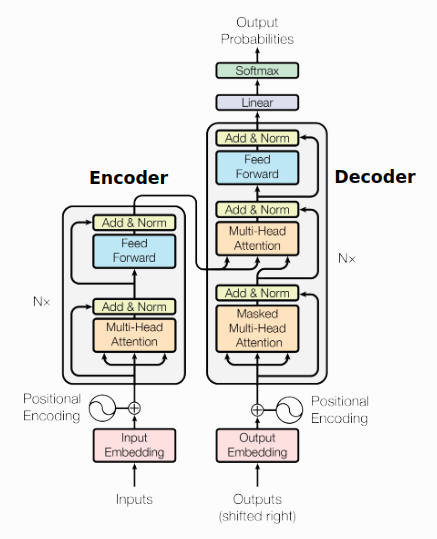
2. Encoder Block
MULTI-HEAD ATTENTION PART
This focuses on how relevant a particular word is with respect to other words in the sentence. It is represented as an attention vector.
For every word, it weighs its value much higher on itself in the sentence, but we want to know its interaction with other words of that sentence. So, we determine multiple attention vectors per word and take a weighted average to compute the final attention vector of every word.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号