

Unicode
Difference between UTF-8, UTF-16 and UTF-32 Character Encoding? Example
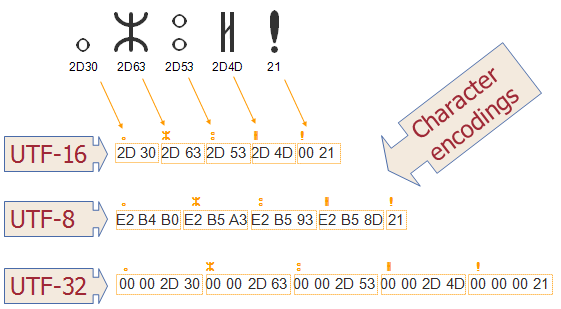
The main difference between UTF-8, UTF-16, and UTF-32 character encoding is how many bytes it requires to represent a character in memory. UTF-8 uses a minimum of one byte, while UTF-16 uses a minimum of 2 bytes. BTW, if the character's code point is greater than 127, the maximum value of byte then UTF-8 may take 2, 3 o 4 bytes but UTF-16 will only take either two or four bytes. On the other hand, UTF-32 is a fixed-width encoding scheme and always uses 4 bytes to encode a Unicode code point. Now, let's start with what is character encoding and why it's important? Well, character encoding is an important concept in the process of converting byte streams into characters, which can be displayed.
There are two things, which are important to convert bytes to characters, a character set and an encoding. Since there are so many characters and symbols in the world, a character set is required to support all those characters. A character set is nothing but list of characters, where each symbol or character is mapped to a numeric value, also known as code points.
On the other hand UTF-16, UTF-32 and UTF-8 are encoding schemes, which describe how these values (code points) are mapped to bytes (using different bit values as a basis; e.g. 16-bit for UTF-16, 32 bits for UTF-32 and 8-bit for UTF-8). UTF stands for Unicode Transformation, which defines an algorithm to map every Unicode code point to a unique byte sequence.
For example, for character A, which is Latin Capital A, Unicode code point is U+0041, UTF-8 encoded bytes are 41, UTF-16 encoding is 0041, and Java char literal is '\u0041'. In short, you just need a character encoding scheme to interpret a stream of bytes, in the absence of character encoding, you cannot show them correctly. Java programming language has extensive support for different charset and character encoding, by default it uses UTF-8.
Check unicode in python2
"""
In Python 2, there are two different types of strings: regular strings (also known as "byte strings") and Unicode strings. The ord() and unichr() functions work with Unicode strings, which are represented in Python 2 using the u'...' syntax.
Example:
char unicode decimal
'印' 0x5370 21360
"""
# str -> unicode
u'印印'.encode('unicode_escape')
# char -> unicode
ord(u'印')
# unicode(hex) -> str
unichr(0x5370)
# unicode(decimal) -> str
unichr(21360)
Check unicode in python3
"""
In python3, the str type is Unicode by default.
Example:
char unicode decimal
'印' 0x5370 21360
"""
# str -> unicode
'印印'.encode('unicode_escape')
# char -> unicode
ord('印')
# unicode(hex) -> str
chr(0x5370)
# unicode(decimal) -> str
chr(21360)
Read binary file with VIM
vim -b ***.bin
:%!xxd

 浙公网安备 33010602011771号
浙公网安备 33010602011771号