

2 scrapy框架
1、概要
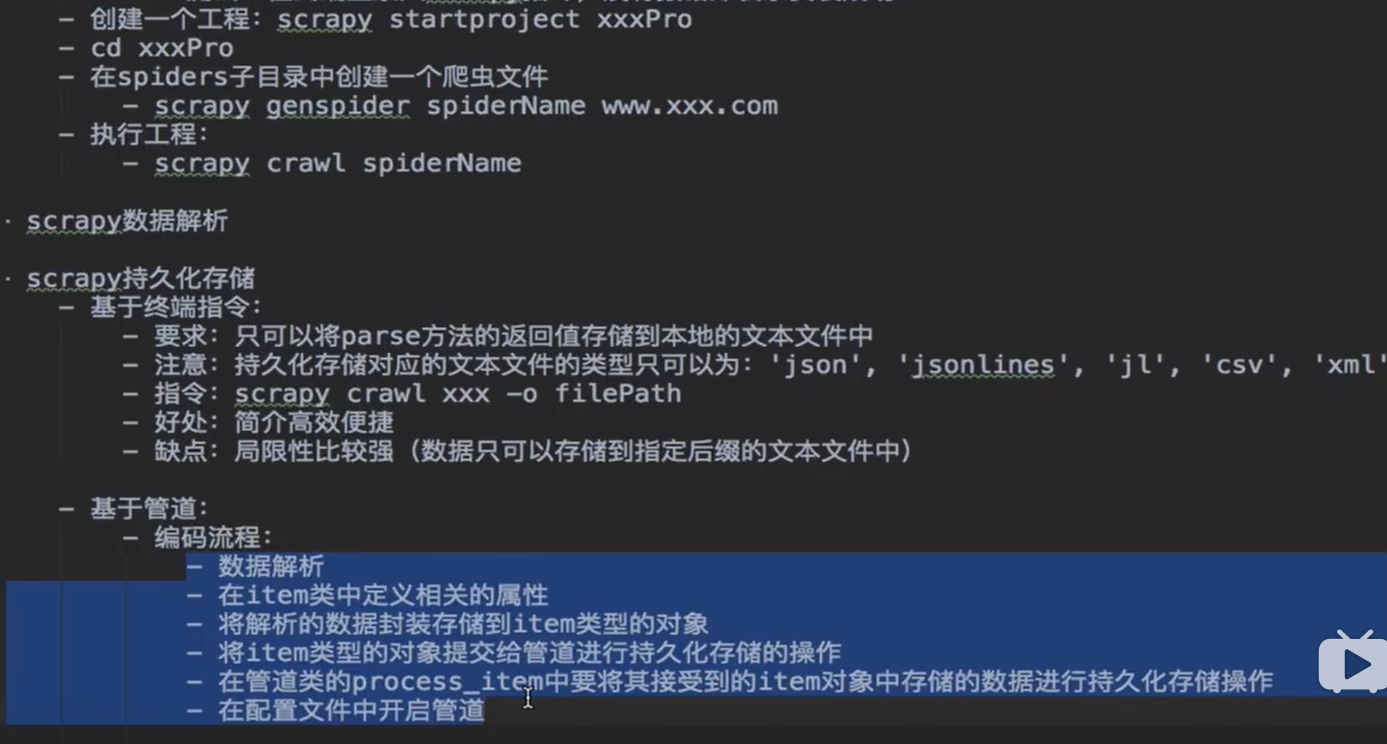
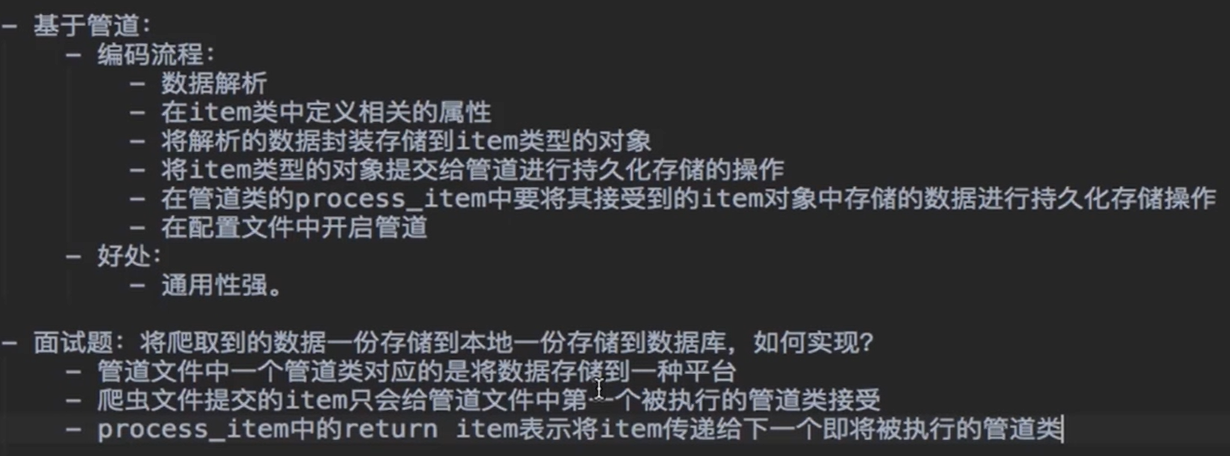
2、步骤
1、
##################### settings文件:#############################
# 头伪装
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# 只显示print和错误信息
LOG_LEVEL = 'ERROR'
##################### 主文件:#################################
# 注释掉allowed_domains
3.基于观管道的持久化存储
############## 1.items.py #############
class FirstBloodItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
url = scrapy.Field()
############## 2.pipelines.py ##########
class FirstBloodPipeline:
# 专门用来接收和处理item类型对象
def process_item(self, item, spider):
return item
############## 3.主文件.py ###########
from first_blood.items import FirstBloodItem
############## 4.settings.py(行) ###########
ITEM_PIPELINES = {
'first_blood.pipelines.FirstBloodPipeline': 300,
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号