GearDVFS@Mobicom '23
1.1 introduction
- 传统的DVFS的解决方案现在变成了次优解,因为没考虑到工作负载的特性。zTT提到了。
- 最近的面向应用的(application-oriented)的研究,通过给定应用的工作负载的上下文来学习和预测合适处理器频率。很难广泛应用开来。
- 现在手机的多任务情况越来越多,面向单任务的DVFS很难适应。
1.2 inefficiency of current DVFS designs
-
面向应用的DVFS方法,作者设计了实验对比zTT技术,在单任务,双任务以及三任务的负载情况。zTT在多任务的时候很难适应多个QoE指标。
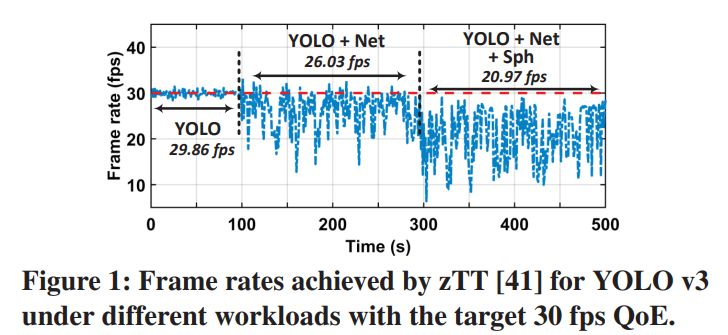
-
与应用无关的DVFS方法,这类方法的目标就是通过调频始终保持芯片利用率趋于一个固定的80%。
1.3 insight
这里作者进行了两个实验来表达它的发现。
-
应该联合调整CPU和GPU频率。
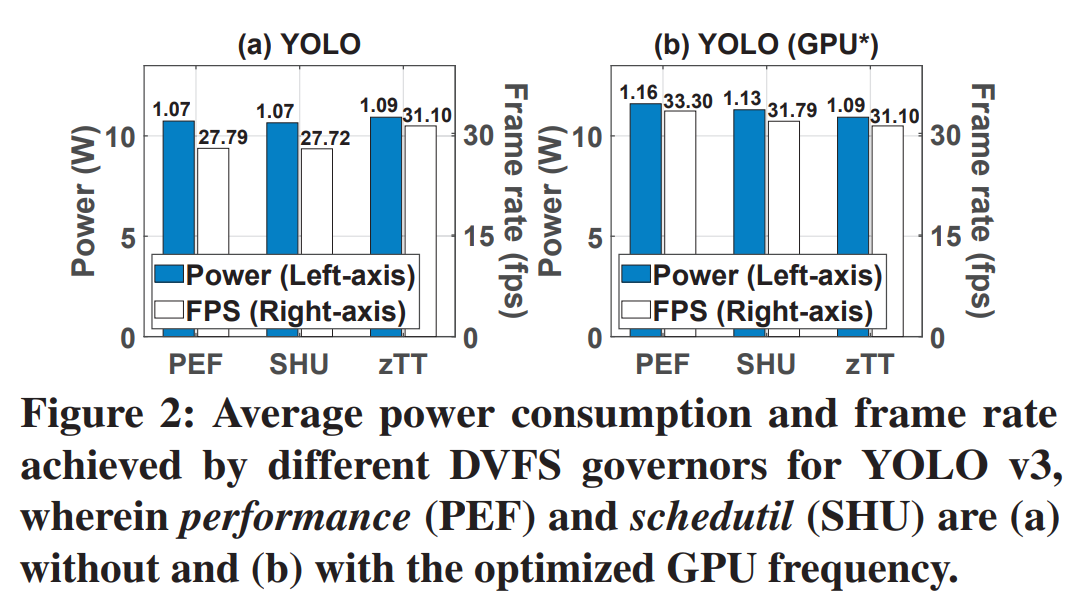
在推理YOLO的时候,PEF和SHU将CPU调整到了最高频率,但是它们无法调整GPU频率(YOLO推理需要进行更多的GPU运算)。所以在Fig 2(a)中,三个方法的功耗近似,而帧率相差很多。当手动将GPU频率固定为合适的频率是,此时PEF和SHU的帧率提高和zTT近似。这表明工作负载对CPU和GPU的计算需求可能不一样,所以调频策略应该同时考虑到CPU和GPU。 -
调频要考虑工作负载的特性。CPU的利用率实际上指的是一段时间内,CPU处于busy状态的占比,但是实际上由于工作负载的特点,CPU在busy时会处于两个状态
active computing和stalled waitting。作者设计两个工作负载,一个是IO密集的负载(STA)、一个时计算IO平衡的负载(BAL)。
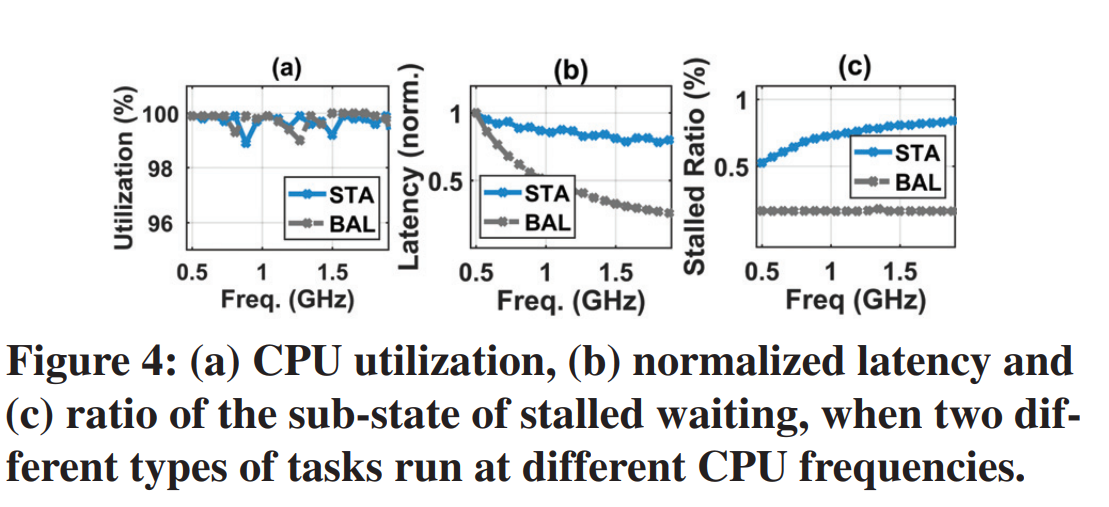
从CPU利用率上,二者区别不大。但是在看计算延迟,发现随着频率变高,BAL的延迟越来越低,而STA的变化较小。对于stalled ratio来看,发现STA会随着频率变大而变大,BAL基本保持不变。这是因为频繁的IO会导致CPU的大量的时钟周期在等待数据传输。所以应该要好好考虑工作负载的特点。
1.4 problem formulation
根据上面的实验和介绍,在时间窗口内\(T_{win}\)处理器利用率\(u=\frac{T_{busy}}{T_{win}}\),而\(T_{win}\)可继续细分为\(T_{act}\)(active computing)和\(T_{sta}\)(stalled waitting)。当\(T_{win}=1\)时:
这里的计算负载\(W_{act}\)和\(T_{act}\)成正比,\({\beta}\)和处理器相关。那么终极目标(调频使利用率保持\(u^g\))就可以化简为
由此,作者认为工作负载的特点可以用一个元组来表达
作者这里表明观点:整个负载感知的目的就是去实时预测出 \(<a, b>\)来找到最适合的频率\(f\)。
1.5 GearDVFS的设计
1.5.1 设计目标
- 目标调整频率处理器i在t时刻的\(f_i(t)\)使得\(u_i(t)\)保持在目标位置\(u^g_i\)
- 限制\(f_i(t)\)的可调频率
- 限制处理器温度\(c_i(t)\)以防过热。
1.5.2 解决方案-RL
作者将这个问题转换为强化学习的问题。强化学习的主要组成是: states,actions,rewards和transitional probabilities。
在DVFS问题中,states和actions分别表达了工作负载特性和频率调整。transitional probabilities,\(p(s'|s,a)\)表示动作\(a\)可以让当前状态\(s\)转换为\(s'\)的可能性。rewards是一个函数,用来量化这次转换的好与坏。
1.5.3 states设计
作者设计了一个meta-states用来表达工作负载的状态。设计的目的是因为,一些硬件相关的参数无法直接获取例如前面的\(\beta\)。另外需要去预测出一个整个处理器工作负载的上下文。
所以作者基于历史的源数据和一些可观测数据来重新表达和预测复杂的工作负载特性。他这里用一个encoder-decoder的框架来学习meta-states。
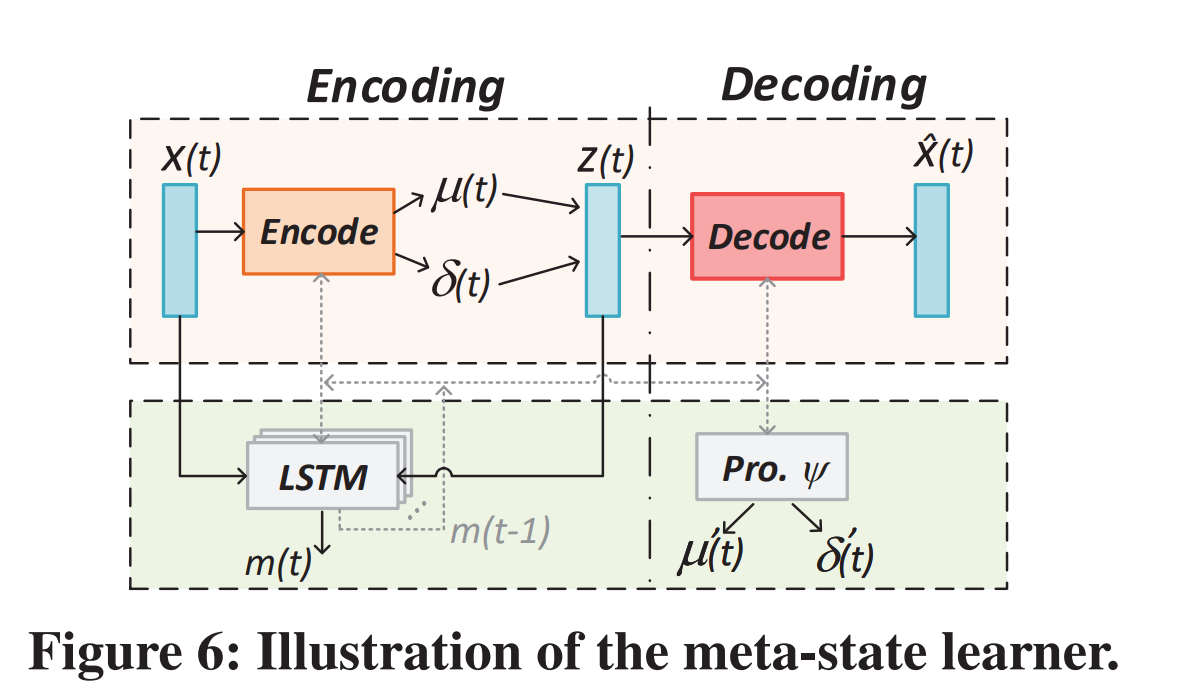
输入的\(x(t)\)包括两类数据:
(1) 利用率数据,CPU的利用率\(u_{i}^{act}(t)\)和\(u_{i}^{sta}(t)\),GPU的利用率\(u_i(t)\)
(2) 硬件的数据,每个处理器的频率\(f_i(t)\)和每个处理器的温度\(c_i(t)\)
如Fig6所示,中间表达\(z(t)\)由encode学习得到,然后为了能让\(z(t)\)和\(x(t)\)等价,再次通过decode重新生成\(\hat{x}(t)\)。
中间LSTM模块就是用来学习历史上下文的。LSTM的输入是\(x(t)\),\(m(t-1)\)和\(z(t)\),输出是\(m(t)\),这个\(m(t)\)就是这个meta-state
1.5.4 actions
DVFS中可以调整的动作主要是处理器和处理器的频率,如果简单的去应用,动作空间是非常大的。总共的动作空间是每个处理器可调频率的乘积\(\prod_{i=1}^{M}{n_i^f}\)。
为了应对这个问题,作者重新设计了一个Q-Network网络。将奖励函数进行了分离,分别奖励每个处理器自己的Actions。这样的输出维度的复杂度就是每个处理器可调频率的求和\(\sum_{i=1}^{M}{n_i^f}\)。如图7,设置多分支网络。
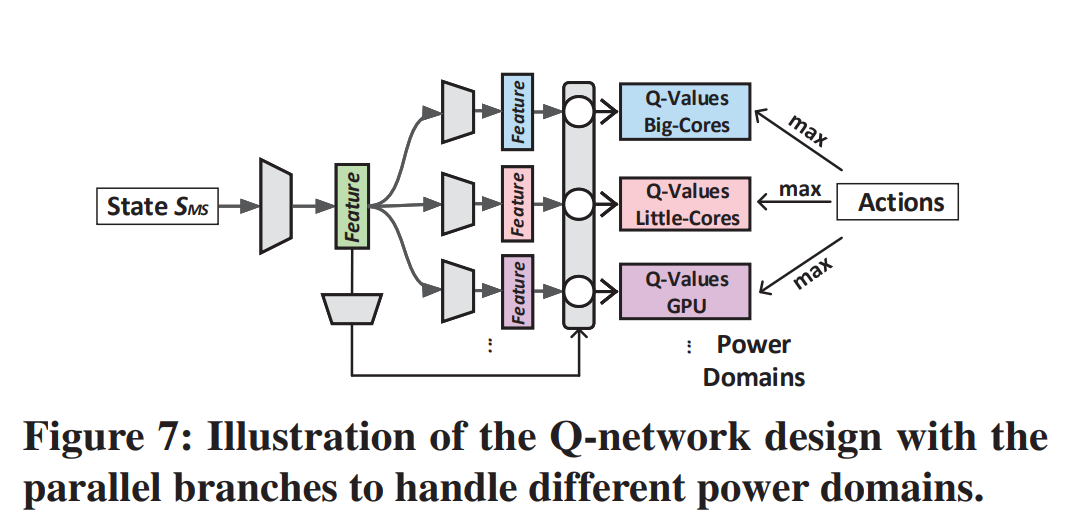
1.5.5 rewards
DVFS的终极目标是实现利用率保持在\(u^g\),因此,作者的给处理器i的奖励函数\(D_i(t)\),表示如下:
第一种情况表达当前的利用率已经过低或者过高,无法达到预期的利用率\(u_i^g\)。作者这里将\(\lambda=0.1\)。
第二种情况就是,在利用率在\([u_i^{min},u_i^{max}]\)之间时,首先计算了\(u_i^g和u_i(t)\)的距离,\(u,v,w\)时设置的超参数。当前距离很小的时候,保证将奖励值趋近于1,当前距离很大的时候奖励值趋近于-1。
这里作者考虑了zTT里面的温度奖励机制\(W_i(t)\)。最终的奖励函数是\(R(t)=\frac{1}{M}\sum_{i=1}^{M}{(D_i(t)+W_i(t))}\)。
1.5.6 updates
在定义为上述的states, actions, rewards的设计后,GearDVFS的可以自己选择最好的更新动作了。但是作者提供了可以在线微调的方案(基于真实的历史数据)。
1.6 实验评估
1.6.1 PPW评估
文章主要测试了一下几种DVFS性能:
- Default (Deft), schedutil for CPU and simple_ondemand for GPU
- Q-Learning (Qlng), Q-Learning method control the frequency of CPU only and without workload context, simple_ondemand for GPU .
- zTT, the state-of-the-art application-oriented DVFS method.
- GearDVFS (Gear), the method proposed in this paper.
实验的评估目标是什么呢?
- DVFS技术的能效提升。就是在实现相同QoE性能的前提下,功耗更低。
- DVFS的达到目标的能力。能不能让处理器利用率保持在\(u_g\)(设定80%)。
坐标轴解释
- PPW, Performance per watt, QoE和Power的比值,PPW越高表示DVFS的性能越好。
- 加号表示多个任务并行执行
实验分析
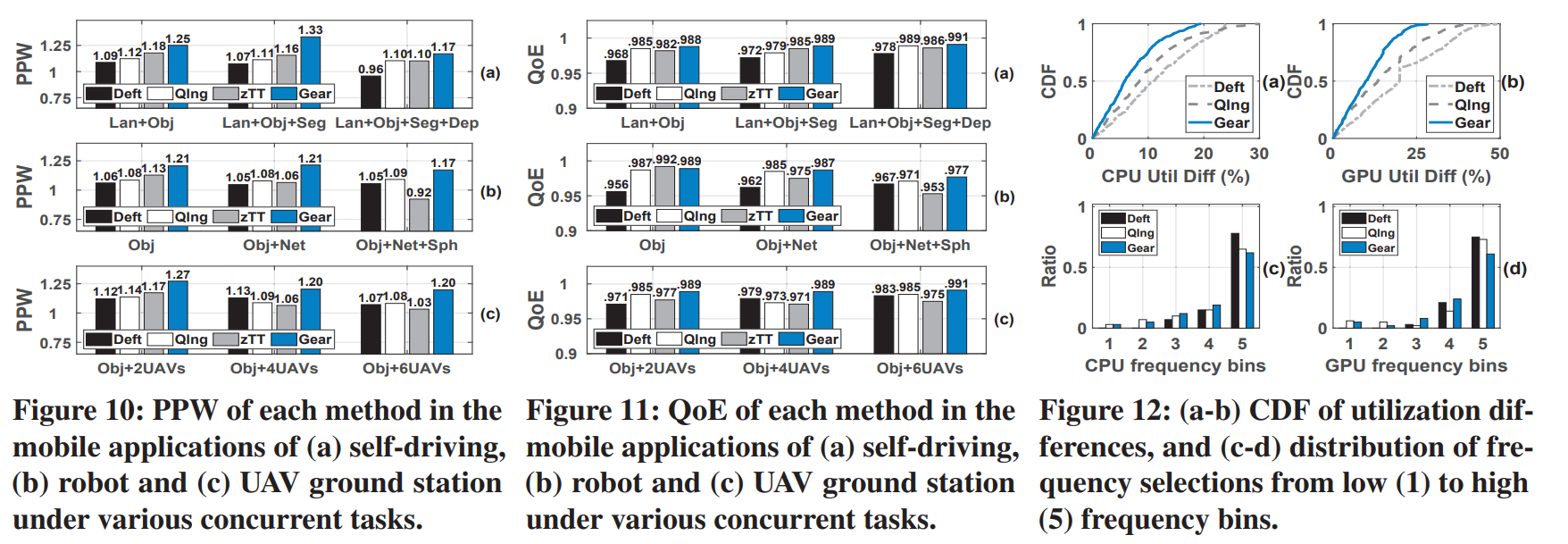
- Fig10/11(a)分别测试了车道线检测(Lan),目标识别(Obj),分割(Seg)和深度估计(Dep)的能效比。这里的QoE用的是归一化帧率。为什么QoE要归一化?因为不同task的指标不同,比如Obj的QoE是FPS,而Net是网络速度。
- Fig10/11(b)分别测试了目标检测(Obj),视频上传(Net)和对话识别(Sph)的应用。这里的QoE用的是归一化的帧率。
- Fig10/11(c)分别测试了UAV的多路视频流的能力,从2加到6.这里的QoE用的归一化帧率。
- Fig12(a)/(b),测试的是Fig10(a)中的"Lan+Obj+Seg",画出了实际利用率和目标利用率差异的CDF曲线。CDF曲线表达了什么?因为要比较谁更接近80%的处理器利用率。它这里画了累计概率密度曲线,就是谁的曲线更靠近左上,谁就是更能让利用率保持在80%。
- Fig12(c)/(d),作者将CPU/GPU频率划分为了5个档次,表示在实现相同利用率是Gear更多的选择是中低频,更节能。
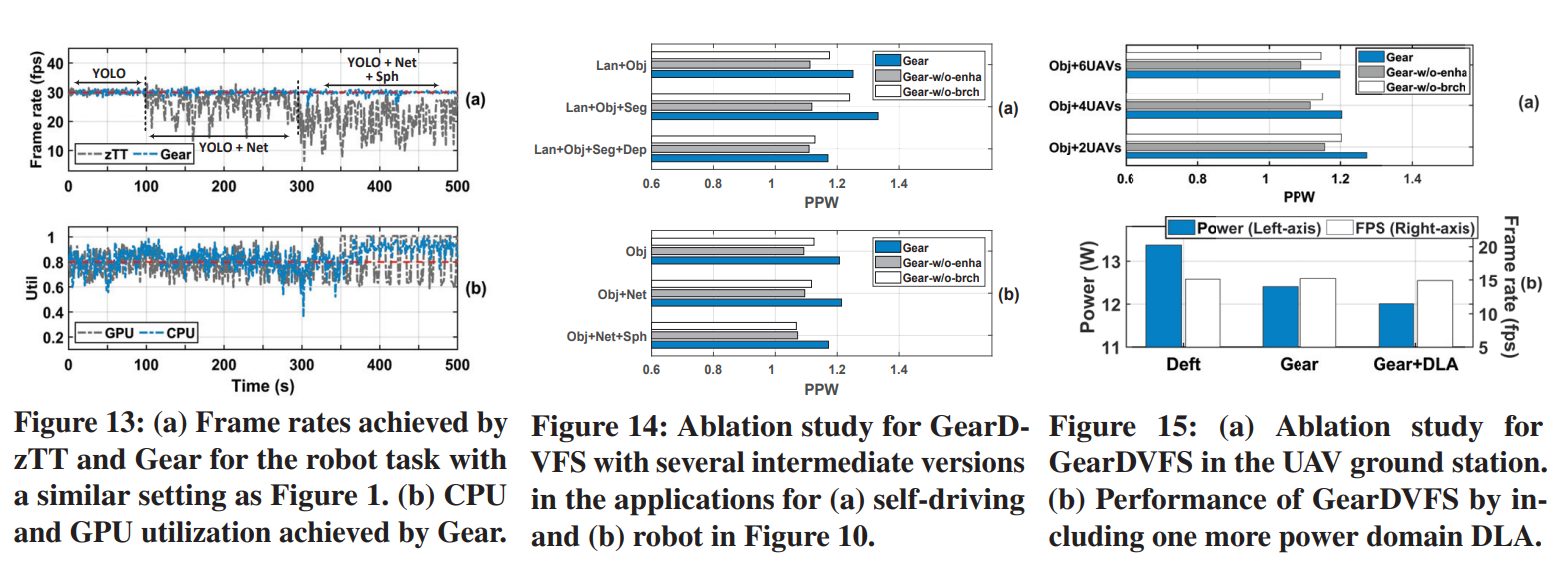
- Fig13,对比了zTT和Gear的多任务的效果。
- Fig14,15是消融实验,去掉了Gear的两个设计,
Gear-w/o-enha是去掉了meta-state的增强设计。Gear-w/o-brch是去掉了meta-learner的多分支设计。
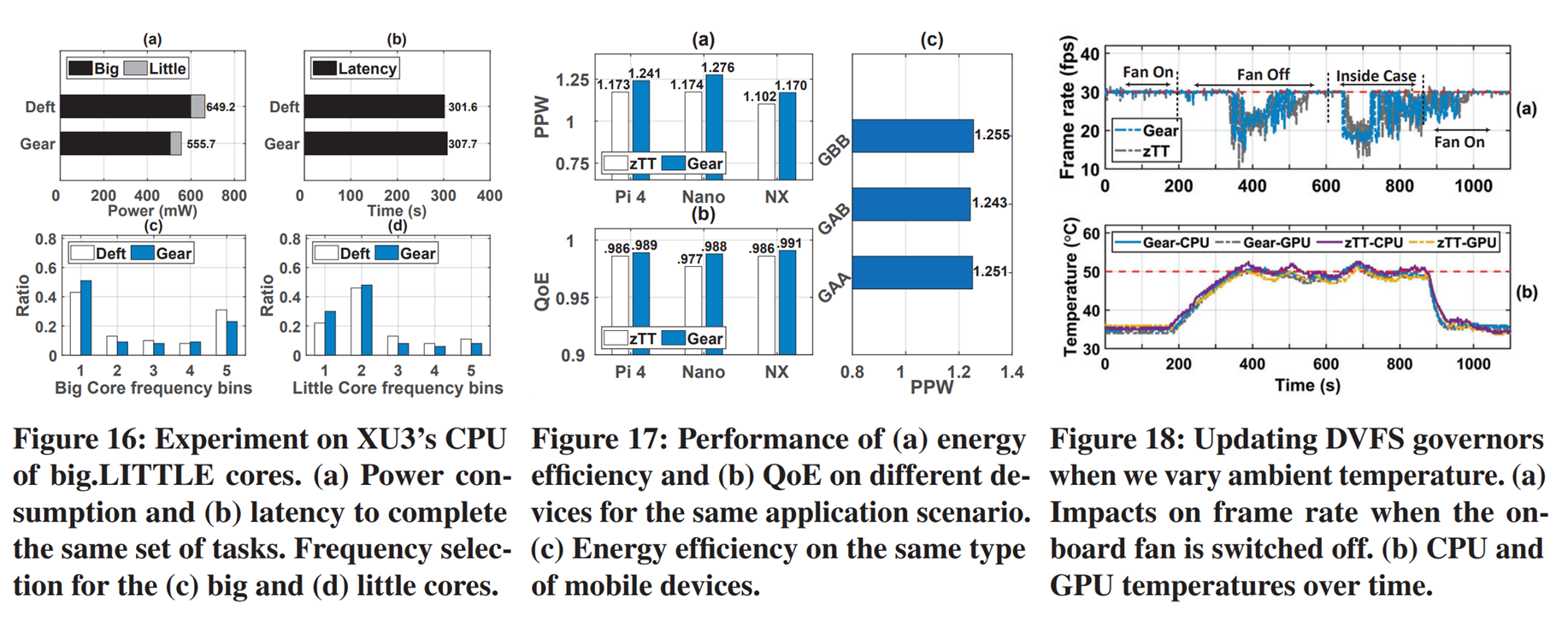
- 前面1-7的实验是在NVIDIA Jetson NX上实现的,这个板子CPU没有大小核心的区分。所以作者在XU'3上重新跑了一次实验,这个板子区分了大小和小。Figf 156(a)里面Gear将大核心和小核心的功耗都降了下来,(b)表示了在降了功耗后,延迟却没怎么变化。(c),(d)就是把频率选择可视化了,因为Gear更多选择了中低频,所以它的功耗比Deft更低。
- Fig17就是在相同应用场景下,(a),(b)分别测了 Pi4, Nano, NX上的能效比和QoE。(c)是交叉验证,GAA的意思是在A板子上训练Gear的模型,部署在A板子上运行的效果。GAB就是在A板子上运行,部署在B板子测试的效果。这里A和B板子是两个型号一致NX。
- Fig18,作者对比的是zTT和Gear的热控制能力。
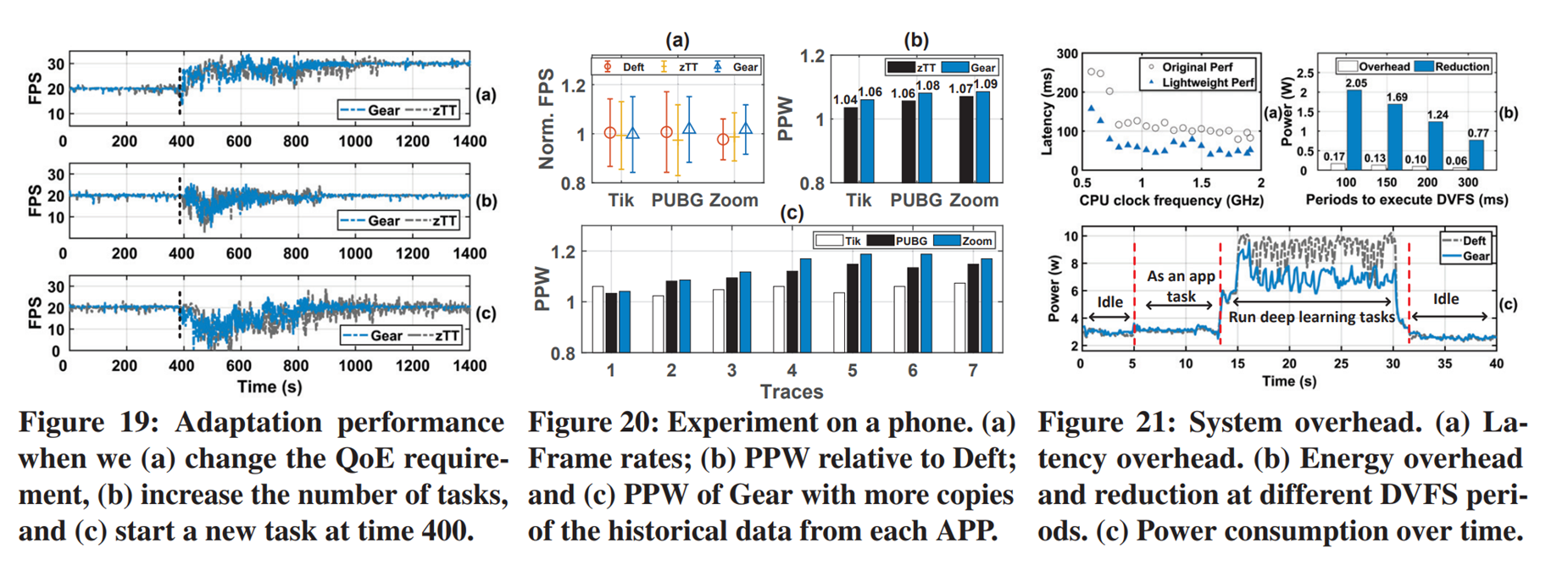
- Fig19对比的是Gear和zTT的QoE的变化的适应性。a在400的时候改变了QoE的target(从20到30),Gear花了大概500秒完成了转换,zTT大概700秒。B里面再400秒时增减了任务数量,从两个视频流加到4个视频流,gear用来490秒,zTT用了500秒完成适应。C里面用于个移动机器人实现目标检测,之后400秒时加上speech reconigtion任务。因为SPH的工作负载更重了,而且Qoe和obj不同,Gear花了650秒完成,而ztt无法满足帧率要求。
- Fig20时再手机上对TikTok,PUBG以及ZOOM三个应用进行了测试(后台仅操作系统服务)。图a分别测试除了3个方法的帧率波动都是非常接近的,在b中进一步测试了PPW的性能发现Gear能够进一步提升能耗数据。C中,追踪测试了1-7次使用该APP的能耗数据,随着使用次数的增多,PPW会提升。
- 主要的overhead在于,因为Gear要去获取一些硬件数据,系统数据,并且GEAR的决策也会受到CPU频率的影响,所以a表示了整个系统随着CPU频率的延迟影响。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号