
数据结构-第七章学习小结
第七章的内容是查找,总的来说整个章节的学习思路很清晰,分为线性表、树表、随机表的查找三部分。
关于线性表的查找,我印象最深刻的内容就是设有“监视哨”的顺序查找方法和折半查找方法。数组首元素存储查找的key数据,保证从后往前遍历到a[0]时能找到key并退出循环,这就不需要计数器来辅助了,这种思路确实很值得学习。但是链表的查找要用到哨兵的话该怎么办呢?既然要有从后往前的遍历过程,那应该是得用双向链表,用每个结点的前驱找到上一个结点的位置。但其实“哨兵”不一定在表首,按这种思路来说,它只要在有效数据范围外面就可以了。所以应该可以在单链表的表尾再加个尾结点存储key值,具体怎么通过返回的值确定是找得到还是找不到,这应该可以通过循环体外的return 0或-1来确定。
其次关于折半查找(二分查找),以前总觉得很难,学完之后发现查找过程蛮清晰的。最有意思的是做讨论二的过程。刚开始只是大致懂这个原理,总是担心奇偶个数、查找数据过大或过小、high值low值交替更新等数据的问题会影响查找的准确性。写过各种情况的具体过程后,才发现是否能准确找到真的与这些问题无关。关键是在hgh值、low值、mid值上。写完讨论二之后感觉对这个折半查找又懂了很多......(至少现在看这些算法不会纠结于每一步怎么走了)
我个人觉得树表的查找是全章最难的部分,尤其是平衡二叉树的调整过程和B树与B+树的区别。说到底还是要多看书,第一次看平衡二叉树那部分的时候看得不够细,以至于听课时也不懂。后来再看了遍书就大概能懂为什么要按这个方向旋转了,但具体的代码实现过程还是得上网搜才懂。其实也不难,类似于swap函数这样交换数值,只是交换的是结点类型,还要加上更新深度的语句。
关于B树和B+树的区别,看了好久终于看懂了:1.B树每个非叶子结点最多有m-1个关键字,存储着有效数据;B+树的每个非叶子结点最多有m个关键字,而且只作索引(只包含对应子树的最大关键字和指向该子树的指针,不含有该关键字对应记录的存储地址),有效数据全存储在叶子节点中。 2.B+树中有两个头指针:一个指向根节点,另一个指向关键字最小的叶子结点,并且所有的叶子结点使用链表相连,便于区间查找和遍历。
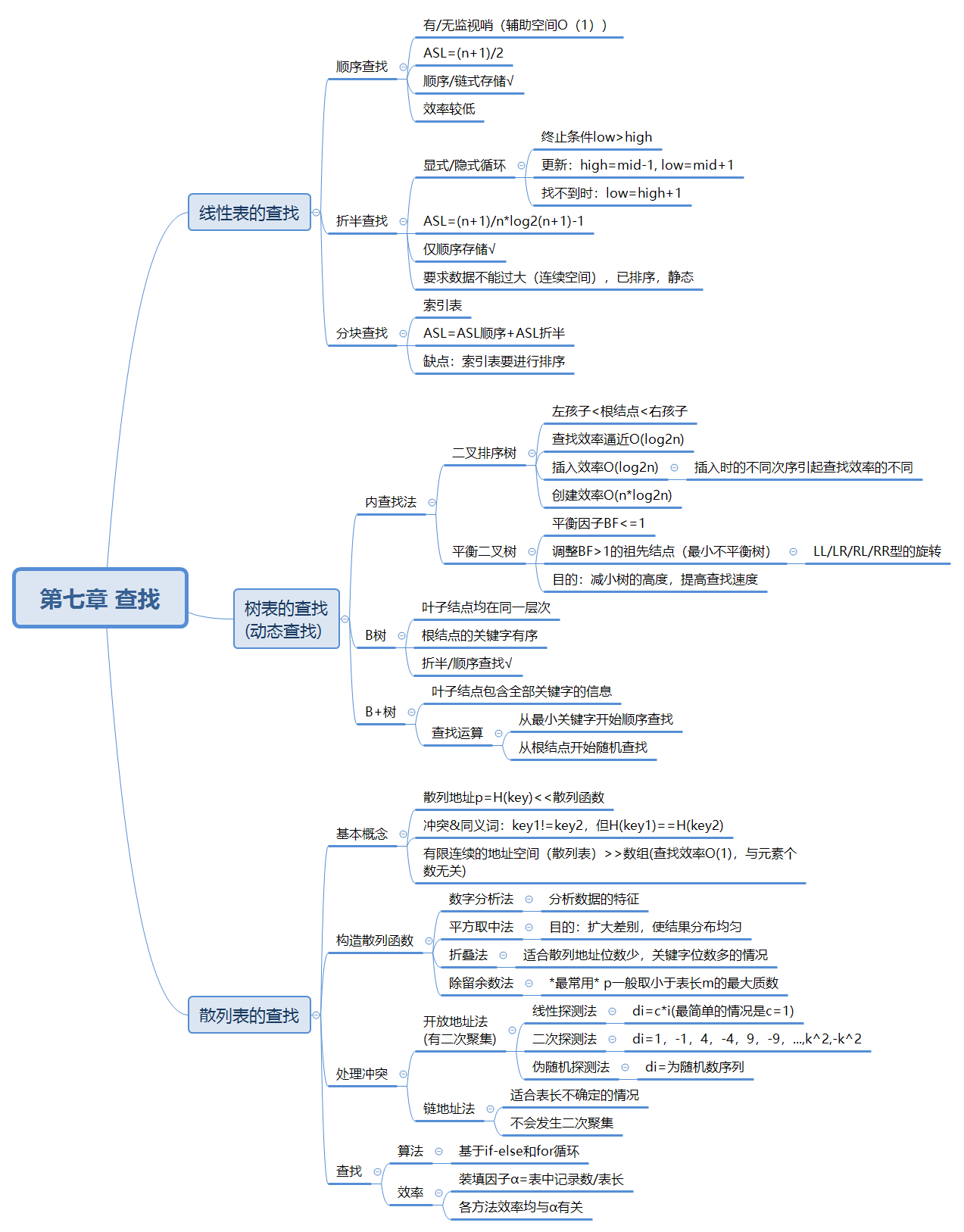
另外本章节应该还有一个重点是不同查找算法的ASL的计算,这个在提纲中没有详写。我觉得复杂一点的计算就是哈希表中查找成功或失败的计算了,但是只要构建完哈希表后就能算出来,(有的题目可能会加些增删元素的操作)。
做跟散列表有关的作业题时犯了个严重错误......总想着用字符的形式存储数据在哈希表中的下标,忽略了字符能表示的数字范围只有0-9,过了很久才反应过来。这次做作业有尝试用课本的哈希表HTable的结构体去做,也有尝试用辅助链表,最终选择了两个数组的形式,因为这个形式最简洁。不过在用链表做的过程中发现自己对以前的知识记得不太牢固了,以至于增加结点的过程写错还隔了好久才看出来。现在还剩最后一章排序就期末考了,下一阶段的目标是首先学好排序,多看课本,然后早点做完作业开始复习(通过这次作业发现真的需要复习了,不仅是算法,还有一些涉及到细致知识点的选择题,之前做完作业都没对过答案...)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号