Kafka-分布式消息队列实战
0. 背景
因为实际项目中碰到这样一个场景:
将不同的轨迹数据发布到不同的处理者进行处理,并在前端展示,想来符合消息队列的场景,开始使用redis实现了一个简单的消息队列:
# -*- coding: utf-8 -*- import redis def singleton(cls, *arg, **kw): instances = {} def _singleton(*arg, **kw): if arg not in instances: instances[arg] = cls(*arg, **kw) return instances[arg] return _singleton class RedisConfig: HOST = '127.0.0.1' PORT = 6379 DBID = 0 @singleton class RedisQueue(object): def __init__(self, trail_id, namespace='data_queue'): ''' RedisQueue设计为单例: trail_id不同则为不同的单例,即同一trail_id应保持为只有一个实例 ''' self.__pool = redis.ConnectionPool(host=RedisConfig.HOST, port=RedisConfig.PORT, db=RedisConfig.DBID) self.__db = redis.Redis(connection_pool=self.__pool) self.key = '%s:%s' % (namespace, trail_id) @staticmethod def create_pool(): RedisQueue.pool = redis.ConnectionPool( host=RedisConfig.HOST, port=RedisConfig.PORT, db=RedisConfig.DBID) def qsize(self): return self.__db.llen(self.key) def empty(self): return self.qsize() == 0 def put(self, item): self.__db.rpush(self.key, item) def get(self, trail_id, block=False, timeout=None): key = 'data_queue:%s' % trail_id if block: item = self.__db.blpop(key, timeout=timeout) else: item = self.__db.lpop(key) return item
这样的实现,虽然满足了现在的项目需求,但是却存在很多问题:
1)数据pop完了会发生什么?
2)设计成了单例模式,使得一条轨迹就使用一个redis实例,但是万一有上万条轨迹,可能无法保证性能
针对这些问题,想使用kafka进行改进优化
1. Kafka核心概念与原理
1)topic 和 日志
每个topic通常对应一个业务,对每个topic,kafka对它进行了分区,如下图所示:
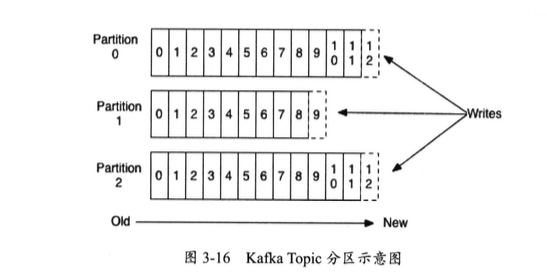
kafka可以在多个consumer并发的情况下提供有序性和负载均衡。
2. 实战
使用kafka, 仿真端有新的数据就将数据发布到指定的queue,订阅端收到订阅队列的数据直接通过websocket推送到前端
直接上代码:
# -*- coding: utf-8 -*- import json import logging, time import collections import threading import multiprocessing import tornado.websocket from kafka import KafkaConsumer, KafkaProducer from Utils import DBUtils, RedisUtil from Conf import conf ''' todo: tornado api开发: 实现restful接口 ''' class Consumer(threading.Thread): daemon = True def __init__(self, kafka_consumer): self._consumer = kafka_consumer super(Consumer, self).__init__() def run(self): for message in self._consumer: WebSocketHandler.write_message_to_all(message) class NewConsumer(multiprocessing.Process): def __init__(self): multiprocessing.Process.__init__(self) self.stop_event = multiprocessing.Event() def stop(self): self.stop_event.set() def run(self): consumer = KafkaConsumer(bootstrap_servers=conf['BOOTSTRAP_SERVERS'], auto_offset_reset='earliest', consumer_timeout_ms=1000) #订阅某个topic consumer.subscribe(['trails']) while not self.stop_event.is_set(): for message in consumer: WebSocketHandler.write_message_to_all(message) if self.stop_event.is_set(): break consumer.close() class Producer(threading.Thread): ''' 目前模拟数据产生,后续应该部署到仿真端,由仿真端生产数据 ''' def __init__(self): threading.Thread.__init__(self) self.stop_event = threading.Event() def stop(self): self.stop_event.set() def run(self): producer = KafkaProducer(bootstrap_servers=conf['BOOTSTRAP_SERVERS']) while not self.stop_event.is_set(): with open(conf['trail_data_fpath'], 'r') as f: lines = [line.strip() for line in f.readlines()] for line in lines: data = {} fields = line.split() data['coordinate_x'] = float(fields[0].strip()) + 1.0 data['coordinate_y'] = float(fields[1].strip()) + 1.0 data['trail_id'] = trail_id data['timestamp'] = time.time() producer.send(data) producer.close() class WebSocketHandler(tornado.websocket.WebSocketHandler): open_sockets = set() def __init__(self, *args, **kwargs): self._consumer = NewConsumer() self._producer = Producer() super(WebSocketHandler, self).__init__(*args, **kwargs) def open(self, *args): self._consumer.start() self._producer.start() self.set_nodelay(True) type(self).open_sockets.add(self) def on_message(self, message): pass @classmethod def write_message_to_all(cls, message): ''' 需要解析数据格式 ''' removable_ws = set() for ws in cls.open_sockets: if not ws.ws_connection or not ws.ws_connection.stream.socket: removable_ws.add(ws) else: ws.write_message(message) for ws in removable_ws: cls.open_sockets.remove(ws) def on_close(self): self._consumer.stop() self._producer.stop() print("WebSocket closed")
web框架是使用的tornado,因为是实时性web应用,需要很多websocket,tornado更适用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号