
个人项目(第二次作业)
| 这个作业属于哪个课程 | 计科国际班 |
| ---- | ---- | ---- |
| 作业要求 | 第二次作业要求 |
| 作业目标 | 编写一个论文查重程序(包含单元测试) |
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时 | 实际耗时 |
|---|---|---|---|
| Planning | 计划 | 30 | |
| -Estimate | -估计这个任务需要多少时间 | 50 | |
| Development | 开发 | 240 | |
| -Analysis | -需求分析 | 120 | |
| -Design Spec | -生成设计文档 | 40 | |
| -Design Review | -设计复审 | 30 | |
| -Coding Standard | -代码规范 | 30 | |
| -Design | -具体设计 | 70 | |
| -Coding | -具体编码 | 230 | |
| -Code Review | -代码复审 | 30 | |
| -Test | -测试 | 60 | |
| Reporting | 报告 | 30 | |
| -Test Report | -测试报告 | 20 | |
| -Size Measurement | -计算工作量 | 10 | |
| -Postmortem &Process Improvement Plan | -事后总结,并提出过程改进计划 | 20 | |
| 合计 | 1010 |
补充一下第一次尝试的过程 我先是在CSDN上查阅了一些判定相似度的算法资料
defi compare(file1,file2):
lines1= readLines(file1) lines2 readlines(file2)
count =0.
for line in lines1:
if lines2.count line)>0
count +=1
return count / max(len(lines1),len(lines2))
这样的结果是查重率高得离谱,果断放弃。
然后网上资料显示,Python有自带的查重函数difflib
import difflib
def string similar(s1,s2):
return difflib.sequenceMatcher(None,s1,s2).quick_ratio() for i in range(len(data4_message)):
s1 data4 message[i] s2= data4 answer[i]
print(string_similar(s1,s2))
这样的结果同样是查重率不符合逻辑,也不使用这种方法
3.查阅资料后发现还有一种以前没有接触过的方法:计算余弦相似度和TF-IDF算法
走投无路之下,只能硬着头皮尝试一下
计算模块接口的设计与实现过程。
设计的思路流程图
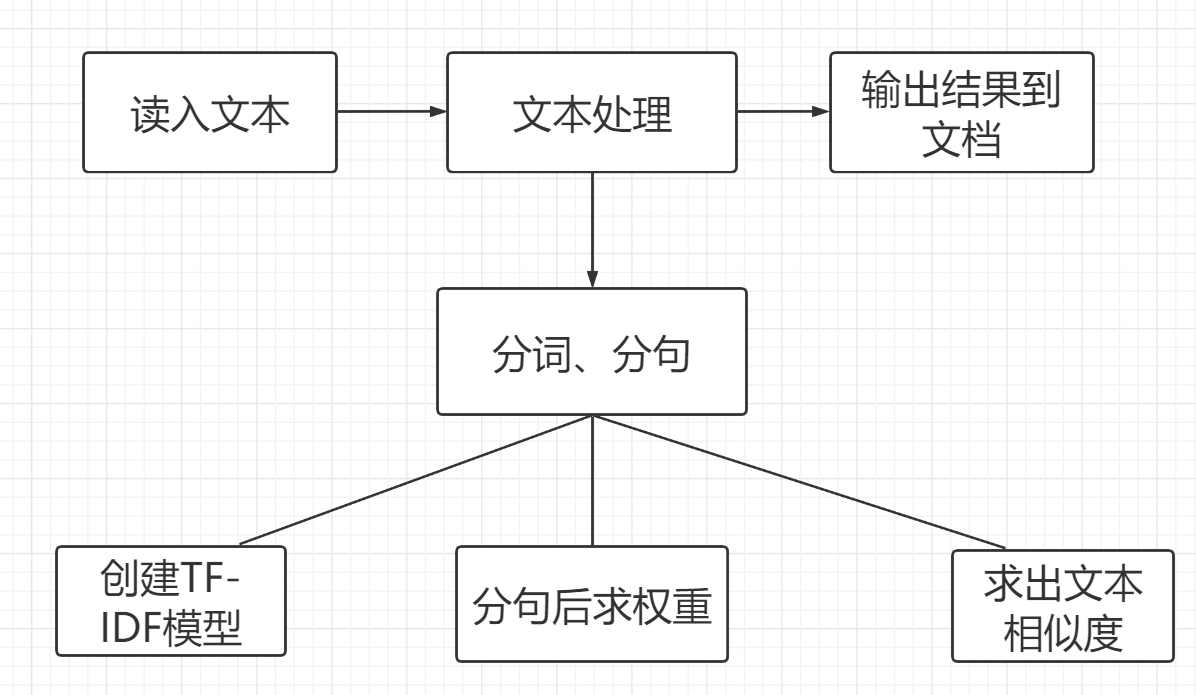
所用接口(函数)
1.分词模块
jieba.cut
从博客园的其他用户发表的随笔中,我得知jieba接口的功能十分强大,jieba分词有三种模式:全模式、精确模式、搜索引擎模式。> https://www.cnblogs.com/aloiswei/p/11567616.html
在这里我认为只需要用到精确模式就足够了。
jieba 代码例子:

运行结果:

2.求权重模块
核心思想就是将该句子的长度除以整篇文章的长度
这个是比较简单粗暴的方法,但我查阅资料发现,这十分有效。
for word in file_data:
if '\u4e00'<=word<='\u9fff':
file_len +=1
for sentence in file_sentence:
for word in sentence:
if '\u4e00' <= word <= '\u9fff':
quanzhong += 1
3.计算文本相似度模块
该模块的核心是基于TF-IDF算法来进行的
其主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
由于以前没有接触过该算法,以下资料大部分都是在CSDN上查阅的
源自> https://blog.csdn.net/asialee_bird/article/details/81486700
TF是词频(Term Frequency)
词频(TF)表示词条(关键字)在文本中出现的频率。
IDF是逆向文件频率(Inverse Document Frequency)
逆向文件频率 (IDF) :某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。
如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。
TF-IDF实际上是:TF * IDF
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
4.在命令行进行文档读入读出
通过调用sys库来读取文档
例子:
import sys
file = open(sys.argv[1],'r', encoding='UTF-8')
data = orig_file.read()
file.close()
但此程序代码在pycharm中运行时是会报错的
需要在命令行界面才能运行
读出文档也同理
file = open('whatever.txt','w', encoding='UTF-8')
file.write(something)
file.close()
性能分析
使用Pycharm Professional版本自带的profile功能进行性能分析
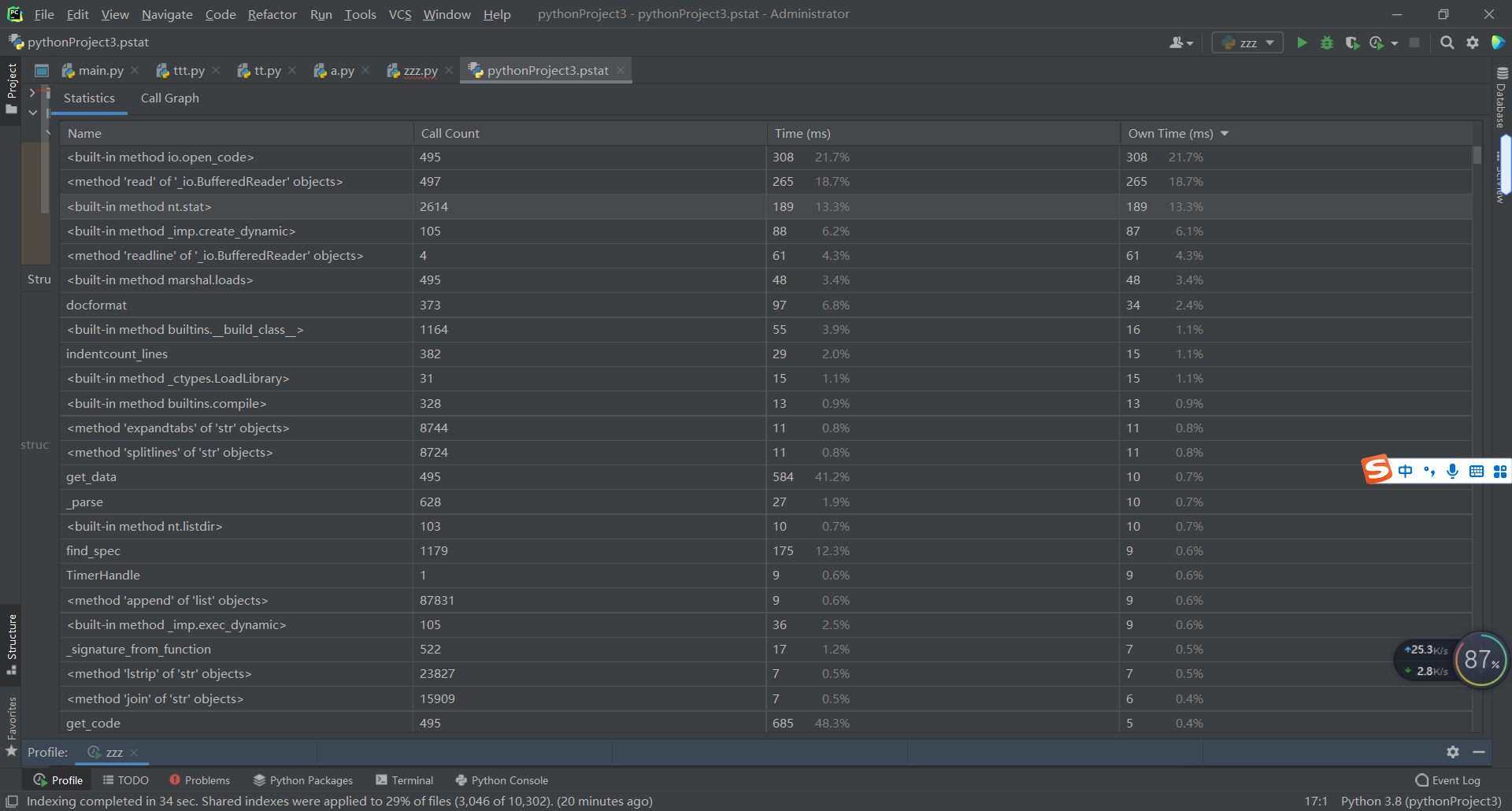
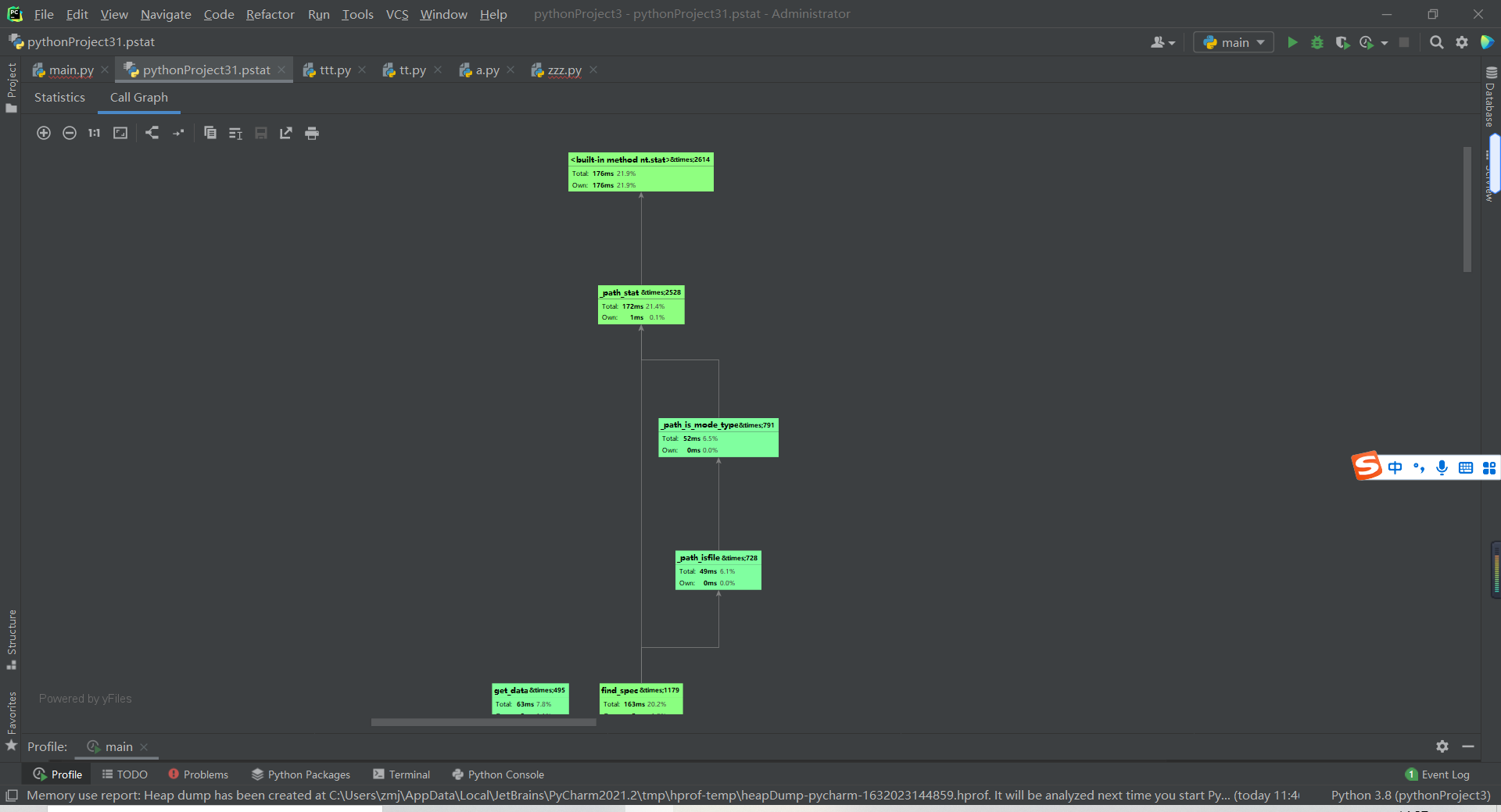
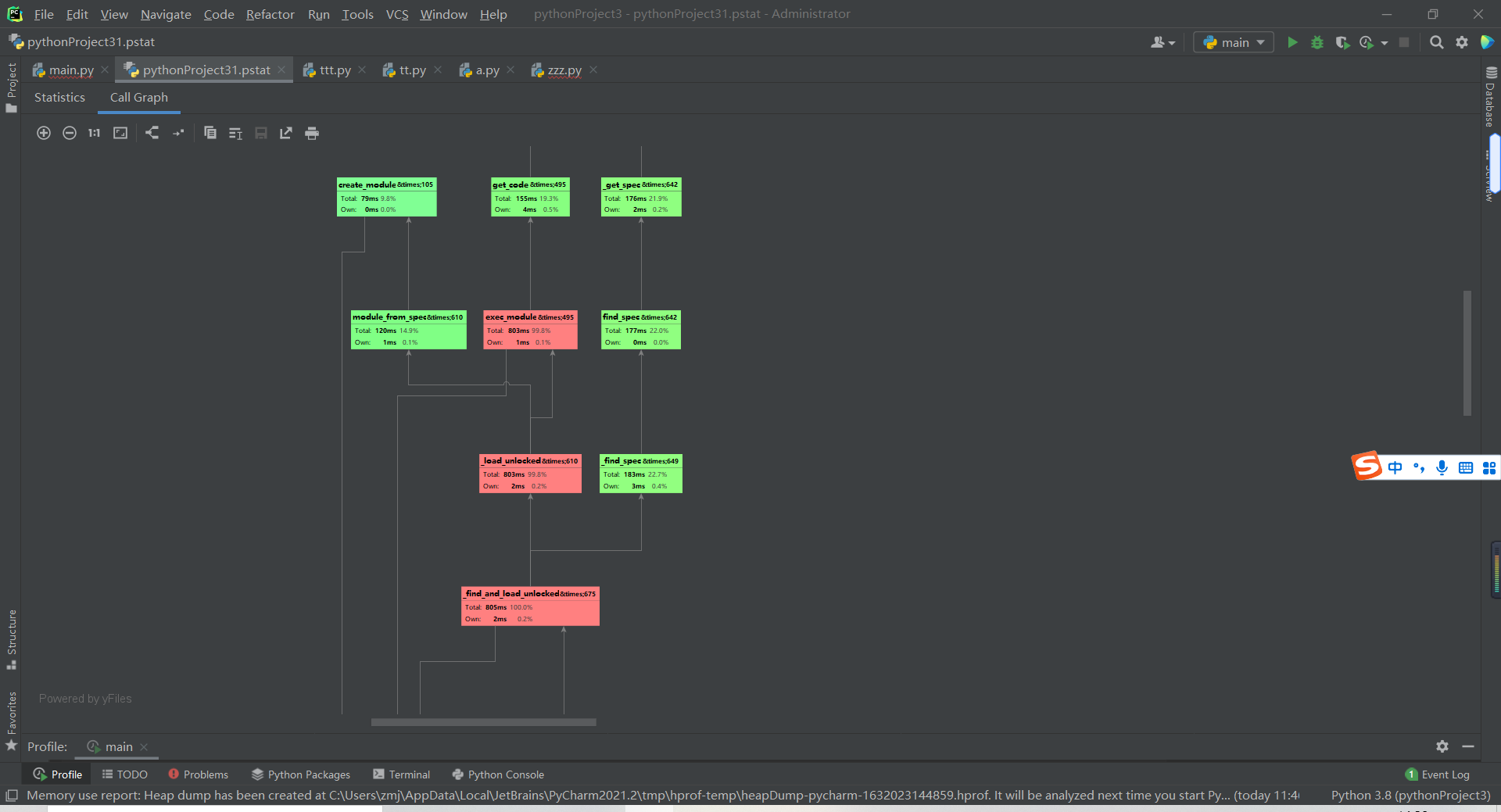
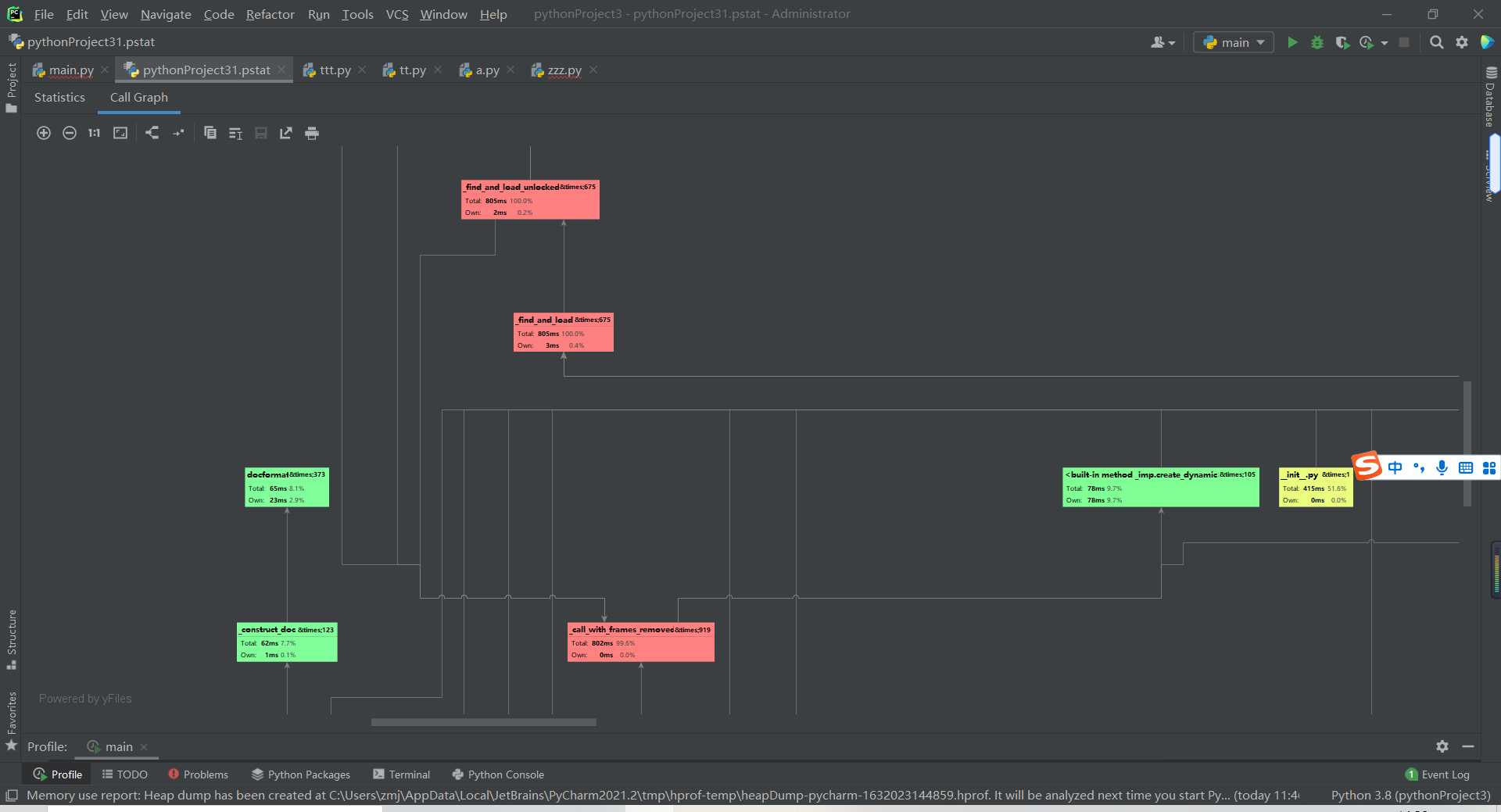
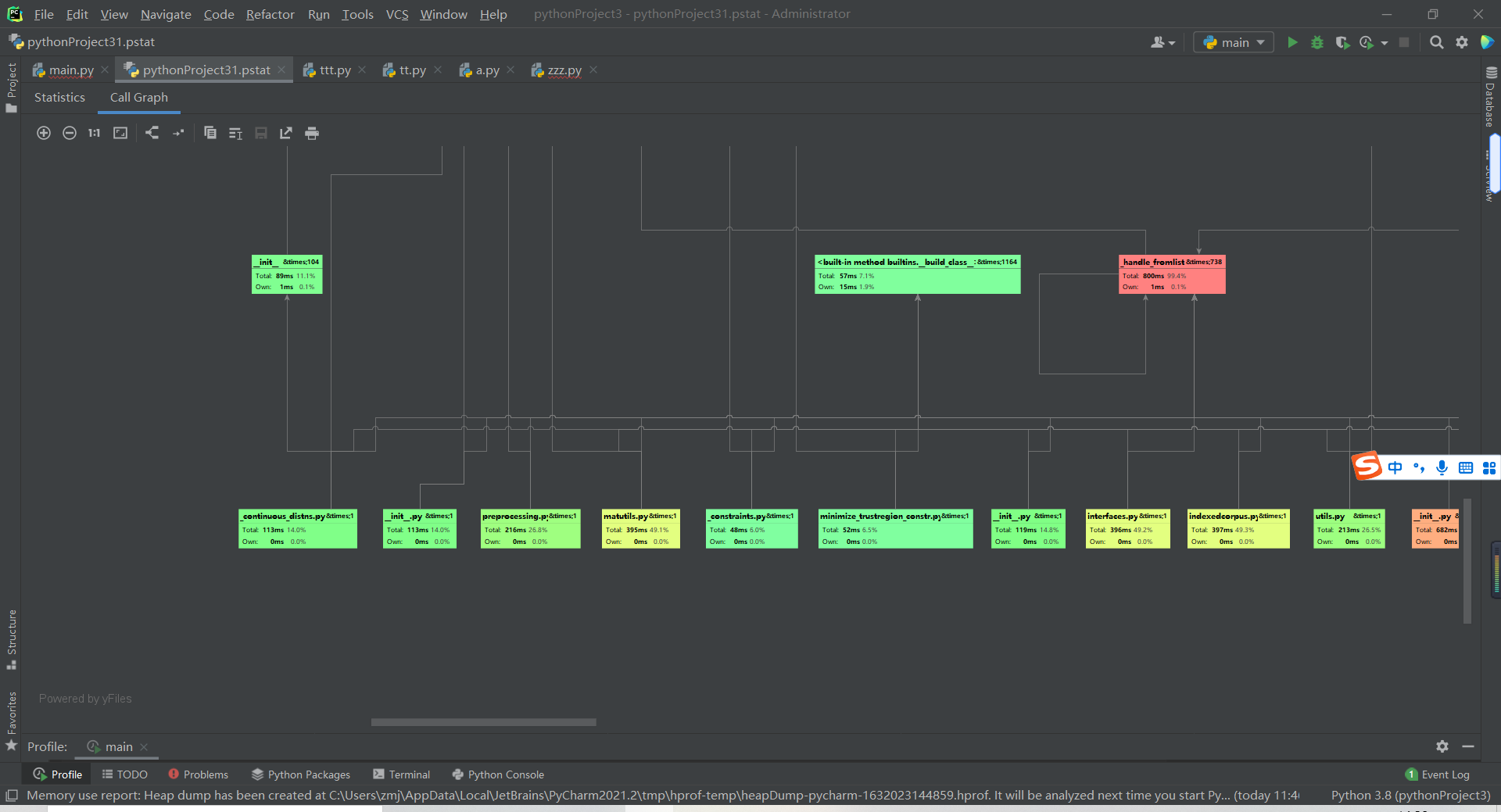
单元测试
使用unnitest和beautifulreport模块进行测试
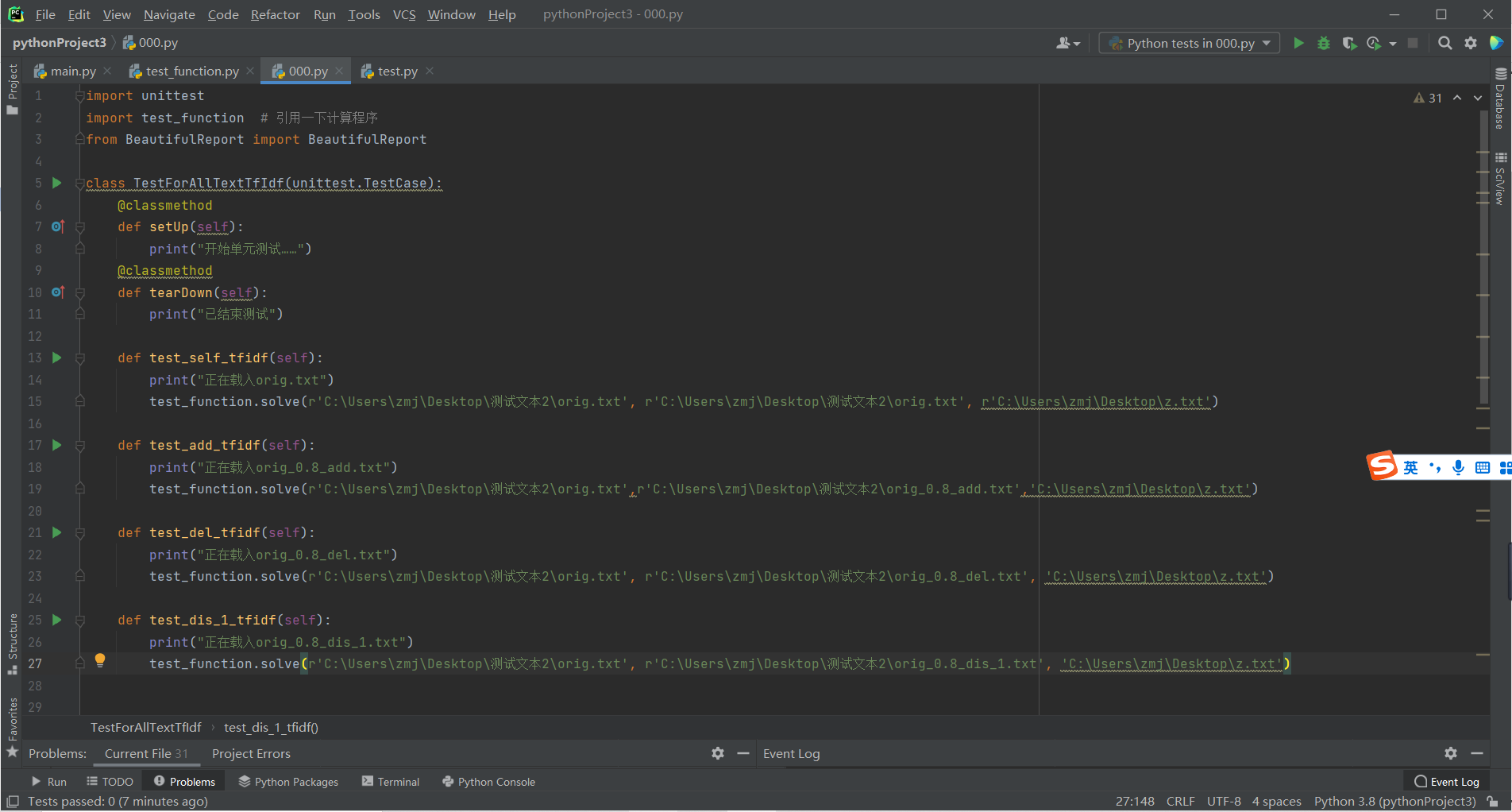
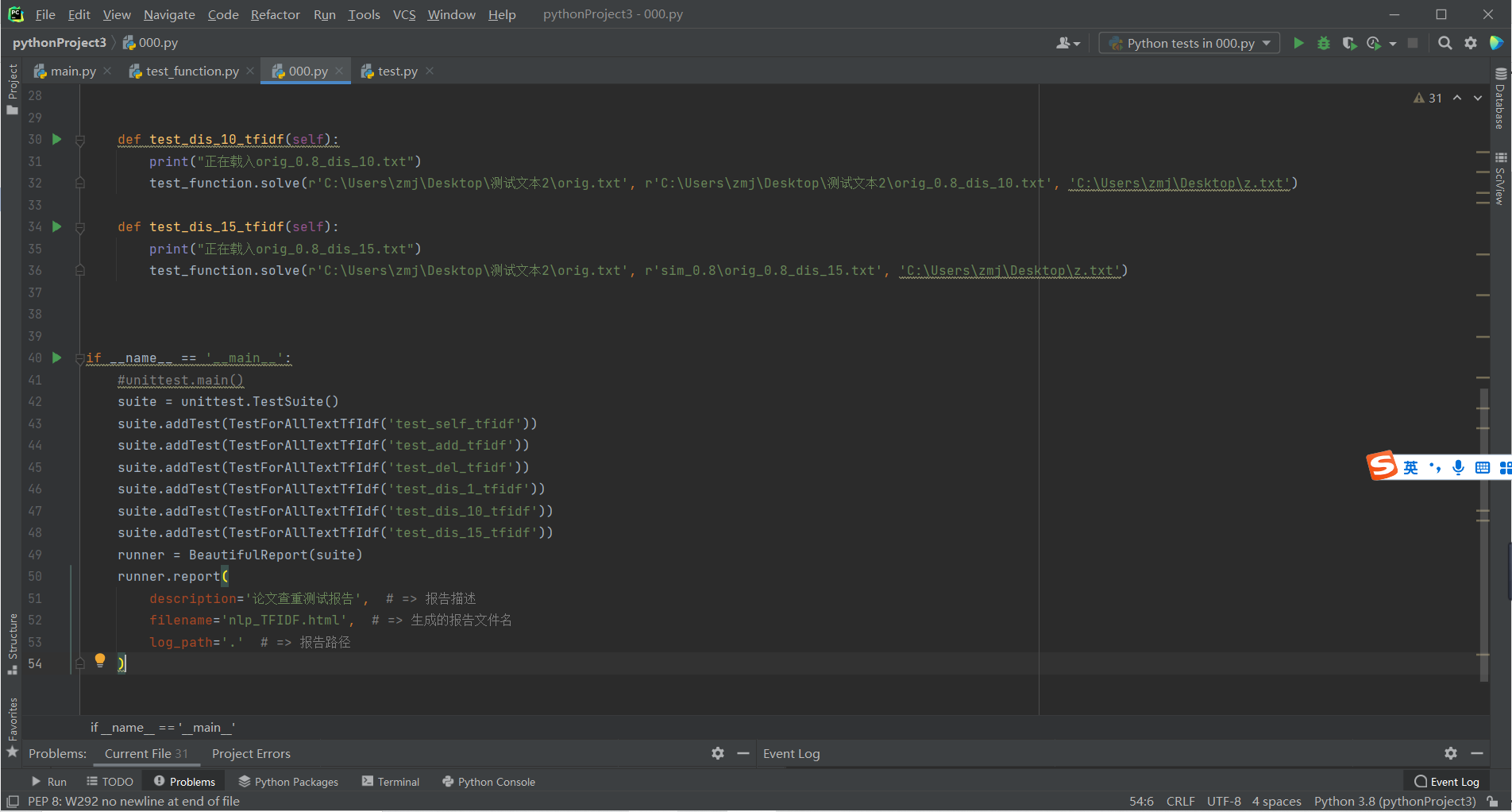


代码覆盖率
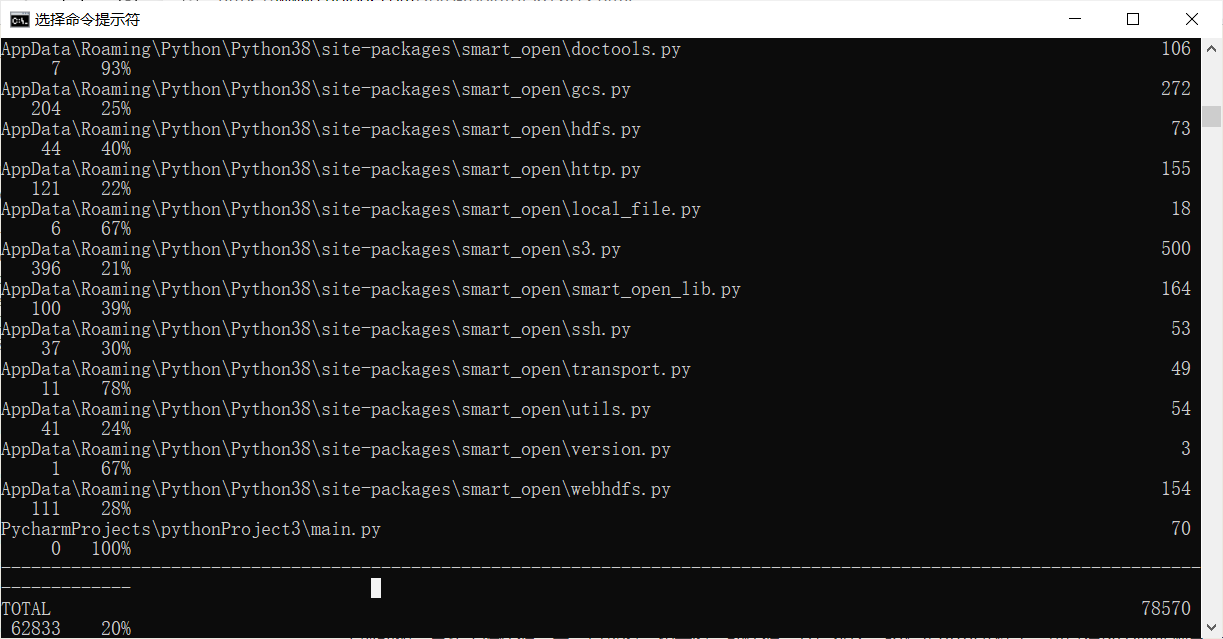
显示main.py百分百覆盖
计算模块的部分异常处理情况
输入空文本和不存在的文本的情况
将使用try-except语句来提示用户输入错误


 浙公网安备 33010602011771号
浙公网安备 33010602011771号