
scala_spark积压解决
案例1
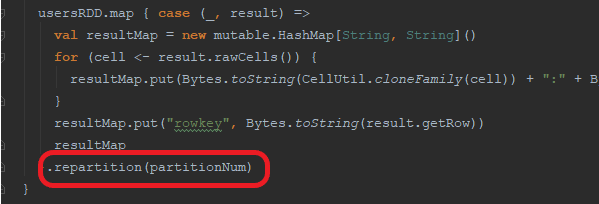
到源码中查看,发现读取HBase数据时使用了重分区算子。
原本Spark在使用RDD模式拉取HBase数据时,会根据资源分配平均地拉取数据到各个节点。但是这里使用了重分区,导致各节点拉取到数据之后,根据resultMap这个对象的Hash值进行了shuffle,导致了数据倾斜。
将重分区算子去掉就ok了。
案例2
val messages = kafkaStream
messages.foreachRDD(rdd => {
val bgRDD = getHBaseRDD(sc, tablename)
bgRDD.filter(line => {
line.get("basic:isguard").isDefined && line.get("basic:isguard").get.equals("1")
}).map(msg => {
///////////////……………..
val put = new Put(Bytes.toBytes(machine))
val iterator =dataRow.iterator()
while (iterator.hasNext){
val (family,column,value) = iterator.next()
put.addColumn(Bytes.toBytes(family),Bytes.toBytes(column),Bytes.toBytes(value))
}
(new ImmutableBytesWritable,put)
}).saveAsNewAPIHadoopDataset(HBaseUtil.getHbaseJob(tablename).getConfiguration)
将原本的推送方式删除后,采用HBaseRDD的形式进行推送,使用这种方式推送时,Spark会自动为HBase的连接进行优化,包括但不限于(连接持久化、批量推送、预创建文件)。这种推送方式也可以避免HBase因大量写入造成死机(原因是这种方式会直接创建HBase的存储文件,然后直接加载到HBase的存储中,不会经过WAL机制和Flush机制)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号