

ElasticSearch 安装中文分词器
1、安装中文分词器IK
下载地址:https://github.com/medcl/elasticsearch-analysis-ik
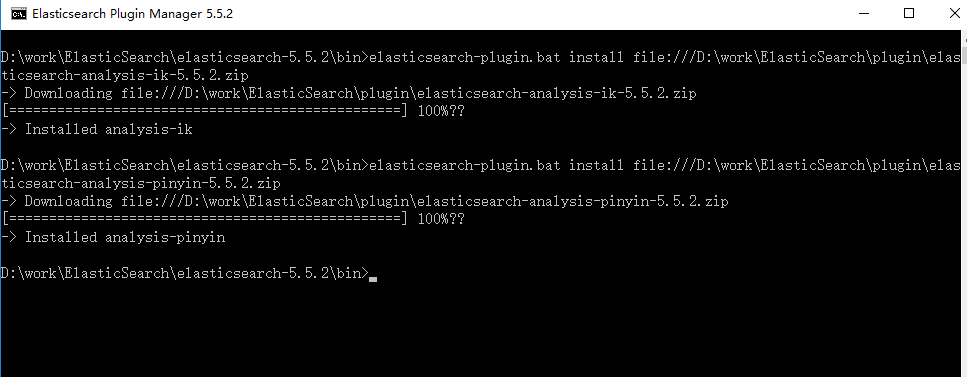
在线下载安装: elasticsearch-plugin.bat install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.5.2/elasticsearch-analysis-ik-5.5.2.zip
先下载后安装:elasticsearch-plugin.bat install file:///D:\work\ElasticSearch\plugin\elasticsearch-analysis-ik-5.5.2.zip

2、重启 elasticsearch
3、创建空索引
curl -XPUT http://127.0.0.1:9200/index_china

或
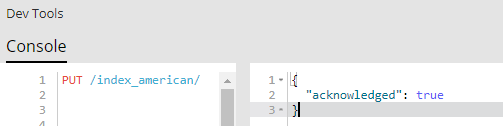
在kibana的Dev Tools中用 PUT /index_american/
4、创建映射
curl -XPOST http://127.0.0.1:9200/index_china/fulltext/_mapping -d "{\"properties\": {\"content\": {\"type\": \"text\",\"analyzer\": \"ik_max_word\",\"search_analyzer\": \"ik_max_word\"}}}"

或
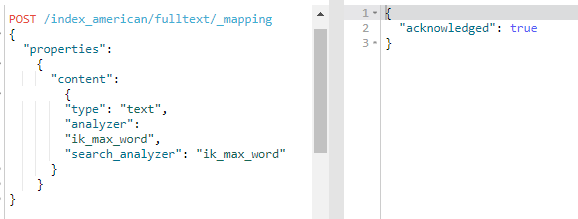
POST /index_american/fulltext/_mapping
{
"properties":
{
"content":
{
"type": "text",
"analyzer":
"ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
5、索引数据
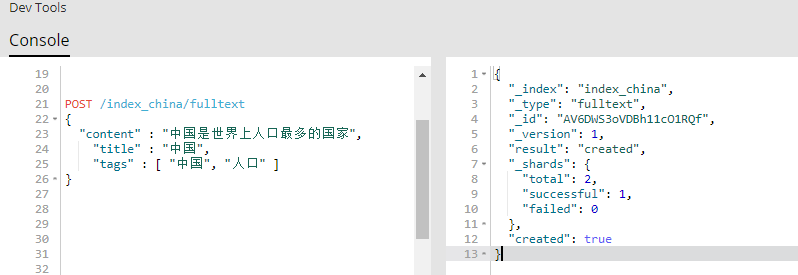
POST /index_china/fulltext
{
"content" : "中国是世界上人口最多的国家",
"title" : "中国",
"tags" : [ "中国", "人口" ]
}
批量索引数据
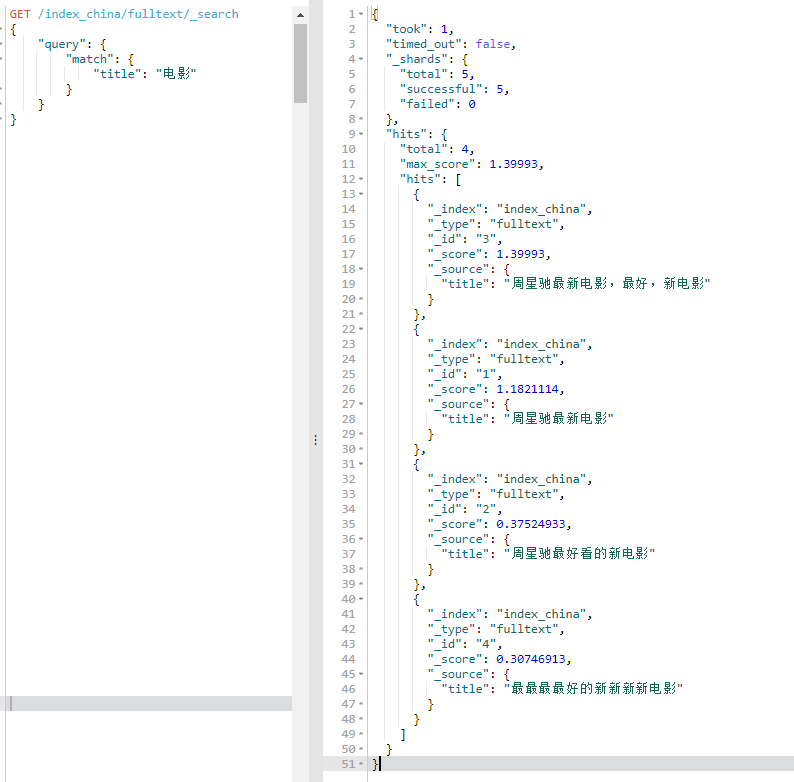
POST /_bulk { "create": { "_index": "index_china", "_type": "fulltext", "_id": 1 } } { "title": "周星驰最新电影" } { "create": { "_index": "index_china", "_type": "fulltext", "_id": 2 } } { "title": "周星驰最好看的新电影" } { "create": { "_index": "index_china", "_type": "fulltext", "_id": 3 } } { "title": "周星驰最新电影,最好,新电影" } { "create": { "_index": "index_china", "_type": "fulltext", "_id": 4 } } { "title": "最最最最好的新新新新电影" } { "create": { "_index": "index_china", "_type": "fulltext", "_id": 5 } } { "title": "I'm not happy about the foxes" }
6、查询
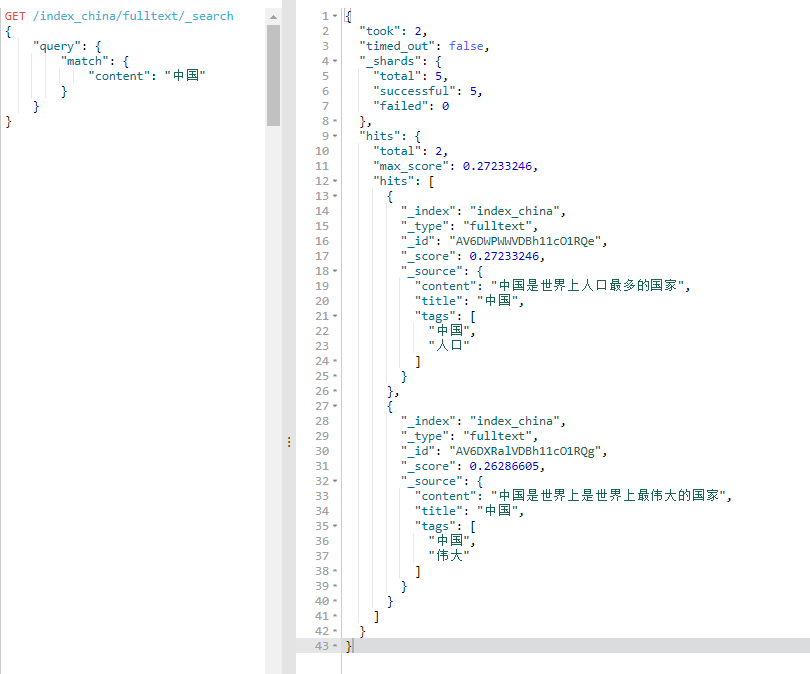
GET /index_china/fulltext/_search
{
"query": {
"match": {
"content": "中国"
}
}
}
7、最大分词和最小分词
ik_smart,
ik_max_word
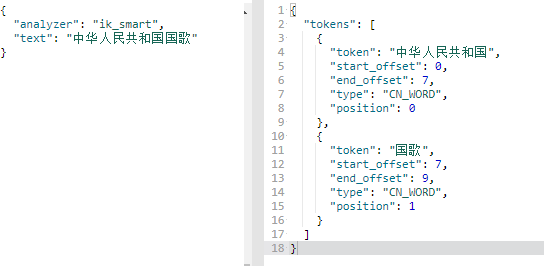

GET /_analyze { "analyzer": "ik_smart", "text": "中华人民共和国" } GET /_analyze { "analyzer": "ik_max_word", "text": "中华人民共和国" }
#删除索引 DELETE /ott_test #创建索引 PUT /ott_test { "mappings": { "ott_type" : { "properties" : { "title" : { "type" : "text", "index":true, "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" }, "date" : { "type" : "date" }, "keyword" : { "type" : "keyword" }, "source" : { "type" : "keyword" }, "link" : { "type" : "keyword" } } } } } #索引数据 POST /ott_test/ott_type { "title":"微博新规惹争议:用户原创内容版权归属于微博?", "link":"http://www.yidianzixun.com/article/0HHoxgVq", "date":"2017-09-17", "source":"虎嗅网", "keyword":"内容" } #分析 GET /ott_test/_analyze { "field": "title", "text": "内容" } #查询 GET /ott_test/ott_type/_search { "query": { "match": { "title": "内容" } } } #只查询title和date两个字段的数据 GET /ott_test/ott_type/_search { "query": {"match_all": {}}, "_source": ["title","date"] }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号