面向对象设计与构造——第一单元总结
写在前面
OO课程的第一单元结束了,第一单元,以多项式求导程序为中心,不断增加新的功能,我学到了很多:
- 熟悉了Java基本语法;
- 初步建立起了面向对象的设计思路;
- 认识到了代码可拓展性的重要;
- 学会了构建自动化测试工具。
Complexity Metrics(复杂度分析)
因为下面要用到复杂度分析,所以先在此给出一些相关概念。
我们需要使用的主要是方法和类的复杂度分析。
方法的复杂度分析主要基于循环复杂度的计算。循环复杂度是一种表示程序复杂度的软件度量,由程序流程图中的“基础路径”数量得来。
-
ev(G):即Essentail Complexity,用来表示一个方法的结构化程度,范围在[1,v(G)]之间,值越大则程序的结构越“病态”,其计算过程和图的“缩点”有关。
-
iv(G):即Design Complexity,用来表示一个方法和他所调用的其他方法的紧密程度,范围也在[1,v(G)]之间,值越大联系越紧密。
-
v(G):即循环复杂度,可以理解为穷尽程序流程每一条路径所需要的试验次数。
对于类,有OCavg和WMC两个项目,分别代表类的方法的平均循环复杂度和总循环复杂度。
下面我将从程序结构,公测、互测以及bug分析几个方面来总结我第一单元的三次作业。
第一次作业
作业要求
实现简单多项式的格式判断和求导,其中多项式由项相加减组成,项是幂函数或带符号整数。
实现方式
读入时用ArrayList存储多项式的每一项,用公式求导后输出。
代码规模
第一次作业代码规模如下图。

类图
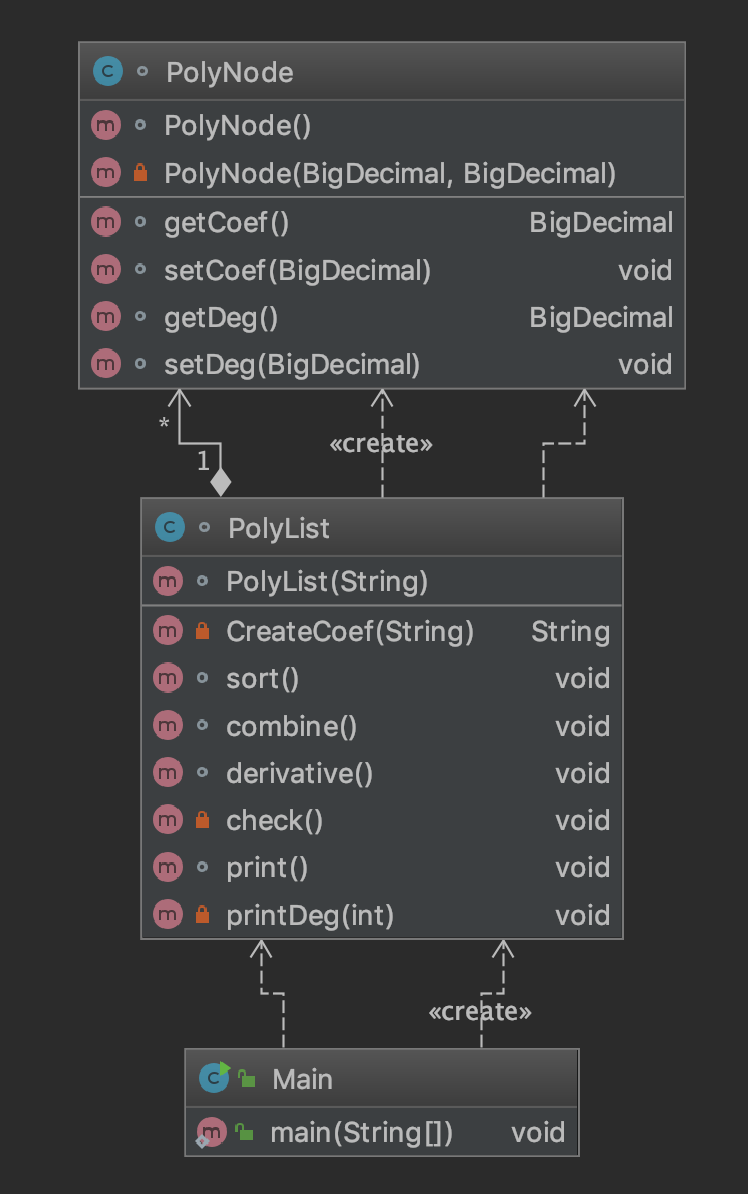
第一次作业类图如下,其中Main是主类,PolyList是多项式类,PolyNode是多项式项类。
复杂度分析
第一次作业的复杂度分析如下。

可以看出PolyList的构造方法和print方法的复杂度很高,因为这两个方法有一个共同点,就是用了很复杂的if/else条件判断语句。
而PolyList的构造方法条件语句复杂,是对正则表达式应用不熟练导致。
Bug分析
公测
笔者的程序在公测中没有出现正确性错误,但是由于优化输出的时候忘记-1*x中的1可以省略,导致一个点性能分不满。
互测
笔者的程序在互测中被发现一个bug,原因是笔者在做输出优化时,只考虑了最后只剩一个系数为0的项,如果出现类似0*x^3+0*x^4,这种两个系数为0的项,就会没有输出。
笔者在互测中,hack了其他人17次,大部分都是正则表达式的错误使用导致的,主要表现在对输入各种情况考虑不周全。
测试方法
- python的xeger包根据正则表达式生成测试数据。
- python的sympy计算正确输出,调用Java的输出,并用equals函数判断正确性。
- 阅读每个人的代码寻找漏洞,在互测中有两个bug是我读代码读出来的。
第二次作业
作业要求
实现简单多项式的格式判断和求导,其中多项式由项相加减组成,项是由因子相乘组成,因子包括sin(x),cos(x),幂函数,带符号整数。
实现方法
-
存储多项式:采用HashMap,其中key采用三元组(x的指数,sin(x)的指数,cos(x)的指数),value存放每一项的系数。
-
求导:公式求导。
-
化简:DFS + 三角函数性质化简。
代码规模
第二次作业的代码规模如下图。

类图
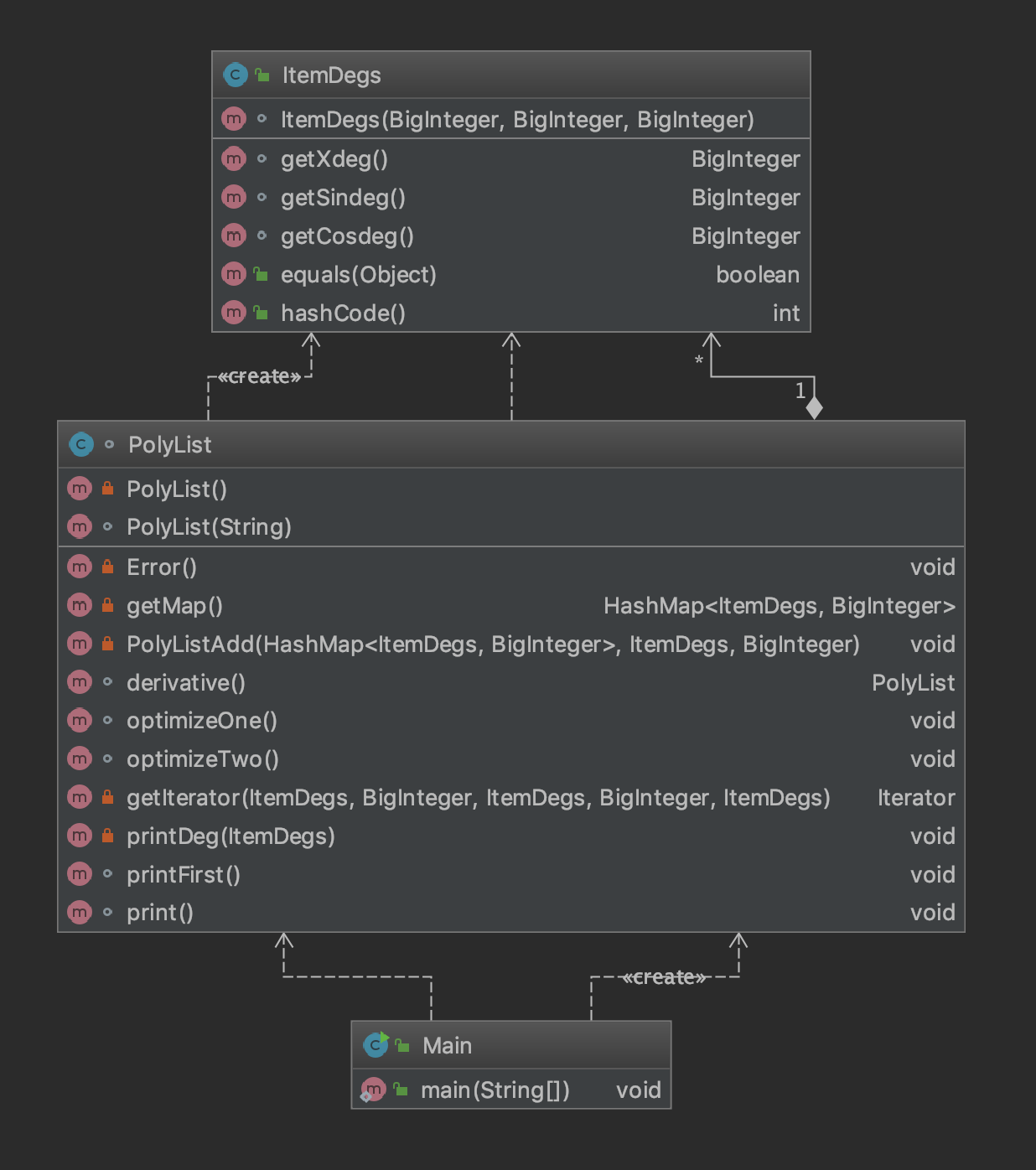
第二次作业类图如下,其中PolyList存储多项式,ItemDegs为自定义的三元组的key。
复杂度分析
第二次作业的复杂度分析如下。
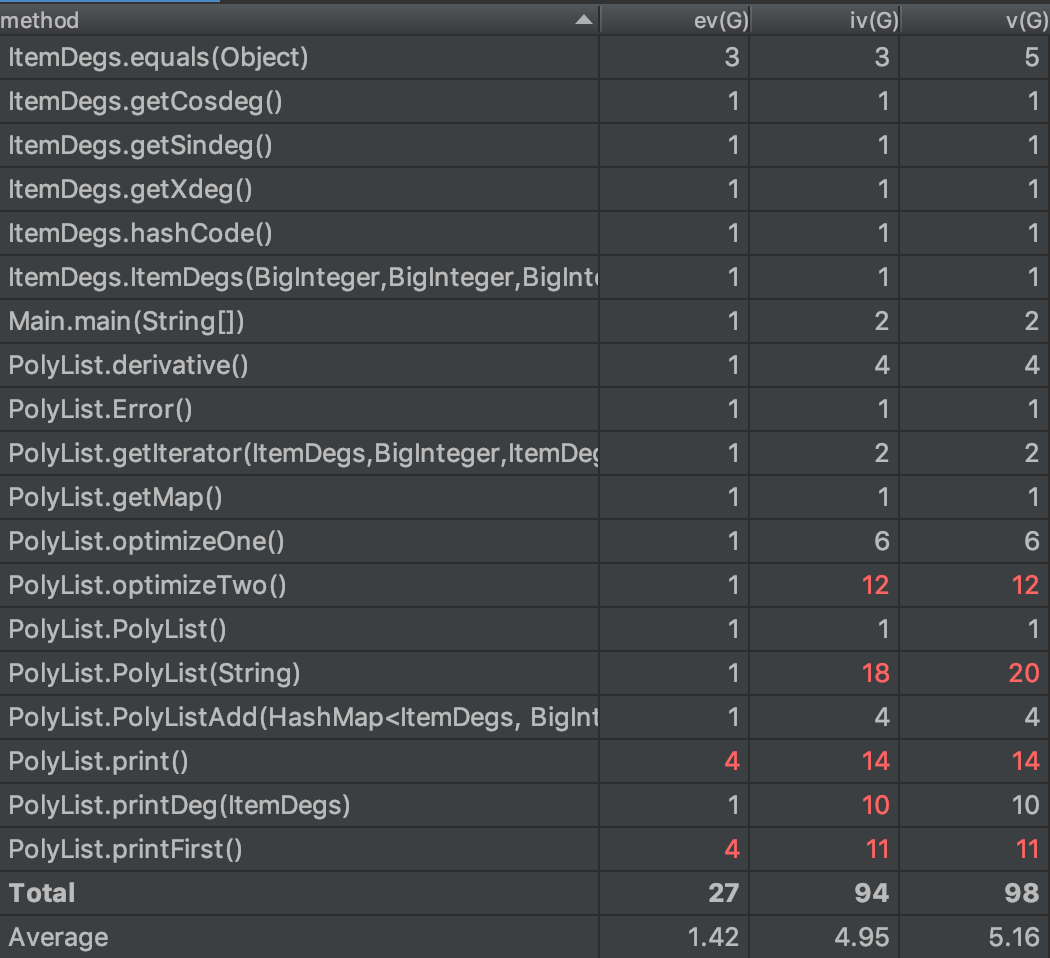
其中几个方法复杂度稍高,下面给出分析:
- optimizeTwo方法是DFS对输出表达式进行三角函数性质优化,有时遍历次数会比较多。
- PolyList构造方法比较冗长,有100行,里面用了很多条件判断,所以iv(G)和v(G)会比较大。
- 而三个print方法对问题类似第一次作业,用了很多复杂的条件判断,造成了很高的代码复杂度。
Bug分析
公测
笔者的程序在公测中,未出现正确性错误,但由于只进行了三角函数合并,未进行贪心拆项优化,故性能分未能拿到满分。
互测
笔者的程序在互测中被发现4个bug,主要来源于几个方面:
- 优化过程中,调用HashMap的remove()方法,但是有的时候这个方法不能remove掉当前的key,效果和未执行一样。而且笔者到现在也没想明白是为什么,如果有大佬知道其中的原因,笔者想请教一下。
- 在用正则表达式检查非法空白字符的时候,误用了Matcher的matches()方法,导致无法检测空白字符。(正确用法是用find()方法)
- 正则表达式TLE,主要是因为用了大正则以及贪婪模式,改为非贪婪模式即可正常输出。
笔者在本次互测时未发现他人bug,主要是因为对拍器出了问题(捂脸),sympy的equals方法有时候不能正确判断表达式的等价性,因此在第三次作业笔者重写了对拍器,代值进行计算来判断正确与否。
第三次作业
作业要求
实现简单多项式的格式判断和求导。其中多项式由项相加减组成,项是由因子相乘组成,因子包括幂函数,带符号整数,三角函数,表达式因子,其中表达式因子为一个表达式外面加括号,三角函数可以嵌套因子。
实现方法
- 读入:采用类似递归下降的思路,反复调用构造方法,直到剩余的项为幂函数或带符号整数,将表达式用ArrayList存储。
- 构建:将表达式从ArrayList构建成表达式数,叶节点全部为幂函数或带符号整数,分支节点为运算符。
- 求导:对表达式树进行DFS求导,得到求导后的表达式树。
- 优化:对表达式树进行可能的优化,如:1*x = x,0*x=0,1*2=2等。
代码规模
第三次作业的代码规模如下图。

类图
第三次作业类图如下,其中Poly是表达式类,Item是表达式项类,CalculateTree是表达式树类,Node是表达式树节点类。

复杂度分析
第三次作业的复杂度分析如下。
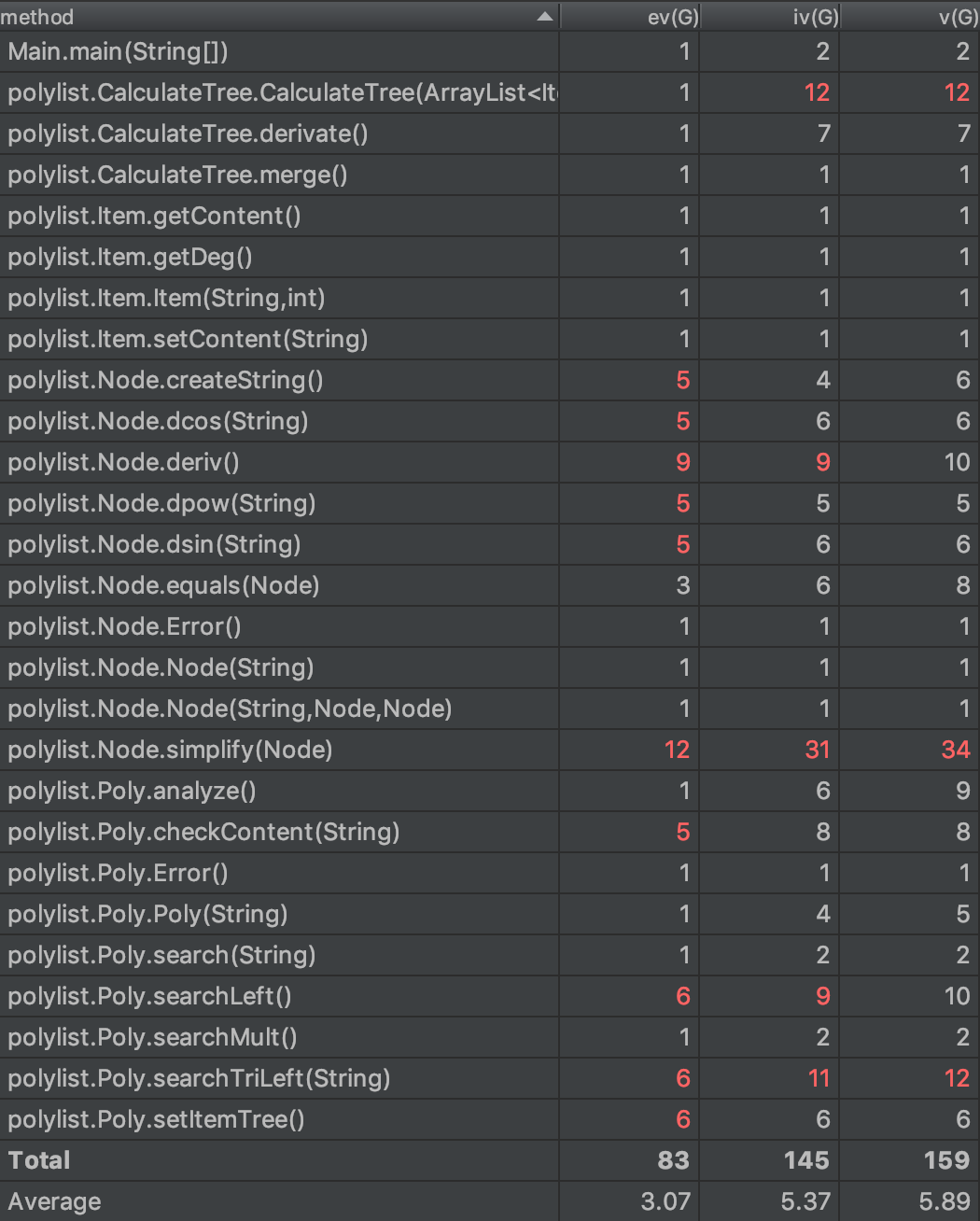
对于其中几个比较复杂的方法,分析如下:
- CalculateTree的构造方法是用双栈法构建表达式树,调用了很多其他方法,耦合性比较高。
- deriv求导函数是一个DFS遍历,复杂度较高。
- simplify函数是对表达式树进行优化,也是DFS的方法,而且里面有复杂的条件语句,所以复杂度很高。
结合三次作业的复杂度分析,仔细思考了可能的解决方法:
- 利用多态和继承,将每一类的因子建立类,并分别实现求导,化简,输出方法,可以有效避免都塞进一个类的复杂度爆表。
- 对于各种条件语句,可以多写几种方法,然后合并到总的方法中,这样一个方法只专注于处理一件事,就不会出现十分复杂的条件语句了。
Bug分析
公测
笔者的程序在公测中未出现正确性错误,但是也没有拿到性能分,原因可能是:
-
对多余括号的去除还没有做的很好,只是做了简单的优化。
-
公测数据都是精心构造,这样做过精心优化的同学能得到更短的输出。
互测
笔者的程序在互测中没有被发现Bug
笔者发现其他人3个Bug,分别是:
- 指数范围判断错误,题目要求小于等于10000,那位同学可能理解成了小于10000。
- 常数求导后没有输出结果。
- 求导后的式子不符合格式要求。
而其中前两个Bug是笔者用手动造的测试集发现的,这也说明了自动数据生成有时候并不好用,手动造的数据才更具有针对性。
测试方法
由于第三次代码较为复杂,所以采取完全黑箱测试,采用随机数生成带n层嵌套的项,并结合第二次作业的生成器,生成表达式。正确性验证是模拟评测机,采用sympy带入100个数计算,Wrong Format判定采用python的异常处理机制。
关于设计模式的思考
在第一单元的学习中,自我感觉对继承和接口方面的知识,以及对工厂模式还没有完全掌握,所以第三次作业没使用工厂模式。利用这周闲暇时间,又仔细研究了一下,感受到了工厂模式+借口的方便和强大。在之后的多线程学习中,进一步深化自己面向对象设计模式是必须的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号