python 用 pandas 实现数据透视表功能详解
透视表是一种可以对数据动态排布并且分类汇总的表格格式。对于熟练使用 excel 的伙伴来说,一定很是亲切!
pd.pivot_table() 语法:
pivot_table(data, # DataFrame
values=None, # 值
index=None, # 分类汇总依据
columns=None, # 列
aggfunc='mean', # 聚合函数
fill_value=None, # 对缺失值的填充
margins=False, # 是否启用总计行/列
dropna=True, # 删除缺失
margins_name='All' # 总计行/列的名称
)
1、销量数据的透视
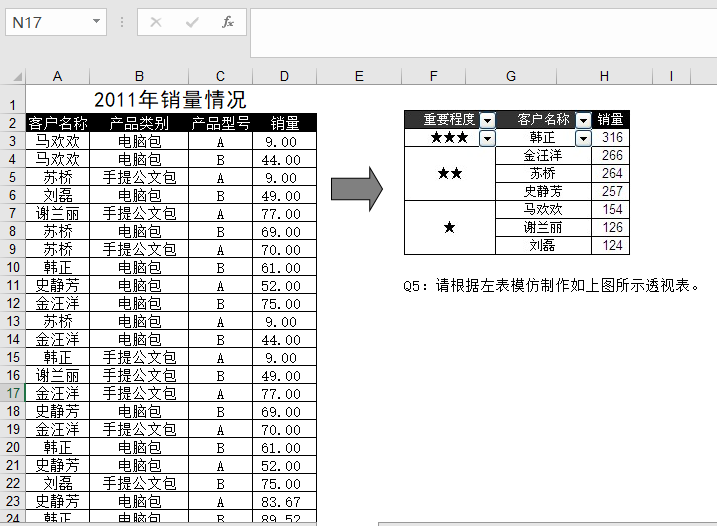
1.1 读入数据
import os
import numpy as np
import pandas as pd
file_name = os.path.join(path, 'Excel_test.xls')
df = pd.read_excel(io=file_name, # 工作簿路径
sheetname='透视表', # 工作表名称
skiprows=1, # 要忽略的行数
parse_cols='A:D' # 读入的列
)
df

1.2 数据透视
# 透视数据
df_p = df.pivot_table(index='客户名称', # 透视的行,分组依据
values='销量', # 值
aggfunc='sum' # 聚合函数
)
# 对透视表进行降序排列
df_p = df_p.sort_values(by='销量', # 排序依据
ascending=False # 是否升序排列
)
# 设置数值格式
df_p = df_p.round({'销量': 0}).astype('int')
# 添加列
ks = df_p['销量']//100
df_p['重要程度'] = ['★'*k for k in ks]
df_p
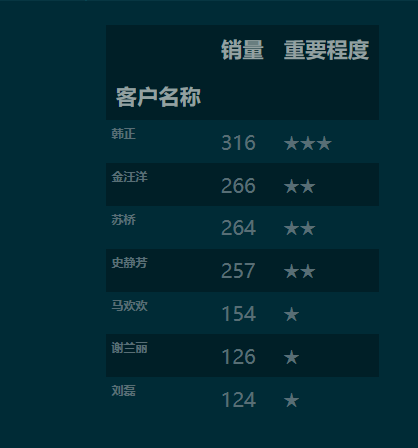
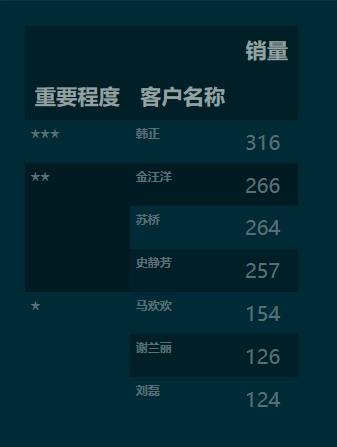
1.3 重新设置图示表的索引
df_p['客户名称'] = df_p.index
df_p.set_index(keys=['重要程度', '客户名称'])
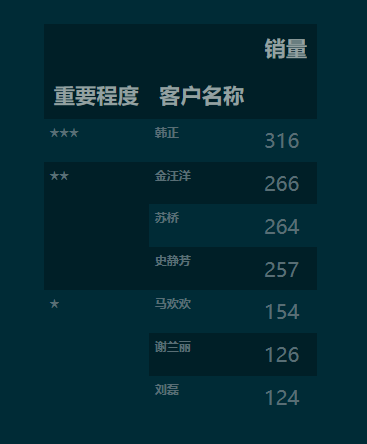
注:以上操作从理论和实践方面看都没什么问题,但模仿 excel 的痕迹浓重了些,更 python 的操作是用 groupby-applay 的方法。
2 用 分组聚合 实现数据透视
grouped = df.groupby(by='客户名称')
grouped['销量'].agg('sum')
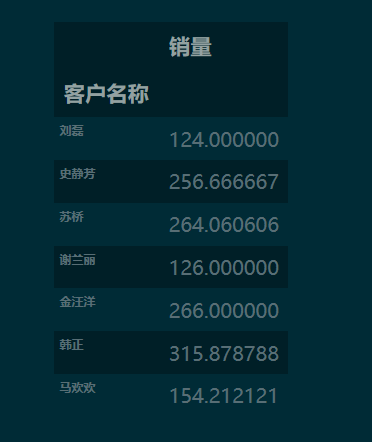
2.2 实现目标格式的透视表
# 分类汇总
df_p = df.groupby(by='客户名称' # 分类
).agg('sum' # 汇总
).sort_values(by='销量', ascending=False # 排序
).round({'销量': 0} # 设置精度
).astype('int') # 数据类型转换
# 添加列
ks = df_p['销量']//100
df_p['重要程度'] = ['★'*k for k in ks]
df_p['客户名称'] = df_p.index
# 层次索引
df_p.set_index(keys=['重要程度', '客户名称'])
软件信息:

非学无以广才,非志无以成学。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号