python 用 pd.Series.str.contains() 方法选取数据框中的特定列
一、读入数据
import os
import pandas as pd
path = r'E:\pyspace\数据集'
data_file = os.path.join(path, 'income_dist.csv')
df = pd.read_csv(open(data_file)) # 因为文件路径中有中文字符,用 open() 函数
二、基本信息
1、维度
df.shape
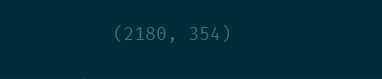 2180 行, 351 列
2180 行, 351 列
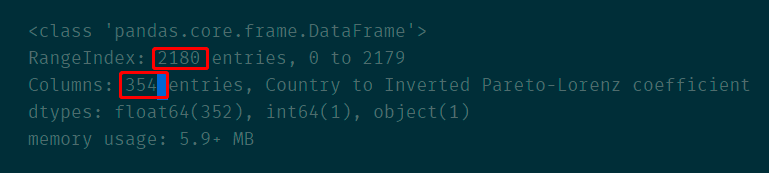
2、info
df.info()
3、表头
df.columns

三、筛选列
1、列名中含有 'Top' 的列
idx = df.columns.str.contains('Top') # 布尔索引
df.columns[idx]
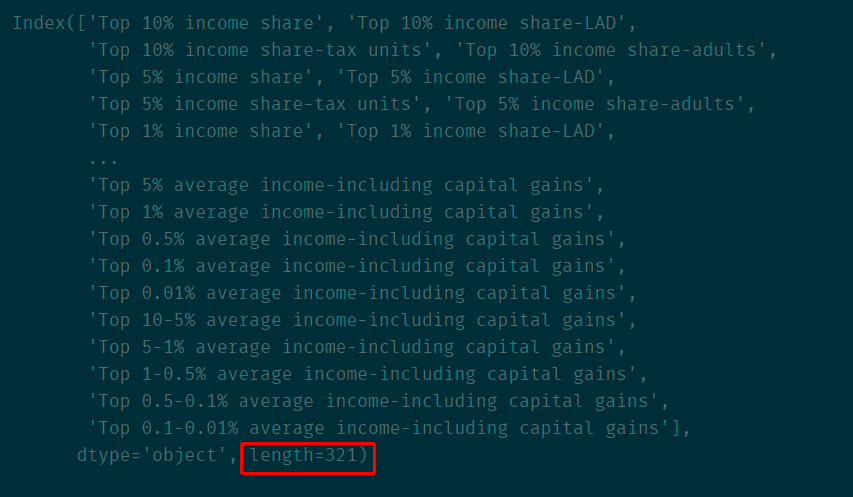
注:df[df.columns[idx]] 即可在源数据框中选取指定的列。
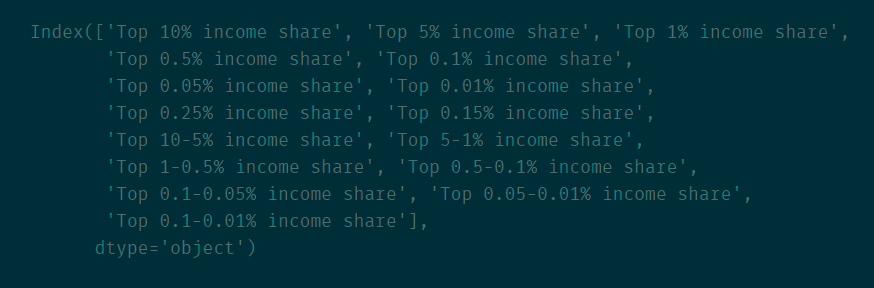
2、选取以 ‘Top’ 开始,以‘share’结尾的列名称
idx = df.columns.str.contains('^Top.+share$', regex=True)
df.columns[idx]
3、选取名称为 'Top 10% income share', 'Top 5% income share', 'Top 1% income share', 'Top 0.5% income share', 'Top 0.1% income share' 的列
idx = df.columns.str.contains('Top (10|5|1|0.5|0.1)%.+share$', regex=True)
df.columns[idx]

函数详解:
Series.str.contains(pat,case = True,flags = 0,na = nan,regex = True)
# 测试pattern或regex是否包含在Series或Index的字符串中。
# 返回布尔值系列或索引,具体取决于给定模式或正则表达式是否包含在系列或索引的字符串中。
参数
pat : str类型
字符序列或正则表达式。
case : bool,默认为True
如果为True,区分大小写。
flags : int,默认为0(无标志)
标志传递到re模块,例如re.IGNORECASE。
na : 默认NaN
填写缺失值的值。
regex : bool,默认为True
如果为True,则假定pat是正则表达式。
如果为False,则将pat视为文字字符串。
返回:
布尔值的Series或Index,指示给定模式是否包含在Series或Index的每个元素的字符串中。
非学无以广才,非志无以成学。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号