python 用 pymysql 执行 case when 实现分组统计
1、加载库、定义函数
import pandas as pd
import pymysql
def mycursor(db_name=None):
'''连接数据库,创建游标'''
config = dict(zip(['host', 'user', 'port', 'password'],
['192.168.137.155', 'shanger', 3306, '0123']))
config.update(database=db_name)
connection = pymysql.connect(**config)
cursor = connection.cursor()
return cursor
def use(db_name):
'''切换数据库,返回游标'''
return mycursor(db_name)
def query(sql):
'''以数据框形式返回查询据结果'''
cursor.execute(sql)
data = cursor.fetchall() # 以元组形式返回查询数据
header = [t[0] for t in cursor.description]
df = pd.DataFrame(list(data), columns=header) # pd.DataFrem 对列表具有更好的兼容性
return df
def select_all_from(table):
sql = f'select * from {table};'
return query(sql)
2、统计
cursor = use('sql123') # 切换数据库
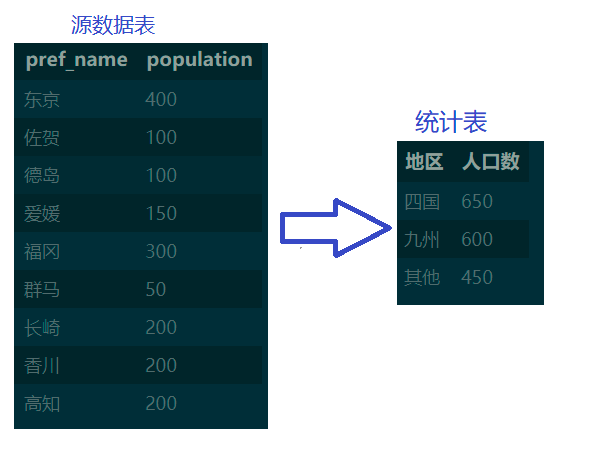
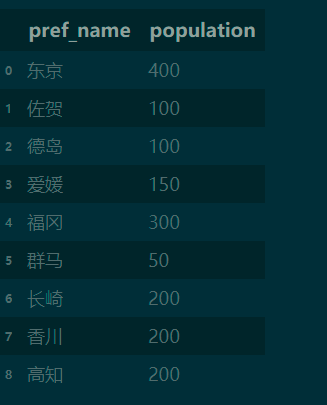
select_all_from('poptbl') # 查看所有记录
分组统计
sql = '''
select case pref_name
when '德岛' then '四国'
when '香川' then '四国'
when '爱媛' then '四国'
when '高知' then '四国'
when '福冈' then '九州'
when '佐贺' then '九州'
when '长崎' then '九州'
else '其他' end as 地区,
sum(population) as 人口数
from poptbl
group by 1;
'''
query(sql).sort_values(by='人口数', ascending=False)

非学无以广才,非志无以成学。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号