

Redis入门到放弃系列-redis数据类型
Redis数据类型?
Redis 提供一些常用的数据类型:Strings、Lists、Sets、Sorted sets、Hashes、Arrays、Bitmap、Streams
Strings(字符串)
Redis中的字符串类型是一比较简单的值类型,和Memcached的数据类型是一样的。
Redis中的key都字符串结构,我们在使用string类型时,其实就是将字符串(key)映射到另一个字符(value).
常用作一些字符串的业务内容缓存;当然,也可以将其它Object业务对像序列化为字符串之后保存。
字符串类型的常用操作命令:
set get mset mget incr
数据结构:
struct sdshdr{
//记录buf数组中已使用字节的数量
int len;
//记录buf数组中未使用的数量
int free;
//字节数组,用于保存字符串
char buf[];
}
注:Redis在内部存储string过程中为了提高性能,做了很多优化。并不是所有的string都是用sds数据结构保存。
| 数据结构 | 条件 |
|---|---|
| 整数 | 字符串长度小于21且能够转化为整数的字符串 |
| EmbeddedString | 字符串长度小于39的字符串(REDIS_ENCODING_EMBSTR_SIZE_LIMIT) |
| SDS | 其它情况,使用sds进行存储 |
Lists(列表)
Redis中的列表类型是简单的字符串列表,按照插入顺序排序,可以快速在列表头部或尾部插入元素。该类型类似Java中的LinkedList实现。
Redis Lists使用场景:热点数据列表、还可用作简单的生产-消费队列
Lists的常用操作命令:
rpush/lpush lrange rpop/lpop brpop/blpop
数据结构:
typedef struct listNode{
//前置节点
struct listNode *prev;
//后置节点
struct listNode *next;
//节点的值
struct value;
}


Sets(集合)
Redis中的Set是无序字符串集合,集合是通过哈希表实现的,提供了求交集、并集、差集等操作。
集合的常用操作命令:
sadd/smembers sinter spop sunionstore

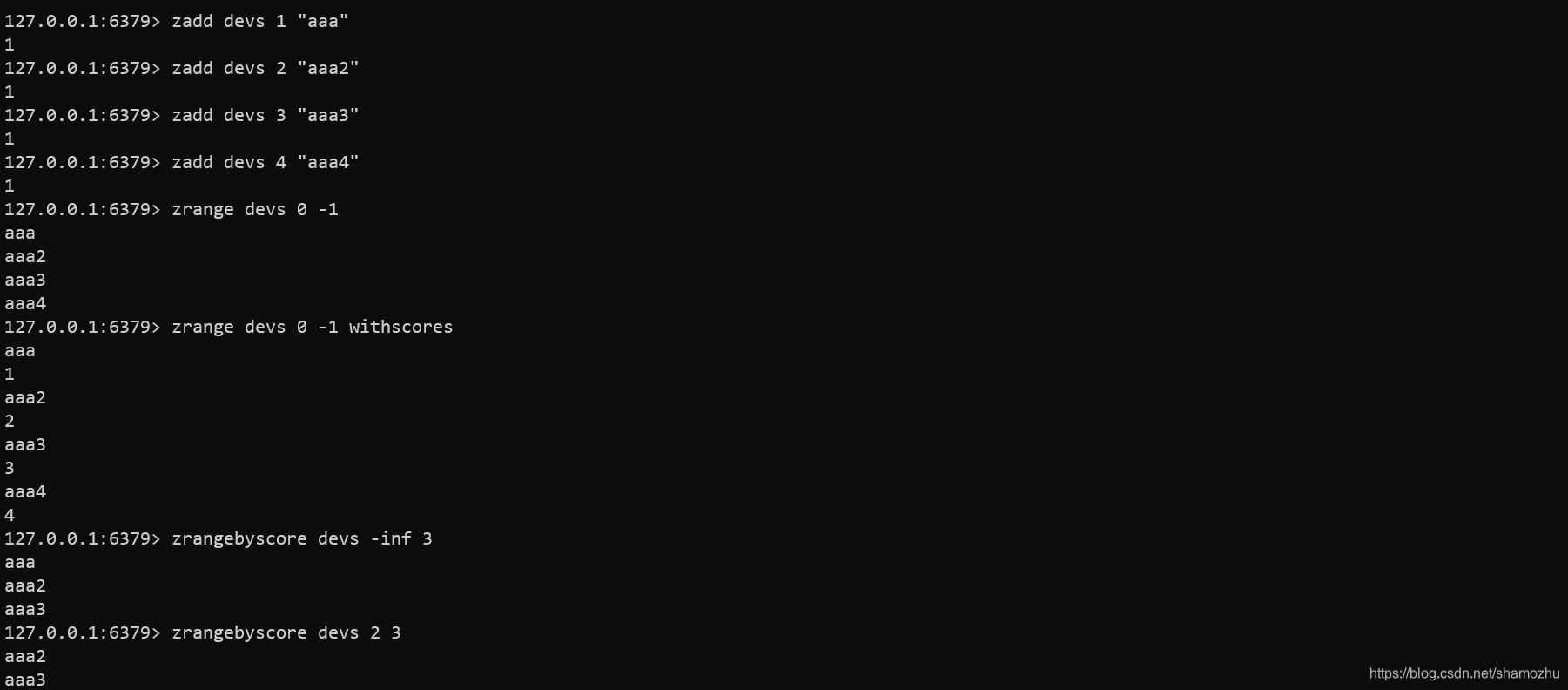
Sorted sets(有序集合)
Redis中的有序集合是无序集合与哈希的混合结构,并且不允许有重复的成员。有序集合中的每个元素都与一个float值的score关联。
有序集合中的元素与元素的score的大小一一对应。
常用操作命令:
zadd zrange zrevrange zrangebyscore
数据结构:
typedef struct zskiplistNode{
//后退指针
struct zskiplistNode *backward;
//分值
double score;
//成员对象
robj *obj;
//层
struct zskiplistLever{
//前进指针
struct zskiplistNode *forward;
//跨度
unsigned int span;
}lever[];
}
typedef struct zskiplist{
//表头节点跟表尾结点
struct zskiplistNode *header, *tail;
//表中节点的数量
unsigned long length;
//表中层数最大的节点的层数
int lever;
}
跳跃表,基于多指针有序链实现,可以看作多个有序链表。
与红黑树等平衡树相比,跳跃表具有以下优点:
- 插入速度非常快速,因为不需要进行旋转等操作来维持平衡性。
- 更容易实现。
- 支持无锁操作。
Hashes(字典)
Redis中的Hash类型是一种键值对集合(field->value),比较适合存放对象。
字典的常用操作命令:
hset/hget hmget/hmset
数据结构:
dictht是一个散列表结构,使用拉链法保存哈希冲突的dictEntry。
typedef struct dictht{
dictEntry **table; //哈希表数组
unsigned long size; //哈希表大小
unsigned long sizemask; //哈希表大小掩码,用于计算索引值
unsigned long used; //该哈希表已有节点的数量
}
typedef struct dictEntry{
//键
void *key;
//值
union{
void *val;
uint64_tu64;
int64_ts64;
}
struct dictEntry *next;
}
Redis的字典dict中包含两个哈希表dictht,这是为了方便进行rehash操作。在扩容时,将其中一个dictht上的键值对rehash到另一个dictht上面,完成之后释放空间并交换两个dictht的角色。
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
rehash操作并不是一次性完成、而是采用渐进式方式,目的是为了避免一次性执行过多的rehash操作给服务器带来负担。
渐进式rehash通过记录dict的rehashidx完成,它从0开始,然后没执行一次rehash例如在一次 rehash 中,要把 dict[0] rehash 到 dict[1],这一次会把 dict[0] 上 table[rehashidx] 的键值对 rehash 到 dict[1] 上,dict[0] 的 table[rehashidx] 指向 null,并令 rehashidx++。
在 rehash 期间,每次对字典执行添加、删除、查找或者更新操作时,都会执行一次渐进式 rehash。
采用渐进式rehash会导致字典中的数据分散在两个dictht中,因此对字典的操作也会在两个哈希表上进行。
例如查找时,先从ht[0]查找,没有再查找ht[1],添加时直接添加到ht[1]中。

Bitmap(位图)
Redis中的Bitmap不是具体的数据类型,其实就是byte数组,用二进制表示,只有0和1,最大优点之一,存储信息时提供极高的空间节省。
Bitmap实际上是在String类型上定义了一组位操作,最大长为为512M
常用操作命令:setbit/getbit bitop bitcount bitpos


 浙公网安备 33010602011771号
浙公网安备 33010602011771号