
Hadoop HA(高可用) 实操
1. HA 概述

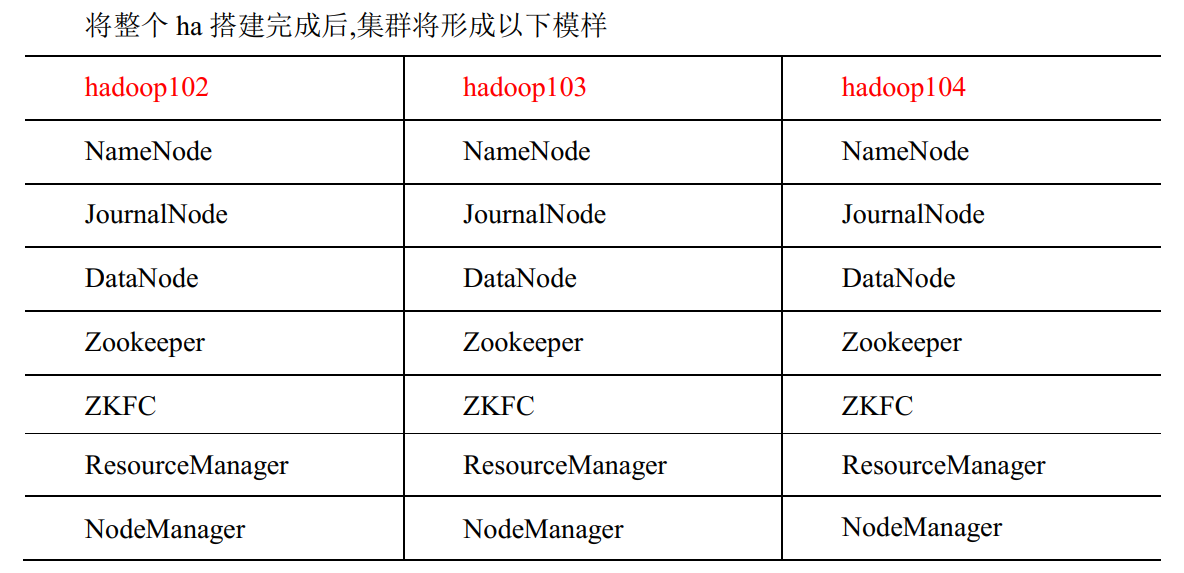
2. HDFS-HA 集群搭建
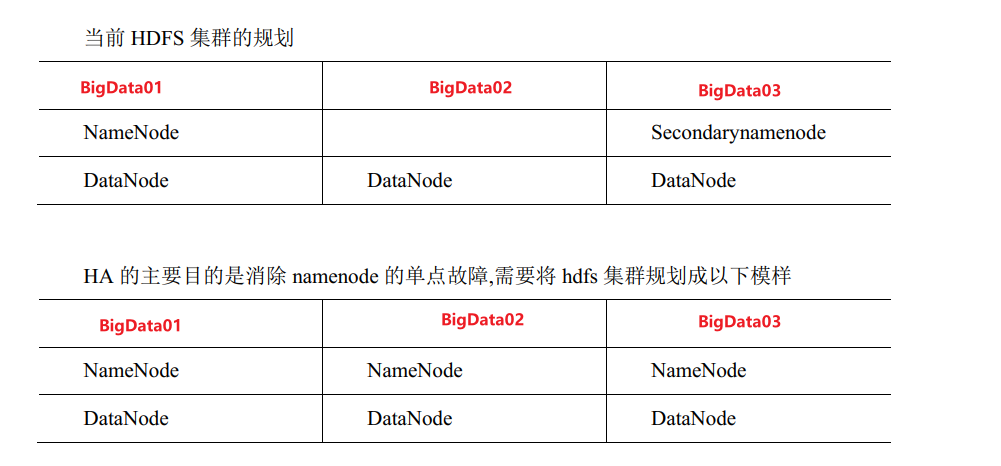
2.1 HDFS-HA 核心问题
1.如何保证三台NameNode数据一致?
a. Fsimage: 让一台nn生成数据, 让其他机器nn同步
b. Edits: 需要引进新的模块 JournalNode 来保证 edots文件的数据一致性
- 如何同时只有一台NN是active 的, 其他所有的是 standBy的
a. 手动分配
b. 自动分配
- 2NN 在 HA架构中并不存在, 定期合并 fsimage 和edits的活谁来干?
由standBy的NN来负责;
- 如果 NN真的发生了问题, 怎么让其他的NN 上位干活?
a. 手动故障转移;
b. 自动故障转移
3. HDFS-HA 手动模式
基础原材料: 一台已经建立完全分布式的Hadoop集群
3.1 集群规划

3.2 配置HDFS-HA 集群
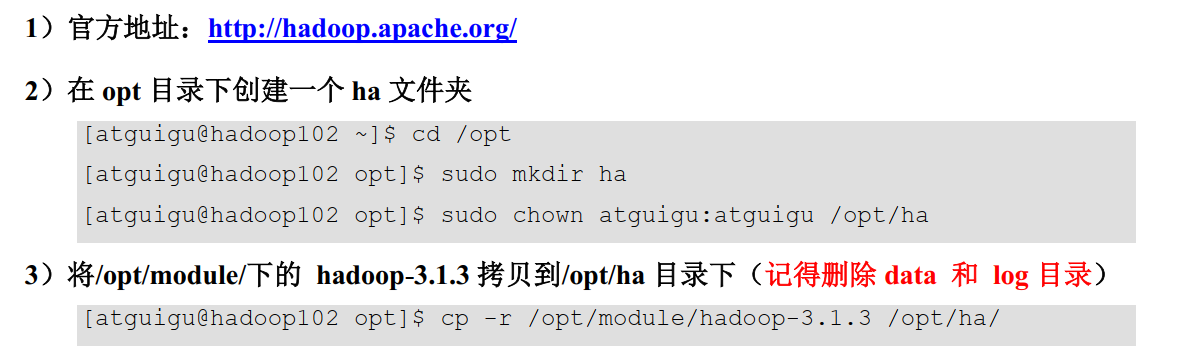
- 配置
core-site.xml
<!-- HADOOP HA 的相关配置 -->
<!-- 把多个NameNode的地址 组装成一个集群mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/HA/hadoop-3.1.3/data</value>
</property>
- 配置
hdfs-site.xml
<!-- NameNode 数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/name</value>
</property>
<!-- DataNode 数据存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/data</value>
</property>
<!-- JournalNode 数据存储目录 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>${hadoop.tmp.dir}/jn</value>
</property>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中 NameNode 节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2,nn3</value>
</property>
<!-- NameNode 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>bigdata01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>bigdata02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn3</name>
<value>bigdata03:9870</value>
</property>
<!-- 指定 NameNode 元数据在 fJournalNode 上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://bigdata01:8485;bigdata02:8485;bigdata03:8485/mycluster</value>
</property>
<!-- 访问代理类: client 用于确定哪个 NameNode 为 Active -->
<property>
<name>
dfs.client.failover.proxy.provider.mycluster
</name>
<value>
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyP
rovider
</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>
dfs.ha.fencing.methods
</name>
<value>
sshfence
</value>
</property>
<!-- 使用隔离机制时需要 ssh 秘钥登录 -->
<property>
<name>
dfs.ha.fencing.ssh.private-key-files
</name>
<value>
/home/atguigu/.ssh/id_rsa
</value>
</property>
- 向其他的节点分发HA文件夹
xsync ./HA
3.3 启动HDFS-HA 集群

运行情况
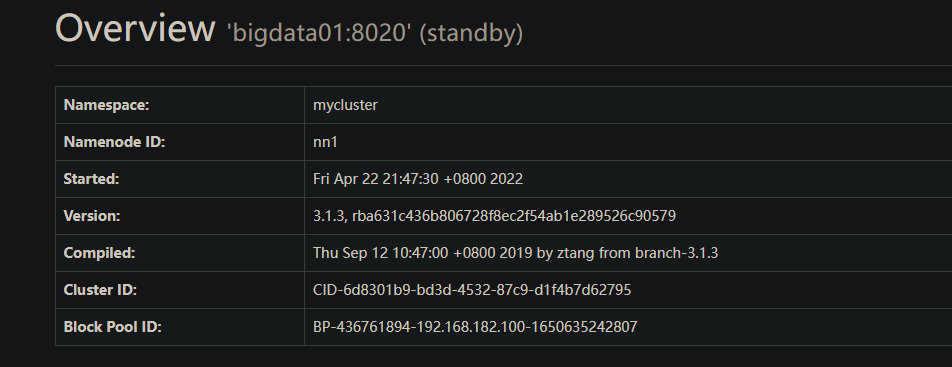
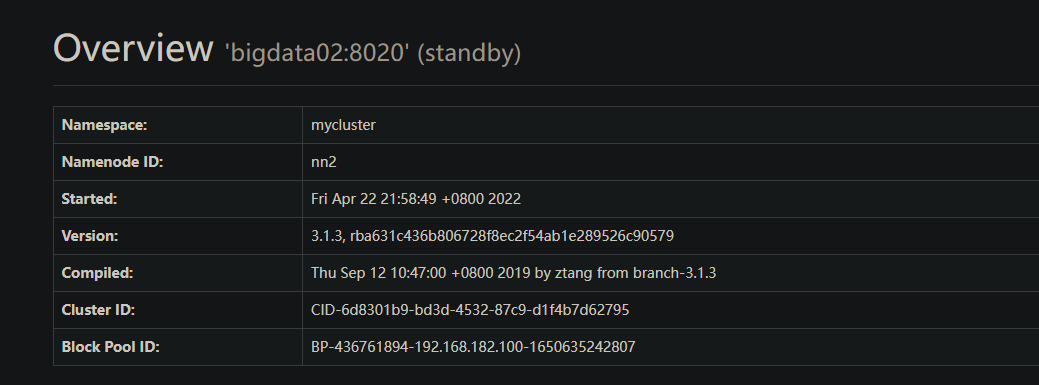
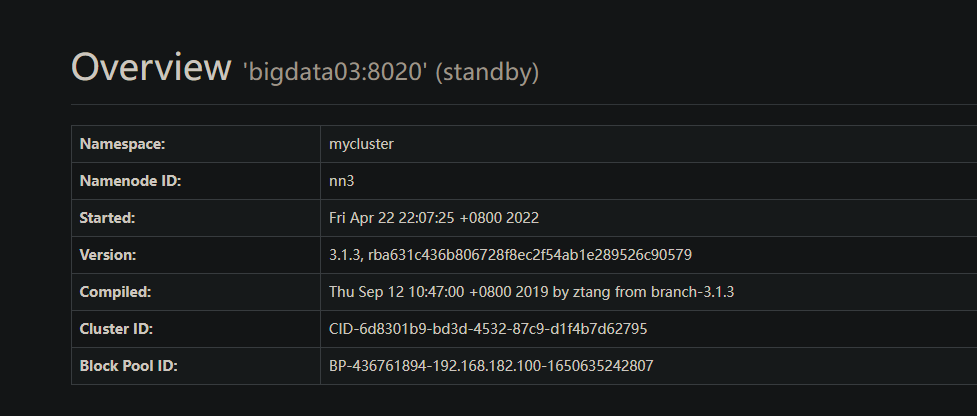

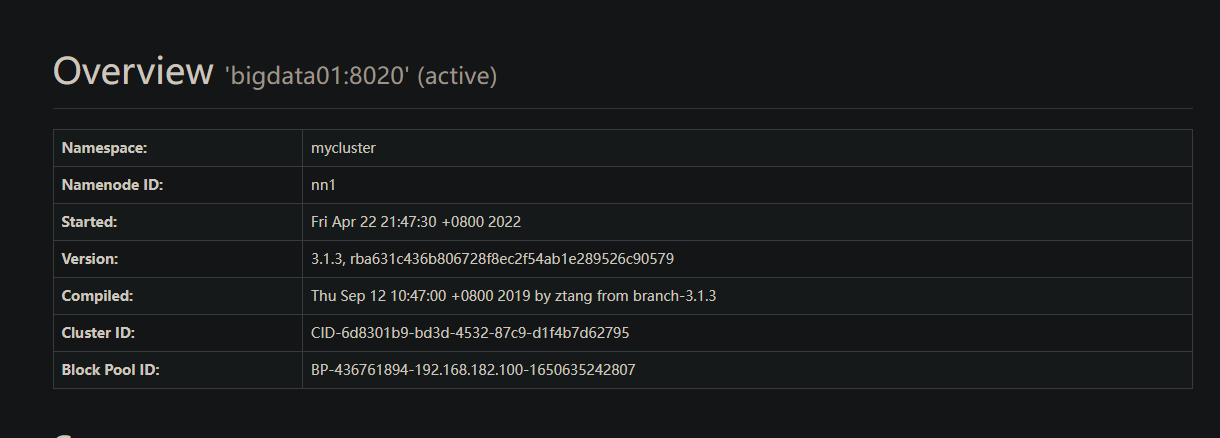
在手动模式中, 我们规定集群内的所有结点都是可以通信的条件下, 才能对集群中的某个节点设置为active状态, 主要是为了防止脑裂现象的产生.
4. HDFS-HA 自动模式
自动故障转移为 HDFS 部署增加了两个新组件: ZooKeeper 和 ZKFailoverController(ZKFC)进程,如图所示。 **ZooKeeper 是维护少量协调数据,通知客户端这些数据的改变和监视客户端故障的高可用服务。 **
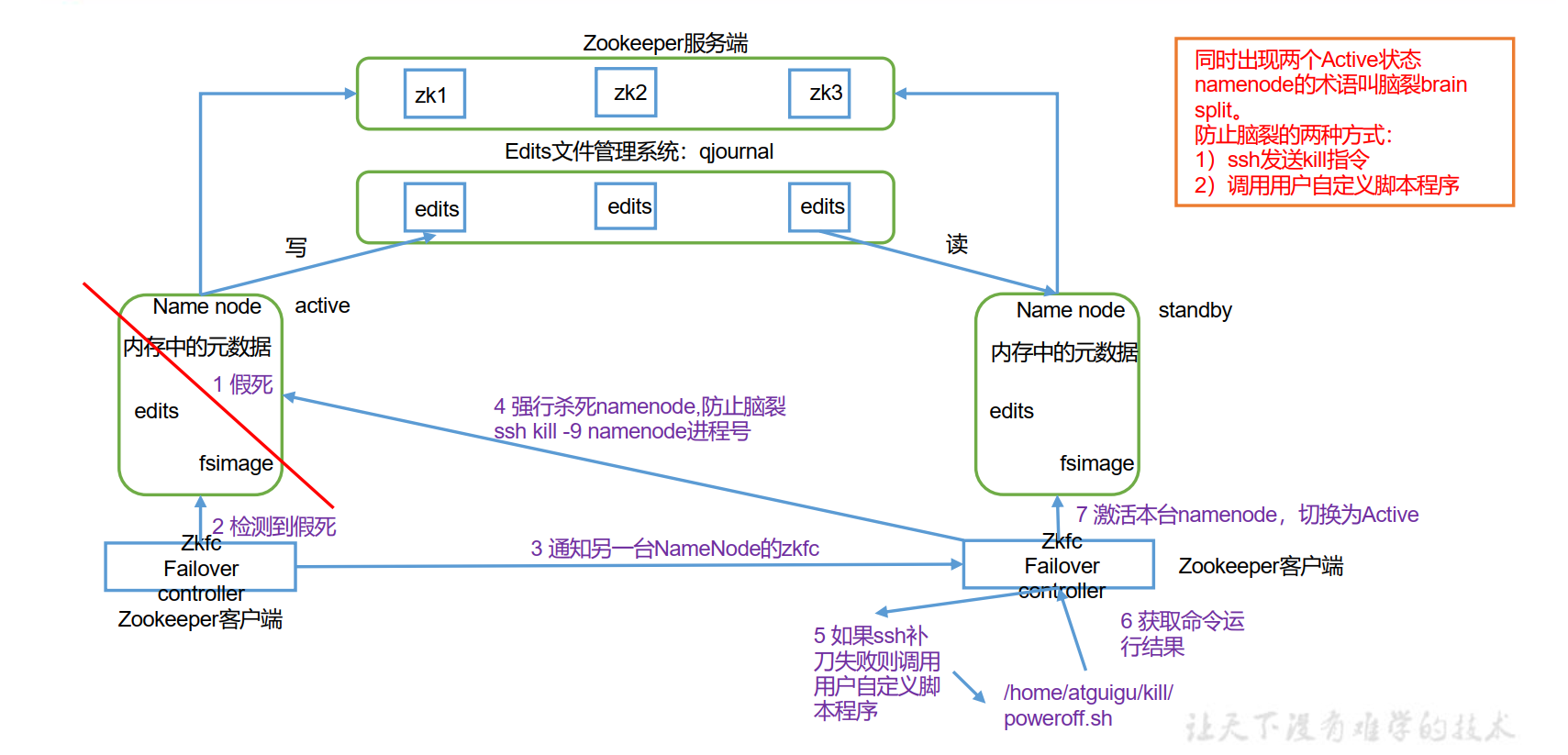
- 一个NameNode 对应一个ZKFC结点
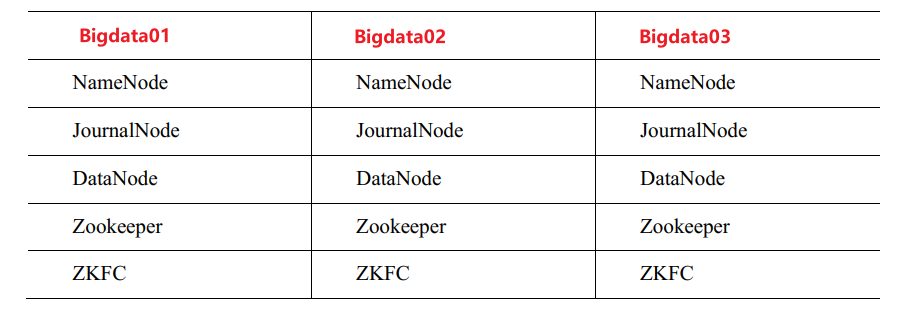
4.2 HDFS-HA 自动故障转移的集群规划
4.3 HDFS-HA 自动故障转移配置
1. hdfs-site.xml
<!-- 启用 nn 故障自动转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
2. core-site.xml
<!-- 指定 zkfc 要连接的 zkServer 地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>bigdata01:2181,bigdata02:2181,bigdata03:2181</value>
</property>
- 修改后分发所有的配置文件:
xsync /opt/HA/hadoop-3.1.3/etc/hadoop
3. 关闭HDFS服务, 然后启动Zookeeper, 启动 Zookeeper 以后, 然后再初始化 HA 在 Zookeeper 中状态:
[win10@bigdata01 ~]$ stop-dfs.sh
[win10@bigdata01 ~]$ zkServer.sh start
[win10@bigdata02 ~]$ zkServer.sh start
[win10@bigdata03 ~]$ zkServer.sh start
[win10@bigdata01 ~]$ hdfs zkfc -formatZK
4. 启动 HDFS 服务:
[win10@bigdata01 ~]$ start-dfs.sh
5. 可以去 zkCli.sh 客户端查看 Namenode 选举锁节点内容
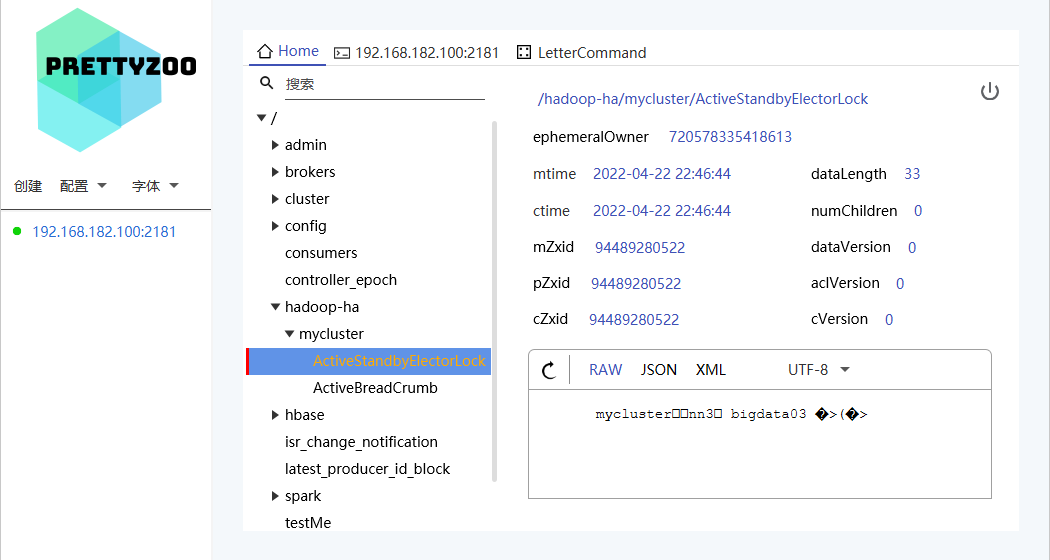
6. 验证
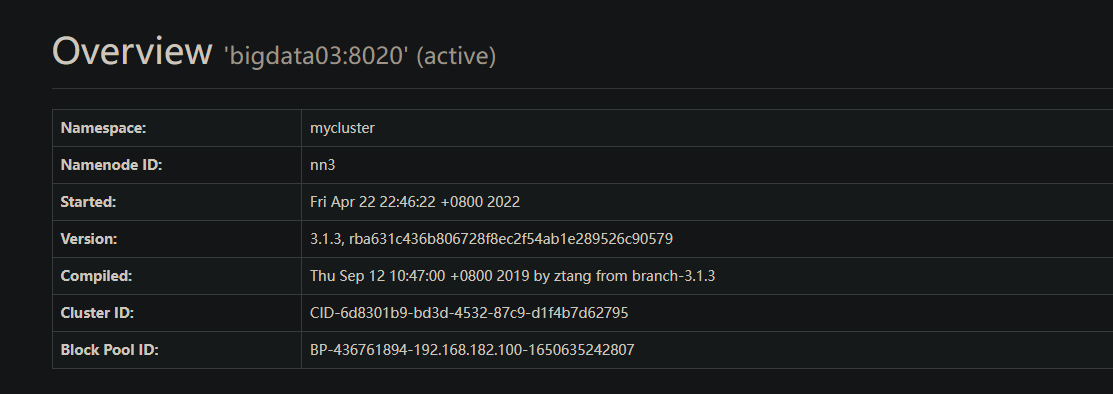
可能出现的Bug和解决方法:


二, Yarn-HA
2.1 Yarn-HA 工作机制
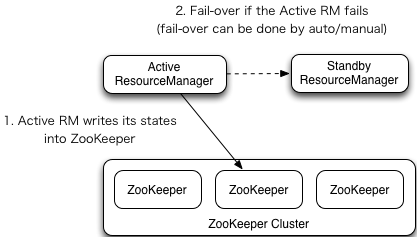
- 刚开始的时候, 我们可以启动多个ResourceManager, 先启动的就可以去ZK中注册一个临时结点, 后启动的也去注册但是发现结点已存在, 就只会对这个节点进行长轮询;
- Active状态的RM将他的状态写入到ZK中;
2.2 Yarn-HA 配置
2.2.1 集群规划

2.2.2 核心问题

2.2.3 配置文件
yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 配置YARN文件-->
<!-- 指定MR走shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager的主机名称-->
<!-- 注意: 这里resourceManager的默认端口为8088 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata02</value>
</property>
<!-- 环境变量的继承-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- 取消内存检查 -->
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
<description>Ratio between virtual memory to physical memory when setting memory limits for containers</description>
</property>
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集功能, 方便查看日志详细信息 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器的地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://bigdata01:19888/jobhistoryserver/logs</value>
</property>
<!-- 设置日志的保留时间为7天-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 启用 resourcemanager ha -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 声明两台 resourcemanager 的地址 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<!-- 指定 resourcemanager 的逻辑列表 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2,rm3
</value>
</property>
<!-- ========== rm1 的配置 ========== -->
<!-- 指定 rm1 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>bigdata01</value>
</property>
<!-- 指定 rm1 的 web 端地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>bigdata01:8088</value>
</property>
<!-- 指定 rm1 的内部通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>bigdata01:8032</value>
</property>
<!-- 指定 AM 向 rm1 申请资源的地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>bigdata01:8030</value>
</property>
<!-- 指定供 NM 连接的地址 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>bigdata01:8031</value>
</property>
<!-- ========== rm2 的配置 ========== -->
<!-- 指定 rm2 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>bigdata02</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>bigdata02:8088</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>bigdata02:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>bigdata02:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>bigdata02:8031</value>
</property>
<!-- ========== rm3 的配置 ========== -->
<!-- 指定 rm1 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm3</name>
<value>bigdata03</value>
</property>
<!-- 指定 rm1 的 web 端地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm3</name>
<value>bigdata03:8088</value>
</property>
<!-- 指定 rm1 的内部通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm3</name>
<value>bigdata03:8032</value>
</property>
<!-- 指定 AM 向 rm1 申请资源的地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm3</name>
<value>bigdata03:8030</value>
</property>
<!-- 指定供 NM 连接的地址 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm3</name>
<value>bigdata03:8031</value>
</property>
<!-- 指定 zookeeper 集群的地址 -->
<property>
<name>hadoop.zk.address </name>
<value>bigdata01:2181,bigdata02:2181,bigdata03:2181</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 指定 resourcemanager 的状态信息存储在 zookeeper 集群 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
- 分发配置:
xsync /opt/HA/hadoop-1.3.1/etc/hadoop/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号