一、操作系统是怎么组织进程的
1. 什么是进程
进程是表示资源分配的基本单位,又是调度运行的基本单位。例如,用户运行自己的程序,系统就创建一个进程,并为它分配资源,包括各种表格、内存空间、磁盘空间、I/O设备等。然后,把该进程放人进程的就绪队列。进程调度程序选中它,为它分配CPU以及其它有关资源,该进程才真正运行。所以,进程是系统中的并发执行的单位。
在Linux中,每个进程在创建时都会被分配一个数据结构,称为进程控制块(Process Control Block,简称PCB)在linux中具体实现是 task_struct数据结构,它记录了一下几个类型的信息:所有进程的PCB都存放在内核空间中。PCB中最重要的信息就是进程PID,内核通过这个PID来唯一标识一个进程。PID可以循环使用,最大值是32768。init进程的pid为1,其他进程都是init进程的后代。
下面这是一个数据结构:
struct task_struct {
/*
* offsets of these are hardcoded elsewhere - touch with care
*/
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */ //进程当前的状态
unsigned long flags; /* per process flags, defined below */ //反应进程状态的信息,但不是运行状态,定义见下
int sigpending; //进程收到了信号,但尚未处理
mm_segment_t addr_limit; /* thread address space: //虚存地址上限
0-0xBFFFFFFF for user-thead
0-0xFFFFFFFF for kernel-thread
*/
struct exec_domain *exec_domain;
volatile long need_resched; //与进程调度有关表示用户从系统空间按返回用户空间要执行的一次调度
unsigned long ptrace;
int lock_depth; /* Lock depth */
/*
* offset 32 begins here on 32-bit platforms. We keep
* all fields in a single cacheline that are needed for
* the goodness() loop in schedule().
*/
long counter; //与进程调度相关
long nice;
unsigned long policy; //实用于本进程的调度政策
struct mm_struct *mm;
int processor;
/*
* cpus_runnable is ~0 if the process is not running on any
* CPU. It's (1 << cpu) if it's running on a CPU. This mask
* is updated under the runqueue lock.
*
* To determine whether a process might run on a CPU, this
* mask is AND-ed with cpus_allowed.
*/
unsigned long cpus_runnable, cpus_allowed;
/*
* (only the 'next' pointer fits into the cacheline, but
* that's just fine.)
*/
struct list_head run_list;
unsigned long sleep_time;
struct task_struct *next_task, *prev_task; //内核会对每一个进程做点什么事情的时候,常常需要将其连成一个队列,这2个指针用于这个目的
struct mm_struct *active_mm;
struct list_head local_pages;
unsigned int allocation_order, nr_local_pages;
/* task state */
struct linux_binfmt *binfmt;//应用文件格式
int exit_code, exit_signal;
int pdeath_signal; /* The signal sent when the parent dies */
/* ??? */
unsigned long personality; //进程的个性化信息,详细见下
int did_exec:1;
unsigned task_dumpable:1;
pid_t pid; //进程号
pid_t pgrp;
pid_t tty_old_pgrp;
pid_t session;
pid_t tgid;
/* boolean value for session group leader */
int leader;
/*
* pointers to (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->p_pptr->pid)
*/
struct task_struct *p_opptr, *p_pptr, *p_cptr, *p_ysptr, *p_osptr; //用于族谱信息的,例如p_opptr指向父进程
struct list_head thread_group;
/* PID hash table linkage. */
struct task_struct *pidhash_next;
struct task_struct **pidhash_pprev; //pid是随机分配的,我们常常使用kill pid想进程发送信号(大部分人认为是杀死进程,其实这是个发送信号的指令,默认的参数为杀死。如果想暂停某进程,只需kill STOP 进程的PID),这里可以看到根据pid寻找进程的操作是经常被使用的,而pid又是随机分配,于是这里边用这2个指针指向一个杂凑数组,数组是按照杂凑的算法,以pid为关键字建立,方便根据pid来寻找task_struct
wait_queue_head_t wait_chldexit; /* for wait4() */
struct completion *vfork_done; /* for vfork() */
unsigned long rt_priority; //优先级
unsigned long it_real_value, it_prof_value, it_virt_value;
unsigned long it_real_incr, it_prof_incr, it_virt_incr;
struct timer_list real_timer;
struct tms times; //运行时间的总汇
unsigned long start_time;
long per_cpu_utime[NR_CPUS], per_cpu_stime[NR_CPUS]; //在多个处理器上运行于系统空间和用户空间的时间
/* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */
unsigned long min_flt, maj_flt, nswap, cmin_flt, cmaj_flt, cnswap;//发生页面异常的次数和换入换出的次数
int swappable:1;
/* process credentials */
uid_t uid,euid,suid,fsuid;
gid_t gid,egid,sgid,fsgid; //与文件权限有关的
int ngroups;
gid_t groups[NGROUPS];
kernel_cap_t cap_effective, cap_inheritable, cap_permitted; //权限,比如该进程是否有权限从新引导系统,这里是大概介绍
int keep_capabilities:1;
struct user_struct *user; //指向该进程拥有的用户
/* limits */
struct rlimit rlim[RLIM_NLIMITS]; //进程对各种资源使用数量的限制,详细见下
unsigned short used_math;
char comm[16];
/* file system info */
int link_count, total_link_count;
struct tty_struct *tty; /* NULL if no tty */
unsigned int locks; /* How many file locks are being held */
/* ipc stuff */
struct sem_undo *semundo;
struct sem_queue *semsleeping;
/* CPU-specific state of this task */
struct thread_struct thread;
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
/* namespace */
struct namespace *namespace;
/* signal handlers */
spinlock_t sigmask_lock; /* Protects signal and blocked */
struct signal_struct *sig;
sigset_t blocked;
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
int (*notifier)(void *priv);
void *notifier_data;
sigset_t *notifier_mask;
/* Thread group tracking */
u32 parent_exec_id;
u32 self_exec_id;
/* Protection of (de-)allocation: mm, files, fs, tty */
spinlock_t alloc_lock;
/* journalling filesystem info */
void *journal_info;
};
#define TASK_RUNNING 0 //不是表示正在运行,而是表示可以被调用
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define TASK_ZOMBIE 4
#define TASK_STOPPED 8 //对应于task_struct中的state,进程运行状态
//对应task_struct的flag
#define PF_ALIGNWARN 0x00000001 /* Print alignment warning msgs */
/* Not implemented yet, only for 486*/
#define PF_STARTING 0x00000002 /* being created */
#define PF_EXITING 0x00000004 /* getting shut down */
#define PF_FORKNOEXEC 0x00000040 /* forked but didn't exec */
#define PF_SUPERPRIV 0x00000100 /* used super-user privileges */
#define PF_DUMPCORE 0x00000200 /* dumped core */
#define PF_SIGNALED 0x00000400 /* killed by a signal */
#define PF_MEMALLOC 0x00000800 /* Allocating memory */
#define PF_MEMDIE 0x00001000 /* Killed for out-of-memory */
#define PF_FREE_PAGES 0x00002000 /* per process page freeing */
#define PF_NOIO 0x00004000 /* avoid generating further I/O */
#define PF_FSTRANS 0x00008000 /* inside a filesystem transaction */
#define PF_USEDFPU 0x00100000 /* task used FPU this quantum (SMP) */
//进程的个性化信息
enum {
MMAP_PAGE_ZERO = 0x0100000,
ADDR_LIMIT_32BIT = 0x0800000,
SHORT_INODE = 0x1000000,
WHOLE_SECONDS = 0x2000000,
STICKY_TIMEOUTS = 0x4000000,
ADDR_LIMIT_3GB = 0x8000000,
};
/*
* Personality types.
*
* These go in the low byte. Avoid using the top bit, it will
* conflict with error returns.
*/
enum {
PER_LINUX = 0x0000,
PER_LINUX_32BIT = 0x0000 | ADDR_LIMIT_32BIT,
PER_SVR4 = 0x0001 | STICKY_TIMEOUTS | MMAP_PAGE_ZERO,
PER_SVR3 = 0x0002 | STICKY_TIMEOUTS | SHORT_INODE,
PER_SCOSVR3 = 0x0003 | STICKY_TIMEOUTS |
WHOLE_SECONDS | SHORT_INODE,
PER_OSR5 = 0x0003 | STICKY_TIMEOUTS | WHOLE_SECONDS,
PER_WYSEV386 = 0x0004 | STICKY_TIMEOUTS | SHORT_INODE,
PER_ISCR4 = 0x0005 | STICKY_TIMEOUTS,
PER_BSD = 0x0006,
PER_SUNOS = 0x0006 | STICKY_TIMEOUTS,
PER_XENIX = 0x0007 | STICKY_TIMEOUTS | SHORT_INODE,
PER_LINUX32 = 0x0008,
PER_LINUX32_3GB = 0x0008 | ADDR_LIMIT_3GB,
PER_IRIX32 = 0x0009 | STICKY_TIMEOUTS,/* IRIX5 32-bit */
PER_IRIXN32 = 0x000a | STICKY_TIMEOUTS,/* IRIX6 new 32-bit */
PER_IRIX64 = 0x000b | STICKY_TIMEOUTS,/* IRIX6 64-bit */
PER_RISCOS = 0x000c,
PER_SOLARIS = 0x000d | STICKY_TIMEOUTS,
PER_UW7 = 0x000e | STICKY_TIMEOUTS | MMAP_PAGE_ZERO,
PER_HPUX = 0x000f,
PER_OSF4 = 0x0010, /* OSF/1 v4 */
PER_MASK = 0x00ff,
};
//进程资源的限制,对应task_struct中的struct rlimit rlim[RLIM_NLIMITS],RLIM_NLIMITS的值是11,代表11项资源,分别是
#define RLIMIT_CPU 0 /* CPU time in ms */
#define RLIMIT_FSIZE 1 /* Maximum filesize */
#define RLIMIT_DATA 2 /* max data size */
#define RLIMIT_STACK 3 /* max stack size */
#define RLIMIT_CORE 4 /* max core file size */
#define RLIMIT_RSS 5 /* max resident set size */
#define RLIMIT_NPROC 6 /* max number of processes */
#define RLIMIT_NOFILE 7 /* max number of open files */
#define RLIMIT_MEMLOCK 8 /* max locked-in-memory address space */
#define RLIMIT_AS 9 /* address space limit */
#define RLIMIT_LOCKS 10 /* maximum file locks held */
除了进程控制块(PCB)以外,每个进程都有独立的内核堆栈(8k),一个进程描述符结构,这些数据都作为进程的控制信息储存在内核空间中;而进程的用户空间主要存储代码和数据。
2.进程的创建
进程是通过调用fork(),vfork()和clone()系统函数创建新进程。在内核中,它们都是调用do_fork实现的。传统的fork函数直接把父进程的所有资源复制给子进程。而Linux的fork()使用写时拷贝页实现,也就是说,父进程和子进程共享同一个资源拷贝,只有当数据发生改变时,数据才会发生复制。通常的情况,子进程创建后会立即调用exec(),这样就避免复制父进程的全部资源。
三者的区别如下:
fork():父进程的所有数据结构都会复制一份给子进程(写时拷贝页)。
vfork():只复制task_struct和内核堆栈,所以生成的只是父进程的一个线程(无独立的用户空间)。
clone():功能强大,带了许多参数。::clone()可以让你有选择性的继承父进程的资源,既可以选择像vfork()一样和父进程共享一个虚拟空间,从而使创造的是线程,也可以不和父进程共享,甚至可以选择创造出来的进程和父进程不再是父子关系,而是兄弟关系。
3. 进程的撤销
进程通过调用exit()退出执行,这个函数会终结进程并释放所有的资源。父进程可以通过wait4()查询子进程是否终结。进程退出执行后处于僵死状态,直到它的父进程调用wait()或者waitpid()为止。父进程退出时,内核会指定线程组的其他进程或者init进程作为其子进程的新父进程。当进程接收到一个不能处理或忽视的信号时,或当在内核态产生一个不可恢复的CPU异常而内核此时正代表该进程在运行,内核可以强迫进程终止。
4. 进程管理
内核把进程信息存放在叫做任务队列(task list)的双向循环链表中(内核空间)。链表中的每一项都是类型为task_struct,称为进程描述符结构(process descriptor),包含了一个具体进程的所有信息,包括打开的文件,进程的地址空间,挂起的信号,进程的状态等。
Linux通过slab分配器分配task_struct,这样能达到对象复用和缓存着色(通过预先分配和重复使用task_struct,可以避免动态分配和释放所带来的资源消耗)。
内核把所有处于TASK_RUNNING状态的进程组织成一个可运行双向循环队列。调度函数通过扫描整个可运行队列,取得最值得执行的进程投入执行。避免扫描所有进程,提高调度效率。
5. 进程的内核堆栈
Linux为每个进程分配一个8KB大小的内存区域,用于存放该进程两个不同的数据结构:thread_info和进程的内核堆栈。
进程处于内核态时使用不同于用户态堆栈,内核控制路径所用的堆栈很少,因此对栈和描述符来说,8KB足够了。
二、进程状态如何转换(给出进程状态转换图)
1)Linux最基本的进程状态有三种:运行态、就绪态和阻塞态(或等待态);这三种状态之间有四种可能的转换关系:运行态->阻塞态、运行态->就绪态、就绪态->运行态和阻塞态->就绪态,如图所示:
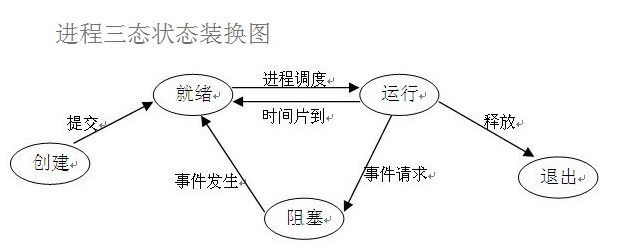
2)为了管理上的方便,将就绪态和运行态合并为一个状态—可运行态,再包括其它方面的一些改变,将进程状态划分为:可运行态、睡眠(或等待)态(分为深度睡眠态和浅度睡眠态)、暂停状态和僵死状态。
以下是LINUX进程间状态转换和内核调用图解

◆运行状态(TASK_RUNNING)
当进程正在被CPU执行,或已经准备就绪随时可由调度程序执行,则称该进程为处于运行状态(running)。进程可以在内核态运行,也可以在用户态运行。当系统资源已经可用时,进程就被唤醒而进入准备运行状态,该状态称为就绪态。这些状态(图中中间一列)在内核中表示方法相同,都被成为处于TASK_RUNNING状态。
◆可中断睡眠状态(TASK_INTERRUPTIBLE)
当进程处于可中断等待状态时,系统不会调度该进行执行。当系统产生一个中断或者释放了进程正在等待的资源,或者进程收到一个信号,都可以唤醒进程转换到就绪状态(运行状态)。
◆暂停状态(TASK_STOPPED)
当进程收到信号SIGSTOP、SIGTSTP、SIGTTIN或SIGTTOU时就会进入暂停状态。可向其发送SIGCONT信号让进程转换到可运行状态。
◆僵死状态(TASK_ZOMBIE)
当进程已停止运行,但其父进程还没有询问其状态时,则称该进程处于僵死状态。
◆不可中断睡眠状态(TASK_UNINTERRUPTIBLE)
与可中断睡眠状态类似。但处于该状态的进程只有被使用wake_up()函数明确唤醒时才能转换到可运行的就绪状态。
当一个进程的运行时间片用完,系统就会使用调度程序强制切换到其它的进程去执行。另外,如果进程在内核态执行时需要等待系统的某个资源,此时该进程就会调用sleep_on()或sleep_on_interruptible()自愿地放弃CPU的使用权,而让调度程序去执行其它进程。进程则进入睡眠状态(TASK_UNINTERRUPTIBLE或TASK_INTERRUPTIBLE)。
只有当进程从“内核运行态”转移到“睡眠状态”时,内核才会进行进程切换操作。在内核态下运行的进程不能被其它进程抢占,而且一个进程不能改变另一个进程的状态。为了避免进程切换时造成内核数据错误,内核在执行临界区代码时会禁止一切中断。
三、进程是如何调度的
1、进程调度信息
调度程序利用这部分信息决定系统中哪个进程最应该运行,并结合进程的状态信息保证系统运转的公平和高效。这一部分信息通常包括进程的类别(普通进程还是实时进程)、进程的优先级等等。如表1所示:
表1 进程调度信息
|
域名 |
含义 |
|
need_resched |
调度标志 |
|
Nice |
静态优先级 |
|
Counter |
动态优先级 |
|
Policy |
调度策略 |
|
rt_priority |
实时优先级 |
当need_resched被设置时,在“下一次的调度机会”就调用调度程序schedule()。 counter代表进程剩余的时间片,是进程调度的主要依据,也可以说是进程的动态优先级,因为这个值在不断地减少;nice是进程的静态优先级,同时也代表进程的时间片,用于对counter赋值,可以用nice()系统调用改变这个值;policy是适用于该进程的调度策略,实时进程和普通进程的调度策略是不同的;rt_priority只对实时进程有意义,它是实时进程调度的依据。
2、进程的调度策略有三种,如表2所示。
表2 进程调度的策略
|
名称 |
解释 |
适用范围 |
|
SCHED_OTHER |
其他调度 |
普通进程 |
|
SCHED_FIFO |
先来先服务调度 |
实时进程 |
|
SCHED_RR |
时间片轮转调度 |
只有root用户能通过sched_setscheduler()系统调用来改变调度策略。
实时进程将得到优先调用,实时进程根据实时优先级决定调度权值,分时进程则通过nice和counter值决定权值,nice越小,counter越大,被调度的概率越大,也就是曾经使用了cpu最少的进程将会得到优先调度。
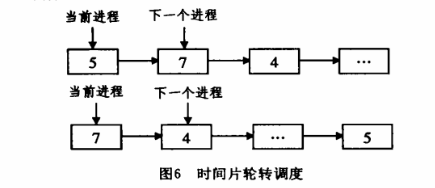
1)SCHED_OTHER:传统的Unix调度,时间片轮转——这不是一个实时进程,在分时系统中,出于人机交互的考虑,系统每个进程依次地按轮转的方式执行,这就是时间片轮转调度。系统将所有的可运行任务按先来先服务的原则,排成一个队列,每次调度时把CPU分配给队列的首进程,一个时间片之后,系统会运行调度程序,停止该进程的执行,并将其放入队列末尾,系统再次选择队列首进程,令其执行一个时间片。这样,进程在一个给定的时间内均可以获得一个时间片的执行时间。整个过程如图6所示。
2) SCHED_FIFO; 实时进程,遵守POSIX.1b 标准的FIFO(先进先出)调度.SCHED_FIFO 进程会始终拥有CPU,
只有更高优先级的进程出现或1/O阻塞,进程明确放弃CPU后才会换出,这种调度算法可用于某些实时性要求不高的实时系统中。
3) SCHED_RR: 实时进程,遵守POSIX.1b 的RR(rou nd- robin )调 度。 除 了 时 间 片 的 限 制, 它 和 SCI IED_ FIFO完全相同,SCHED_RR 进程在时间片用完后,进程保持rt-priority,且被移到进程列表的最后.
4) Policy 还有一个SCHED_YIELD的位集,这和调度策略无关,进程在明确交出CPU的控制权时,就设定该位。
3、Linux 进往调度算法
进程调度关键的函数是kernel/sched.c 中的schedule 和goodness,在这里不必详细分析函数的执行流程,而只是简单介绍其实现的思想。调度过程是这样的:
1) 遍历任务队列,找到最值得(goodness)运行的任务;
schedule 函数中,在task queue,bottom half 等处理完之后,就要对任务队列进行处理,如Round Robin调度策略下的任务移动、任务删除等。这时,中断上锁,保证不会有新任务插入到任务队列时造成混乱。
进程的缺省调度算法是SCHED._OTHER,即时间片轮转,在这种调度算法下,进程调度的依据就是它所使用的时间片。内核代码中它的实现并不那么明显。进程的时间片是由task-stuct 成员counter 决定的,而counter 的变化是在kernel/sched.c 中的update- process-times 函数中,它会将counter 的值减少从上次时钟底半运行以来经过的tick(实际是时钟的上半部分中的lost-tick数)。当counter 减少为小于0时,就需要重新调度了,这一点在update-process-times 中很明确.正如我们在前面提到的,update-process-times 在时钟中断的底半执行,这样,时钟系统就和进程调度相互作用了。
goodness函数是调度的依据,它的工作比较简单:如果调度策略是实时调度(SCHED_FIFO 和SCHED_RR),则简单地给weight 赋一个与rt.priority 相关的且很大的值(实际代码是1000+rt priority),如图7所示,这样就与非实时进程区分开了;如果是一般进程(SCHED_OTHER),将进程的counter值(一般来说,不会大于20)赋给weight 即可.结合前面调度策略的说明,我们可以印证:实时进程的执行总优先于非实时进程;在SCHED_FIFO策略下,则尽可能地运行最高优先级的进程,且尽可能地占用CPU的资源.

__schedule函数
static void __sched __schedule(void) { struct task_struct *prev, *next; unsigned long *switch_count; struct rq *rq; int cpu; need_resched: /*禁止内核抢占*/ preempt_disable(); cpu = smp_processor_id(); /*获取CPU 的调度队列*/ rq = cpu_rq(cpu); rcu_note_context_switch(cpu); /*保存当前任务*/ prev = rq->curr; schedule_debug(prev); if (sched_feat(HRTICK)) hrtick_clear(rq); /* * Make sure that signal_pending_state()->signal_pending() below * can't be reordered with __set_current_state(TASK_INTERRUPTIBLE) * done by the caller to avoid the race with signal_wake_up(). */ smp_mb__before_spinlock(); raw_spin_lock_irq(&rq->lock); switch_count = &prev->nivcsw; /* 如果内核态没有被抢占, 并且内核抢占有效 即是否同时满足以下条件: 1 该进程处于停止状态 2 该进程没有在内核态被抢占 */ if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) { if (unlikely(signal_pending_state(prev->state, prev))) { prev->state = TASK_RUNNING; } else { deactivate_task(rq, prev, DEQUEUE_SLEEP); prev->on_rq = 0; /* * If a worker went to sleep, notify and ask workqueue * whether it wants to wake up a task to maintain * concurrency. */ if (prev->flags & PF_WQ_WORKER) { struct task_struct *to_wakeup; to_wakeup = wq_worker_sleeping(prev, cpu); if (to_wakeup) try_to_wake_up_local(to_wakeup); } } switch_count = &prev->nvcsw; } pre_schedule(rq, prev); if (unlikely(!rq->nr_running)) idle_balance(cpu, rq); /*告诉调度器prev进程即将被调度出去*/ put_prev_task(rq, prev); /*挑选下一个可运行的进程*/ next = pick_next_task(rq); /*清除pre的TIF_NEED_RESCHED标志*/ clear_tsk_need_resched(prev); rq->skip_clock_update = 0; /*如果next和当前进程不一致,就可以调度*/ if (likely(prev != next)) { rq->nr_switches++; /*设置当前调度进程为next*/ rq->curr = next; ++*switch_count; /*切换进程上下文*/ context_switch(rq, prev, next); /* unlocks the rq */ /* * The context switch have flipped the stack from under us * and restored the local variables which were saved when * this task called schedule() in the past. prev == current * is still correct, but it can be moved to another cpu/rq. */ cpu = smp_processor_id(); rq = cpu_rq(cpu); } else raw_spin_unlock_irq(&rq->lock); post_schedule(rq); sched_preempt_enable_no_resched(); if (need_resched()) goto need_resched; }
4、调度器的结构
在Linux内核中,调度器可以分成两个层级,在进程中被直接调用的成为通用调度器或者核心调度器,他们作为一个组件和进程其他部分分开,而通用调度器和进程并没有直接关系,其通过第二层的具体的调度器类来直接管理进程。具体架构如下图:

如上图所示,每个进程必然属于一个特定的调度器类,Linux会根据不同的需求实现不同的调度器类。各个调度器类之间具备一定的层次关系,即在通用调度器选择进程的时候,会从最高优先级的调度器类开始选择,如果通用调度器类没有可运行的进程,就选择下一个调度器类的可用进程,这样逐层递减。
每个CPU会维护一个调度队列称之为就绪队列,每个进程只会出现在一个就绪队列中,因为同一进程不能同时被两个CPU选中执行。就绪队列的数据结构为struct rq,和上面的层次结构一样,通用调度器直接和rq打交道,而具体和进程交互的是特定于调度器类的子就绪队列。
5、调度器类
在linux内核中实现了一个调度器类的框架,其中定义了调度器应该实现的函数,每一个具体的调度器类都要实现这些函数 。在当前linux版本中(3.11.1),使用了四个调度器类:stop_sched_class、rt_sched_class、fair_sched_class、idle_sched_class。在最新的内核中又添加了一个调度类dl_sched_class,下面定义一些调度器类:
1 struct sched_class { 2 const struct sched_class *next; 3 4 void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags); 5 void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags); 6 void (*yield_task) (struct rq *rq); 7 bool (*yield_to_task) (struct rq *rq, struct task_struct *p, bool preempt); 8 9 void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags); 10 11 struct task_struct * (*pick_next_task) (struct rq *rq); 12 void (*put_prev_task) (struct rq *rq, struct task_struct *p); 13 14 #ifdef CONFIG_SMP 15 int (*select_task_rq)(struct task_struct *p, int sd_flag, int flags); 16 void (*migrate_task_rq)(struct task_struct *p, int next_cpu); 17 18 void (*pre_schedule) (struct rq *this_rq, struct task_struct *task); 19 void (*post_schedule) (struct rq *this_rq); 20 void (*task_waking) (struct task_struct *task); 21 void (*task_woken) (struct rq *this_rq, struct task_struct *task); 22 23 void (*set_cpus_allowed)(struct task_struct *p, 24 const struct cpumask *newmask); 25 26 void (*rq_online)(struct rq *rq); 27 void (*rq_offline)(struct rq *rq); 28 #endif 29 30 void (*set_curr_task) (struct rq *rq); 31 void (*task_tick) (struct rq *rq, struct task_struct *p, int queued); 32 void (*task_fork) (struct task_struct *p); 33 34 void (*switched_from) (struct rq *this_rq, struct task_struct *task); 35 void (*switched_to) (struct rq *this_rq, struct task_struct *task); 36 void (*prio_changed) (struct rq *this_rq, struct task_struct *task, 37 int oldprio); 38 39 unsigned int (*get_rr_interval) (struct rq *rq, 40 struct task_struct *task); 41 42 #ifdef CONFIG_FAIR_GROUP_SCHED 43 void (*task_move_group) (struct task_struct *p, int on_rq); 44 #endif 45 };
进程调度并不是什么时候都可以,系统会有一个周期调度器,根据频率自动调用schedule_tick函数。其主要作用就是根据进程运行时间触发调度;在进程遇到资源等待被阻塞也可以显示的调用调度器函数进行调度;另外在有内核空间返回到用户空间时,会判断当前是否需要调度,在进程对应的thread_info结构中,有一个flag,该flag字段的第二位(从0开始)作为一个重调度标识TIF_NEED_RESCHED,当被设置的时候表明此时有更高优先级的进程,需要执行调度。另外目前的内核支持内核抢占功能,在适当的时机可以抢占内核的运行。
6. Linux 进程切换
与进程切换相关的是task_struct 中的tss字段,关于这一字段的数据结构比较复杂,也不必详细解释,它存储的是进程的上下文环境,这里用到了两个成员:ESP(进程的栈地址)和EIP(进程的当前运行指针)。
Linux 中任务切换起主要作用的部分是switch-to(prev,nextlast),这是一个宏定义,其主要工作是:(1)保存prev任务的ESP,EIP;(2)恢复next 任务的EIP,ESP,ret 后进入next 的空间。
EIP的恢复借助了ret 语句的功能。实际过程是这样的:先将进程next 的EIP压入堆栈,然后程序跳转到_switch-to,-switch-to 函数的最后是ret 语句,而ret 语句的功能就是弹出堆栈的最上面的值作为当前的EIP,这样next进程的EIP就出栈成为当前执行的EIP,完成了整个任务上下文的切换过程.以下是进程切换的代码
#define switch_to(prev, next, last) \ do { \ /* \ * Context-switching clobbers all registers, so we clobber \ * them explicitly, via unused output variables. \ * (EAX and EBP is not listed because EBP is saved/restored \ * explicitly for wchan access and EAX is the return value of \ * __switch_to()) \ */ \ unsigned long ebx, ecx, edx, esi, edi; \ \ asm volatile("pushfl\n\t" /* save flags */ \ "pushl %%ebp\n\t" /* save EBP */ \ "movl %%esp,%[prev_sp]\n\t" /* save ESP */ \ "movl %[next_sp],%%esp\n\t" /* restore ESP */ \ "movl $1f,%[prev_ip]\n\t" /* save EIP */ \ "pushl %[next_ip]\n\t" /* restore EIP */ \ __switch_canary \ "jmp __switch_to\n" /* regparm call */ \ "1:\t" \ "popl %%ebp\n\t" /* restore EBP */ \ "popfl\n" /* restore flags */ \ \ /* output parameters */ \ : [prev_sp] "=m" (prev->thread.sp), \ [prev_ip] "=m" (prev->thread.ip), \ "=a" (last), \ \ /* clobbered output registers: */ \ "=b" (ebx), "=c" (ecx), "=d" (edx), \ "=S" (esi), "=D" (edi) \ \ __switch_canary_oparam \ \ /* input parameters: */ \ : [next_sp] "m" (next->thread.sp), \ [next_ip] "m" (next->thread.ip), \ \ /* regparm parameters for __switch_to(): */ \ [prev] "a" (prev), \ [next] "d" (next) \ \ __switch_canary_iparam \ \ : /* reloaded segment registers */ \ "memory"); \ } while (0)
四、谈谈自己对该操作系统进程模型的看法
进程实现是分时系统的核心部分之一,且与操作系统多方面的内容联系。Linux是十分成功的操作系统,许多方面的设计都十分新颖,而且在实现上也相当畜于技巧,其设计思路和方法都是值得借鉴的。
参考资料:
https://www.cnblogs.com/ck1020/p/6089970.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号