物流项目(一):采集平台
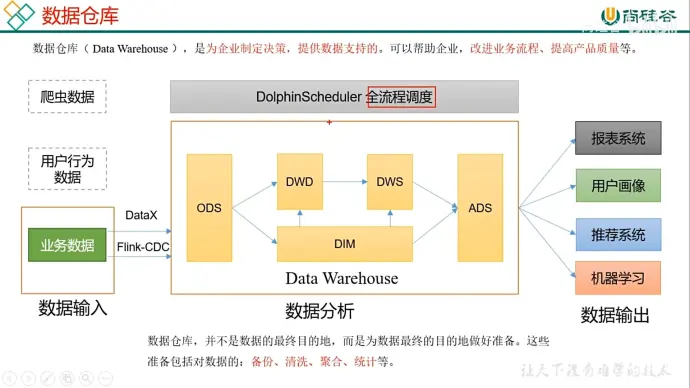
1、数据仓库的作用
(1)采集存储
(2)计算分析
2、数据来源
(1)业务数据
(2)用户行为
(3)爬虫数据
3、流程
(1)DataX 负责全量导入,Flink-CDC 负责增量导入
(2)DWD 存储事实表(用户具体做了什么事),DIM 存储维度表(用于描述事实表)
(3)DWS 负责预聚合
4、项目需求
(1)业务数据采集
(2)数据仓库维度建模
(3)分析主题,统计指标
(4)采用即席查询工具分析指标
(5)对集群性能进行监控
(6)元数据管理
(7)质量监控
(8)权限管理
5、技术选择考虑的因素
(1)数据量大小
(2)业务需求
(3)行内经验
(4)技术成熟度
(5)开发维护成本
(6)总成本预算
数据采集传输:
Flume:采集日志数据
Kafka:消峰、解耦
DataX:同步 mysql 数据,支持数据源比较多,不支持分布式,可以做成伪分布式
Flink-CDC:实现增量同步
数据存储
MySQL: 数据量少的
HDFS:数据量大的
Redis,HBase:实时数据存储
MongoDB:JSON 数据
数据计算
Hive、Spark:离线用
Flink:实时用
数据查询:
Presto(sql 语法差别和 hive 较大),Kylin,Impala:离线数据查询
Druid,ClickHouse,Doris:实时数据查询
数据可视化
Superset
任务调度
DolphinScheduler(简单功能还多,国人开发)
Airflow(python)
集群监控:
Zabbix,Prometheus
元数据管理:
Atlas
权限管理:
Ranger,Sentry
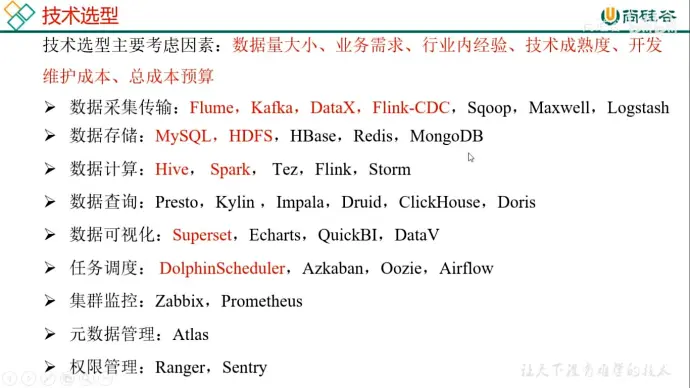
6、系统数据流程设计
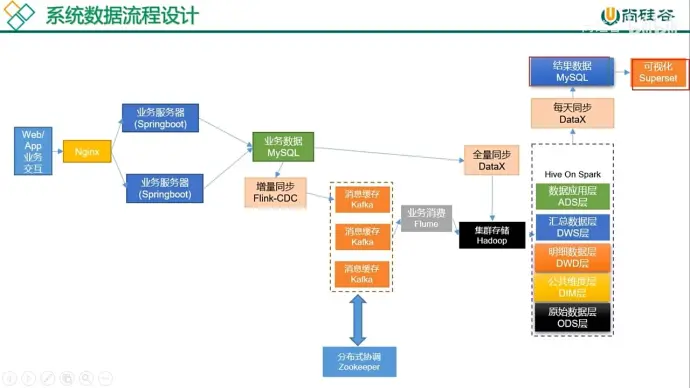
7、框架发型版本选择
Apache:运维麻烦,组件间的兼容性需要自己调研(建议使用)
CDH: 国内使用最多版本,但 CM 不开源
HDP: 开源,可进行二次开发,没 CDH 稳定,国内使用少
8、版本号
9、服务器选择

10、集群规划

11、集群资源规划设计‘
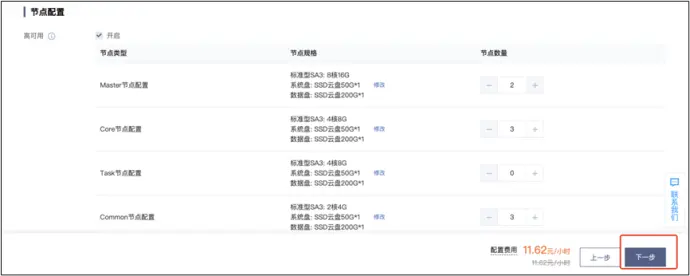
(1)推荐部署
master 节点:管理节点,保证集群的调度正常进行,NameNode、ResourceManager
core 节点:计算及存储节点,通常扩容的 mode
common 节点:主要部署分布式协调组件,如 zookeeper,secondarynode
(2) 消耗内存的分开部署
(3)数据传输数据比较紧密的放在一起(Kafka、clickhouse)
(4)客户端尽量放在一到两台服务器上,方便外部访问
(5)有依赖关系的尽量放到同一台服务器(例如:Ds-worker 和 hive/spark)
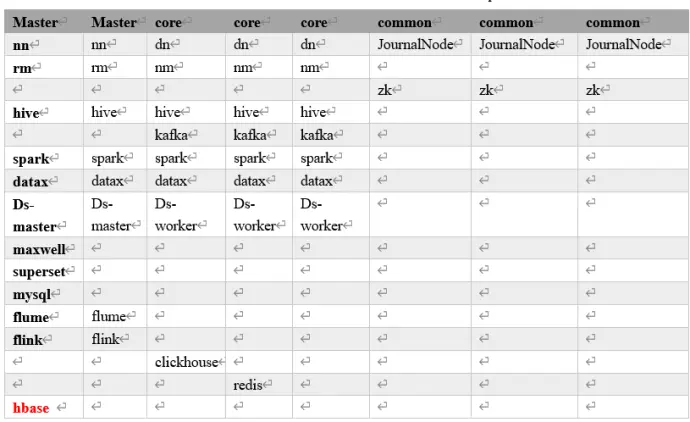
12、业务流程
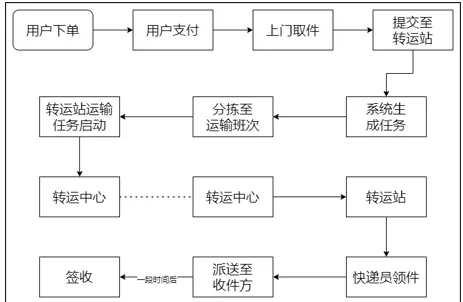
13、阿里云
(1)使用阿里云的 ECS 服务,创建时使用抢占式比较实惠,但要做好数据丢失的准备
(2)私有 IP 是阿里云内部机器使用的 IP,公网 IP 是外部访问用的 IP
14、集群数据均衡
(1)节点间的数据均衡
不同节点间的调动,任务多的机器分给任务少的
start-balancer.sh -threshold 10(存储阈值)
stop-balsnce.sh
(2)磁盘间数据均衡
【1】生成均衡计划
hdfs diskbalancer -plan hadoop102
【2】执行均衡计划
hdfs diskbalancer -execute
【3】查看当前均衡任务的执行情况
hadoop102.plan.json
【4】取消均衡任务
hdfs diskbalancer -cancel hadoop102.plan.json
mb
15、hadoop 参数调优
(1)线程数量(并发心跳)
默认 10 个,需要根据参数公式来调整

16、yarn 参数调优
(1)内存利用率不够问题
这种问题主要是 yarn 所造成的
【1】yarn.nodemanager.resource.memory-mb
表示 yarn 上可用的物理内存总量,默认 8192mb
【2】yarn.scheduler.maximum-allocation-mb
单个任务可申请最多物理内存量,默认 8192mb
17、业务数据同步概述
(1)数据同步策略概述
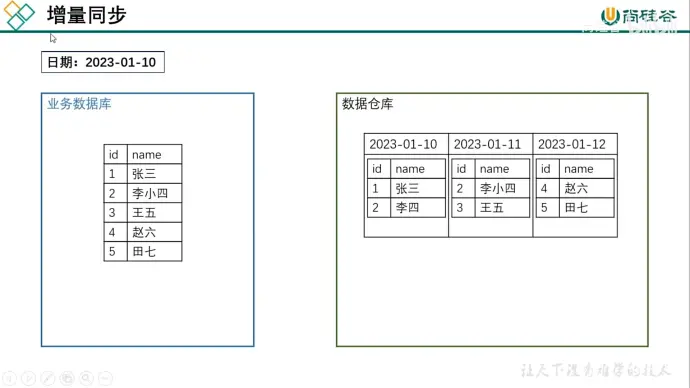
业务数据是数据仓库的重要数据来源,我们需要每日定时从业务数据库中抽取数据,传输到数据仓库中,之后再进行数据分析统计
为保证统计结果正确性,需要保证数据仓库中的数据与业务数据库是同步的,离线数据仓的计算周期通常为天,所以数据同步周期通常为天。
同步策略有全量同步和增量同步
全量同步是计算历史和今天的数据;增量同步只计算今天的数据
全量同步会重复存储历史数据,性价比较低,通常不会删除历史数据,主要是记录历史数据变化
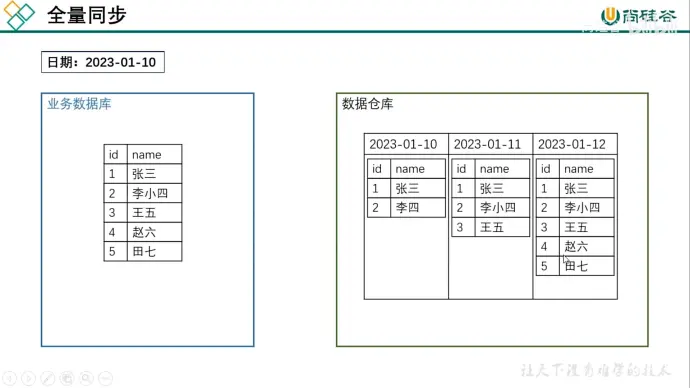
增量同步每次只同步最新的数据,但是变向增加计算成本(例如计算历史人物数量)
(2)同步策略的选择
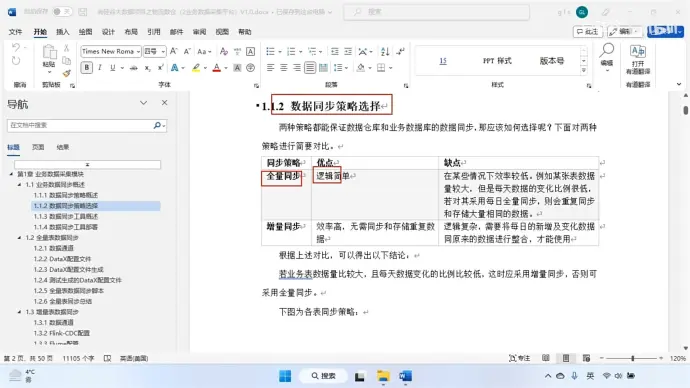
全量同步逻辑简单,但在某些情况下效率较低,尤其是在数据量较大的情况下会存储大量重复数据
增量同步效率高,无需同步和存储重复数据,但逻辑复杂,需要将每日新增和变化数据通原数据整合才能使用
因此:
若业务数据量较大,数据变化比例低,可以采用同步增量,否则采用全量同步
(3)同步工具的选择
基于 select 查询的离线、批量同步工具:DataX、Sqoop
基于数据库数据变更日志的实时流工具:Maxwell、Canal、Flink-CDC

本项目全量同步用 DataX,增量用 Flink-CDC
18、异构数据源工具:DATAX(同步用)
一个开源的异构数据源离线同步工具
(1)结构图
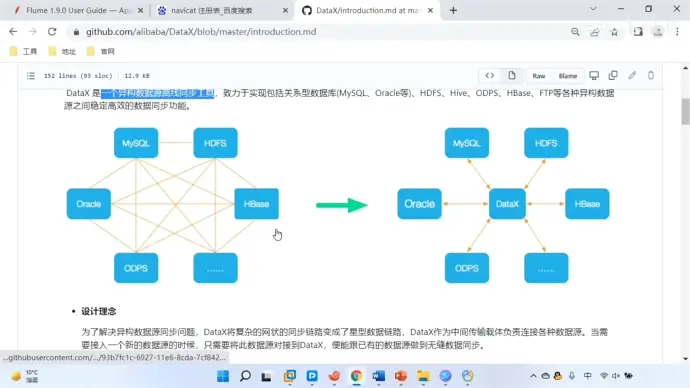
将复杂的网状格式转变成立星型数据链路
(2)框架设计
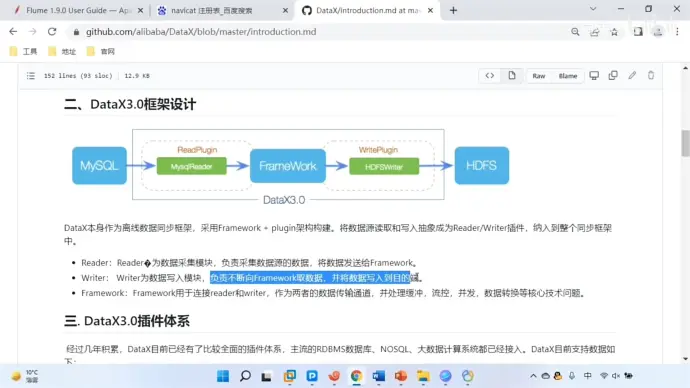
【1】reader 负责采集数据源的数据发送给 framework
【2】writer 从 framework 取出数据写入到目的端
【3】framework 用于连接 reader 和 writer,作为二者的传输通道,并处理缓存、流控、并发、数据转换
(3)运行流程
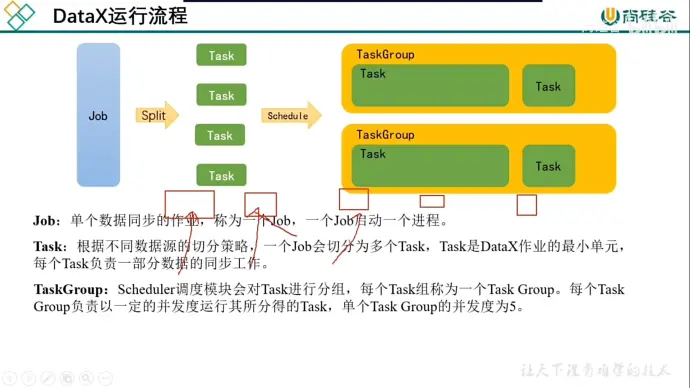
【1】默认情况下一个表一个 task
【2】taskgroup 默认并发度是 5,最多同时执行个 task
【3】流式处理,处理完一个 task 就离开一个
(4)决策思路

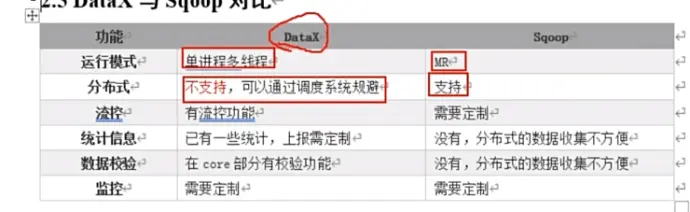
(5)和 sqoop 对比
(6)安装注意
Ubuntu 用户解压 datax 后进行 python 校验时如果遇到找不到文件的错误可以试试删除 plugin 文件夹中 reader 和 writer 中所有._开头的文件
(7)自定义配置 job.json

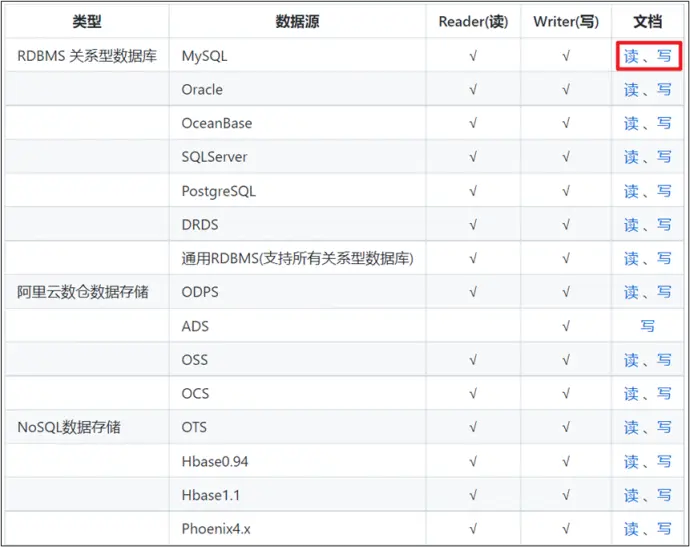
各种数据库的读写插件支持表
reader 参数

writer 参数

(8)案例
案例一:创建表到 HDFS 中
base_province 似乎缺失,可以根据文档中的数据找 GPT 生成相关表的语句在 tms01 中生成

案例二:对表进行查询

案例三:同步表到 mysql 中

(9)DATAX 传参
HDFS 的存储分区一般按照时间进行,因此使用 datax 写入时需要根据时间修改存储路径,这时候就需要使用传参的方式修改存储路径

接着只要在执行命令时写入参数即可

(10)DATAX SplitPK 切割原理
使用 splitPK 可以将所代表的字段进行数据分片,因此 DATAX 会启动并发任务进行数据同步,可以大大提高同步效能,只支持整形数据切分,不支持浮点、字符串、日期等其他类型。默认为空
task 数量 = 分区数(channel>=2) * 5 + 1
(11)null 值存储
如果在 hive 中的结果是 null 的话,在 hdfs 中会存储为'\n'。但当写会 mysql 时还是要转回 null
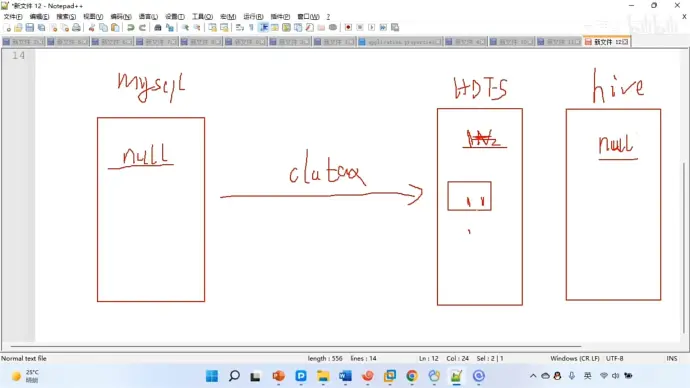
由于 datax 采用 Java 编写,因此需要在写代码时采用两个斜杠
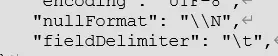
遗憾的是如果从 mysql 中读取出了 null 值是无法逆向转换成'\N'的,而是以''的方式返回,这会导致在 hdfs 中存储的数据类型不匹配。因此一个解决方法是创建 hive 表的时候就指定 null 值为'',但无法识别 mysql 中的''数据。
因此最好的方法是重写 datax 的源码,修改逻辑,改成'\N'
(12)参数调优
【1】速度控制

图中(1)和(2)的单独设定是为了防止数据倾斜(总和一样但内部分配不均匀)
【2】计算方法


【3】内存配置
提升 datax 的并发数意味着内存的占用会增加,因此需要修改内存大小
推荐设置为 4G 或者 8G

19、增量工具 Flink-CDC
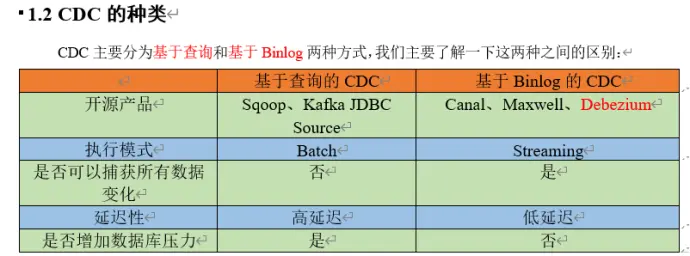
(1)什么是 CDC
CDC 是用于检测并补货数据库变动,并记录下来变更顺序,写入消息中间件的工具
(2)种类
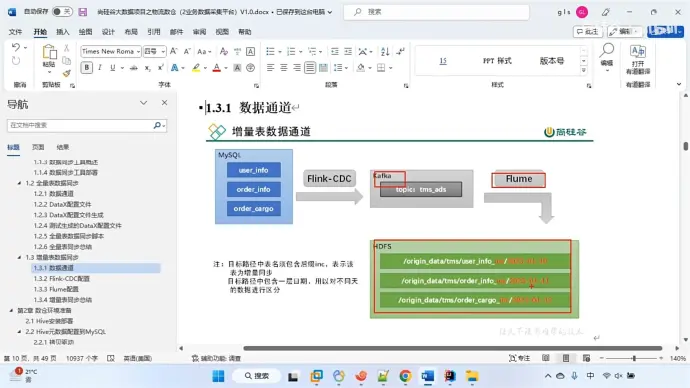
20、增量表数据同步

 浙公网安备 33010602011771号
浙公网安备 33010602011771号