[自然语言处理入门]三、文本分类基础
三、文本分类基础
学习路线参考:
https://blog.51cto.com/u_15298598/3121189
https://github.com/Ailln/nlp-roadmap
https://juejin.cn/post/7113066539053482021
https://zhuanlan.zhihu.com/p/100567371
https://cloud.tencent.com/developer/article/1884740
本节学习使用工具&阅读文章:
https://zhuanlan.zhihu.com/p/32965521
https://blog.csdn.net/feilong_csdn/article/details/88655927
https://zhuanlan.zhihu.com/p/30875066
https://blog.csdn.net/qq_43019117/article/details/82770124
https://blog.csdn.net/qq_39439006/article/details/126760701
https://zhuanlan.zhihu.com/p/40276005
1. Softmax回归
Softmax回归模型是logistic回归模型在多分类问题上的推广。
-
假设函数
对于给定的测试输入\(x\),用假设函数针对每一个类别 \(j\)估算出概率值 \(p(y=j|x)\) ,即,估计\(x\)的每一种分类结果出现的概率。假设函数将要输出一个\(k\)维的向量来表示这\(k\)个估计的概率值。假设函数\(h_{w}(x)\)形式如下:
\(h_{w}(x^{(i)})= \begin{bmatrix}p(y^{(i)}=1|x^{(i)};w)\\ p(y^{(i)}=2|x^{(i)};w)\\……\\ p(y^{(i)}=k|x^{(i)};w) \end{bmatrix} = {1 \over \sum^k_{j=1}e^{w_jx^{(i)}}}\begin{bmatrix}e^{w_1x^{(i)}}\\ e^{w_2x^{(i)}}\\……\\ e^{w_kx^{(i)}} \end{bmatrix}\)
其中\(\theta_1,\theta_2,……,\theta_k\)是模型的参数。\({1 \over \sum^k_{j=1}e^{w_jx^{(i)}}}\)这一项对概率分布进行归一化,使得所有概率之和为1。
-
代价函数
\(J(w)=-{1\over m}[\sum^m_{i=1}\sum^k_{j=1}1\{y^{(i)}=j\}log{e^{w_jx^{(i)}}\over\sum^k_{l=1}e^{w_lx^{(i)}}}\)
上述公式是logistic回归代价函数的推广。
-
层级Softmax
标准的Softmax回归需要对所有的K个概率做归一化,这在类别很多时非常耗时。可以使用层级Softmax,它的基本思想是使用树的层级结构替代扁平化的标准Softmax。和之前的word2vec使用的是同一种优化方法。
实际上这是用多次二分类的逻辑回归代替Softmax回归,但是通过层级Softmax,计算复杂度可以大幅下降。
2. Fasttext
FastText是一个快速文本分类算法,与基于神经网络的分类算法相比有以下优点
- FastText在保持高精度的情况下加快了训练速度和测试速度
- FastText不需要预训练好的词向量,fastText会自己训练词向量
- FastText两个重要的优化:Hierarchical Softmax、N-gram
-
字符集别的n-gram
word2vec把语料库中的每个单词当成原子的,它会为每个单词生成一个向量。这忽略了单词内部的形态特征。为了克服这个问题,fastText使用了字符级别的n-grams来表示一个单词。对于单词apple,假设n的取值为3,则它的trigram有
ap, app, ppl, ple, le。优点:
- 对于低频词生成的词向量效果会更好。因为它们的n-gram可以和其它词共享。
- 对于训练词库之外的单词,仍然可以构建它们的词向量。我们可以叠加它们的字符级n-gram向量。
-
词嵌入
首先,FastText通过Skip-Gram训练了字符级别的N-gram的Embedding,然后通过将其相加得到词向量。
其次,这样处理会丢失词顺序,FastText增加了N-gram的特征。具体做法是把N-gram当成一个词,也用embedding向量来表示,在计算隐层时,把N-gram的embedding向量也加进去求和取平均。
举个例子来说,假设某篇文章只有3个词:[W1,W2,W3]。N-gram的N取2,w1、w2、w3以及w12、w23分别表示词W1、W2、W3和bigram W1-W2,W2-W3的embedding向量,那么文章的隐层可表示为:
\(h={1\over5}(w_1+w_2+w_3+w_{12}+w_{23})\)
具体实现上,由于n-gram的量远比word大的多,完全存下所有的n-gram也不现实。FastText采用了Hash桶的方式,把所有的n-gram都哈希到buckets个桶中,哈希到同一个桶的所有n-gram共享一个embedding vector。
-
模型架构

-
输入:一篇文章中,每个词的word embedding表示以及n-gram信息。
-
输出:该篇文章对应的分类label。
-
3. TextCNN
与传统图像的CNN网络相比,TextCNN在网络结构上没有任何变化,只有一层卷积,一层max-pooling,最后将输出外接softmax来n分类。网络结构简单导致参数数目少,计算量少,训练速度快。
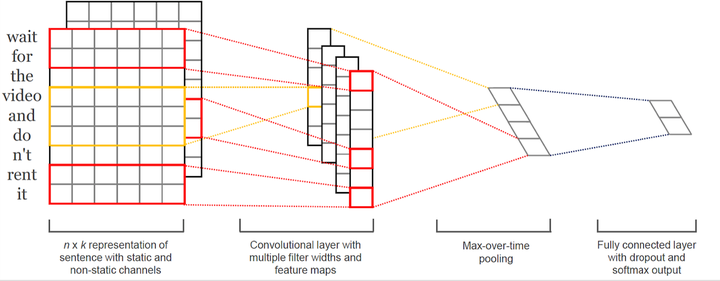
-
输入层(嵌入层)
一般使用预训练好的词向量(Word2Vector或者glove)方法作为Embedding layer。也存在一些变化模型。
- CNN-rand:作为一个基础模型,Embedding layer所有words被随机初始化,然后模型整体进行训练。
- CNN-static:模型使用预训练的word2vec初始化Embedding layer,对于那些在预训练的word2vec没有的单词,随机初始化。然后固定Embedding layer,fine-tune整个网络。
- CNN-non-static:训练的时候,Embedding layer跟随整个网络一起训练。
- CNN-multichannal:Embedding layer有两个channel,一个channel为static,一个为non-static。然后整个网络fine-tune时只有一个channel更新参数。两个channel都是使用预训练的word2vec初始化的。
-
卷积层
相比于一般CNN中的卷积核,这里的卷积核的宽度一般需要与词向量的维度一样。卷积核的高度则是一个超参数可以设置,比如设置为2、3等。然后剩下的就是正常的卷积过程了。
在传统CV领域,可利用 (R, G, B) 作为不同channel,通道个数一般为3个。在使用TextCNN做分类时,通道个数一般是一个。
其实也可以采用多channel输入,TextCNN的多channel通常是不同方式的embedding方式。但是实验证明,单channel的TextCNN表现都要优于多channels的TextCNN。
-
池化层&全连接层:与CNN相同。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号