
OCR工具对比与tesseract简明教程
OCR工具对比与tesseract简明教程

一、OCR工具对比
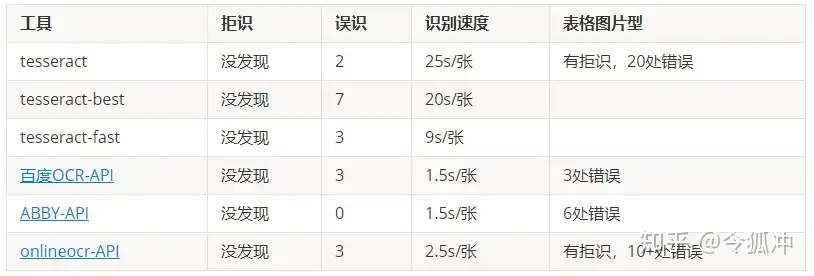
经过预处理后,tesseract识别率达到100%,tesseract-fast错误均为人名,tesseract-best/tesseract-fast仅用LSTM。CLSTM已经年久失修,docker镜像都404了。tesseract对清晰度不高的图片识别出现很多拒识,百度OCR-API准确率还在95%以上
结论:tesseract较多人使用,有比较多资料可查,目前由google提供支持,暂定它了,优化方向:通过训练微调、想办法提速。
二、tesseract-ocr使用流程
安装
支持windows、linux,注意要安装4.0版,准确率有较大提升,安装后需要添加中文词库。
安装教程地址:https://github.com/tesseract-ocr/tesseract/wiki
中文词库地址:chi_sim.traineddata
运行
假设当前目录下有test.jpg(注意要先把pdf文件转为图片),生成的文件名是result.txt,执行如下命令:
tesseract test.jpg result -l chi_sim其中-l代表使用的词库,chi_sim是简体中文。
tesseract生成的结果包括可搜索pdf文档(文本双层pdf),在命令结尾加上pdf即可
tesseract test.jpg result -l chi_sim pdftesseract的python接口:pytesseract
pip install pytesseract简单调用:
import pytesseract
from PIL import Image
im=Image.open('test.jpg')
print(pytesseract.image_to_string(im))训练
所需工具:
1. 根据图片生成BOX文件
tesseract myfontlab.normal.exp0.jpg myfontlab.normal.exp0 -l chi_sim batch.nochop makebox注意图片与box文件名需保持一致,box文件格式如下
字 x坐标 y坐标 宽度 高度2. 修正BOX文件
使用jTessBoxEditor打开图片文件修正box错误

3.进行训练
训练,生成.tr文件
tesseract myfontlab.normal.exp0.jpg myfontlab.normal.exp0 nobatch box.train生成一个unicharset文件
unicharset_extractor myfontlab.normal.exp0.box新建一个font_properties.txt文件,里面内容写入 normal 0 0 0 0 0 表示默认普通字体
shapeclustering -F font_properties.txt -U unicharset myfontlab.normal.exp0.tr
mftraining -F font_properties.txt -U unicharset -O unicharset myfontlab.normal.exp0.tr
cntraining myfontlab.normal.exp0.tr在这五个文件前加上normal.进行重命名
combine_tessdata normal.得到训练好的字库,normal.traineddata,复制到Tesseract-OCRt程序目录下的“tessdata”目录即可,使用时可以多个字库并用
tesseract test.jpg result -l chi_sim+normal优化方向
- 图像处理(后面单列)
- 参数调整
当文字内容比较模糊不清时,按行模式来识别能够大大提高识别率和准确率,如使用默认参数,下图基本识别不出来

当把按照行切开后,使用单行识别模式,Page segmentation modes:Treat the image as a single text line
shell tesseract test_singleline.png single -l chi_sim --psm 7 #促进节约集约用地,国土资源部
识别率大大提高
4.0的LSTM引擎不支持常用字典、黑名单、白名单,综合来看还是4.0的LSTM识别率高。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号