
hadoop大作业
1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计。
1.启动hadoop
2.Hdfs上创建文件夹并查看

3.上传英文词频统计文本至hdfs

1、把英文文章的每个单词放到列表里,并统计列表长度;
2、遍历列表,对每个单词出现的次数进行统计,并将结果存储在字典中;
3、利用步骤1中获得的列表长度,求出每个单词出现的频率,并将结果存储在频率字典中;
3、以字典键值对的“值”为标准,对字典进行排序,输出结果(也可利用切片输出频率最大或最小的特定几个,因为经过排序sorted()函数处理后,单词及其频率信息已经存储在元组中,所有元组再组成列表。)
fin = open('The_Magic_Skin _Honore_de_Balzac.txt') #the txt is up
#to you
lines=fin.readlines()
fin.close()
'''transform the article into word list
'''
def words_list():
chardigit='ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789 '
all_lines = ''
for line in lines:
one_line=''
for ch in line:
if ch in chardigit:
one_line = one_line + ch
all_lines = all_lines + one_line
return all_lines.split()
'''calculate the total number of article list
s is the article list
'''
def total_num(s):
return len(s)
'''calculate the occurrence times of every word
t is the article list
'''
def word_dic(t):
fre_dic = dict()
for i in range(len(t)):
fre_dic[t[i]] = fre_dic.get(t[i],0) + 1
return fre_dic
'''calculate the occurrence times of every word
w is dictionary of the occurrence times of every word
'''
def word_fre(w):
for key in w:
w[key] = w[key] / total
return w
'''sort the dictionary
v is the frequency of words
'''
def word_sort(v):
sort_dic = sorted(v.items(), key = lambda e:e[1])
return sort_dic
'''This is entrance of functions
output is the ten words with the largest frequency
'''
total = total_num(words_list())
print(word_sort(word_fre(word_dic(words_list())))[-10:])
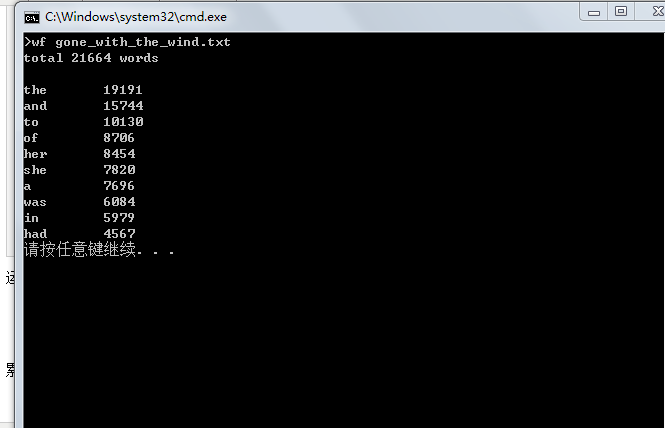
英文长篇小说TXT如下

词频截图如下
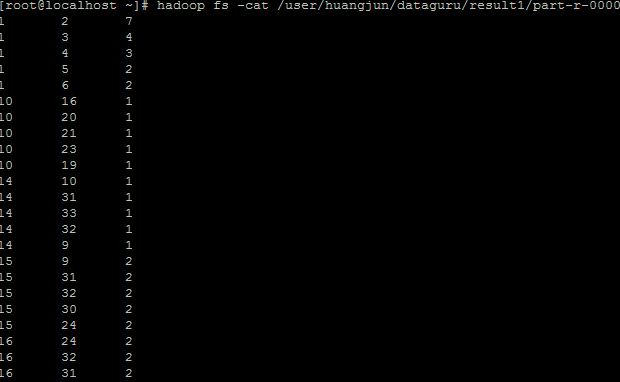
2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
csv文件,通过 Numbers 打开
"Header1","Header2","Header3" "Data1","Data2","Data3" "Data1","Data2","Data3"
所有的数据都读到了 datas 数组中
def main(input_file_path):
input_file = open(input_file_path);
# skip header
input_file.readline();
datas = [];
key_index_table = {
"Header1": 0,
"Header2": 1,
"Header3": 2};
count = 0;
max_count = 10000;
while count < max_count:
count += 1;
line = input_file.readline();
if not line:
break;
values = line.split(",");
data = {};
for key in key_index_table:
value = values[key_index_table[key]];
value = value[1:-1]; # remove quotation mark
data[key] = int(value);
datas.append(data);
drawTable(datas);
分析截图如下

这样就可以对自己感兴趣的方向分析。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号