知乎爬虫之2:爬虫流程设计(附赠爬出的数据库)
本文由博主原创,转载请注明出处:我的博客-知乎爬虫之爬虫流程设计
git爬虫项目地址(关注和star在哪里~~):https://github.com/MatrixSeven/ZhihuSpider (已完结)
附赠之前爬取的数据一份(mysql): 链接:https://github.com/MatrixSeven/ZhihuSpider/README.MD 只下载不点赞,不star,差评差评~蓝瘦香菇)
(Ps:这个思路有问题,实际上并不是这么搞得代码,后续补上)
说到爬虫,其实写起来很简单,爬虫无非就是将自己想要的内容在页面上抽离出来,并且存储。这个过程在今天已经变得非常轻松,在Java下有Jsoup,Python下有BS4,还有通吃的正则等等,然而真正难的却是在于伪造请求,截获分析请求参数,获取正确的页面.
首先来说,一个能混得过去的爬虫,应该有一个优秀的流程,在明确自己的目标后,应该立马去设计爬虫工作流程,而不是去无脑的Coding。
那么今天咱们就先研究下咱们这个爬虫的目标和流程。
首先咱们是要获取知乎页面上的个人信息,关注和被关注信息,首先咱们会遇到第一个问题就是登陆,咱们这里暂且不讲,
其次咱们就是要给定一个初始化url,然后进行followers的和followees的获取,然后循环爬起来,那么其中一定会遇到数据重复和人物关系建立的问题。
1.过滤重复数据
这个相对而言比较简单,有几种常规方法:
1. 数据库设置主键,锁定人物ID
2. 存入数据时查询数据库数据
3. 使用缓存队列,在缓存中查找数据判断
首先来说第一种,数据库设置主键,锁定人物ID,这个方法可以使数据永远不重复,但是也会造成批量插入的时候造成出错
第二种方法,存入数据时查询数据库数据,可行,但是多次访问数据库,造成效率低下
第三种方法,使用缓存队列,在缓存中查找数据判断,这种方法很好,而且速度相对较快,但是缓存太多容易出现OOM问题
在这里咱们不选择某一种方案,而是采用主键+优先缓存+数据库查询方式,后期自己实现一个LRU缓存队列,提供命中率
2. 爬取时创建人物关系
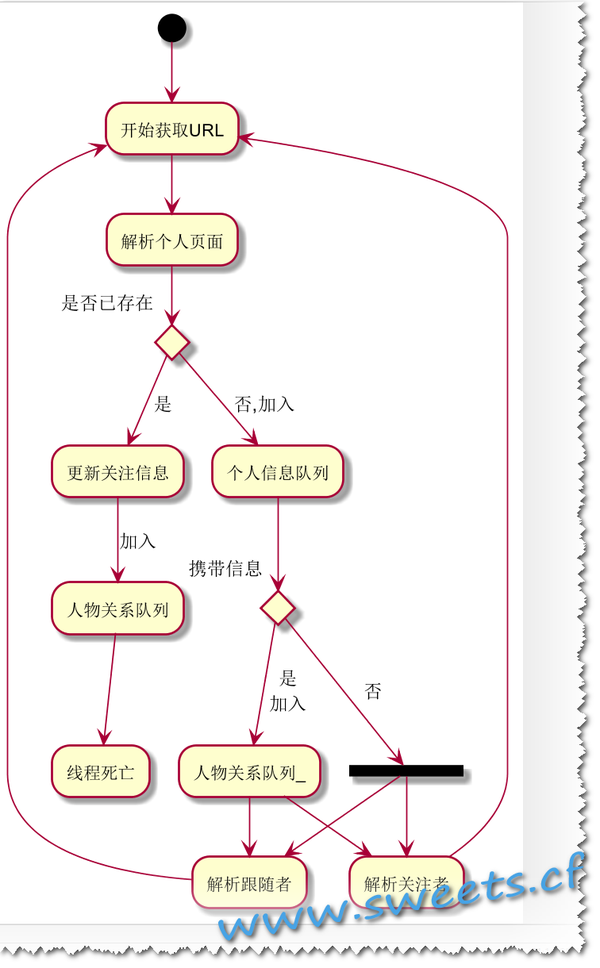
这个问题思考了很久,也比较恶心,在人物不确定的情况下进行人物的获取和关系的创建,怎么处理好呢。我的想法是让每一个人员信息携带一个上级信息,来判断是否能够构建人物关系,有点类似于尾递归的思想。
3. 绘制流程图
那么对于咱们的一个整体流程目前就有了(挑战一下,还是放弃了、哈哈):
获取URL-->解析页面<--------
| |
| |
是否存在 |
/\ |
/ \ |
更新 携带 |
数据 信息 |
/\ |
/ \ |
跟随 关注 |
信息 信息----
获取URL–》解析—》判断—》更新/携带信息?—》分析跟随者/根系关注者–》解析页面
最终画出真正的流程图
//吾爱Java(QQ群):170936712(点击加入)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号