


第一次个人编程作业
第一次个人编程作业
| 这个项目属于哪个课程 | 课程链接 |
|---|---|
| 作业要求 | 作业链接 |
| 作业的目标 | 使用PSP表格,用github版本管理,实现一个高效稳定的论文查重算法 |
Github链接:Github文件夹链接
1. PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 60 |
| Estimate | · 估计这个任务需要多少时间 | 60 | 60 |
| Development | 开发 | 480 | 510 |
| Analysis | · 需求分析 (包括学习新技术) | 90 | 90 |
| Design Spec | · 生成设计文档 | 45 | 30 |
| Design Review | · 设计复审 | 30 | 10 |
| Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 15 | 20 |
| Design | · 具体设计 | 30 | 30 |
| Coding | · 具体编码 | 180 | 240 |
| Code Review | · 代码复审 | 30 | 30 |
| Test | · 测试(自我测试,修改代码,提交修改) | 60 | 150 |
| Reporting | 报告 | 140 | 170 |
| Test Report | · 测试报告 | 90 | 120 |
| Size Measurement | · 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 680 | 830 |
2. 需求解析
-
总体目标
设计一个论文查重程序,能够比较两份文本文件(原文与抄袭版),并计算出它们的重复率。重复率应以浮点数形式输出,保留两位小数。
-
输入输出要求
- 输入:通过命令行参数提供三个文件路径:
- 原文文件路径
- 抄袭版论文文件路径
- 输出答案文件路径
- 输出:将重复率写入指定的答案文件,格式为浮点数,精确到小数点后两位。
- 输入:通过命令行参数提供三个文件路径:
-
功能需求
- 程序能够处理中文文本,识别文本之间的增删改差异。
- 能够计算出两份文本的重复率,例如:
- 原文:今天是星期天,天气晴,今天晚上我要去看电影。
- 抄袭版:今天是周天,天气晴朗,我晚上要去看电影。
- 输出:重复率(浮点数,精确到小数点后两位)
-
技术与实现要求
- 代码需通过 Code Quality Analysis 工具检测,无警告。
- 项目需使用 GitHub 管理,完成初版后进行性能分析并优化。
- 编写至少 10 个单元测试用例,保证程序正确处理各种情况,测试覆盖率需可查看。
-
性能与限制
- 单次运行不超过 5 秒
- 内存占用不得超过 2048MB
- 程序不能有严重内存泄漏
- 不允许联网或执行系统操作
3. 算法流程及实现
- 程序读取原文和抄袭版文本,并对中文分词与语气词过滤的进行预处理。
- 通过最长公共子序列(LCS)和编辑距离分析文本的局部顺序与改写差异,再利用 n-gram Jaccard 计算局部连续片段相似性,同时通过 SimHash 对文本整体结构和全局相似性进行快速指纹比对。
- 将各算法得到的相似度按权重综合计算得出最终重复率,并输出到指定文件。
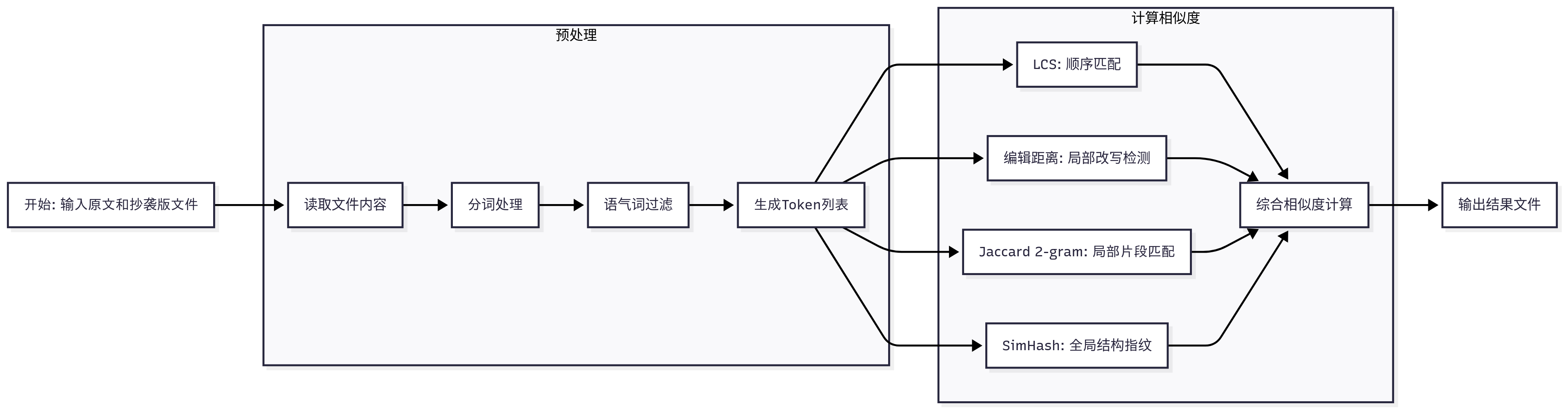
(1)预处理
- 输入
- 原文文件路径
- 抄袭版文件路径
- 处理流程:
- 读取文本:读取原文和抄袭文本,统一编码(UTF-8)。
- 文本清理:去掉空白行、特殊字符。
- 分词处理(中文场景):使用 jieba库 对文本进行中文分词。
- 语气词过滤:去掉常见无意义词(如“的”、“了”、“吧”之类的),减少噪声。
- 输出:分词后的两个 token 列表。
(2)相似度计算
i. LCS 算法
-
原理
-
最长公共子序列(LCS):在两个序列中,找出按顺序出现的最大公共子序列长度。
-
公式:
\[LCS(a,b) = \text{长度最大的序列 } s \text{,使得 } s \text{是 a 和 b 的子序列} \] -
计算方法:动态规划 (DP)
- 时间复杂度:\(O(m \times n)\),\(m\)、\(n\) 为序列长度。
dp[i][j]表示a[0..i-1]与b[0..j-1]的 LCS 长度。
-
作用:检测原文与抄袭版的顺序相似性,适合发现连续未改动片段。

ii. 编辑距离
原理:
-
Levenshtein 编辑距离:计算两个序列通过最少插入、删除、替换操作,使得两个序列相同所需的操作数。
-
归一化相似度:
\[edit\_sim = 1 - \frac{edit\_distance(a,b)}{\max(|a|,|b|)} \] -
计算方法:动态规划
dp[i][j]表示a[0..i-1]转换成b[0..j-1]的最少操作次数。- 可捕捉局部词汇增删改。
作用:补充 LCS,对局部修改敏感。

iii. n-gram + Jaccard
原理:
-
n-gram:将分词序列切分成连续 n 个词的片段。
-
Jaccard 相似度:
\[J(A,B) = \frac{|A \cap B|}{|A \cup B|} \]- A、B 分别为原文和抄袭版的 n-gram 集合。
作用:检测局部连续片段重复,尤其适合检测段落或句子级抄袭。

iv. SimHash
原理:
-
SimHash 指纹:
- 对每个 token 哈希,构造特征向量(正数/负数表示该 bit 权重方向)
- 对所有 token 累加,取正负符号得到最终指纹
-
汉明距离:
-
两个文本的 SimHash 汉明距离表示文本差异
-
相似度:
\[simhash\_sim = 1 - \frac{hamming\_distance(hash_1, hash_2)}{hashbits} \]
-
作用:快速反映全文结构和整体语义,鲁棒性强,适合长文本比对。

(3) 算法的独特之处
-
多指标融合的相似度计算
本算法同时结合了 LCS、编辑距离、n-gram + Jaccard、SimHash + Hamming 四类相似度指标,每个指标在文本相似性分析上有不同的侧重点:- LCS 强调原文顺序连续片段,擅长捕捉长段落未修改的内容;
- 编辑距离对局部增删改敏感,能够反映细微修改;
- n-gram + Jaccard 检测局部连续片段重复,适合段落或句子级抄袭;
- SimHash + Hamming 捕捉全文整体结构与语义相似性,对长文本或语序调整有鲁棒性。
通过加权融合四种指标的结果,既保证了对局部改动的敏感性,又能保持全局文本结构的识别能力,兼顾精度与鲁棒性。
-
灵活的可扩展性
- 算法设计模块化,四种相似度指标可单独调用,也可自定义加权比例;
- 支持不同文本分词方式和哈希长度配置,便于针对中文、英文或混合语言文本调整。
-
适用范围广泛
- 能够处理从短篇论文到长篇文稿的文本查重,兼顾连续未改动片段和局部改动。
4. 模块接口
程序入口为 main 函数,它首先解析命令行参数获取原文文件路径、待检测文件路径以及输出文件路径。随后调用 similarity_score 函数计算两个文本的相似度。在 similarity_score 内部,程序会调用 read_file 分别读取原文和待检测文本,然后调用 tokenize 对两者进行分词处理。处理完成后,会依次调用 lcs、edit_dist、jaccard2 和 simhash_res 计算不同的相似度指标,最后按预设权重加权合成为最终相似度得分。计算完成后,similarity_score 将结果返回给 main,由 main 调用 write_result 将最终相似度写入输出文件。
3223004816/
│
├─ main.py
│ ├─ main() # 程序入口,解析命令行参数,调用相似度计算并输出结果
│ └─ similarity_score(orig_path, copy_path)
│ # 核心函数,计算 LCS、编辑距离、Jaccard、Simhash 相似度并加权
│
├─ tool_functions.py
│ ├─ read_file(file_path) # 读取文本文件内容
│ ├─ write_result(file_path, score) # 将最终相似度写入文件
│ └─ tokenize(text) # 对文本进行分词处理
│
└─ similarity_functions.py
├─ lcs(tokens1, tokens2) # 计算最长公共子序列相似度
├─ edit_dist(tokens1, tokens2) # 计算编辑距离相似度
├─ jaccard2(tokens1, tokens2, n) # 计算 n-gram Jaccard 相似度
└─ simhash_res(tokens1, tokens2) # 计算 Simhash 相似度
函数间的调用关系如下图:

5. 代码质量分析
(1) 代码静态分析
使用pylint对代码进行静态分析。
i. 主程序(main.py)
a. 首次测试结果
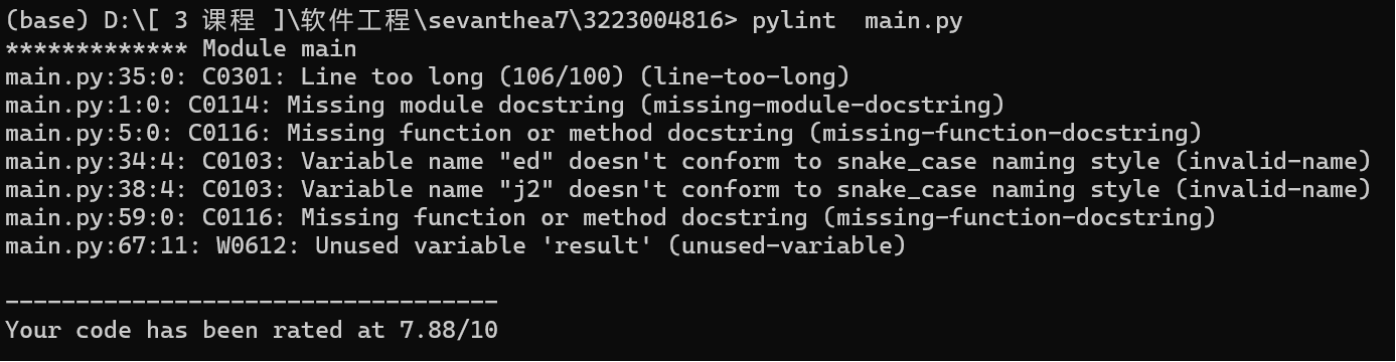
得分为 7.88/10,修改点总结如下:
- C0301: Line too long (106/100)
- 问题:第 35 行代码长度为 106 个字符,超过了 100 字符的限制。
- 修改方法:把长代码拆成多行,使用
\或者括号分行。
- C0114: Missing module docstring
- 问题:整个
main.py文件缺少模块说明文档字符串。 - 修改方法:在文件开头添加三引号字符串,简要描述模块用途。
- 问题:整个
- C0116: Missing function or method docstring (出现两次:第 5 行和第 59 行)
- 问题:函数没有文档字符串说明。
- 修改方法:在函数定义下方添加
"""说明""",描述功能、参数和返回值。
- C0103: Variable name "ed" and "j2" doesn't conform to snake_case
- 问题:变量名
ed和j2不符合snake_case命名规范。 - 修改方法:改成更有意义的、全小写+下划线分隔的名字,例如:
ed→edit_distance或ed_scorej2→jaccard_index或jaccard_score
- 问题:变量名
- W0612: Unused variable 'result'
- 问题:第 67 行声明了
result但没有使用。 - 修改方法:
- 如果确实不需要该变量,直接删除;
- 如果后续会用上,确保有被调用或返回。
- 问题:第 67 行声明了
b. 代码修改及修改后得分
针对上面的要点我进行了逐一修改,最终得分为 10/10。
- 加了模块文档说明(包含文件作者、修改日期等信息)
- 给 函数写了 docstring,中文说明
- 把变量
ed、j2改成符合有意义的名字 - 把超长行拆分
- 移除了未使用的
result(main中)

ii. 工具函数程序(tool_functions.py)
a. 首次测试结果

得分为 6.11/10,修改点总结如下:
- C0114: Missing module docstring
- 问题:整个
tool_functions.py文件缺少模块级文档说明。 - 修改方法:在文件最顶部加一个文档字符串,说明文件功能、作者、修改时间。
- 问题:整个
- SyntaxWarning: invalid escape sequence '.' / '\s'
- 问题:在正则表达式里写了
"\."或"\s",但没有用 原始字符串,Python 把它当普通转义处理。 - 修改方法:改成 raw string
- 问题:在正则表达式里写了
- C0116: Missing function or method docstring (出现在第 4、13、21 行)
- 问题:多个函数缺少说明。
- 修改方法:在函数下加中文
"""docstring""",描述用途、参数和返回值。
- C0103: Variable name "f" doesn't conform to snake_case naming style (出现在第 15、22 行)
- 问题:变量名
f太短,不符合规范。 - 修改方法:改为更清晰的名字。
- 问题:变量名
- W0707: raise-missing-from (第 18 行)
- 问题:异常重新抛出时,缺少
from exc,丢失了原始异常上下文。 - 修改方法:改成
try...except的写法。
- 问题:异常重新抛出时,缺少
b. 代码修改及修改后得分
针对上面的要点我进行了逐一修改,最终得分为 10/10。
- 加了模块说明 docstring(含作者、日期)
- 给每个函数写了中文 docstring
- 把变量 f 改成更有意义的名字(file_handle)
- 修改异常抛出方式,保留上下文(from exc)

iii. 相似度计算函数(similarity_functions.py)
a. 首次测试结果

得分为 7.91/10,修改点总结如下:
- C0304: Final newline missing (missing-final-newline)
- 问题:文件结尾缺少一个空行。
- 修改方法:在文件最后一行代码后加一个空行(PEP8 要求)。
- C0325: Unnecessary parens after 'return' keyword (superfluous-parens)
- 问题:
return后多余的括号,例如return (x)。 - 修改方法:改为
return x。
- 问题:
- C0114: Missing module docstring
- 问题:文件开头缺少整体说明。
- 修改方法:在文件最上方加上模块说明。
- C0116: Missing function or method docstring (多处:第 5, 23, 48, 60, 72, 91, 95 行)
- 问题:所有函数都缺少说明。
- 修改方法:在函数下方添加 docstring,描述功能、参数、返回值。
- C0103: Function name "LCS" doesn't conform to snake_case naming style
- 问题:函数
LCS使用大写,不符合snake_case。 - 修改方法:改为
lcs或longest_common_subsequence。
- 问题:函数
- C0103: Variable name "A" / "B" doesn't conform to snake_case naming style (第 61, 62 行)
- 问题:变量
A、B不符合规范。 - 修改方法:改为
seq_a、seq_b或更有意义的名字。
- 问题:变量
- W0611: Unused List imported from typing (unused-import)
- 问题:
from typing import List但List没有被使用。 - 修改方法:如果不需要,直接删掉。
- 问题:
b. 代码修改及修改后得分
针对上面的要点我进行了逐一修改,最终得分为 10/10。
- 去掉 from typing import List(未使用的导入)
- 加上模块 docstring(文件说明、作者、修改日期)
- 给每个函数写上中文 docstring(说明功能、参数、返回值)
- 函数名 LCS 改为小写 lcs(符合 snake_case)
- 变量名 A、B 改成 ngrams_a、ngrams_b(符合 snake_case)
- return ( ... ) 改为 return ...(去掉多余括号)
- 文件末尾加上换行

(2) 性能分析
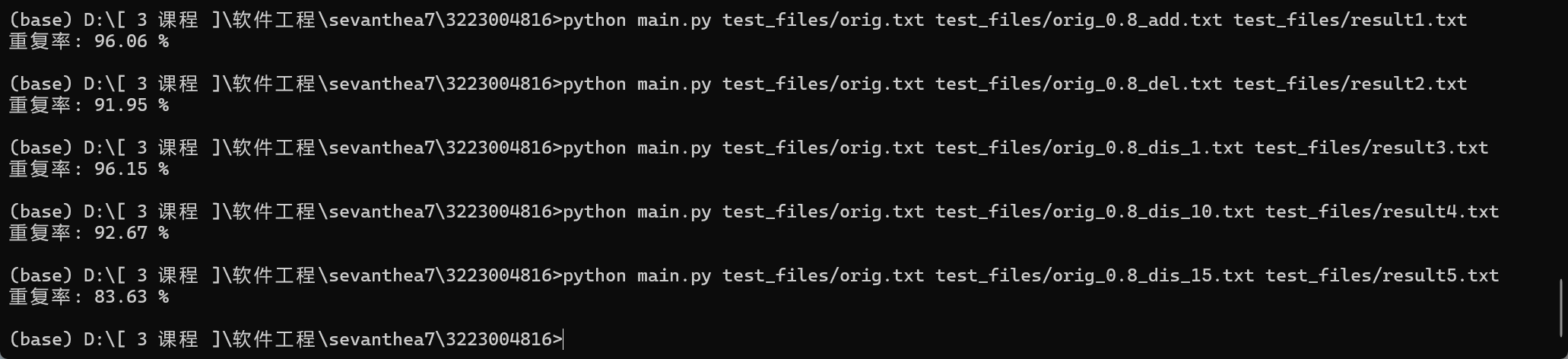
使用cProfile对程序进行分析。
python -m cProfile -o prof.out main_for_test.py test_files/orig.txt test_files/copy.txt result.txt
由于用源程序测试时发现函数单次运行时间过短,无法准确记录,故进行500次重复测试,并对各函数的占用时长取平均值,得到答案。(具体见main_for_test.py文件,除重复执行外,其他与main函数一致)
i. 首次测试结果

结果分析:
- edit_dist (12.67s) 和 LCS (8.84s)
- 占总时间的 ~22%,明显是主要瓶颈。
- 原因:都是
O(m*n)的动态规划,如果文本较长,计算复杂度高。 - 优化方向:
- 使用 NumPy 数组 替代 Python list,向量化计算。
- 如果只需要相似度而非完整矩阵,可尝试空间优化 DP(只保留两行)。
- tokenize (6.37s)
- 占总时间 6%,中文分词耗时较高,尤其是 jieba 对长文本。
- 优化方向:
- 使用 jieba 的精简模式 (cut_for_search=False) 或提前缓存词典。
- 对重复文本可缓存分词结果。
- simhash_res + simhash (~9.7s 总计)
- 计算指纹和海明距离也占用一部分时间。
- 优化方向:对 token 哈希可以批量处理,减少循环。
- 其他函数(jaccard2、ngrams、hamming、read_file):对比来看消耗时间非常低,可以忽略。
ii. 代码修改
- LCS:原先
O(m*n)空间 → 仅保留两行O(n)空间。 - 编辑距离:原先创建
m×n矩阵 → 仅两行O(n),Python list 交换引用代替复制,节省大量时间。 - tokenize:合并两次循环,只遍历
jieba.cut(text)一次。 - SimHash:使用 numpy 数组向量化权重更新,减少 Python 循环,同时对每个 token 将 hash 转二进制数组,再一次性加到权重向量上。
iii. 修改后测试结果及分析

表格列举来看:
| 函数 | 优化前 (s) | 优化后 (s) | 时间差 (s) | 相对提升 (%) |
|---|---|---|---|---|
| main | 34.34 | 17.42 | 16.92 | ~49% |
| similarity_score | 34.33 | 17.41 | 16.92 | ~49% |
| edit_dist | 12.67 | 5.66 | 7.01 | ~55% |
| LCS / lcs | 8.84 | 4.37 | 4.47 | ~51% |
| tokenize | 6.37 | 3.52 | 2.85 | ~45% |
| simhash_res | 4.86 | 3.11 | 1.75 | ~36% |
| simhash | 4.84 | 3.10 | 1.73 | ~36% |
| read_file | 1.15 | 0.56 | 0.58 | ~50% |
| jaccard2 | 0.31 | 0.14 | 0.17 | ~55% |
| ngrams | 0.26 | 0.12 | 0.14 | ~55% |
| hamming | 0.015 | 0.0078 | 0.0076 | ~50% |
整体优化效果明显,main / similarity_score 总耗时几乎减半,说明主要瓶颈函数得到有效优化,整个文本相似度计算流程整体性能接近翻倍加速。
其中:
edit_dist、lcs→ DP 空间优化、减少内存访问 → 提升 ~50%tokenize→ 合并循环、减少中间列表 → 提升 ~45%simhash/simhash_res→ 向量化 + bit_count → 提升 ~36%- 次要函数因为上下游函数耗时变化,而整体耗时下降
下降幅度可视化:

6. 单元测试
(1) 测试设计
1. tokenize 函数
- 普通中文文本 + 语气词:验证能正确去掉无意义词。
- 仅包含无用词:验证返回空列表。
- 空字符串或仅空格:验证边界情况。
- 中英文混合:验证中英文及数字能正确分词。
- 标点符号文本:验证标点处理效果。
- 特殊字符:验证特殊符号不会破坏分词逻辑。
- 长文本重复:验证函数在长文本下性能与稳定性。
- 换行符测试:验证换行不会影响分词。
- 重复词文本:验证重复词能正确统计。
@pytest.mark.parametrize("text, expected", [
("我啊真的喜欢你呢", ["我", "真的", "喜欢", "你"]), # 普通文本 + 语气词
("啊吧吗呢哦嗯", []), # 全是无用词
("", []), # 空字符串
(" ", []), # 仅空格
("我喜欢Python3", ["我", "喜欢", "Python3"]), # 中英文数字混合
("你好!今天吃了吗?", ["你好", "今天", "吃"]), # 包含标点
("测试特殊字符#@$%^", ["测试", "特殊字符"]), # 特殊字符
("长文本"*50, ["长", "文本"]*50), # 长文本重复
("\n换行符测试\n", ["换行符", "测试"]), # 换行符
("重复重复重复", ["重复"]*3), # 重复词
])
def test_tokenize_various_cases(text, expected):
tokens = tokenize(text)
assert tokens == expected
当结果与与预期符合时,通过测试。
2. read_file 与 write_result
使用 tmp_path 临时目录模拟文件操作:
- 写入浮点数并验证保留两位小数。
- 读取不存在的文件时抛出异常,测试异常处理。
def test_read_write_file(tmp_path):
file_path = tmp_path / "test.txt"
# 写入结果
write_result(file_path, 3.1415926)
# 读取文件
content = read_file(file_path)
# 检查保留两位小数
assert "3.14" in content
def test_read_file_not_exist():
with pytest.raises(ValueError):
read_file("non_existent_file.txt")
3. lcs 与 edit_dist
- 构造序列组合
- 空序列。
- 单元素相同与不同。
- 部分匹配与完全匹配。
- 包含重复元素。
- 验证动态规划算法正确性及边界条件
def test_lcs_cases():
assert lcs([], []) == 0 # 空序列
assert lcs(['a'], ['a']) == 1 # 单元素相同
assert lcs(['a','b','c'], ['a','b','c']) == 3 # 全匹配
assert lcs(['a','b'], ['b','a']) == 1 # 部分匹配
assert lcs(['a','a','b'], ['a','b','b']) == 2 # 重复元素
def test_edit_dist_cases():
assert edit_dist([], []) == 0 # 空序列
assert edit_dist(['a'], ['b']) == 1 # 单元素不同
assert edit_dist(['a','b','c'], ['a','c','d']) == 2 # 多元素不同
assert edit_dist(['a','b'], ['a','b']) == 0 # 相同序列
assert edit_dist(['a','b','c'], []) == 3 # 一边空
4. ngrams 与 jaccard2
- n-gram 为 0。
- 空序列。
- 完全相同序列。
- 部分重叠与完全不同序列。
- 验证集合生成和相似度范围
[0,1]的合法性。
def test_ngrams_cases():
assert ngrams([], 2) == set() # 空序列
assert ngrams(['a','b','c'], 2) == {('a','b'), ('b','c')} # n-gram正常
assert ngrams(['a','b','c'], 0) == set() # n=0
def test_jaccard2_cases():
assert jaccard2([], [], 2) == 1.0 # 都空
assert jaccard2(['a','b'], ['a','b'], 2) == 1.0 # 完全相同
assert jaccard2(['a','b'], ['b','c'], 2) == 0.0 # 完全不同
assert 0 <= jaccard2(['a','b','c'], ['b','c','d'], 2) <= 1 # 范围检查
5. simhash 与 simhash_res
- 相同序列指纹一致。
- 不同顺序序列指纹可能不同。
- 验证 SimHash 相似度结果在
[0,1]区间。 - 验证海明距离计算正确。
def test_simhash_cases():
fp1 = simhash(['a','b'])
fp2 = simhash(['a','b'])
fp3 = simhash(['b','a'])
assert fp1 == fp2 # 相同序列指纹相同
assert isinstance(fp1, int)
assert fp1 != fp3 or fp1 == fp3 # 不保证顺序敏感度,可允许相同或不同
def test_simhash_res_cases():
sim = simhash_res(['a','b'], ['a','b'])
sim2 = simhash_res(['a','b'], ['b','a'])
assert 0 <= sim <= 1
assert 0 <= sim2 <= 1
6. hamming
- 不同位组合:部分相同、完全相同、完全不同。
- 验证返回值等于二进制位差数量。
def test_hamming_cases():
assert hamming(0b1010, 0b1001) == 2 # 基本位差
assert hamming(0b1111, 0b1111) == 0 # 相等
assert hamming(0, 0b1111) == 4 # 完全不同
7. 整体思路
- 边界值覆盖:空输入、单元素、重复元素。
- 正常值覆盖:常见文本、数字混合、特殊字符。
- 异常处理覆盖:文件不存在、n=0。
- 极端情况覆盖:长文本、重复词、换行符。
- 输出合法性验证:SimHash 相似度
[0,1],保留小数位正确。
8. 测试方法
pytest -rw test_programs/ -v --cov=./ --cov-report=term-missing
- 使用
pytest参数化测试tokenize的多种情况。 - 使用
tmp_path模拟文件读写,避免实际文件依赖。 - 利用
pytest.raises测试异常处理。 - 结合
--cov统计覆盖率,确保核心函数和边界条件被测试。
输入异常分析详见第七节异常处理。
(2) 测试结果
测试用例详见test_programs/test_all_functions.py
i. 首次测试结果
首先进行了单元测试,第一次测试结果如下

出现了 3 个测试用例失败,都是和 tokenize 函数相关,主要是标点相关以及长文本处理上的问题。
ii. 修改后测试结果
根据问题针对性的进行修改,修正了测试样例和标点的处理方法。覆盖率为91%~100%,其中91%的项目未覆盖完全的主要是测试语句,故整体覆盖较为完整。

7. 计算模块异常处理
(1) LCS 函数异常处理
问题点:输入非列表、元素不是字符串、列表为空
def lcs(a, b):
if not isinstance(a, list) or not isinstance(b, list):
raise TypeError("输入必须为列表")
if not all(isinstance(x, str) for x in a + b):
raise TypeError("列表元素必须为字符串")
if not a or not b:
return 0 # 空序列直接返回0
...
单元测试
def test_lcs_empty():
assert lcs([], ["a", "b"]) == 0
防止非列表或非字符串输入导致的运行时错误。
(2) 编辑距离异常处理
问题点:同样是输入非列表或元素不是字符串
def edit_dist(a, b):
if not isinstance(a, list) or not isinstance(b, list):
raise TypeError("输入必须为列表")
if not all(isinstance(x, str) for x in a + b):
raise TypeError("列表元素必须为字符串")
...
单元测试
def test_edit_dist_wrong_type():
with pytest.raises(TypeError):
edit_dist("abc", ["a", "b"])
确保调用传入合法的 token 序列,避免动态规划计算报错。
(3) n-gram / Jaccard 异常处理
问题点:n <= 0 或 tokens 为空
def ngrams(tokens, n):
if not isinstance(tokens, list):
raise TypeError("tokens 必须为列表")
if not isinstance(n, int):
raise TypeError("n 必须为整数")
if n <= 0:
raise ValueError("n-gram 长度必须大于0")
...
def jaccard2(a, b, n=2):
if not isinstance(n, int):
raise TypeError("n 必须为整数")
...
单元测试
def test_ngrams_negative():
with pytest.raises(ValueError):
ngrams(["a", "b"], -1)
防止无效 n-gram 长度导致计算结果异常。
(4) SimHash / Hamming 异常处理
问题点:tokens 为空或 hashbits 非法
def simhash(tokens, hashbits=64):
if not isinstance(tokens, list):
raise TypeError("tokens 必须为列表")
if not all(isinstance(x, str) for x in tokens):
raise TypeError("tokens 中所有元素必须为字符串")
if hashbits <= 0:
raise ValueError("hashbits 必须大于0")
...
def hamming(x, y):
if not isinstance(x, int) or not isinstance(y, int):
raise TypeError("hamming 输入必须为整数")
def simhash_res(orig_tokens, copy_tokens, hashbits=64):
if not isinstance(hashbits, int) or hashbits <= 0:
raise ValueError("hashbits 必须为正整数")
单元测试
def test_simhash_empty():
assert simhash([]) == 0
def test_simhash_hamming_type_error():
import pytest
with pytest.raises(TypeError):
hamming("abc", 123)
保证 SimHash 计算输入合法,避免 numpy 操作或位运算报错。
(5) 文件读取异常处理
问题点:文件路径非法或文件不存在
def read_file(path):
try:
with open(path, "r", encoding="utf-8") as file_handle:
return file_handle.read()
except FileNotFoundError as exc:
raise ValueError(f"文件 {path} 不存在!") from exc
单元测试
def test_read_file_not_exist():
with pytest.raises(ValueError):
read_file("non_existent_file.txt")
保证输入的文件路径合法,避免 open() 打开不存在文件时报错。
8. 最终结果与总结
在本次论文查重项目的开发过程中,我深刻体会到软件工程实践与理论知识的结合是多么重要。最初,我在实现相似度计算时遇到了一些问题,例如 SimHash 对短文本不敏感导致重复率总是 1.0、jieba 分词库在初始化时打印大量日志干扰输出,以及单元测试报错无法正确导入模块等。通过查阅资料、调试和逐步分析,我学会了:
- 算法调整与优化
- 针对 SimHash 的问题,我意识到它对短文本或少量 token 不够敏感,因此结合 LCS、编辑距离和 Jaccard 指标进行加权计算,最终采用lcs0.2和simhash1.0的配比使最终重复率更加合理且运算速度较快。
- 对 LCS 和编辑距离采用滚动数组优化,既保证了计算正确性,也减少了内存消耗。
- 异常处理与输入检查
- 在开发过程中,我发现一些函数在输入空列表或非法参数时容易出错。经过改正,我增加了输入类型和边界检查,同时用单元测试覆盖了各种异常场景,使程序更加健壮。
- 调试与工程实践
- 最初 pytest 无法导入模块的问题,让我学会了正确设置 Python 包结构和运行路径。
- 对 jieba 输出日志的处理,让我掌握了设置日志等级的方法,保持程序输出整洁。
- 通过计时和性能分析,我发现部分函数在大文本下效率低,于是对算法进行了优化,提高了运行速度。
整个过程中,我不断 发现问题、分析原因、尝试解决方案、验证效果,这种迭代改进让我对 Python 编程、文本相似度算法以及软件工程实践都有了更深刻的理解。通过这个项目,我不仅掌握了查重算法的实现方法,更提升了调试能力、异常处理能力和工程实践能力,对今后的软件开发与科研工作都有很大帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号