【论文笔记】(FGSM)Explaining and Harnessing Adversarial Examples
本文发表于 ICLR 2015,提出了经典的攻击方法 - FGSM(Fast Gradient Sign Method),这篇博客的第1-5节为重点部分,包括原文第5节的公式推导。
1. 对抗扰动
寻找对抗样本的目标是:1)模型将其错误分类;2)人眼无法分辨对抗扰动。已知对抗样本 \(\tilde{x}\) 的公式为:
其中,\(x\) 为干净样本/原始样本/自然样本,\(\eta\) 为对抗扰动。需要对扰动加以限制以保证扰动小得难以被人眼识别:\(||\eta||_{\infty}<\epsilon\),这个约束表示:图片中每个像素点的扰动范围必须小于 \(\epsilon\)。
L-infinity norm:\(||x||_\infty=\max(|x_i|)\),其中 \(x_i\) 为 向量\(x\) 中的元素。
2. 线性模型
对于线性模型,考虑重\(w\)与对抗样本\(\tilde{x}\)的点积:
\(w^T\eta\) 是增量,可以令\(\eta={\rm sign}(w)\)来最大化这个增量,前提是保证 \(L_\infty\) 范数限制(即\(||\eta||_{\infty}<\epsilon\))。不难算出,\(w^{T}\eta=w^T{\rm sign}(w)=||w||_1\)。
如果\(w\)的维度为\(n\),元素的平均大小为\(m\),那么增量为\(\epsilon mn\)。
\(||\eta||_\infty\)不随\(n\)改变,但增量随\(n\)线性增长,所以对于高维问题,可以对输入进行许多很小的改变,合起来对输出就是一个很大的改变。作者将其描述为"accidental steganography",所以如果一个简单的线性模型的输入的维度足够大,它就可以找到对抗样本。
3. 非线性模型
假设 \(\theta\) 为模型的参数,\(x\) 为模型的输入,\(y\) 为目标输出,\(J(\theta,x,y)\) 为用于训练神经网络的损失函数。FGSM 给出的对抗扰动为:
其中的梯度可由 BP 计算。不难理解,当输入 \(x\) 沿着 \(\triangledown_x J(\theta,x,y)\) 方向梯度下降一点点的话,模型将它预测为 \(y\) 的可能性越大,但根据公式(1)可知,对抗样本的生成是 \(x\) 加上 \(\epsilon{\rm sign}(\triangledown_x J(\theta,x,y))\),也就是沿着$ \triangledown_x J(\theta,x,y)$ 方向增加一点点,即沿着梯度下降相反的方向走,变化的值由 \(\epsilon\) 决定,所以这样得到的 \(\tilde{x}\) 更小的可能被模型预测为 \(y\)。

图1.使用 FGSM 构造对抗样本,其中模型选择 GoogLeNet,数据集选择 ImageNet,\(\epsilon=0.007\)。
4. 线性模型的对抗训练 vs 权值衰减
4.1 二分类
首先考虑二分类的逻辑回归问题,假设标签 \(y\in \{-1,1\}\),\(P(\hat{y}=1)=\sigma(w^Tx+b)\),其中 \(\sigma\) 是 sigmoid 函数,那么:
将这两种情况整理为一种表达式:
带入两种情况的值可解得 \(a=1\),\(b=0\),所以有:
接下来考虑损失函数,对于一组样本,交叉熵损失为:
根据 sigmoid 的性质之一:\(\log \sigma(x) = -\zeta(-x)\),公式(4)可变为:
其中,\(\zeta(z)=\log(1+\exp(z))\)为 softplus 函数,note 它的导数为\(\zeta'(z)=\frac{e^z}{1+e^z}=\sigma(z)\)。
接下来考虑扰动 \(\eta\),对于一个样本 \(x\) 和它的真实标签 \(y_{true}\):
\({\rm sign}\)中的第二项大于0,可省略,即:
结合\(w^T{\rm sign}(w)=||w||_1\),带入公式(5)可得:
[Note:公式(8)跟原文不一样,个人认为论文中的是错误的,公式(7)一定带有 \(y_{true}\) 项,否则扰动不随 label 的不同而改变,将是个定值,这是不对的。]
这有点类似于 L1 正则化。区别是,L1惩罚项是在对抗的训练期间从模型的激活中减去,而不是添加。 如果模型训练出精确的预测能力以使\(\zeta\)饱和,那么惩罚项会开始消失。但不保证一定饱和,在欠拟合的情况下,对抗训练会加剧欠拟合。所以,作者将L1权值衰减视为"worst case"。
4.2 多分类
考虑多分类的 softmax 回归问题,L1 权值衰减会变得更加悲观,因为它将softmax的每个输出视为独立的量,而实际上无法找到与所有类的权重向量对齐的单个向量\(\eta\)。在具有多个隐藏单元的深度网络中,权值衰减高估了扰动造成的损害。L1权值衰减高估了对抗样本能造成的损害,所以应当使用比特征精度\(\epsilon\)更小的L1权值衰减系数。
在MNIST上训练maxout网络,当\(\epsilon=0.25\)时对抗训练得到了不错的结果。在对模型的第一层应用L1权值衰减时,作者发现\(\epsilon=0.0025\)都太大了,导致模型在训练集上出现超过5% 的误差。很小的权值衰减系数能提高训练的成功率,但是没有起到正则化的作用。
5. DNNs 的对抗训练
相比于浅层的线性模型,深度网络至少能表示出抵抗对抗扰动的函数。
Szegedy表明,在混合了对抗样本和干净样本的数据集上进行训练可以一定程度的对神经网络正则化。
作者给出了一个基于FGSM的对抗训练方法,这也是一种有效的regularizer:
在实验中,作者令\(\alpha=0.5\)。这种对抗训练方法意味着不断更新对抗样本,以使它们对抗当前版本的模型。使用此方法来训练使用dropout的maxout网络,错误率为0.84%,而没采用对抗训练的网络错误率为0.94%。
作者在训练集的对抗样本上没有取得过0错误率,他们给出了两个解决方法:
- 1.使模型更大:每层使用1600个单元(之前为240个)。
当没采用对抗训练,模型会有些过拟合,测试集上的错误率为1.14%。当使用了对抗训练,验证集的错误率十分缓慢地随着时间趋于平稳。初始的maxout实验使用了early stopping,当验证集的错误率在100个epoch内没有下降后终止学习。作者发现,即使验证集错误率十分平坦,但对抗验证集(adversarial validation set error)并非如此,所以:
- 2.在对抗验证集上也使用early stopping。
采用这两点后,作者在MNIST数据集上进行实验,错误率为0.782%。
对抗样本还可以在两个模型之间转移,但经过对抗训练的模型显示出更高的鲁棒性:模型采用对抗训练,当对抗样本由此模型生成时:模型错误率为19.6%;当对抗样本由另一个模型生成时:模型错误率为40.9%。错误分类的样本的平均置信度为81.4%。 作者还发现模型的权重发生了显着变化,采用对抗训练的模型的权重明显更具本地化和可解释性(见图 3)。

图3. 在MNIST上训练的maxout网络的权重可视化。每行展示了单个maxout单元的filter。 左)无对抗训练的模型;右)使用对抗性训练的模型。
噪声会导致目标函数值降低,可以将对抗训练视为在一组有噪输入中进行样本挖掘,以便通过仅考虑那些强烈抵制分类的噪声点来更有效地训练。作为对照实验,作者训练了一个带有噪声的maxout网络,训练的噪声为:1.随机添加\(\pm \epsilon\)到每个像素; 2.添加噪声(噪声服从\(U(-\epsilon,\epsilon)\))到每个像素。在FGSM生成的对抗样本上,1的错误率为86.2%,置信度为97.3%;2的错误率为90.4%,置信度为97.8%。
符号函数的导数处处为0或未定义(原点处),因此基于FGSM对抗训练的模型无法预测adversary将如何对参数的变化做出反应。如果改为基于小幅度旋转或添加缩放梯度(scaled gradient)的对抗样本,那么扰动过程本身是可微的,并且学习过程中可以看到adversary的反应。
这里提到了一个问题:扰动输入更好,还是扰动隐藏层更好,或是二者都被扰动?这里的结论是不一致的。Szegedy等人通过对sigmoidal网络实验总结出:当对抗扰动应用在隐藏层时,正则效果最好。文本中作者的实验基于FGSM,他们发现具有无界激活(unbounded activation functions)的隐藏单元的网络只是通过使隐藏单元的激活非常大来做出响应,因此通常最好只扰动原始输入。在Rust模型等饱和模型上,输入的扰动与隐藏层的扰动相当。基于旋转隐藏层的扰动解决了无界激活增长的问题,从而使扰动相对更小。使用隐藏层的旋转扰动,作者成功地训练了maxout网络。然而,这并没有产生与输入层一样正则化效果。神经网络的最后一层(linear-sigmoid或linear-softmax层)不是隐藏层最后一层的通用近似,这表明在对隐藏层最后一层应用对抗扰动时可能会遇到欠拟合问题。作者得到的最佳结果是使用对隐藏层的扰动进行训练,但是没涉及到隐藏层的最后一层。
6.不同类型的模型capacity
人们直觉上认为capacity低的模型无法准确预测,但并非如此,如RBF网络:
只能准确预测\(\mu\)附近\(y=1\)的类,RBF预测对抗样本的置信度很低:作者选择无隐藏层的浅层RBF对(MNIST上用FGSM生成的)对抗样本进行实验,错误率为55.4%,置信度为1.2%,对干净样本的置信度为60.6%。这种低capacity的模型错误率高是正常的,但它们通过在自己不"理解"的点上大大降低其置信度来做出正确的反应。
RBF的泛化能力不好。可以将RBF网络中的线性单元和RBF单元视为精确度-召回率(precision-recall)曲线上的不同点,线性单元召回率高,精确度低;RBF单元精确度高,召回率低。受这个想法的启发,作者在下文对一些包含二阶单元(quadratic units 如RBF单元中有二次项)的模型进行探索。
7.对抗样本泛化的原因
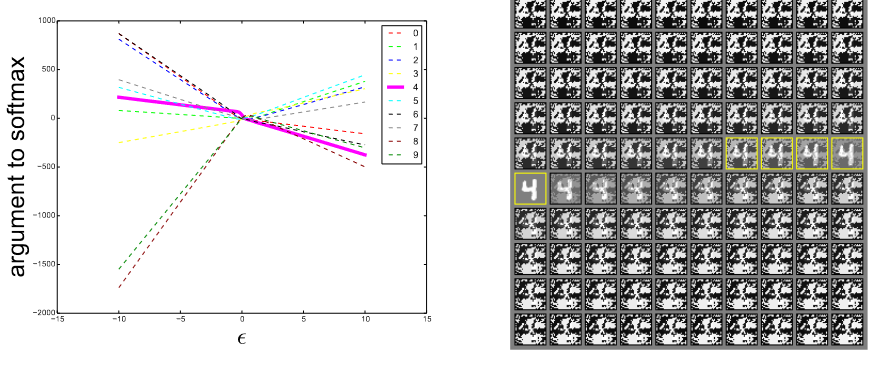
图4 简单训练的maxout网络:左)在单个输入样本上改变\(\epsilon\)的值,观察10个MNIST类中每个softmax层的参数(未归一化的log概率)。正确的类是4。可以看到每个类别的概率与\(\epsilon\)呈分段线性,错误的分类存在于\(\epsilon\)值的广泛区域。右)用于生成左图的输入。左上为负数的\(\epsilon\),右下为正值得\(\epsilon\),黄框中的为正确分类的输入。
1.对抗样本特别多,且泛化能力强,同一对抗样本会被不同模型错误分类:线性的观点是,对抗样本出现在广泛的子空间中。如图4,通过追踪\(\epsilon\)不同的值可以看到,对抗样本出现在由FGSM定义的一维子空间的连续区域中,而不是特定的区域。
2.一个对抗样本还会被不同的模型错误分成同一类:这是因为机器学习算法的泛化性,在训练集的不同子集上训练时,模型能学到大致相同的权重,所以,分类权重的稳定性返回来引起了对抗样本的稳定性。
8.其他假设
作者反驳了两个假设:
1.生成训练可以在训练过程中提供更多的约束或限制,或者使模型学习如何分辨 "real" 或 "fake" 的数据,并且只对"real"的数据更加自信。
2.单个模型有奇怪的行为特点(strange quirks),但对多个模型进行平均(模型平均)可能会抵抗对抗样本的干扰。
9.论文总结
此篇论文提出了以下结论:
- 对抗样本可以解释为高维点积的一种特征属性,它们的产生是由于模型过于线性化,而非过于非线性化。
- 对抗样本在不同模型中的泛化可以解释为对抗扰动与模型的权重向量高度一致,且不同模型(当执行相同任务时,如手写数字分类)在训练中学习的函数相同。
- 扰动的方向是最重要的,而非空间中的特定点。对抗样本广泛存在于空间中。
- 对抗扰动会泛化到不同的干净样本中。
- 提出了生成对抗样本的方法——FGSM。
- 作者证明了对抗训练可以提供正则作用,甚至比dropout更强。
- 作者进行了控制实验,但未能使用简单 效率低的正则化器来重现这种效果。
- 易于优化的模型容易收到对抗样本的干扰。
- 线性模型缺乏对对抗扰动的抵抗能力,具有隐藏层结构的模型才能通过对抗训练来抵抗它们。
- RBF网络对对抗样本有抵抗能力。
- 为输入分布建模而训练的模型对对抗样本没有抵抗能力。
- 集成对对抗样本没有抵抗能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号