RabbitMQ集群
RabbitMQ集群原理
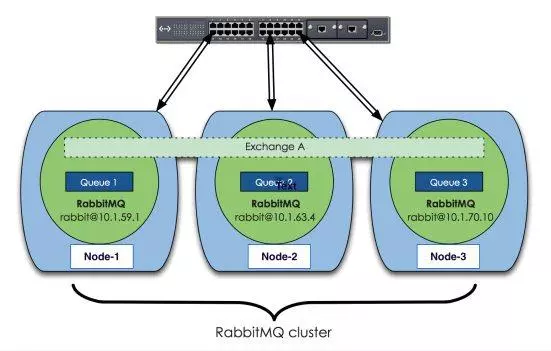
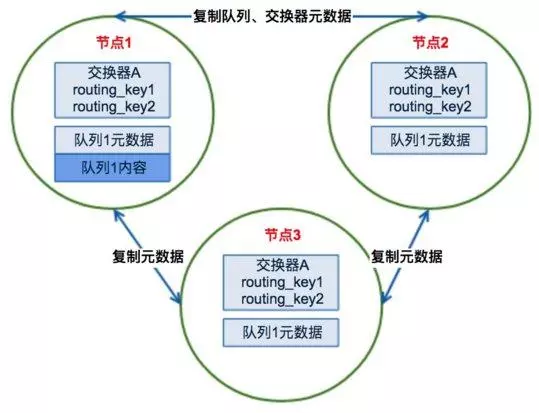
(1)RabbitMQ集群元数据的同步
RabbitMQ集群会始终同步四种类型的内部元数据(类似索引):
a.队列元数据:队列名称和它的属性;
b.交换器元数据:交换器名称、类型和属性;
c.绑定元数据:一张简单的表格展示了如何将消息路由到队列;
d.vhost元数据:为vhost内的队列、交换器和绑定提供命名空间和安全属性;
因此,当用户访问其中任何一个RabbitMQ节点时,通过rabbitmqctl查询到的queue/user/exchange/vhost等信息都是相同的。
(2)为何RabbitMQ集群仅采用元数据同步的方式
我想肯定有不少同学会问,想要实现HA方案,那将RabbitMQ集群中的所有Queue的完整数据在所有节点上都保存一份不就可以了么?(可以类似MySQL的主主模式嘛)这样子,任何一个节点出现故障或者宕机不可用时,那么使用者的客户端只要能连接至其他节点能够照常完成消息的发布和订阅嘛。
我想RabbitMQ的作者这么设计主要还是基于集群本身的性能和存储空间上来考虑。第一,存储空间,如果每个集群节点都拥有所有Queue的完全数据拷贝,那么每个节点的存储空间会非常大,集群的消息积压能力会非常弱(无法通过集群节点的扩容提高消息积压能力);第二,性能,消息的发布者需要将消息复制到每一个集群节点,对于持久化消息,网络和磁盘同步复制的开销都会明显增加。
(3)RabbitMQ集群发送/订阅消息的基本原理
场景1、客户端直接连接队列所在节点
如果有一个消息生产者或者消息消费者通过amqp-client的客户端连接至节点1进行消息的发布或者订阅,那么此时的集群中的消息收发只与节点1相关,这个没有任何问题;如果客户端相连的是节点2或者节点3(队列1数据不在该节点上),那么情况又会是怎么样呢?
场景2、客户端连接的是非队列数据所在节点
如果消息生产者所连接的是节点2或者节点3,此时队列1的完整数据不在该两个节点上,那么在发送消息过程中这两个节点主要起了一个路由转发作用,根据这两个节点上的元数据(也就是上文提到的:指向queue的owner node的指针)转发至节点1上,最终发送的消息还是会存储至节点1的队列1上。
同样,如果消息消费者所连接的节点2或者节点3,那这两个节点也会作为路由节点起到转发作用,将会从节点1的队列1中拉取消息进行消费。
配置集群前须知
主机名解析
RabbitMQ节点使用域名相互寻址,因此所有集群成员的主机名必须能够从所有集群节点解析,可以修改hosts文件或者使用DNS解析
如果要使用节点名称的完整主机名(RabbitMQ默认为短名称),并且可以使用DNS解析完整的主机名,则可能需要调查设置环境变量 RABBITMQ_USE_LONGNAME = true
创建集群的方法用多种
通过配置文件
rabbitmqctl手动配置
通过插件(如:AWS(EC2)实例发现,Kubernetes发现,基于Consul的发现,基于etcd的发现)
一个集群的组成可以动态改变,所有的RabbitMQ开始作为单个节点运行,这些节点可以加入到集群,然后也可以再次脱离集群转回单节点
RabbitMQ集群可以容忍单个节点的故障。节点可以随意启动和通知,只要它们可以与在关闭时已知的集群成员节点联系
集群意味着在局域网使用,不建议运行跨广域网的集群
节点可以是disk节点或RAM节点
RAM节点将内部数据库表存储在RAM中。这不包括消息,消息存储索引,队列索引和其他节点状态
在90%以上的情况下,您希望所有节点都是磁盘节点; RAM节点是一种特殊情况,可用于改善高排队,交换或绑定流失的性能集群。RAM节点不提供有意义的更高的消息速率。如有疑问,请仅使用磁盘节点。
由于RAM节点仅将内部数据库表存储在RAM中,因此它们必须在启动时从对等节点同步它们。这意味着群集必须至少包含一个磁盘节点。因此无法手动删除集群中剩余的最后一个磁盘节点
rabbitmqctl配置集群
| hostname | ip | system | RabbitMQ |
| rabbit1 | 192.168.88.1 | CentOS7.2.1511 | 3.7.0 |
| rabbit2 | 192.168.88.2 | ||
| rabbit3 | 192.168.88.3 |
绑定hosts文件
192.168.88.1 rabbit1
192.168.88.2 rabbit2
192.168.88.3 rabbit3
在三台机器安装RabbitMQ
设置节点互相验证:Erlang Cookie
RabbitMQ节点和CLI工具(例如rabbitmqctl)使用cookie来确定它们是否被允许相互通信,要使两个节点能够通信,它们必须具有相同的共享密钥,称为Erlang Cookie.
Cookie只是一个字符串,最多可以有255个字符。它通常存储在本地文件中。该文件必须只能由所有者访问(400权限)。每个集群节点必须具有相同的 cookie,文件位置/var/lib/rabbitmq/.erlang.cookie, 把rabbit2、rabbit3设置成和rabbit2一样的即可,权限是400
正常方式启动所有节点
rabbitmq-server -detached rabbitmq-server -detached rabbitmq-server -detached
现在启动了三个独立的RabbitMQ,我们用cluster_status命令查看集群状态
[root@rabbit1 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit1 ...
[{nodes,[{disc,[rabbit@rabbit1]}]},
{running_nodes,[rabbit@rabbit1]},
{cluster_name,<<"rabbit@rabbit1">>},
{partitions,[]},
{alarms,[{rabbit@rabbit1,[]}]}]
[root@rabbit2 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit2 ...
[{nodes,[{disc,[rabbit@rabbit2]}]},
{running_nodes,[rabbit@rabbit2]},
{cluster_name,<<"rabbit@rabbit2">>},
{partitions,[]},
{alarms,[{rabbit@rabbit2,[]}]}]
[root@rabbit3 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit3 ...
[{nodes,[{disc,[rabbit@rabbit3]}]},
{running_nodes,[rabbit@rabbit3]},
{cluster_name,<<"rabbit@rabbit3">>},
{partitions,[]},
{alarms,[{rabbit@rabbit3,[]}]}]
为了连接集群中的三个节点,我们把rabbit@c2和rabbit@c3节点加入到rabbit@c1节点集群
首先,在rabbit@c1的簇中加入rabbit@c2
1、停止rabbir@c2的rabbitmq应用程序,
2、加入rabbit@c1集群
3、然后启动RabbitMQ程序
注意:加入集群会隐式重置节点,从而删除此节点上以前存在的所有资源和数据
[root@rabbit2 ~]# rabbitmqctl stop_app Stopping rabbit application on node rabbit@rabbit2 ... [root@rabbit2 ~]# rabbitmqctl join_cluster rabbit@rabbit1 Clustering node rabbit@rabbit2 with rabbit@rabbit1 [root@rabbit2 ~]# rabbitmqctl start_app Starting node rabbit@rabbit2 ... completed with 0 plugins.
现在我们在rabbit1、rabbit2任意一个节点上查看集群状态,我们可以看到这两个节点加入了一个集群
[root@rabbit1 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit1 ...
[{nodes,[{disc,[rabbit@rabbit1,rabbit@rabbit2]}]},
{running_nodes,[rabbit@rabbit2,rabbit@rabbit1]},
{cluster_name,<<"rabbit@rabbit1">>},
{partitions,[]},
{alarms,[{rabbit@rabbit2,[]},{rabbit@rabbit1,[]}]}]
我们再把rabbit3节点加入到这个集群
[root@rabbit3 ~]# rabbitmqctl stop_app Stopping rabbit application on node rabbit@rabbit3 ... [root@rabbit3 ~]# rabbitmqctl join_cluster rabbit@rabbit1 Clustering node rabbit@rabbit3 with rabbit@rabbit1 [root@rabbit3 ~]# rabbitmqctl start_app Starting node rabbit@rabbit3 ... completed with 0 plugins.
通过任何节点上的cluster_status命令,我们可以看到这三个节点加入了一个集群
[root@rabbit1 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit1 ...
[{nodes,[{disc,[rabbit@rabbit1,rabbit@rabbit2,rabbit@rabbit3]}]},
{running_nodes,[rabbit@rabbit3,rabbit@rabbit2,rabbit@rabbit1]},
{cluster_name,<<"rabbit@rabbit1">>},
{partitions,[]},
{alarms,[{rabbit@rabbit3,[]},{rabbit@rabbit2,[]},{rabbit@rabbit1,[]}]}]
[root@rabbit2 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit2 ...
[{nodes,[{disc,[rabbit@rabbit1,rabbit@rabbit2,rabbit@rabbit3]}]},
{running_nodes,[rabbit@rabbit3,rabbit@rabbit1,rabbit@rabbit2]},
{cluster_name,<<"rabbit@rabbit1">>},
{partitions,[]},
{alarms,[{rabbit@rabbit3,[]},{rabbit@rabbit1,[]},{rabbit@rabbit2,[]}]}]
[root@rabbit3 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit3 ...
[{nodes,[{disc,[rabbit@rabbit1,rabbit@rabbit2,rabbit@rabbit3]}]},
{running_nodes,[rabbit@rabbit1,rabbit@rabbit2,rabbit@rabbit3]},
{cluster_name,<<"rabbit@rabbit1">>},
{partitions,[]},
{alarms,[{rabbit@rabbit1,[]},{rabbit@rabbit2,[]},{rabbit@rabbit3,[]}]}]
通过遵循上述步骤,我们可以在集群正在运行的同时随时向集群添加新节点
已加入群集的节点可随时停止。他们也可以崩溃。在这两种情况下,群集的其余部分都会继续运行,并且节点在再次启动时会自动“跟上”(同步)其他群集节点。
我们关闭rabbit@rabbit1和rabbit@rabbit3,并检查每一步中的集群状态
[root@rabbit1 ~]# rabbitmqctl stop
Stopping and halting node rabbit@rabbit1 ...
[root@rabbit2 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit2 ...
[{nodes,[{disc,[rabbit@rabbit1,rabbit@rabbit2,rabbit@rabbit3]}]},
{running_nodes,[rabbit@rabbit3,rabbit@rabbit2]},
{cluster_name,<<"rabbit@rabbit1">>},
{partitions,[]},
{alarms,[{rabbit@rabbit3,[]},{rabbit@rabbit2,[]}]}]
[root@rabbit3 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit3 ...
[{nodes,[{disc,[rabbit@rabbit1,rabbit@rabbit2,rabbit@rabbit3]}]},
{running_nodes,[rabbit@rabbit2,rabbit@rabbit3]},
{cluster_name,<<"rabbit@rabbit1">>},
{partitions,[]},
{alarms,[{rabbit@rabbit2,[]},{rabbit@rabbit3,[]}]}]
[root@rabbit3 ~]# rabbitmqctl stop
Stopping and halting node rabbit@rabbit3 ...
[root@rabbit2 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit2 ...
[{nodes,[{disc,[rabbit@rabbit1,rabbit@rabbit2,rabbit@rabbit3]}]},
{running_nodes,[rabbit@rabbit2]},
{cluster_name,<<"rabbit@rabbit1">>},
{partitions,[]},
{alarms,[{rabbit@rabbit2,[]}]}]
现在我们再次启动节点,在我们继续检查集群状态时
[root@rabbit3 ~]# rabbitmq-server -detached
[root@rabbit3 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit3 ...
[{nodes,[{disc,[rabbit@rabbit1,rabbit@rabbit2,rabbit@rabbit3]}]},
{running_nodes,[rabbit@rabbit2,rabbit@rabbit3]},
{cluster_name,<<"rabbit@rabbit1">>},
{partitions,[]},
{alarms,[{rabbit@rabbit2,[]},{rabbit@rabbit3,[]}]}]
[root@rabbit2 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit2 ...
[{nodes,[{disc,[rabbit@rabbit1,rabbit@rabbit2,rabbit@rabbit3]}]},
{running_nodes,[rabbit@rabbit3,rabbit@rabbit2]},
{cluster_name,<<"rabbit@rabbit1">>},
{partitions,[]},
{alarms,[{rabbit@rabbit3,[]},{rabbit@rabbit2,[]}]}]
[root@rabbit1 ~]# rabbitmq-server -detached
[root@rabbit1 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit1 ...
[{nodes,[{disc,[rabbit@rabbit1,rabbit@rabbit2,rabbit@rabbit3]}]},
{running_nodes,[rabbit@rabbit2,rabbit@rabbit3,rabbit@rabbit1]},
{cluster_name,<<"rabbit@rabbit1">>},
{partitions,[]},
{alarms,[{rabbit@rabbit2,[]},{rabbit@rabbit3,[]},{rabbit@rabbit1,[]}]}]
[root@rabbit2 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit2 ...
[{nodes,[{disc,[rabbit@rabbit1,rabbit@rabbit2,rabbit@rabbit3]}]},
{running_nodes,[rabbit@rabbit1,rabbit@rabbit3,rabbit@rabbit2]},
{cluster_name,<<"rabbit@rabbit1">>},
{partitions,[]},
{alarms,[{rabbit@rabbit1,[]},{rabbit@rabbit3,[]},{rabbit@rabbit2,[]}]}]
[root@rabbit3 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit3 ...
[{nodes,[{disc,[rabbit@rabbit1,rabbit@rabbit2,rabbit@rabbit3]}]},
{running_nodes,[rabbit@rabbit1,rabbit@rabbit2,rabbit@rabbit3]},
{cluster_name,<<"rabbit@rabbit1">>},
{partitions,[]},
{alarms,[{rabbit@rabbit1,[]},{rabbit@rabbit2,[]},{rabbit@rabbit3,[]}]}]
一些重要的警告:
当整个集群关闭时,最后一个关闭的节点必须是第一个要联机的节点。
如果要脱机的最后一个节点无法恢复,可以使用forget_cluster_node命令将其从群集中删除
如果所有集群节点同时停止并且不受控制(例如断电),则可能会留下所有节点都认为其他节点在其后停止的情况。在这种情况下,您可以在一个节点上使用force_boot命令使其再次可引导
集群移除节点
当节点不再是节点的一部分时,需要从集群中明确地删除节点。我们首先从集群中删除rabbit@rabbit3,并将其返回到独立操作
在rabbit@rabbit3上:
1、我们停止RabbitMQ应用程序,
2、重置节点
3、重新启动RabbitMQ应用程序
[root@rabbit3 ~]# rabbitmqctl stop_app Stopping rabbit application on node rabbit@rabbit3 ... [root@rabbit3 ~]# rabbitmqctl reset Resetting node rabbit@rabbit3 ... [root@rabbit3 ~]# rabbitmqctl start_app Starting node rabbit@rabbit3 ... completed with 0 plugins.
在节点上 运行cluster_status命令确认rabbit@rabbit3现在不再是集群的一部分并独立运行
[root@rabbit3 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit3 ...
[{nodes,[{disc,[rabbit@rabbit3]}]},
{running_nodes,[rabbit@rabbit3]},
{cluster_name,<<"rabbit@rabbit3">>},
{partitions,[]},
{alarms,[{rabbit@rabbit3,[]}]}]
[root@rabbit1 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit1 ...
[{nodes,[{disc,[rabbit@rabbit1,rabbit@rabbit2]}]},
{running_nodes,[rabbit@rabbit2,rabbit@rabbit1]},
{cluster_name,<<"rabbit@rabbit1">>},
{partitions,[]},
{alarms,[{rabbit@rabbit2,[]},{rabbit@rabbit1,[]}]}]
[root@rabbit2 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit2 ...
[{nodes,[{disc,[rabbit@rabbit1,rabbit@rabbit2]}]},
{running_nodes,[rabbit@rabbit1,rabbit@rabbit2]},
{cluster_name,<<"rabbit@rabbit1">>},
{partitions,[]},
{alarms,[{rabbit@rabbit1,[]},{rabbit@rabbit2,[]}]}]
我们也可以远程删除节点,例如,在处理无响应的节点时,这很有用
比如:我们在节点rabbit@rabbit2上把rabbit@rabbit1从集群中移除
[root@rabbit1 ~]# rabbitmqctl stop_app Stopping rabbit application on node rabbit@rabbit1 ... [root@rabbit2 ~]# rabbitmqctl forget_cluster_node rabbit@rabbit1 Removing node rabbit@rabbit1 from the cluster
请注意,rabbit1仍然认为它与rabbit2集群 ,并试图启动它将导致错误。我们需要重新设置才能重新启动。
[root@rabbit1 ~]# rabbitmqctl reset #必须要重置 Resetting node rabbit@rabbit1 ... [root@rabbit1 ~]# rabbitmqctl start_app Starting node rabbit@rabbit1 ... completed with 0 plugins.
现在查看集群状态,三个节点都时作为独立的节点
请注意,rabbit@rabbit2保留了簇的剩余状态,而rabbit@rabbit1 和rabbit@rabbit3是刚刚初始化的RabbitMQ。如果我们想重新初始化rabbit@rabbit2,我们按照与其他节点相同的步骤进行:
[root@rabbit2 ~]# rabbitmqctl stop_app Stopping rabbit application on node rabbit@rabbit2 ... [root@rabbit2 ~]# rabbitmqctl reset Resetting node rabbit@rabbit2 ... [root@rabbit2 ~]# rabbitmqctl start_app Starting node rabbit@rabbit2 ... completed with 0 plugins.
主机名更改
RabbitMQ节点使用主机名相互通信。因此,所有节点名称必须能够解析所有集群对等的名称。像rabbitmqctl这样的工具也是如此
除此之外,默认情况下RabbitMQ使用系统的当前主机名来命名数据库目录。如果主机名更改,则会创建一个新的空数据库。为了避免数据丢失,建立一个固定和可解析的主机名至关重要。每当主机名更改时,您应该重新启动RabbitMQ
如果要使用节点名称的完整主机名(RabbitMQ默认为短名称),并且可以使用DNS解析完整的主机名,则可能需要调查设置环境变量 RABBITMQ_USE_LONGNAME = true
从客户端连接到群集
客户端可以正常连接到群集中的任何节点。如果该节点出现故障,并且集群的其余部分仍然存在,那么客户端应该注意到已关闭的连接,并且应该能够重新连接到群集的一些幸存的成员。通常,将节点主机名或IP地址烧入客户端应用程序是不可取的:这会引入不灵活性,并且如果集群配置发生更改或集群中节点数发生更改,则需要编辑,重新编译和重新部署客户端应用程序。相反,我们推荐一个更抽象的方法:这可能是一个动态的DNS服务,它具有非常短的TTL配置,或者一个普通的TCP负载均衡器,或者用起搏器或类似技术实现的某种移动IP。一般来说
具有RAM节点的集群
RAM节点只将其元数据保存在内存中。由于RAM节点不必像光盘节点那样写入光盘,它们可以更好地执行。但是请注意,由于永久队列数据总是存储在磁盘上,因此性能改进将仅影响资源管理(例如添加/删除队列,交换或虚拟主机),但不会影响发布速度或消耗速度
RAM节点是高级用例; 设置你的第一个群集时,你应该不使用它们。您应该有足够的光盘节点来处理您的冗余要求,然后在需要时添加额外的RAM节点进行缩放
只包含RAM节点的集群是脆弱的; 如果群集停止,您将无法再次启动, 并将丢失所有数据。RabbitMQ将阻止在许多情况下创建RAM节点的群集,但是它不能完全阻止它
这里的例子仅仅为了简单起见,显示了具有一个光盘和一个RAM节点的集群; 这样的集群是一个糟糕的设计选择
创建RAM节点
我们可以在首次加入集群时将节点声明为RAM节点。像之前一样,我们使用rabbitmqctl join_cluster来完成此 操作,但传递 --ram标志
rabbit2$ rabbitmqctl stop_app
Stopping node rabbit@rabbit2 ...done
.
rabbit2$ rabbitmqctl join_cluster --ram rabbit@rabbit1
Clustering node rabbit@rabbit2 with [rabbit@rabbit1] ...done.
rabbit2$ rabbitmqctl start_app
Starting node rabbit@rabbit2 ...done.
RAM节点在集群状态中显示为:
rabbit1$ rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit1 ...
[{nodes,[{disc,[rabbit@rabbit1]},{ram,[rabbit@rabbit2]}]},
{running_nodes,[rabbit@rabbit2,rabbit@rabbit1]}]
...done.
rabbit2$ rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit2 ...
[{nodes,[{disc,[rabbit@rabbit1]},{ram,[rabbit@rabbit2]}]},
{running_nodes,[rabbit@rabbit1,rabbit@rabbit2]}]
...done.
更改节点类型
我们可以将节点的类型从ram更改为disc,反之亦然。假设我们想要颠倒rabbit @ rabbit2和rabbit @ rabbit1的类型 ,将前者从ram节点转换为disc节点,将后者从disc节点转换为ram节点。要做到这一点,我们可以使用 change_cluster_node_type命令。该节点必须先停止
rabbit2$ rabbitmqctl stop_app Stopping node rabbit@rabbit2 ...done. rabbit2$ rabbitmqctl change_cluster_node_type disc Turning rabbit@rabbit2 into a disc node ... ...done. Starting node rabbit@rabbit2 ...done. rabbit1$ rabbitmqctl stop_app Stopping node rabbit@rabbit1 ...done. rabbit1$ rabbitmqctl change_cluster_node_type ram Turning rabbit@rabbit1 into a ram node ... rabbit1$ rabbitmqctl start_app Starting node rabbit@rabbit1 ...done.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号