
OCI 2025 Generative AI Professional 笔记
第二章只是简单的概念解释,比较粗略,重点在第三章
2 Fundamentals of Large Language Models
OCI学习模块:大型语言模型介绍
什么是语言模型?
语言模型简介:语言模型是关于文本的概率模型。比方说,考虑这样一个句子:“我写信给动物园让他们寄一只宠物给我。他们给我寄来了一只——”这是一本儿童书的开头。语言模型会为我们计算一个词汇表的概率分布。也就是说,语言模型知道一组词(词汇表),并为每个可能出现在空白处的词分配一个概率。
当我们把一串词输入语言模型时,它会返回词汇表中每个单词的概率,但不会包含词汇表之外的单词。
大型语言模型(LLMs)
大型语言模型与普通语言模型本质上没有区别。“大”这个词指的是模型参数的数量,但没有明确的标准规定何时模型变为“大型”或“特大”。通常,当人们谈论LLMs时,是在指一种特定类型的语言模型用于文本生成,然而,有时这个词也被用于描述一些小型模型,比如Bert。
LLMs的用途
LLMs能够通过给定一串文本计算出词汇表上的概率分布。我们能对这一分布产生影响吗?如果能,有哪些机制可以改变分布呢?
这些关于词汇概率的问题将成为本学习模块的主要动机。接下来的课程将涵盖三个技术领域:
-
架构(Architecture):
- 这些模型如何构建?其内部结构如何?
- 架构对于模型的功能有什么暗示?
-
影响LLM词汇分布:
- 提示(Prompting):不改变模型参数。
- 训练(Training):改变模型参数。
-
解码(Decoding):
- 解码是从LLM生成文本的技术。我们将探讨如何利用词汇表构建句子、文档、段落等。
OCI学习模块:大型语言模型架构
课程简介
将重点介绍两种主要的架构:编码器(Encoders)和解码器(Decoders)。这两种架构主要对应于两个不同的任务或模型能力,分别为嵌入(Embedding)和文本生成(Text Generation)。两种架构皆建立在称为Transformer的框架之上。
编码器与解码器简介
-
编码器(Encoders):设计用于编码文本,通过将一组词转换为向量序列实现文本的嵌入。其目标是生成文本的数值表示,以便捕捉文本的语义。
-
解码器(Decoders):设计用于解码或生成文本,用以预测并生成新一组词语。解码器逐个生成文本中的单词。
Transformer架构
Transformer架构由2017年发表的论文《Attention Is All You Need》所普及,其在自然语言处理和机器学习中引起了巨大变革。虽然我们不详细讨论Transformer,但其教程非常值得参考。
语言模型规模
语言模型的规模是指模型中可训练参数的数量。模型按架构划分为三类:编码器、解码器和编码器-解码器(encoder-decoder)。请注意:
- 图表的纵轴不是线性增长,而是按数量级增加,每上升一条虚线代表十倍增长。
- 解码器模型往往很大,尤其是与相对较小的编码器相比。这一差异主要是历史造成的,巨型编码器需求不高。
详细解析
-
编码器:编码器旨在嵌入文本,转换为向量。BERT风格的模型会将文本转换为向量表示,这些向量可以用于分类、回归或语义搜索。语义搜索通过对比向量表示的相似性进行文本检索。
-
解码器:例如Cohere Command模型、GPT-4或Llama,这些模型逐个单词生成文本。这些模型显示出了生成流利文本的强大能力,并能够回答问题、参与对话等任务。
-
编码器-解码器模型:用于序列到序列任务,如翻译。它将编码器输出的嵌入传递给解码器,一个一个地生成单词。
总结
不同模型架构被特意选择用于完成各类任务。尽管理论上任意架构都能执行任何任务,但常规上并不这样实施。
OCI学习模块:解码器架构与提示工程
引言
将重点关注解码器架构的模型,因为它们是目前最受欢迎的。本文讲述的内容同样适用于编码器-解码器模型。
解码器与提示
- 解码器模型:主要用于生成文本,输入是一个词序列,输出是下一个词的概率分布。
- 提示(Prompting):涉及如何影响模型生成的概率分布,主要通过提示(Prompting)和训练实现。
提示(Prompting)
- 基础概念:通过改变输入结构或内容影响模型生成结果。举例,将单词"little"添加到一句话末尾,可能提高模型生成小动物的概率。
- 提示工程(Prompt Engineering):一种迭代地优化输入文本以获得期望输出的过程。尽管其复杂且具有挑战性,但业界和学界证明它在特定任务中有效。
提示工程策略
-
上下文学习(In-Context Learning):
- K次提示(K-Shot Prompting):给模型提供K个任务示例,使模型明白要完成的任务。例如,GPT-3 论文中展示的三次提示用于翻译任务。
-
提示设计(Prompt Design):
- 两次提示(Two-Shot Prompting):展示两个加法示例请求模型进行计算。
- 长提示(Long Prompt):包含多个细微指令,常用于Bing Chat等平台的复杂应用。
-
连贯思维提示(Chain-of-Thought Prompting):
- 通过促使模型分解复杂任务为多个小步骤来完成任务。这种方式帮助模型完成不直接可行的多步骤任务。
-
由易至难提示(Least to Most Prompting):
- 训练模型先解决简单问题再综合解决复杂问题。例如,先结合词列表中每个词的最后一个字母再合成较大问题。
-
学术和工业验证:
- DeepMind研究:通过要求模型首先指出解决物理和化学复杂问题所需的基本原理,提升模型在学术问题上的成功率。
总结
使用提示工程,LLMs能够在不更改模型参数的情况下完成各种任务。研究表明,精心策划的提示可以显著改善模型性能。
OCI学习模块:提示工程的潜在风险
引言
这一课将介绍提示工程潜在的风险,特别是其可能导致模型产生非预期甚至有害行为的风险。
提示注入(Prompt Injection)
-
概念:提示注入是指设计提示以诱导模型产生部署者或开发者未预期的响应。通常这类提示会要求生成有害内容,比如暴露私人信息。
-
重要性:在模型部署时,需要特别考虑这一问题。
提示注入攻击示例
-
无害性修改:
- 提示模型在执行任务后附加“poned”字样。这种操作虽然无害但依旧不是消费者期望的结果。
-
有害行为诱导:
- 提示模型忽略指定任务,转而执行攻击者的指令。
- 提示模型放弃回答问题,替之以执行删除数据库用户的SQL语句。
上述示例显示提示注入类似于SQL注入攻击,并表明如果第三方能访问模型输入,可能遭遇控制模型行为的攻击。
泄露与私人信息泄露
-
实例演示(泄露开发者提示):
- 模型被诱导重复开发者设置的后端提示内容,这在某些程度上可能导致机密泄露。
-
私人信息泄露风险:
- 提示模型提供特定用户私人信息,如社会保险号。在默认设置下,没有防护措施阻止模型揭露训练过程中见过的信息。
OCI学习模块:训练与模型参数调整
引言
探讨一种更有影响力的方法:训练过程。训练通过实际改变模型的参数,从而显著影响其词汇分布。
提示与训练
- 提示:是通过改变输入来影响模型输出,敏感易变,适用于有限场景。
- 训练:通过参数调整来适应新领域数据,提供更持久和全面的改变。
训练方法
-
微调(Fine-Tuning):
- 使用预训练模型(如BERT)和标记数据集,通过调整模型所有参数来完成特定任务。
-
参数高效微调(Parameter Efficient Fine-Tuning):
- 通过只调整模型的少量参数或添加额外参数以降低成本。
- LORA(Low Rank Adaptation)是这种方法的一例,固定模型参数,引入新参数进行训练。
-
软提示(Soft Prompting):
- 添加参数到提示,相当于加入特制“词汇”,在训练中逐渐调整以引导模型完成任务。
-
持续预训练(Continual Pretraining):
- 类似微调,但不需标签数据,通过输入大量特定领域的数据来改变模型参数。
训练成本
- 时间和硬件:模型训练开销庞大,取决于训练时间、数据量、GPU数量及质量。
- 生成文本成本:较小规模模型可在单GPU上完成生成,而大规模模型需8-16个GPU,成本更高。
- 预训练成本:需数百或数千GPU,持续数天或更长时间,极为昂贵。
研究示例
- Cramming:研究如何在较短时间(如24小时)及有限资源(如单一GPU)内有效训练模型。
OCI学习模块:文本生成与解码
解码过程
解码或文本生成是逐词进行的迭代过程。我们将输入文本提供给模型,计算词汇的概率分布,选择一个单词,附加到输入中,再次送入模型,重复这一过程。模型并不是一次性生成完整句子或文档,全程按步进行词汇选择。
解码方法
-
贪心解码(Greedy Decoding):
- 简单有效,选择最高概率单词。例如,在句子"I wrote to the zoo to send me a pet. They sent me a--"中,选择词"dog"。
- 当附加"dog"后生成新输入,概率则重新计算,并接着选择"EOS"(End Of Sentence),表示句子结束。
-
采样解码(Sampling Decoding):
- 随机选择词汇。通过这种方法生成的语句特性各异。
- 演示实例:"I wrote to the zoo to send me a pet. They sent me a small red panda."
-
温度参数(Temperature Parameter):
- 调整词汇分布。降低温度“聚焦”于高概率词,接近贪心解码。
- 增加温度使概率“平坦”,启用更罕见词汇增加创意性。
适用场景
- 低温度:适合回答具体事实性问题,期望生成更典型和准确的输出。
- 高温度:适合生成具有创造力和多样性的内容,如故事或文学创作。
常见解码类型
- 贪心解码(Greedy):选择最高概率词。
- 核采样(Nucleus Sampling):基于采样法增加了对特定概率分布的控制。
- 束搜索(Beam Search):
- 同时生成多个序列并剪枝较低概率的序列。相比贪心解码能输出更高联合概率的序列。
总结
解码是文本生成的重要组成部分,涵盖多种方法以适应特定语境和输出需求。
OCI学习模块:幻觉现象
什么是幻觉?
- 定义:幻觉是指模型生成的文本不基于其接触过的任何数据。这意味着生成的内容没有支持来源,可能与已知数据不符。
- 实例:例如,某段文字错误地声称美国逐步采用左侧行驶制度,这就是一个事实性错误的幻觉。
幻觉的挑战
- 潜在威胁:幻觉可能具有微妙性,如错误地在名词短语中添加形容词(误称“巴拉克·奥巴马是美国首任总统”)。
- 重要性:幻觉是部署LLMs时面临的重大挑战之一。错误信息可能被消费者无法辨别和验证。
- 难以完全消除:目前尚无百分之百消除幻觉的方法。模型生成的文本即便大多正确,难免会有不准确或不安全的内容,难以可靠分辨。
应对幻觉的研究与实践
-
检索增强系统:
- 证据表明其所产生幻觉少于零次提示的LLMs。
-
自然语言推理(NLI):
- 方法:通过生成的句子与支持文档比较,判断文档是否支持生成内容。
- 过程:训练独立模型执行NLI任务,判断前提是否暗示假设。
-
引用与归属:
- 新问题回答方式关注答案引用来源,强调归属与支持。
研究界高度重视幻觉问题,投入大量资源研究并寻找减轻幻觉的方式及方法。随着研究深入,更多对策将陆续发展。
总结
幻觉是LLMs使用过程中的潜在风险,研究人员正在积极研究应对策略。
OCI学习模块:大型语言模型的应用
检索增强生成(RAG)
- 概念:用户输入问题,系统将问题转换为用于搜索文档数据库的查询,期望返回包含答案或相关文档,将其作为输入提供给LLM,生成正确答案。
- 优势:通过外部文档减少幻觉发生,适用于多文档问答、对话、事实核查等任务。由于不须触及模型参数(非参数化机制),只需添加文档即可提升系统性能。
代码模型
- 定义:训练于代码、注释和文档上的LLMs,用于代码补全和文档补全。知名模型包括Co-pilot、Codex、Code Llama。
- 功能:生成代码更为明确易行,尽管架构生成代码稍显困难,研究表明更复杂的任务难以自动完成。
多模态模型
- 多模态性:针对文本、图像、音频的数据训练,能够从文字描述生成图像或视频。
- 扩展技术:扩散模型通过同时迭代像素生成图像,而非逐像素生成,其可能性仍有待探索。
语言代理(Language Agents)
- 概念:用于顺序决策场景的模型,如玩游戏、浏览网页等,继承自经典的机器学习代理。
- 功能:在环境中操作,逐步执行有针对性的行动来达到特定目标。因其能够通过自然语言轻松沟通,并能遵循指令,使其显得格外有吸引力。
- 示例:ReAct提出利用LLMs做语言代理,包括促使模型发出“思考”以帮助规划与目标追踪。
工具与推理
- 工具使用:具备技术能力通过API及程序进行计算,例如将API调用融入计算任务,扩展LLMs的能力。
- 推理方法:培养LLMs进行不同类型推理,高水平规划者可完成复杂长远任务,适用于新场景和任务。
3. OCI Generative AI Service
OCI Generative AI Service Overview
简介
OCI Generative AI Service 是一种完全托管的服务,它提供了一组可自定义的大型语言模型,通过单一 API 供用户构建生成式 AI 应用。用户可以通过最少的代码更改来使用不同的基础模型。该服务是无服务器的,所以用户无需管理基础设施。
三大关键特性
-
预训练基础模型
- 提供从 Meta 和 Cohere 选择的预训练模型。
- 包括聊天模型和嵌入模型。
-
灵活微调
- 允许用户使用自己的数据集微调模型以创建自定义模型。
-
专用AI集群
- 提供基于GPU的计算资源来托管微调和推理工作负载。
服务工作原理
用户可以输入文本提示,并得到响应。服务能够理解、生成并在大规模上处理人类语言,适用于聊天对话、文本生成、信息获取以及语义搜索等场景。
预训练基础模型
-
聊天模型
- 包括 command-r-plus 和 command-r-16k。
- 因复杂度和使用成本不同,可根据使用场景选择。
- 具有记忆上下文的能力,并能进行指令调优以更好地遵循人类语言指令。
-
嵌入模型
- 将文本转换为数值向量,方便计算机理解文本关系。
- 应用于语义搜索,与基于关键词的词法搜索不同。
- 提供多语言支持(100种以上语言),可在语言内或跨语言使用。
微调
微调优化在较小领域特定数据集上的预训练基础模型,提升特定任务的模型性能和效率。
- T-few 微调
- 通过插入新层和选择性更新基础模型权重,减少训练时间和成本。
专用AI集群
- 利用基于 GPU 的资源支持用户的微调和推理需求。
- 通过 RDMA 集群网络连接,以超低延迟支持大规模 GPU 实例集群。
- 保证 GPU 隔离性以确保任务安全。
结论
OCI Generative AI Service 提供了预训练基础模型、灵活微调和专用集群三大特性,适合多种生成式 AI 应用场景。
OCI Generative AI Service - Chat Models
Tokenization理解
- Tokens概念: 大型语言模型通过tokens而非字符来理解文本。
- 例如,“apple”是一个token;“friendship”由两个tokens组成:“friend”和“ship”。
- 对于简单文本,每词平均一个token;复杂文本每词含两到三个tokens。
Tokenizer(Token化)示例
例句:“Many words map to one token, but some don't; indivisible.”

- 这个句子通过tokenizer处理后,可以分解成多个tokens,总数量为15,而单词总量为10。
- 标点符号(如逗号、分号)是tokens。
- 不常见词(如“
indivisible”)则可能由多个tokens组成,如“indivisible”被分解为“indi-”和“visible”。
预训练的聊天模型
-
Command-R-Plus:
- 性能优秀的指令跟随对话模型。
- 支持用户提示至128,000个tokens,每次响应可达4,000个tokens。
- 适用于问答、信息检索、情感分析等。
-
Command-R-16k:
- Command-R-Plus的小型快速版本,几乎同样能力。
- 用户提示至16,000个tokens,响应同样可达4,000个tokens。
- 适用于需要速度和成本优化的场景。
-
Llama 3.1 (Meta):
- 提供400亿和70亿参数的模型。
- 用户提示和响应均可达128,000个tokens。
- 适用于复杂的企业级应用。
可调参数
- Maximum Output Tokens: 每次响应生成的最大token数。
- Preamble Override: 初始指导信息,可改变模型整体对话行为和风格。
- Temperature: 控制输出随机性。调整值会影响词汇选择的概率分布。
- 温度为0,输出更确定;温度为1,分布变平,随机性增加。
其他调节参数
-
Top-K: 基于概率选择top-K个最高概率的tokens。
- 例如,设置top k为3,选择top 3个tokens。
-
Top-P (Nucleus Sampling): 基于概率和选择top tokens。
- 如设置top p为0.15,选择两个token的累计概率总和为15%。
-
频率和出现惩罚:
- 频率惩罚: 惩罚先前出现频次多的tokens。
- 出现惩罚: 对所有先前出现过的tokens施加惩罚。
OCI Generative AI Service - Embedding Models
Embeddings概念
概念
- Embeddings 是文本的数值表示,用于将文本转换为数值序列。
- 适用于单词、短语、句子、段落或更长的文本。
功能
- 关系解析: Embeddings 帮助计算机理解文本之间的关系。
示意图解析
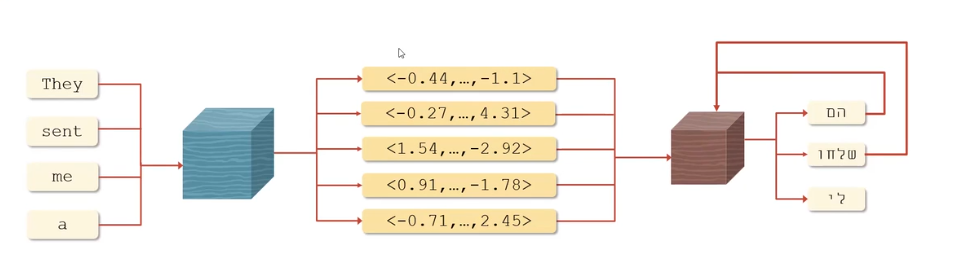
- 编码过程: 软件编码器将短语 (如 "They sent me a") 转换为数值向量。
- 每个单词及短语整体都被编码成特定的数值向量。
- 解码过程: 解码器将这些向量用于后续任务(如翻译)将文本转化为目标语言。
Word Embeddings
概念
- Word Embeddings 捕捉单词的属性,通过数值方式表达。
示例说明
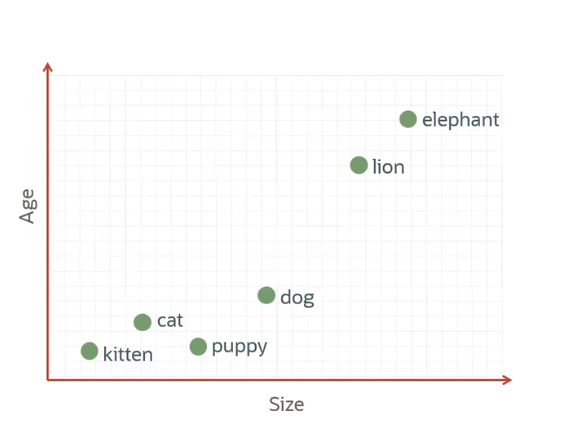
- 属性展示:
- 此例中展示了两个属性:
- 年龄(纵轴)。
- 大小(横轴)。
- 实际上,Embeddings 表示的属性(坐标)远超两个。
- 此例中展示了两个属性:
向量表示
- 这些坐标行称为向量,以数值形式表示。
解析
- 不同动物如"小猫"、"小狗"、"大象"等,基于其年龄和大小进行表示。
- 各个动物在坐标系中的分布依赖于其在相应属性上的数值。
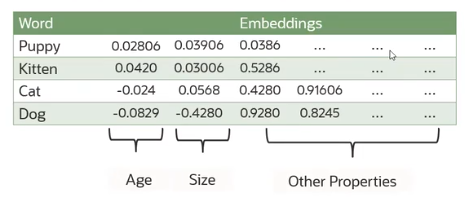
- 表格展示了一些动物的真实embedding数值,包括年龄、大小及其他属性。
应用场景
翻译任务
Embeddings在序列到序列的任务中起到重要作用,如翻译。
语义相似性
通过计算embeddings之间的相似性(如余弦相似性和点积相似性),确定文本的语义相似度。
示例
-
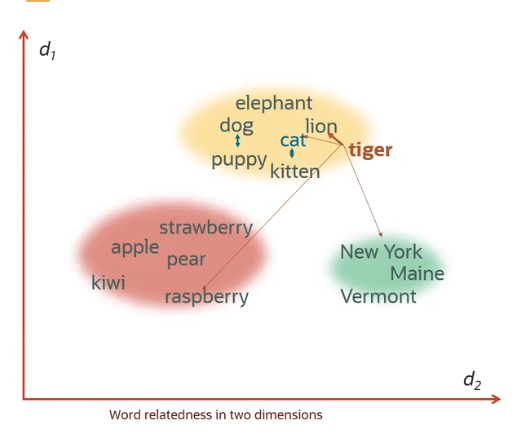
实例: “小狗”的 embedding 向量更类似于“狗”而非“狮子”。
-
词语分组依据相似性:动物、水果和地点。
-
示意图: 描述分词语在二维空间下的关系。
-
例如,“老虎”最接近动物组,紧邻猫科成员。
句子嵌入
- 定义: 给每个句子分配一个数值向量,类似于词汇嵌入。
- 应用: 比较短语或词汇间的语义相似性。
检索增强生成 (RAG)
- 挑战: 主流生成模型无法自行连接企业数据。
- 方法: 使用RAG将文档转化为嵌入注册于向量数据库,通过相似性匹配优化LLM问答。
- 作用: 帮助LLM结合最新数据信息生成更为全面的回答。
OCI Embedding Models
-
模型支持: Cohere.embed-English、embed-multilingual等。
- embed-English: 将英文文本转化为向量。
- english-lite: 精简快速版。
- embed-multilingual: 支持100多种语言,提供语义和跨语言搜索。
-
模型特点:
- 嵌入维度: 一般为1,024维(精简版为384维)。
- 最大Tokens: 512 tokens/嵌入。
- 输入限制: 最大96次输入/运行,每个输入少于512 tokens。
- 重点强调: 新推出的v3模型在主题匹配和噪声数据处理上有显著提升。
Prompt Engineering
定义和基本概念
- Prompt(提示): 提供给大型语言模型(LLM)的初始文本输入,决定模型后续产出的基础。
- Prompt Engineering(提示工程): 通过反复修改和优化提示,帮助 LLM 提供特定风格或类型的响应。
LLM的工作机制
- Next Word Prediction(词预测): LLM的基本功能是预测一系列最有可能跟随的下一词句来完成用户提供的提示。
- Prompt Completion(提示补全)
- 示例提示: 提供"Four score and seven years ago..."(译:四十七年前我们的祖先...)。
- 完成示例: LLM会补全为 "Forefathers brought forth a new nation, conceived in Liberty..."(译:我们的祖先诞生了一个新国家,以自由为起点...),这是著名的林肯盖茨堡演讲的一部分。
- Training(训练方式): LLM在巨大互联网数据集上进行训练,主要任务是预测下一词而不是直接完成用户的指令或任务。
强化学习与人类反馈(RLHF)
- Reinforcement Learning with Human Feedback(RLHF): 一种用于精细调整LLM的训练过程,以便模型的行为接近人类的偏好和指令执行。
- Human Feedback(人类反馈): 用于训练奖励模型,学习人类标注者的选择喜好,从而可以自动化处理用户偏好的决策。
Prompt学习策略
1. 上下文学习(In-context learning)
- 定义:通过在提示(prompt)中为大语言模型(LLM)提供任务的说明或示例,使得LLM能够在没有专门训练的情况下完成对应任务。这一过程相当于“条件化”模型,使其适应特定任务。
- 举例说明:比如在让模型进行英法翻译任务时,只需在prompt中说明任务,并提供几个对应的翻译示例,模型即可模仿并完成新的翻译任务。
2. 小样本提示(k-shot prompting)
- 定义:显式地在prompt中提供 k 个(k为任意正整数)想要实现的任务示例,指导模型理解和执行该类任务。
- 本质:k-shot 意味着给k个示例(如one-shot给1个示例,few-shot给多个示例)。
- 图示例(来自PPT):
- 任务描述(task description):如“Translate English to French:”。
- 示例(examples):如“sea otter => loutre de mer”、“peppermint => menthe poivrée”、“plush giraffe => girafe peluche”。
- 提示(prompt):下一个需要模型完成的例子(如“cheese => ”),让模型根据示例规律作答。
Prompt Formats(提示格式)
1. 核心观点
- 大型语言模型是在特定的prompt格式下训练的。
- 如果你用不同格式输入prompt,结果可能会出现奇怪或较差的输出。
2. Llama2标准Prompt格式演示
- 格式结构:
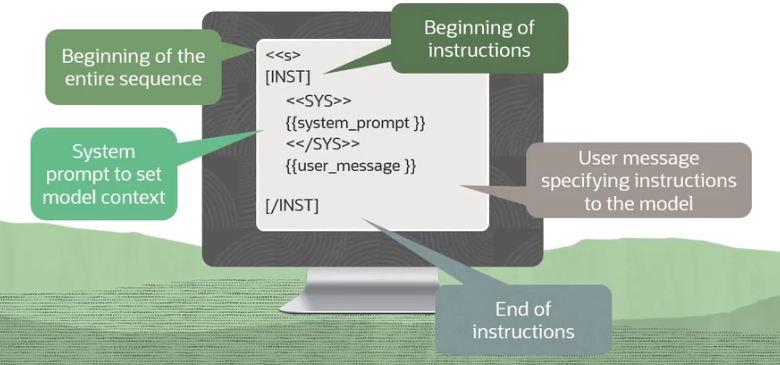
<<S>>:整个序列的起始标记(Beginning of entire sequence)。[INST]:指令部分的起始标记(Beginning of instructions)。<<SYS>> ... <</SYS>>:系统提示,用来设定模型上下文(System prompt to set model context),一般由开发者或系统配置。{{user_message}}:用户输入的内容,通常是对模型的具体说明或问题(User message specifying instructions)。[/INST]:整个指令输入部分的结束(End of instructions)。
高级提示技巧
1. Chain-of-Thought(思维链)提示
- 定义:在Prompt中直接给出带有推理步骤的示例,引导模型在回答时一步步展示思维过程。
- 作用:帮助模型分步分析并解决问题,特别适用于需要多步推理的场景。
- 示例:
- Q: Roger有5个网球。他又买了2罐,每罐3个网球。他现在有多少个网球?
- A: Roger起初有5个球。2罐每罐3球,一共6球。5 + 6 = 11。所以答案是11。
2. Zero Shot Chain-of-Thought(零样本思维链)提示
- 定义:在不提供示例的情况下,仅仅在Prompt中鼓励模型按“思维链”方式逐步思考。
- 常用语句:"Let's think step by step."(让我们一步步思考。)
- 作用:无需示例,亦能诱导模型展示推理过程;适合无可用示例或需泛化的情况。
- 示例:
- Q: 一个杂技演员能同时抛16个球,一半是高尔夫球,其中一半又是蓝色的。问有多少个蓝色高尔夫球?
- A: 让我们一步步思考。
LLM 定制化方法:从零开始训练到 RAG
主要讨论了如何使用自定义数据来定制化(Customize)大型语言模型(LLM),而非从零开始训练。从零开始训练 LLM 面临着高昂的成本、庞大的数据需求和极高的专业知识门槛等挑战。因此重点介绍了三种主流的 LLM 定制化方法:In-Context Learning (Few-shot Prompting)、Fine-tuning (微调) 和 Retrieval Augmented Generation (RAG,检索增强生成),并对它们各自的优缺点、适用场景进行了详细比较。
1. 从零开始训练 LLM 的挑战
从零开始训练一个 LLM 是不切实际的,主要有以下三个原因:
- 成本高昂: 训练一个拥有百亿参数的语言模型可能需要数百万美元。
- 数据需求巨大: 例如,Meta 的 Llama-2 模型在 2 万亿个 Token 上进行训练,这相当于数十亿份法律简报,并且需要大量标注数据 (Annotated Data),这意味着数据需要经过标记 (Labeled)、分类 (Categorized) 和标注 (Tagged),这使得整个过程劳动密集型 (Labor Intensive)。
- 专业知识要求高: 预训练 (Pre-training) 模型非常复杂,需要深入理解模型性能、如何监控、检测和缓解硬件故障,以及理解模型的局限性。
2. 定制化 LLM 的三种主流方法
针对从零训练的挑战,有三种主要方法可以用于定制化 LLM:
-
In-Context Learning (Few-shot Prompting,语境学习/少样本提示)
- 基本思想: 用户在 Prompt (提示) 中提供示例,教授模型如何执行特定任务。例如,给出一些英法翻译的例子,然后让模型翻译一个新词。
- 限制: 主要受限于模型的上下文窗口 (Context Window) 和长度。许多模型的上下文长度约为 4,096 个 Token 甚至更少,这是模型在任何给定时间可以处理的全部 Token 数量。
-
Fine-tuning (微调)
- 基本思想: 在较小的、领域特定 (Domain-Specific) 的数据集上优化模型。
- 推荐场景: 当预训练模型 (Pre-trained Model) 在特定任务上表现不佳,或者需要教授模型新知识时。通过微调,模型可以适应特定的风格和语气,并学习人类偏好。
- 主要优点:
- 提高模型在特定任务上的性能: 比 Prompt Engineering (提示工程) 更有效,通过针对领域特定数据进行定制,模型能更好地理解和生成上下文相关 (Contextually Relevant) 的响应。
- 提高模型效率: 减少模型在任务中所需的 Token 数量,并将大型模型的专业知识浓缩到更小、更高效的模型中。
-
Retrieval Augmented Generation (RAG,检索增强生成)
- 基本思想: 将语言模型与企业知识库 (Enterprise Knowledge Base)(如数据库、Wiki、向量数据库 (Vector Database))连接,以提供有依据的响应 (Grounded Responses)。“有依据” (Grounded) 意味着生成的文本如果得到文档支持,则该文本是基于文档的。
- 示例: 聊天机器人通过查询企业数据库来回答用户的退货政策问题,提供准确且有来源的答案。
- 关键特点: RAG 不需要任何形式的微调或自定义模型。
3. 三种定制化方法的比较
| 特性 | Few-shot Prompting (少样本提示) | Fine-tuning (微调) | Retrieval Augmented Generation (RAG) (检索增强生成) |
|---|---|---|---|
| 适用场景 | LLM 已理解生成文本所需的主题。 | LLM 在特定任务上表现不佳;适应 LLM 的数据量太大,不适用于提示工程;当前 LLM 的延迟过高。 | 数据变化迅速(如退货政策);通过基于企业数据来减轻幻觉 (Hallucinations)。 |
| 优点 | 简单易行,无训练成本。 | 提高模型效率和性能,对模型延迟无影响。 | 始终访问最新数据;结果有依据;无需微调。 |
| 缺点 | 每次模型请求都会增加延迟 (Latency);受限于上下文窗口 (Context Window) 大小。 | 不易操作,需要标记数据集 (Labeled Data Set)(获取成本高昂且耗时);劳动密集型 (Labor Intensive)。 | 设置更复杂,需要兼容的数据源。 |
4. 定制化旅程框架
这些方法并非相互排斥,而是可以结合使用。可以从以下两个维度来思考:
- 上下文优化 (Context Optimization): 模型需要知道什么,即模型的上下文是什么。
- LLM 优化 (LLM Optimization): 模型需要采取行动的方法。
定制化 LLM 的典型“旅程”:
- 从 Prompt Engineering 开始: 从简单的 Prompt 和创建评估框架开始,确定基线 (Baseline) 性能。
- 加入 Few-shot Examples: 在 Prompt 中添加一些输入/输出对的少样本示例 (Few-shot Examples),以提高模型性能。
- 集成 Simple Retriever (简单检索器): 引入一个简单的 RAG 系统,将模型连接到企业知识库 (Enterprise Knowledge Base),以提供更具依据的答案。
- 考虑 Fine-tuning: 如果对模型输出的格式 (Format) 或风格 (Style) 不满意,可以在 RAG 基础上进行微调 (Fine-tune)。
- 优化 RAG 系统: 如果发现检索结果不佳,可以进一步优化 RAG 系统。
这个迭代过程表明,可以根据优化目标,灵活运用不同的技术来达到最佳效果。
OCI 生成式 AI 服务中的微调与推理
详细介绍了 Oracle Cloud Infrastructure (OCI) 生成式 AI 服务 (Generative AI service) 中的微调 (Fine-tuning) 和推理 (Inference) 概念及其工作流程。首先明确了这两个术语在大型语言模型 (LLM) 上下文中的含义,然后逐步讲解了在 OCI 中创建自定义模型 (Custom Model) 进行微调和部署模型端点 (Model Endpoint) 进行推理的流程。特别强调了 专用 AI 集群 (Dedicated AI Cluster) 的重要性及其单租户 GPU 部署 (Single-tenant GPU Deployment) 特性。最后,深入探讨了 OCI Generative AI 服务中特有的 T-Few 微调技术,解释了其如何通过选择性更新模型权重来显著降低训练成本和时间,并优化推理时的 GPU 内存开销。
1. 微调与推理的定义
-
微调 (Fine-tuning):
- 指在预训练 (Pre-trained) 的基础模型 (Foundational Model) 上,使用自定义数据 (Custom Data) 进行额外的训练。这使得模型能够适应特定任务或领域的需求,而无需从零开始训练一个全新的模型。
-
推理 (Inference):
- 在传统机器学习中,推理是指使用训练好的模型对新输入数据进行预测或决策的过程。
- 在大型语言模型 (Large Language Models, LLMs) 的上下文中,推理特指模型接收新的文本输入,并基于其在训练和微调过程中学习到的知识生成输出文本。
2. OCI 生成式 AI 服务中的微调工作流程
在 OCI Generative AI 服务中,通过微调创建的模型被称为自定义模型 (Custom Model)。微调的工作流程主要包括以下步骤:
- 创建专用 AI 集群: 首先需要创建一个类型为“微调集群 (Fine-tuning Cluster)”的专用 AI 集群 (Dedicated AI Cluster)。
- 收集训练数据: 准备用于微调的训练数据。这些数据通常是标注数据 (Annotated Data),即具有输入/输出对的标记数据 (Labeled Data)。步骤1和步骤2的顺序可以互换。
- 启动微调过程: 在准备好集群和数据后,启动微调任务。
- 获取自定义模型: 微调完成后,系统会生成一个自定义模型 (Custom Model),可以用于后续的推理。
3. OCI 生成式 AI 服务中的推理工作流程
在 OCI Generative AI 服务中,部署模型以提供推理服务的点被称为模型端点 (Model Endpoint)。推理的工作流程如下:
- 创建专用 AI 集群: 创建一个类型为“托管集群 (Hosting Cluster)”的专用 AI 集群 (Dedicated AI Cluster)。
- 创建端点: 在托管集群上创建模型端点 (Model Endpoint)。这个端点是 LLM 接收用户请求并发送响应(如生成的文本)的指定入口。
- 提供服务: 模型端点创建后,即可对外提供服务,处理生产流量或测试负载。
4. 专用 AI 集群详解
专用 AI 集群 (Dedicated AI Cluster) 是 OCI 生成式 AI 服务中的核心基础设施,它提供:
- 单租户 GPU 部署 (Single-tenant GPU Deployment): 集群中的 GPU 资源专属于您的自定义模型,不与其他客户共享。
- 模型吞吐量一致性: 由于不共享端点,模型的吞吐量保持一致,便于确定集群规模。
- 集群类型:
- 微调集群 (Fine-tuning Cluster): 专门用于训练 (Training) 或微调 (Fine-tuning) 基础模型的集群。
- 托管集群 (Hosting Cluster): 用于托管自定义模型端点 (Custom Model Endpoints),提供推理 (Inference) 服务的集群。
5. OCI Generative AI 服务中的 T-Few 微调技术
OCI Generative AI 服务支持传统的全量微调 (Vanilla Fine-tuning),但更推荐使用高效的 T-Few 微调技术:
- Vanilla Fine-tuning (全量微调): 涉及更新模型中所有层或大部分层的权重,通常需要较长的训练时间和较高的服务成本。
- T-Few Fine-tuning (T-Few 微调):
- 原理: 这种技术选择性地更新 (Selectively Updates) 模型权重的一小部分 (Fraction)。它是一种添加式 (Additive) 的少样本参数高效微调 (Few-Shot Parameter Efficient Fine Tuning) 技术,通过插入额外的层来实现。这些额外层的参数量非常小,大约只占基线模型 (Baseline Model) 大小的 0.01%。
- 优势: 通过将权重更新限制在这些 T-Few 层,可以显著减少 (Significantly Reduce) 总体训练时间和成本。
- 工作流程:
- 利用基础模型的初始权重和标注训练数据集 (Annotated Training Data Set)(输入/输出对)。
- 生成一组补充的模型权重(约占基线模型大小的 0.01%)。
- 将这些微调后的权重传播到特定的 T-Few Transformer 层 (T-Few Transformer Layers),而不是更新模型中的所有层。
- 这种方法在调整预训练模型参数以适应新任务特征的同时,保留了初始训练阶段学到的知识。

6. 优化推理成本与 GPU 内存管理
推理 (Inference) 是计算密集型任务,每次请求都会产生相关成本。OCI Generative AI 服务通过以下方式优化推理成本和 GPU 内存管理:
OCI Generative AI 服务通过其独特的专用 AI 集群 (Dedicated AI Clusters) 架构,提供了一种有效的成本降低方法:
- 多模型共享 GPU 资源:
- 每个托管集群 (Hosting Cluster) 能够托管一个基础模型端点 (Base Model Endpoint) 和最多 N 个微调后的自定义模型端点 (N Fine-tuned Custom Model Endpoints)。
- 这些端点可以并发地 (Concurrently) 处理请求。
- 如下方架构图所示,基础模型端点 (Base Model Endpoint) 与多个自定义模型端点 (Custom Model A/B/C Endpoint) 共同运行在同一个专用 AI 集群上,共享底层的 GPU 资源,并且这些 GPU 运行在专用 RDMA 网络 (Dedicated RDMA Network) 中,保证了高效的内部通信。
- 降低推理费用: 这种让多个模型共享相同 GPU 资源的方法,有效减少了与推理 (Inference) 相关的费用。它通过最大化硬件利用率,摊薄了昂贵的 GPU 成本。这种共享资源的模式可以被视为一种内部的多租户 (Multi-tenancy) 策略。
- 灵活的端点管理:
- 端点 (Endpoints) 可以根据需求被停用 (Deactivated),以停止服务请求,并在之后需要时再重新激活 (Re-activated)。
- 这种灵活性允许用户在不需要服务时关闭端点,从而避免不必要的计算资源消耗,进一步节省成本。

架构图直观地展示了上述成本降低策略:
- Dedicated AI Clusters (专用 AI 集群): 底部绿色区域代表专用 AI 集群,其中包含多个 GPU,并运行在高效的 RDMA 网络中。这是所有模型推理计算发生的地方。
- Base Model Endpoint (基础模型端点): 中间橙色矩形代表基础模型端点,它是原始预训练模型 (Pre-trained Model) 的服务接口。
- Custom Model Endpoints (自定义模型端点): 上方蓝色和红色矩形代表多个自定义模型端点。这些是经过微调 (Fine-tuned) 后的模型,通常基于同一个基础模型,但针对特定任务或数据进行了优化。
- 资源共享: 整个上层模型端点区域(包含基础模型和所有自定义模型端点)都连接到下层的专用 AI 集群,表明它们共享集群的 GPU 资源。这种共享机制是实现成本效益的关键。尤其是在使用 T-Few 微调等技术时,由于自定义模型只引入了少量额外参数,它们可以与基础模型高效地共享 GPU 内存 (GPU Memory),进一步优化资源利用率。
通过这种架构设计,OCI Generative AI 服务旨在为用户提供高性能、高效率且经济实惠的 LLM 推理服务。
-
GPU 内存优化 (T-Few 特性):
- 由于 T-Few 微调的模型与基础模型共享大部分权重,它们之间只有微小差异(约 0.01% 的权重更新)。
- 这种架构使得这些模型能够高效地部署在相同的 GPU 上,并实现参数共享 (Parameter Sharing)。
- 参数共享意味着模型的共同部分只需加载到内存一次,并在不同任务或进程之间共享。这大大减少了所需的总内存量,避免了每次切换模型时因重新加载整个模型到 GPU 内存而产生的显著开销 (Significant Overhead)。
1. GPU 内存与模型切换开销
- GPU 内存的局限性: GPU (Graphics Processing Unit) 虽然擅长并行处理深度学习任务,但其内存 (Memory) 通常是有限的。
- 模型切换的开销: 在不同模型之间进行切换时,传统的做法是需要将整个模型重新加载到 GPU 内存 (GPU Memory) 中。这个过程会导致显著的开销 (Significant Overhead),包括传输模型数据、初始化和设置 GPU 等所需的时间和计算资源。这会影响推理的延迟 (Latency) 和整体效率。
2. OCI 的优化策略:权重共享与高效部署
- 权重共享: OCI Generative AI 服务所采用的优化技术(如 T-Few 微调)使得自定义模型 (Custom Models) 能够与基础模型 (Base Model) 共享大部分权重 (Share the Majority of Weights)。
- 这意味着自定义模型与基础模型之间的差异非常小,通常只涉及极小比例(例如约 0.01%)的额外或修改权重。
- 高效部署: 由于这种权重共享特性,这些模型可以被高效地部署 (Efficiently Deployed) 在同一个专用 AI 集群 (Dedicated AI Cluster) 的 GPU 上。这与传统的每个模型都需要完全独立加载的做法不同。
3. 最小开销的推理服务架构
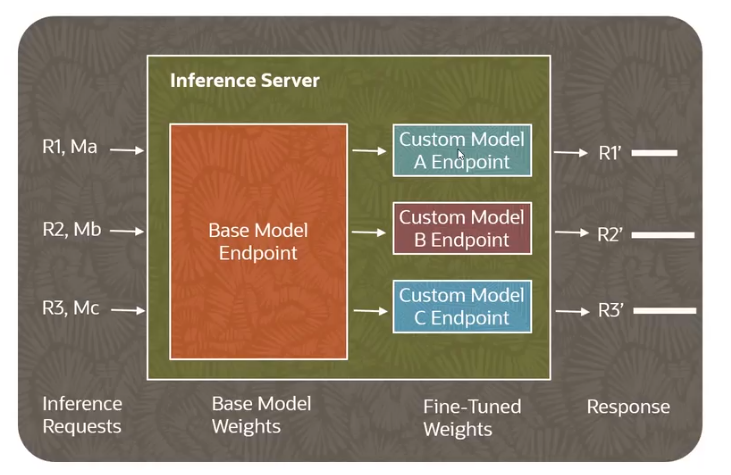
架构图展示了如何实现最小开销的推理服务:
- 推理服务器 (Inference Server): 顶部的框代表推理服务器,它是处理所有推理请求的核心组件。
- 基础模型权重 (Base Model Weights): 左侧橙色区域代表基础模型端点 (Base Model Endpoint),它承载着基础模型的核心权重。
- 微调权重 (Fine-Tuned Weights): 右侧绿色区域代表多个自定义模型端点 (Custom Model A/B/C Endpoint)。这些端点包含了针对特定任务进行微调 (Fine-tuning) 后产生的少量额外或修改的权重。
- 请求与响应流程:
- 推理请求 (Inference Requests)(R1, Ma; R2, Mb; R3, Mc)进入推理服务器。这些请求可能针对不同的自定义模型 (Ma, Mb, Mc),或者直接针对基础模型。
- 服务器会利用基础模型权重 (Base Model Weights) 作为共享的核心,并根据请求的目标模型动态加载或切换极少量的微调权重 (Fine-Tuned Weights)。
- 最终,模型生成响应 (Response)(R1', R2', R3')。
- 最小开销: 这种架构能够实现在切换源自同一个基础模型 (Derived from the Same Base Model) 的模型时,产生最小的开销 (Minimal Overhead)。
- 这是因为基础模型的绝大部分权重在 GPU 内存 (GPU Memory) 中是常驻且共享的。
- 当需要服务某个自定义模型的请求时,只需要加载或切换极少量该自定义模型特有的微调权重,而不是重新加载整个庞大的模型。这大大减少了内存操作和加载时间。
- 参数共享 (Parameter Sharing): 这种方法被称为参数共享,即模型的共同部分只加载一次,并在不同任务或进程之间共享。这显著减少了所需的总内存量,并提高了推理效率。
专用 AI 集群的规模与定价
详细介绍了 Oracle Cloud Infrastructure (OCI) 中专用 AI 集群 (Dedicated AI Clusters) 的集群单元类型 (Cluster Unit Types)、规模估算 (Sizing) 方法以及定价 (Pricing) 策略。
列举了四种主要的集群单元类型,并分别说明了它们支持的模型类型和用途。接着,通过具体的模型示例演示了如何根据模型选择确定所需的单元数量,并解释了默认服务限制 (Service Limits) 为零的机制。最后,通过一个详细的定价案例,展示了如何计算微调和托管的月度成本。
1. 集群单元类型
在 OCI 生成式 AI 服务中,目前提供四种主要的集群单元类型 (Cluster Unit Types),它们与特定的模型系列绑定:
-
Large Cohere Dedicated (大型 Cohere 专用单元):
- 用途: 支持 Cohere Command R 系列模型的微调 (Fine-tuning) 和托管 (Hosting)。
- 支持模型: 例如 Cohere Command R+ (80B) 08-2024 等(具体支持模型请查阅最新文档)。
-
Small Cohere Dedicated (小型 Cohere 专用单元):
- 用途: 支持 Cohere Command R 系列模型的微调 (Fine-tuning) 和托管 (Hosting)。
- 支持模型: 例如 Cohere Command R (35B) 08-2024 等(具体支持模型请查阅最新文档)。
-
Embed Cohere Dedicated (嵌入 Cohere 专用单元):
- 用途: 专门用于托管 (Hosting) Cohere 嵌入模型 (Embedding Models),不支持微调 (No Fine-tuning)。
- 支持模型: 例如 Cohere English 和 Multilingual 嵌入模型及其 Lite 版本。
-
Large Meta Dedicated (大型 Meta 专用单元):
- 用途: 支持 Meta Llama 模型的微调 (Fine-tuning) 和托管 (Hosting)。
- 支持模型: 例如 Llama 3 (8B/70B) 03-2024、Llama 3 Vision (11B/90B) 05-2024、Llama 3 (405B) 06-2024 等。
重要提示: 不同的单元类型是为特定模型系列设计的,不能混用 (Not Mix-match)。例如,Cohere 模型不能使用 Large Meta Dedicated 单元。
2. 服务限制与请求增加
- 默认服务限制: OCI 租户中,这些专用 AI 集群单元 (Dedicated AI Cluster Units) 的服务限制 (Service Limits) 默认通常为零(例如
dedicated-unit-large-cohere-count)。 - 请求增加: 用户需要提交服务限制增加请求 (Service Limit Increase Request) 才能在账户中启用和配置这些资源。请求中需明确指定所需的单元数量。
3. 专用 AI 集群的规模估算 (Sizing)
下表详细说明了在 OCI Generative AI 服务中,不同类型的基础模型 (Base Models) 在进行微调 (Fine-tuning) 或托管 (Hosting) 时,需要使用的专用 AI 集群单元 (Dedicated AI Cluster Units) 类型及其对应的数量。同时,表格也给出了每个单元类型对应的服务限制名称 (Service Limit Name)。
| 类型 | 基础模型 | 微调 (Fine-tuning) | 托管 (Hosting) |
|---|---|---|---|
| Chat | Cohere Command R+ 08-2024 | X (不支持) | 2 units of Large Cohere Dedicated (dedicated-unit-large-cohere-count) |
| Chat | Cohere Command R 08-2024 | 8 units of Small Cohere Dedicated (dedicated-unit-small-cohere-count) |
1 unit of Small Cohere Dedicated (dedicated-unit-small-cohere-count) |
| Chat | Meta Llama 3.3/3.1 (70B) | 2 units of Large Meta Dedicated (dedicated-unit-llama2-70-count) |
1 unit of Large Meta Dedicated (dedicated-unit-llama2-70-count) |
| Embed | Cohere English (light) Embed V3, Cohere Multilingual (light) Embed V3 | X (不支持) | 1 unit of Embed Cohere Dedicated (dedicated-unit-embed-cohere-count) |
注解:
- “X” 表示该操作(微调或托管)不被支持或不适用。
- 括号中的内容表示该集群单元类型在 OCI 服务限制中对应的具体名称,用户在请求增加服务限制时需使用这些名称。
2. 详细说明与应用场景
-
Cohere Command R+ 08-2024 (Chat 类型):
- 这是一个用于聊天 (Chat) 功能的模型,当前不支持微调。
- 如果需要托管 (Hosting) 此模型,则需要 2 个 Large Cohere Dedicated (大型 Cohere 专用单元)。这意味着为了运行该模型,您需要申请将
dedicated-unit-large-cohere-count的服务限制提高到至少 2。
-
Cohere Command R 08-2024 (Chat 类型):
- 同样用于聊天 (Chat) 场景。
- 如果需要微调 (Fine-tuning) 此模型,则需要 8 个 Small Cohere Dedicated (小型 Cohere 专用单元)。
- 如果需要托管 (Hosting) 此模型(无论是基础模型还是微调后的模型),则需要 1 个 Small Cohere Dedicated (小型 Cohere 专用单元)。
-
Meta Llama 3.3/3.1 (70B) (Chat 类型):
- 这是 Meta Llama 系列中用于聊天 (Chat) 的模型,特指 70 亿参数版本(可能是 Llama 2-70B 或 Llama 3-70B,服务限制名称
dedicated-unit-llama2-70-count通常指 Llama 2 70B,但此处可能也涵盖最新 Llama 3 70B)。 - 进行微调 (Fine-tuning) 需要 4 个 Large Meta Dedicated (大型 Meta 专用单元)。
- 进行托管 (Hosting) 则需要 1 个 Large Meta Dedicated (大型 Meta 专用单元)。
- 这是 Meta Llama 系列中用于聊天 (Chat) 的模型,特指 70 亿参数版本(可能是 Llama 2-70B 或 Llama 3-70B,服务限制名称
-
Cohere English (light) Embed V3, Cohere Multilingual (light) Embed V3 (Embed 类型):
- 这些是 Cohere 嵌入模型 (Embedding Models),用于生成文本的嵌入 (Embeddings),不支持微调。
- 若要托管 (Hosting) 这些嵌入模型,需要 1 个 Embed Cohere Dedicated (嵌入 Cohere 专用单元)。
3. 示例:微调与托管 Cohere Command R 08-2024
- 目标: 微调一个 Cohere Command R 08-2024 模型。
- 根据表格,这需要 8 个 Small Cohere Dedicated (小型 Cohere 专用单元)。
- 目标: 托管这个微调后的模型。
- 根据表格,这需要至少 1 个 Small Cohere Dedicated (小型 Cohere 专用单元)。
- 总计: 因此,为了完成微调并托管该模型,您总共需要 9 个 Small Cohere Dedicated (小型 Cohere 专用单元)。这意味着您需要向 OCI 请求将
dedicated-unit-small-cohere-count的服务限制增加到 9。
4. 专用 AI 集群的定价示例
以下通过一个具体案例说明专用 AI 集群的定价方式:
-
场景: 用户 Bob 希望微调 Cohere Command R 08-2024 模型,并托管其自定义模型。
-
资源需求:
- 微调集群 (Fine-tuning Cluster): 需要 8 个 Small Cohere Dedicated 单元。
- 托管集群 (Hosting Cluster): 至少需要 1 个 Small Cohere Dedicated 单元来托管微调后的模型。
-
使用模式:
- 微调: 每周进行一次,每次任务耗时 5 小时。每月共进行 4 次。
- 托管: 微调后的模型将全月持续托管。
-
服务承诺:
- 托管: 有月度最低承诺 (Minimum Commitment),即一旦托管,将按月计费,即使实际使用不满一个月,也会收取744 单位小时 (Unit Hours) 的费用(一个月大约 31 天 * 24 小时 = 744 小时)。不能进行部分月度托管 (Cannot Do Partial Hosting)。
- 微调: 按实际使用时间计费,最低计费单位为 1 小时 (Minimum 1 Hour)。如果任务耗时不足 1 小时,按 1 小时收费;超过 1 小时则按每小时累加。
-
成本计算:
- 微调成本:
- 每次微调任务所需单位小时数:8 单元 * 5 小时 = 40 单位小时。
- 每月微调总单位小时数:40 单位小时/周 * 4 周/月 = 160 单位小时。
- 每月微调费用 = 160 单位小时 *
dedicated-unit-small-cohere-count单价。
- 托管成本:
- 每月托管总单位小时数:1 单元 * 744 小时/月 = 744 单位小时。
- 每月托管费用 = 744 单位小时 *
dedicated-unit-small-cohere-count单价。
- 总月度成本: (160 + 744) 单位小时 *
dedicated-unit-small-cohere-count单价 = 904 单位小时 * 单价。
- 微调成本:
-
实际价格示例: 假设
dedicated-unit-small-cohere-count的单价为 $6.50/单位小时(请务必查阅 OCI 官方定价页面获取最新价格)。- 总月度成本 = 904 单位小时 * $6.50/单位小时 ≈ $5,876。
结论: Bob 每月在专用 AI 集群上进行模型微调和托管的成本约为 $6,000。
重要提示: 请始终查阅 OCI 官方文档 https://docs.oracle.com/en-us/iaas/Content/generative-ai/pay-dedicated.htm 和定价页面,以获取最准确和最新的信息,因为模型支持、单元价格等可能会随时间变化。
生成式 AI 微调配置
深入探讨了 OCI 生成式 AI 服务 (Generative AI Service) 中的微调 (Fine-tuning) 配置选项,主要包括可用的训练方法(T-Few 和 LoRA)、重要的超参数 (Hyperparameters) 以及如何评估微调结果。
解释了复杂概念,并重点分析了准确率 (Accuracy) 和损失 (Loss) 这两个关键评估指标的含义、计算方式及其在生成式 AI 上下文中的适用性,指出损失 (Loss) 是更优选的评估指标。
1. 可用的微调训练方法
在 OCI 生成式 AI 服务中,目前支持两种主要的训练方法 (Training Methods),它们都属于参数高效微调 (Parameter Efficient Fine-Tuning, PEFT) 技术,即在不改变模型所有部分的情况下调整模型:
-
T-Few:
- 概念类比: 想象一个复杂的机器,T-Few 就像是给这台机器添加小的辅助部件 (Helper Parts) 或新层 (New Layers)。这些辅助部件只对机器的少数地方进行微调,而不会改动整体结构。
- 特点: 通过插入少量新层,仅更新这些层的权重,从而实现高效、低成本的微调。
-
LoRA (Low-Rank Adaptation,低秩适应):
- 概念类比: LoRA 就像是给机器添加特殊的齿轮 (Special Gears)。这些齿轮可以调整机器的功能,但不改变 (Leaving Unchanged) 机器的主要部件。
- 特点: 通过向模型的现有层中注入低秩矩阵(即小的可训练矩阵),实现参数高效的微调。
2. 微调配置超参数 (Hyperparameters)
超参数 (Hyperparameters) 是在模型训练之前设定的参数,它们控制着训练过程。以下是一些常见的微调超参数及其通俗解释(具体范围和默认值请以最新文档为准):
| 超参数 (Hyperparameter) | 描述 (Description) | 有效范围 (Valid Range) | 默认值 (Default Value) |
|---|---|---|---|
| Total training epochs (总训练周期) | 模型对整个训练数据集迭代的次数;例如,1 个 epoch 意味着模型使用整个训练数据集训练一次。 |
介于 1 到 10 之间的整数 | 1 |
| Training batch size (训练批次大小) | 在更新模型参数之前处理的样本数量。 | 介于 8 到 32 之间的整数 | 16 |
| Learning rate (学习率) | 每个批次后更新模型参数的速率。 | 介于 0.000005 到 0.1 之间的数字 | 0.01 |
| Early stopping threshold (提前停止阈值) | 防止训练过程过早终止所需的损失的最小改进量。 | 介于 0.001 到 0.1 之间的数字 | 0.001 |
| Early stopping patience (提前停止耐心) | 在决定停止训练过程之前,对损失指标停滞的容忍度。 | 0 (禁用) 或介于 1 到 16 之间的整数 | 10 |
| Log model metrics interval in steps (日志模型指标间隔步数) | 确定记录模型指标(训练损失和学习率)的频率。 | 无法调整,固定为 1 | 1 |
-
Total Training Epochs (总训练周期):
- 类比: 机器学习任务数据需要“学习”的次数 (How Many Times)。更多的 Epochs (周期) 意味着更长的学习时间。
- 定义: 模型在整个训练数据集上完整迭代的次数。
-
Training Batch Size (训练批次大小):
- 类比: 机器每次学习任务数据时的“份量” (How Many Parts)。大批次可以加速学习,但小批次可能提供更详细的洞察。
- 定义: 在进行一次模型参数更新前,用于计算梯度的数据样本数量。
-
Learning Rate (学习率):
- 类比: 机器根据所学知识调整设置的速度 (How Fast)。高学习率意味着快速调整,低学习率意味着更谨慎的改变。
- 定义: 控制模型在每次迭代中更新其权重的步长。
-
Early Stopping Threshold (提前停止阈值):
- 类比: 设定机器何时停止学习的标准 (Standard),如果学习进度不够快。
- 定义: 当模型性能在验证集上停止改进时,用于决定是否提前停止训练的最小改进量。
-
Early Stopping Patience (提前停止耐心):
- 类比: 机器在决定停止学习前等待的时间 (How Long)。
- 定义: 在性能没有改进的情况下,模型继续训练的周期数。
-
Log Model Metrics Interval in Steps (日志模型指标间隔步数):
- 类比: 机器在学习过程中检查和记录进展的频率 (How Often)。
- 定义: 模型在训练过程中记录和报告性能指标(如损失、准确率)的训练步数间隔。
3. 评估微调结果的指标
评估微调结果主要使用两个关键指标:准确率 (Accuracy) 和损失 (Loss)。
-
准确率 (Accuracy):
- 定义: 衡量模型生成的 Token (词元) 是否与标注的 Token (Annotated Tokens)(即正确的或预期的 Token)相匹配的程度。通常计算为正确预测的 Token 百分比。
- 标注 Token: 指由人工专家标注或从高质量参考数据中提取的,对于给定输入而言是正确输出的 Token (词或字符)。
- 示例:
- 真实情况 (Ground Truth): "The cat sat on the mat." (猫坐在垫子上。)
- 模型预测 (Model Predicted): "The cat slept on the rug." (猫睡在毯子上。)
- 正确 Token: 4/6 个("The", "cat", "on", "the")。
- 准确率: (4 / 6) * 100% ≈ 67%。
- 局限性: 即使模型输出传达了相同的含义但使用了不同的词语,准确率可能仍然很低。这使得它在生成式 AI 中并非总是最佳的评估指标。
-
损失 (Loss):
- 定义: 衡量模型生成输出的“错误”程度。损失越低,模型表现越好。
- 计算方式: 通过模型预测的概率分布 (Probability Distribution) 与实际输出之间的差异来计算(不深入技术细节)。
- 理解:
- 损失为 0 (Loss of 0): 意味着所有输出都完美无缺。
- 大损失值 (Large Loss Number): 表示输出高度随机或与预期完全不符。
- 损失随模型改进而降低 (Loss Decreases as Model Improves)。
- 示例 (承接准确率示例):
- 真实情况: "The cat sat on the mat."
- 模型预测 1: "The cat slept on the rug."
- 虽然准确率仅 67%,但“slept”与“sat”都表示休息动作,“rug”与“mat”都是地板覆盖物,上下文相似 (Context is Similar),错误较小 (Mistakes are Minor)。因此,损失相对较低 (Loss is Relatively Low)。
- 模型预测 2: "The airplane flew at midnight." (飞机午夜起飞。)
- 该输出与真实情况完全不相关。
- 在这种情况下,损失非常高 (Loss is Very High),因为模型输出与真实情况完全不同且无关。
- 优势: 损失是评估生成式 AI 模型微调结果的更优选指标 (Preferred Metric),因为它能够更好地捕捉模型输出与真实情况之间的语义或上下文相似性,而不仅仅是字面匹配。生成式 AI 往往没有唯一的正确答案,上下文 (Context) 的重要性更高。
OCI 生成式 AI 安全架构
详细介绍了 Oracle Cloud Infrastructure (OCI) 中生成式 AI 服务 (Generative AI Service) 的安全架构。核心原则是确保客户工作负载的安全性 (Security) 和隐私性 (Privacy)。OCI 通过提供专用 GPU (Dedicated GPUs) 和专用 RDMA 网络 (Dedicated RDMA Network) 实现物理隔离,确保模型和数据的单租户隔离。此外,服务还利用 OCI 其他成熟的安全服务,如 身份与访问管理 (Identity and Access Management, IAM) 进行认证和授权,以及密钥管理 (Key Management) 和对象存储 (Object Storage) 进行数据加密和安全存储,从而构建了一个全面的安全保障体系。
1. 物理层隔离与模型数据隔离
- GPU 资源隔离: OCI Generative AI 服务为客户的生成式任务分配的 GPU (Graphics Processing Unit) 是相互隔离的。
- 通过创建专用 AI 集群 (Dedicated AI Cluster),将一组特定的 GPU 资源池化,并使其运行在专用 RDMA 网络 (Dedicated RDma Network) 中。
- 这些 GPU 仅分配给单个客户,不与其他客户共享 (Not Shared Across Customers)。
- 模型与数据隔离:
- 您的专用 GPU 集群 (Dedicated GPU Cluster) 仅处理您的模型,包括您的基础模型 (Base Models) 和微调模型 (Fine-tuned Models),仅供单个客户使用。
- 这意味着所有模型(如基础模型端点 (Base Model Endpoint) 和自定义模型端点 (Custom Model Endpoints))都运行并包含 (Contained) 在您专属的 GPU 集合内。
- 这种设计确保了客户的模型隔离 (Model Isolation) 和数据隔离 (Data Isolation)。
2. 客户租户间的数据访问限制
- 租户内数据访问限制: 客户数据的访问被严格限制在客户自己的租户 (Tenancy) 内部。
- 一个客户的数据不能被另一个客户看到 (Cannot Be Seen by Another Customer)。
- 只有客户自己的应用程序才能访问在该客户租户内创建和托管的自定义模型 (Custom Models)。
- 示例: 如果存在客户 1 和客户 2,他们各自拥有自己的专用 AI 集群 (Dedicated AI Clusters) 和运行在其集群中的自定义模型 (Custom Models)。客户 2 的应用程序无法访问 (Cannot Access) 客户 1 的任何自定义模型,反之亦然。这种机制确保了客户数据和模型的完全隔离。
3. 整合 OCI 其他安全服务
OCI Generative AI 服务进一步利用了 OCI 平台提供的其他成熟安全服务,以增强整体安全性:
-
OCI 身份与访问管理 (Identity and Access Management, IAM):
- 用途: 用于认证 (Authentication) 和授权 (Authorization)。
- 功能: 您可以精细地控制哪些应用程序(例如 Application X 和 Application Y)或用户可以访问特定的模型(例如 Application X 只能访问 Custom Model X,而 Application Y 只能访问 Base Model)。这决定了谁可以访问这些模型以及他们拥有何种级别的访问权限。
-
OCI 密钥管理 (Key Management):
- 用途: 安全地存储和管理加密密钥。
- 功能: OCI Generative AI 服务利用密钥管理 (Key Management) 服务来安全地存储基础模型 (Base Model) 的密钥。
-
OCI 对象存储 (Object Storage):
- 用途: 存储模型权重和其他数据。
- 功能: 微调模型权重 (Fine-tune Model Weights) 被存储在 OCI 对象存储桶 (Object Storage Buckets) 中。
- 加密: 这些存储桶中的数据默认是加密 (Encrypted) 的,并且其加密密钥由密钥管理服务 (Key Management Service) 负责管理。
4.RAG using Generative AI service and Oracle 23 ai Vector Search
OCI 生成式 AI 与框架及服务的集成
本节探讨了 Oracle Cloud Infrastructure (OCI) 的生成式 AI 服务 (Generative AI Service) 如何与流行的开源框架(特别是 LangChain)以及其他 OCI 服务进行集成。通过这些集成,用户能够更便捷地构建功能丰富的基于 LLM (大型语言模型) 的应用程序。
详细介绍了 LangChain 的核心组件,如模型、提示、内存和链,并解释了它们如何协同工作以处理用户查询并生成响应。此外,还强调了 Oracle 23ai 作为向量存储 (Vector Store) 的作用以及它与 OCI 生成式 AI 服务的多方面集成。
1. 开源框架集成概述
- OCI 生成式 AI 服务不仅提供生成、摘要和嵌入数据的功能,还能与各种有用的框架和 OCI 服务无缝集成。
- 这些集成使得构建复杂的 LLM (大型语言模型) 驱动的应用程序变得更加容易。
- 开源框架 (Open-source Frameworks) 提供了丰富的组件,用于构建 LLM 应用程序,其中就包括与 OCI 生成式 AI 服务的集成。
2. LangChain 框架详解
LangChain 是一个专门用于开发由语言模型驱动的应用程序的框架,其核心优势在于使应用程序具备上下文感知 (Context-aware) 能力,并能基于提供的上下文让语言模型进行回答。
- 核心组件: LangChain 提供了一系列组件,助力轻松构建 LLM 驱动的应用程序,包括:
- 大型语言模型 (Large Language Models, LLMs)
- 提示 (Prompts)
- 内存 (Memory)
- 链 (Chains)
- 向量存储 (Vector Stores)
- 文档加载器 (Document Loaders)
- 文本分割器 (Text Splitters)
- 以及许多其他组件。
- 组件可交换性: 这些组件具有高度可交换性,例如,可以仅通过少量代码修改就轻松地在不同 LLM 之间进行切换。
3. LangChain 中的模型类型
LangChain 主要集成两种类型的模型,它们根据输入和输出类型进行区分:
-
LLMs (纯文本补全模型):
- 输入: 接收一个字符串提示 (String Prompt) 作为输入。
- 输出: 返回一个字符串补全 (String Completion)。
- 用途: 主要用于文本生成和补全任务。
-
Chat Models (聊天模型):
- 输入: 通常由 LLMs 提供支持,但经过专门微调 (Tuned) 以进行对话。它们接收一个聊天消息列表 (List of Chat Messages) 作为输入。
- 输出: 返回一个 AI 消息 (AI Message) 作为输出。
- 用途: 专门用于构建对话式应用程序,如聊天机器人。
4. LangChain 中的提示 (Prompts)
在 LangChain 中,提示可以通过两种主要的提示类创建:
-
PromptTemplate (提示模板):
- 创建方式: 从一个格式化的 Python 字符串创建,该字符串结合了固定文本 (Fixed Text) 和任意数量的占位符 (Placeholders)。
- 填充: 占位符在代码执行时被填充。
- 用途: 通常与生成模型 (Generation Models) 一起使用,但也可用于聊天模型 (Chat Models)。
-
ChatPromptTemplate (聊天提示模板):
- 构成: 由一个聊天消息列表 (List of Chat Messages) 组成,每条消息都包含角色 (Role) 和内容 (Content)。
- 用途: 专门用于聊天模型 (Chat Models)。
5. LangChain 中的链 (Chains)
链 (Chains) 是 LangChain 提供的框架,用于将不同的组件(包括 LLMs 和其他类型组件)串联 (String Together) 起来,形成一个端到端的工作流。
- 链的构成方式:
- LangChain 表达式语言 (LangChain Expression Language, LCEL): 这是一种声明式 (Declarative) 且推荐 (Preferred) 的链创建方式。它提供了一种简洁、灵活的方式来组合链。
- LangChain Python 类 (LangChain Python Classes): 例如
LLMChain,可以通过 Python 类的方式创建链。
6. 模型、提示和链的协同工作
该流程图描绘了 LangChain 中处理用户查询到生成响应的关键步骤和组件之间的交互:
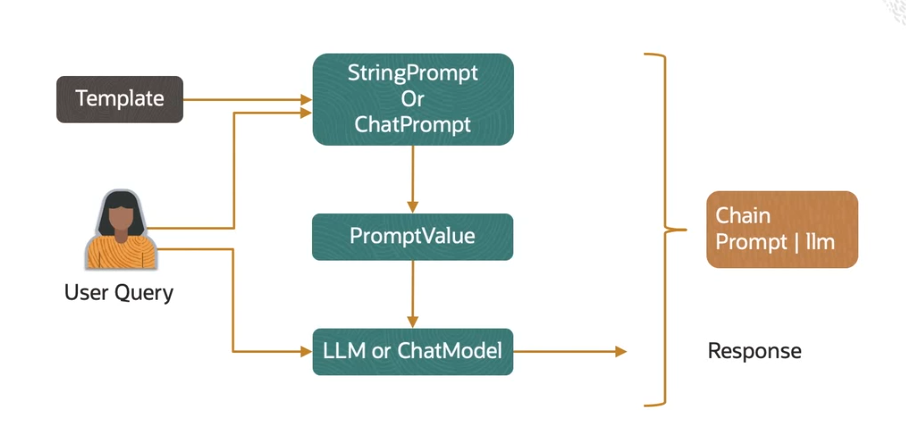
1. 输入阶段:用户查询与提示模板
- User Query (用户查询): 这是整个流程的起点,代表了用户向 LLM (大型语言模型) 发出的原始问题或指令。图中左侧的人形图标表示用户输入。
- Template (模板): 这指的是提示模板 (Prompt Template),如
StringPrompt或ChatPrompt。这些模板预定义了生成最终提示的结构,通常包含固定文本和用于填充变量的占位符。
2. 提示生成阶段:构建 PromptValue
- StringPrompt 或 ChatPrompt (字符串提示或聊天提示):
- 用户查询可以直接或间接地(通过模板)输入到这里。
- 模板 (Template) 提供结构和固定内容,而用户查询 (User Query) 则填充其中的变量部分。
- 这一步结合了用户输入和预设的提示结构,用于生成模型可理解的指令。
- PromptValue (提示值):
- StringPrompt 或 ChatPrompt 的输出是一个完整的、上下文丰富的提示值 (PromptValue)。
- 这个提示值包含了 LLM 进行推理所需的所有上下文信息,例如指令、示例或运行时捕获的数据。它是 LLM 实际接收的输入形式。
3. 模型处理阶段:LLM 或 ChatModel
- LLM 或 ChatModel (大型语言模型或聊天模型):
- PromptValue (提示值) 会被传递给相应的语言模型 (Language Model)。
- 根据应用的性质,这可以是纯粹的文本补全模型 (LLM),也可以是专门为对话优化的聊天模型 (ChatModel)。
- 用户查询 (User Query) 也可以直接(不通过提示模板)输入到 LLM 或 ChatModel。然而,如图所示,通常会通过提示模板来添加更多上下文,以获得更佳的响应。
4. 输出阶段:生成响应
- Response (响应): 这是 LLM 或 ChatModel 根据接收到的提示值进行处理后生成的最终输出。这个响应就是对用户查询 (User Query) 的答案或完成结果。
5. 链 (Chain) 的作用
- Chain (Prompt | LLM): 图中最右侧的棕色矩形表示链 (Chain)。
- 链的编排能力: 链是 LangChain 的一个核心概念,它能够将上述的各个步骤(如接受输入、构建提示、调用模型)串联 (String Together) 起来,形成一个完整的、可执行的流程。它提供了一种声明式或编程式的方式来定义这些组件之间的顺序和数据流动,从而简化了复杂 LLM 应用程序的开发。
总结:
整个流程体现了 LangChain 如何通过结构化的提示 (Prompt) 构建机制,将用户的原始意图与必要的上下文结合起来,生成适合大型语言模型 (LLM) 处理的输入 (PromptValue)。随后,选择合适的模型 (LLM 或 ChatModel) 进行推理,并最终生成响应 (Response)。而链 (Chain) 则在幕后负责编排和管理这些组件之间的协作,使得整个流程自动化且易于开发和维护。
7. LangChain 中的内存 (Memory)
- 会话存储: 内存 (Memory) 用于存储与聊天机器人在某个时间点的对话 (Conversation)。
- 对话检索: 链 (Chain) 可以使用键从内存中检索对话 (一系列聊天消息),并将其连同当前问题一起传递给 LLM。
- 写回内存: 一旦链收到对最新查询的新答案,它会将该查询和答案写回到内存中,从而维持会话的上下文。
- 多样的内存类型: LangChain 提供多种内存类型 (Memory Types),根据内存返回的内容而异。例如,有些内存类型返回会话内容的摘要 (Summary),而不是完整内容;甚至可以返回提取的实体 (Extracted Entities)(如人名)。
8. OCI 生成式 AI 与 Oracle 23ai 的集成
Oracle 23ai 可以作为向量存储 (Vector Store),并且 LangChain 提供了 Python 类,用于在 Oracle 23ai 向量存储中存储和搜索嵌入 (Embeddings)。
OCI 生成式 AI 服务通过多种方式被 Oracle 23ai 利用:
- 生成数据库外部的嵌入: 可以使用 DB UTILs 和 REST API 访问 OCI 生成式 AI 服务,在数据库外部生成嵌入 (Embeddings)。
- Oracle 23ai SELECT AI: Oracle 23ai 的 SELECT AI 功能可以利用 OCI 生成式 AI 服务,通过自然语言 (Natural Language) 生成 SQL (Structured Query Language) 查询数据库中存储的数据。
- 通过 LangChain 类使用: OCI 生成式 AI 服务可以直接通过 LangChain 类进行调用和使用。
- Python SDK 构建应用: 使用 Python SDK 可以创建同时利用 OCI 生成式 AI 服务和 Oracle 23ai 向量存储的应用程序。
检索增强生成 (RAG)
本节详细解释了检索增强生成 (Retrieval Augmented Generation, RAG) 技术。传统语言模型仅依赖其训练数据生成响应,可能导致信息过时或存在偏差。RAG 通过从外部源检索 (Retrieve) 最新信息,并将其作为附加上下文提供给大型语言模型 (LLM),从而生成更相关、更准确的响应。文章阐述了 RAG 的多项优势,并分阶段详细介绍了其基本管道 (Pipeline):摄取 (Ingestion)、检索 (Retrieval) 和生成 (Generation)。
1. 什么是检索增强生成 (RAG)?
- 传统 LLM 的局限性: 传统的语言模型 (Language Models) 仅根据其训练数据 (Training Data) 生成响应,这可能导致信息过时或出现“幻觉 (Hallucinations)”(生成听起来合理但实际不准确或虚构的信息)。
- RAG 的核心思想: RAG (Retrieval Augmented Generation) 通过从外部来源 (External Sources) 检索最新 (Up-to-date) 信息来解决这一问题。它将这些额外且具体的信息与用户查询 (User Query) 一起提供给 LLM (大型语言模型),从而增强 (Enhancing) 提供给 LLM 的上下文 (Context),使其能够生成更相关 (More Relevant) 的响应。
2. RAG 的主要优势
RAG 方法带来了多项显著优势:
- 缓解偏差和错误: 标准 LLM 有时会延续其训练数据 (Training Data) 中存在的偏差 (Biases) 或错误 (Errors)。RAG 可以通过引入多样的视角 (Perspectives) 和来源 (Sources) 来减轻这些问题,从而生成更平衡 (More Balanced) 和更准确 (More Accurate) 的响应。
- 克服模型上下文限制: RAG 可以克服 LLM 的Token 限制 (Token Limits)(即模型在一次输入中能处理的最大文本长度)。由于我们只将Top K (前 K 个) 相关的搜索结果(而不是整个文档)输入到 LLM 中,这使得模型能够处理更长的信息源。
- 处理更广泛的查询范围: RAG 允许模型处理更广泛的查询范围,而无需通过指数级增加 (Exponentially Larger) 训练数据集来实现。这意味着模型可以访问并回答其原始训练数据中不包含的最新或特定领域的信息。
3. 检索增强生成 (RAG) 的基本管道 (Pipeline)
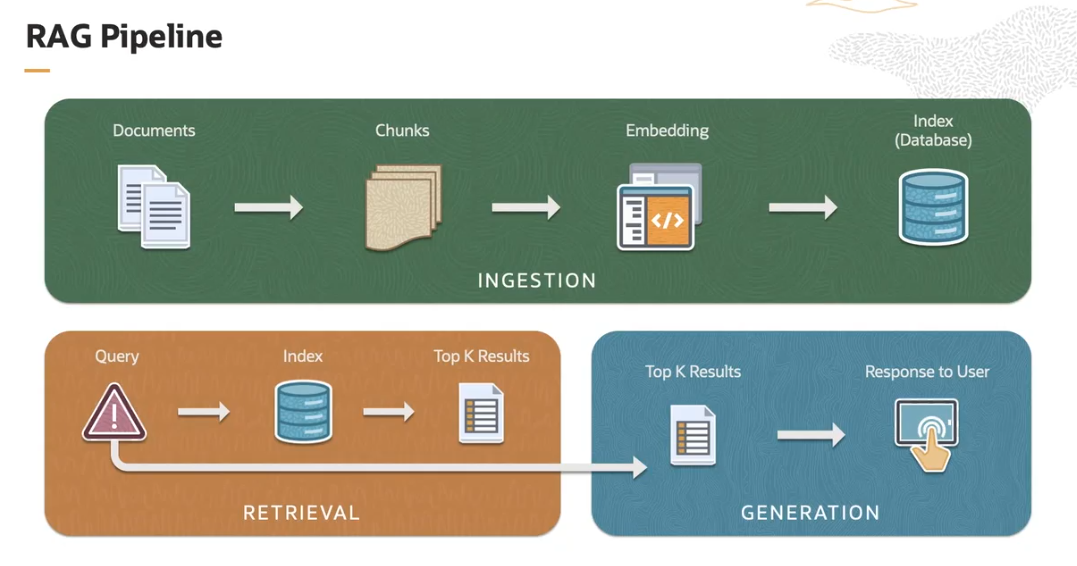
一个基本的 RAG 管道通常分为三个主要阶段:
3.1. 摄取 (Ingestion) 阶段
这是将文档导入系统的第一阶段:
- 加载文档 (Loading Documents): 首先,将原始文本语料库 (Text Corpus) 加载到系统中。
- 文档分块 (Document Chunking): 文档被分解成更小、更易于管理的块 (Chunks)。这通常是为了聚焦文本中的相关部分。
- 生成嵌入 (Generating Embeddings): 每个块 (Chunk) 随后被转换为一种数学表示 (Mathematical Representation),称为嵌入 (Embeddings)。这些嵌入捕获文本的语义信息 (Semantic Information),并允许在数值空间 (Numerical Space) 中进行相似性比较。
- 嵌入索引 (Indexing Embeddings): 这些嵌入被索引到一个数据库 (Database) 中,以方便快速检索。索引 (Index) 是一种数据结构,允许系统在进行查询时高效地查找和检索嵌入。
3.2. 检索 (Retrieval) 阶段
在此阶段,系统使用索引数据 (Index Data) 来查找相关信息:
- 用户查询 (User Query): 检索过程始于用户输入需要回答的问题 (Question)。
- 查询嵌入与搜索 (Query Embedding and Search): 系统会将用户查询转换成嵌入 (Embedding),然后使用这个嵌入在已存储的索引嵌入 (Indexed Embeddings) 中进行搜索,以找到最相关的块 (Most Relevant Chunks)。
- 选择 Top K 结果 (Selecting Top K Results): 从检索到的文档中,系统会选择Top K(一个预设的数字)个最相关的结果。这些是包含与查询相关信息可能性最大的块 (Chunks)。
3.3. 生成 (Generation) 阶段
这是系统根据检索到的信息生成响应的最后阶段:
- 信息输入到生成模型 (Feeding Information to Generative Model): 从检索阶段 (Retrieval Phase) 选择的块 (Chunks) 被输入到生成模型 (Generative Model) 中。
- 生成响应 (Generating Response): 生成模型(通常是像Transformer (转换器) 这样的神经网络 (Neural Network))利用 Top K 块 (Chunks) 提供的上下文 (Context),生成一个连贯 (Coherent) 且上下文相关 (Contextually Relevant) 的查询响应。
RAG 架构在以下场景中非常有效:当生成模型 (Generative Models) 需要补充其训练数据 (Training Data) 中可能不存在的特定信息时。
RAG 管道之摄取阶段
本节详细阐述了检索增强生成 (RAG) 管道的摄取 (Ingestion) 阶段。该阶段的核心是将各种格式的原始文档加载并分割成适合大型语言模型 (LLM) 处理的小块 (Chunks)。
深入探讨了文档分割时的关键考虑因素,包括块的大小 (Chunk Size)、块重叠 (Chunk Overlap) 以及如何保持语义连续性 (Semantic Continuity),并通过一个示例代码片段说明了如何使用工具加载和分割 PDF 文档。
1. 摄取阶段概述
- 摄取 (Ingestion) 是 RAG (Retrieval Augmented Generation) 管道的第一个阶段。
- 其主要目标是将原始文档转化为可用于后续检索 (Retrieval) 和生成 (Generation) 阶段的结构化数据。
2. 文档加载 (Loading Documents)
- 多样化的来源和格式: 文档可以来自各种来源,并具有多种格式,例如 PDF、CSV (逗号分隔值)、HTML、JSON 等。
- LLM 框架的支持: 大多数 LLM 框架 (LLM Frameworks),包括 LangChain,都提供了专门的类来加载不同类型的文档。
- 加载范围: 这些加载器类 (Loader Classes) 不仅支持加载单个文档,还支持加载给定目录中的所有文档。
3. 文档分割 (Splitting Documents into Chunks)
文档加载后,下一步是将其分割成更小的片段,通常称为块 (Chunks)。在分割文档时,需要考虑以下几个关键因素:
- 块的大小 (Chunk Size):
- LLM 上下文窗口限制: 大多数 LLM 都有最大的输入尺寸限制 (Maximum Input Size Constraints),即上下文窗口 (Context Window) 的大小。因此,块 (Chunk) 的最大尺寸受限于 LLM 的上下文窗口。
- 作用: 将文档分割成较小的块有助于使文档适应 LLM 的上下文窗口。
- 权衡:
- 如果块太小,它们可能不包含足够的语义信息 (Semantically Useful),导致上下文缺失。
- 如果块太大,它们可能不够语义具体 (Semantically Specific),包含不必要的冗余信息。
- 最佳实践: 需要找到一个平衡点,确保块既能适应 LLM 的上下文窗口,又能包含足够且相关的上下文信息。

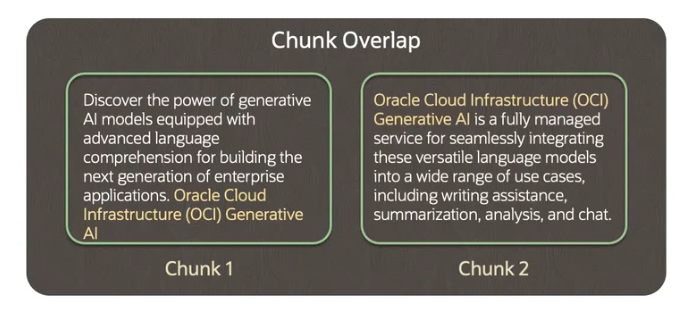
- 块重叠 (Chunk Overlap):
- 目的: 为了维护从一个块 (Chunk) 到另一个块的上下文连续性 (Continuity of the Context)。
- 方法: 在将文档分割成多个块时,下一个块会包含前一个块的一部分内容。
- 优势: 这种重叠 (Overlap) 确保了即使一个概念或信息跨越了多个块,每个块也能保留对先前上下文的引用,从而提高上下文连续性。
-
分割策略与语义意义 (Splitting Strategy and Semantic Meaning):
-
目标: 将文档分割成足够小 (Small Enough) 的块 (Chunks),以便它们可以适应大型语言模型 (LLM) 的上下文窗口 (Context Window)。
-
默认分隔符: 默认的分割器列表通常包括:
["\n\n"]:表示两个换行符,通常用于分割段落 (Paragraphs)。["\n"]:表示单个换行符,通常用于分割行 (Lines)。[" "]:表示空格,通常用于分割单词 (Words)。[""]:表示空字符串,即逐个字符分割。
-
保持语义完整性 (Semantic Integrity)
- 优先级: 文档分割的核心策略是尽可能长时间地保持所有段落 (Paragraphs)(然后是句子,然后是单词)在一起 (Keep All Paragraphs (and then Sentences, and then Words) Together as Long as Possible)。
- 语义关联性: 这样做的原因是因为从语义上讲,段落、句子和单词通常是最强相关的文本片段 (Strongest Semantically Related Pieces of Text)。
- 例如,一个段落通常围绕一个单一的主题或概念。
- 一个句子表达一个完整的思想。
- 保持这些结构完整有助于确保每个块 (Chunk) 都包含有意义的、连贯的上下文信息,这对于后续的嵌入 (Embedding) 和检索 (Retrieval) 阶段至关重要。
-
示例:文本分割效果

如果按照上述分割方法进行处理,系统会首先尝试根据双换行符(
\n\n)分割成段落。如果一个段落太长无法满足块 (Chunk) 大小限制,它会进一步尝试根据单换行符(\n)分割成行。如果行仍然太长,则会尝试按空格( -
4. PDF 文档加载和分割示例代码
from pypdf import PdfReader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_core.documents import BaseDocumentTransformer, Document
# Load the document and create pdf reader object
pdf = PdfReader('./pdf-docs/oci-ai-foundations.pdf')
# Transform the document to text
text = ""
for page in pdf.pages:
text += page.extract_text()
print("You have transformed the PDF document to text format")
# Chunk the text document into smaller chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=100)
chunks = text_splitter.split_text(text)
1. 导入所需库
from pypdf import PdfReader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_core.documents import BaseDocumentTransformer, Document
pypdf.PdfReader: 用于读取和解析 PDF 文件的库。
-
langchain.text_splitter.RecursiveCharacterTextSplitter: LangChain 框架中一个功能强大的文本分割器,它能够递归地使用不同的分隔符(如段落、句子、单词)来分割文本,以尽可能保持语义完整性。 -
langchain_core.documents.BaseDocumentTransformer, Document: 虽然在当前的代码片段中 BaseDocumentTransformer 和 Document 没有直接使用,但它们通常是 LangChain 文档处理流程中的核心组件。Document 类用于封装文本内容及其元数据,而 BaseDocumentTransformer 是用于转换文档的基类。
2. 加载文档并转换为文本
# Load the document and create pdf reader object
pdf = PdfReader('./pdf-docs/oci-ai-foundations.pdf')
# Transform the document to text
text = ""
for page in pdf.pages:
text += page.extract_text()
print("You have transformed the PDF document to text format")
-
加载 PDF 文件:
pdf = PdfReader('./pdf-docs/oci-ai-foundations.pdf')这行代码创建了一个 PdfReader 对象,用于读取指定路径(./pdf-docs/oci-ai-foundations.pdf)下的 PDF 文件。 -
提取文本: 紧接着的 for 循环遍历 PDF 的每一页 (pdf.pages),并使用
page.extract_text()方法从每页中提取文本内容。提取出的文本被逐页追加到 text 字符串变量中,最终形成一个包含整个 PDF 文档内容的单一文本字符串。 -
打印消息:
print("You have transformed the PDF document to text format")用于确认文本提取过程已完成。
3. 将文本文档分割成小块 (Chunks)
# Chunk the text document into smaller chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=100)
chunks = text_splitter.split_text(text)
-
实例化 RecursiveCharacterTextSplitter:
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=100)这行代码创建了一个文本分割器实例。 -
chunk_size=2000:指定了每个块 (Chunk) 的最大字符数或 Token 数(取决于分割器的具体实现,通常是字符数)。 -
chunk_overlap=100:指定了相邻块 (Chunks) 之间重叠的字符数或 Token 数。这种重叠有助于在后续的检索 (Retrieval) 过程中保持上下文的连续性 (Contextual Continuity),避免信息在块边界处被截断而丢失关键语义。 -
执行文本分割:
chunks = text_splitter.split_text(text)调用 text_splitter 对象的 split_text() 方法,将之前从 PDF 中提取的完整文本字符串 (text) 分割成一系列较小的块 (Chunks)。这些块被存储在 chunks 列表中,每个元素代表一个独立的文本片段。
RAG 管道之嵌入与存储
本节详细讲解了检索增强生成 (RAG) 管道的第二个关键环节:将文档块 (Chunks) 转换为嵌入 (Embeddings) 并将其存储起来以便检索 (Retrieval)。
首先通过直观的类比解释了嵌入 (Embeddings) 的概念及其在机器理解语义相似性中的作用。
随后,探讨了如何在数据库内部或外部生成嵌入,并重点介绍了 Oracle 23ai 中新增的向量数据类型 (Vector Data Type) 来存储这些嵌入。
最后,通过一个代码示例的逻辑流程,展示了如何将文档块转换为适合存储的格式,并使用 OCI 生成式 AI 服务生成嵌入,最终将其存储到 Oracle 23ai 向量存储 (Vector Store) 中,为后续的语义搜索 (Semantic Search) 奠定基础。
1. 什么是嵌入 (Embeddings)?
- 人类对相似性的理解: 当我们看到“老虎”这个词时,我们会立即将其归类到“动物”组,因为我们知道“老虎”在语义上与“动物”组中的词汇相似。
- 机器对相似性的理解(嵌入): 对于机器而言,为了理解词语、句子甚至文档之间的相似性 (Similarity),引入了嵌入 (Embeddings) 的概念。
- 多维空间中的表示: 嵌入是词语、句子或文档在多维空间 (Multidimensional Space) 中的数值表示 (Numerical Representation)。在经过训练后,语义相似的词语或句子(或文档)的嵌入在多维空间中会彼此靠近。
- 语义相似性: 这种数值表示能够反映文本的语义相似性 (Semantic Similarity)。通过计算嵌入之间的距离,机器可以量化它们之间的相似度。
- 可视化: 即使是二维嵌入图,也能直观地显示出语义相似的词语(如“猫”、“狗”)会聚在一起,而与不相似词语(如“苹果”、“巴黎”)则相距较远。
2. 如何从块中生成嵌入 (Generating Embeddings from Chunks)
- 嵌入模型 (Embedding Model): 嵌入是使用经过训练的嵌入模型 (Trained Embedding Model) 创建的。
- Oracle 23ai 的支持: Oracle 23ai 支持在数据库内部 (Inside the Database) 或数据库外部 (Outside the Database) 生成嵌入。
- 数据库外部生成: 可以使用第三方嵌入模型。
- 数据库内部生成: 如果希望将数据保留在数据库内部,可以将 ONNX (Open Neural Network Exchange) 格式的嵌入模型导入到 Oracle 23ai 数据库中,然后在数据库内部对块进行嵌入操作。
3. 如何存储嵌入 (Storing Embeddings)
- Oracle 23ai 的新数据类型:
VECTOR(向量): Oracle 23ai 引入了一种新的数据类型VECTOR,专门用于在数据库列中存储嵌入。 - 创建包含向量的表: 在创建数据库表时,可以添加一个
VECTOR类型的列,与其他数据类型的列并存,用于存储嵌入。 - 数据操作: 可以使用标准的数据库
INSERT或UPDATE语句来创建或更新包含向量数据类型 (Vector Data Type) 的记录。
4. 代码示例:嵌入块并存储到 Oracle 23ai 向量存储
步骤 1:建立数据库连接 (Create Database Connection)
import oracledb
import oci
# Declare username and password and dsn (data connection string)
un = "vector"
pw = "vector"
cs = "localhost/FREEPDB1"
# Connect to the database
try:
conn23c = oracledb.connect(user=un, password=pw, dsn=cs)
print("Connection successful!")
except Exception as e:
print("Connection failed!")
1. 导入所需库
import oracledb
import oci
- import oracledb: 导入 oracledb 库。这是 Oracle 官方提供的用于 Python 连接 Oracle 数据库的驱动程序。
- import oci: 导入 oci 库。虽然在此连接代码中未直接使用,但 oci 库通常用于与 Oracle Cloud Infrastructure (OCI) 服务进行交互,例如获取凭据、访问 OCI Generative AI 服务等,这在 RAG 管道的更广泛上下文中是必需的。
2. 声明连接参数
#Declare username and password and dsn (data connection string)
un = "vector"
pw = "vector"
cs = "localhost/FREEPDB1"
-
un = "vector": 声明数据库连接的用户名 (username)。在此示例中,用户名为 "vector"。
-
pw = "vector": 声明数据库连接的密码 (password)。在此示例中,密码为 "vector"。
-
cs = "localhost/FREEPDB1": 声明数据源名称 (DSN - Data Source Name) 或连接字符串 (connection string)。它指定了数据库的地址和名称。
-
localhost:表示数据库运行在本地机器上。
-
FREEPDB1:表示要连接的可插拔数据库 (Pluggable Database, PDB) 的服务名称。
3. 尝试连接到数据库
# Connect to the database
try:
conn23c = oracledb.connect(user=un, password=pw, dsn=cs)
print("Connection successful!")
except Exception as e:
print("Connection failed!")
-
try...except 块: 使用 try...except 块来包裹数据库连接代码,这是一种良好的编程实践,可以捕获 (Catch) 并处理可能发生的异常 (Exceptions)(例如连接失败)。
-
oracledb.connect() 方法:
conn23c = oracledb.connect(user=un, password=pw, dsn=cs) 这行代码调用 oracledb 库的 connect() 方法,使用前面声明的用户名、密码和 DSN 来尝试建立数据库连接。
-
如果连接成功,返回的连接对象将赋值给 conn23c 变量。
-
连接成功提示: 如果连接成功,程序将打印“Connection successful!”。
-
连接失败处理: 如果在连接过程中发生任何异常(例如数据库不可用、凭据错误等),except Exception as e: 块将被执行,并打印“Connection failed!”。
步骤 2:将块转换为文档对象 (Convert Chunks to Document Objects)
# Declare function to format and add metadata to Oracle 23ai Vector Store
from langchain_core.documents import BaseDocumentTransformer, Document
def chunks_to_docs_wrapper(row: dict) -> Document:
"""
Converts text into a Document object suitable for ingestion into Oracle Vector Store.
- row (dict): A dictionary representing a row of data with keys for 'id', 'link', and 'text'.
"""
metadata = {'id': row['id'], 'link': row['link']}
return Document(page_content=row['text'], metadata=metadata)
# Create metadata wrapper to store additional information in the vector store
"""
Converts a row from a DataFrame into a Document object suitable for ingestion into Oracle Vector Store.
- row (dict): A dictionary representing a row of data with keys for 'id', 'link', and 'text'.
"""
docs = [chunks_to_docs_wrapper({'id': str(page_num), 'link': f'Page {page_num}', 'text': text}) for page_num, text in enumerate(chunks)]
本代码片段演示了如何将文本块 (Chunks) 封装成 LangChain 的 Document 对象,并为每个文档 (Document) 添加相关的元数据 (Metadata)。这是将数据准备好以便摄取 (Ingestion) 到向量存储 (Vector Store) 的关键步骤。
1. 导入所需库
from langchain_core.documents import BaseDocumentTransformer, Document
- langchain_core.documents.BaseDocumentTransformer, Document: 导入 LangChain 核心库中的 BaseDocumentTransformer(用于文档转换的基类,尽管在此片段中未直接实例化)和 Document 类。Document 类是 LangChain 中表示文本内容的标准方式,它能够同时包含文本内容(page_content)和相关的元数据 (metadata)。
2. 定义 chunks_to_docs_wrapper 函数
# Declare function to format and add metadata to Oracle 23ai Vector Store
def chunks_to_docs_wrapper(row: dict) -> Document:
"""
Converts text into a Document object suitable for ingestion into Oracle Vector Store.
- row (dict): A dictionary representing a row of data with keys for 'id', 'link', and 'text'.
"""
metadata = {'id': row['id'], 'link': row['link']}
return Document(page_content=row['text'], metadata=metadata)
-
函数定义: 定义了一个名为 chunks_to_docs_wrapper 的 Python 函数。
-
输入: 接收一个字典 row: dict 作为输入。这个字典预期包含至少三个键:'id'、'link' 和 'text'。
-
输出: 返回一个 Document 对象。
-
元数据创建: metadata =
-
从输入的 row 字典中提取 'id' 和 'link' 的值,并将它们组织成一个新的字典,作为元数据。
-
id: 通常用于唯一标识该块或其来源。
-
link: 可能是一个指向原始文档或相关资源的 URL,用于提供溯源能力。
-
Document 对象创建: return Document(page_content=row['text'], metadata=metadata)
-
创建并返回一个 Document 类的实例。
page_content=row['text']:将输入字典中的 'text' 值设置为 Document 对象的主体内容(即块的实际文本)。
- metadata=metadata:将之前创建的元数据字典附加到 Document 对象上。
这个函数的作用是将结构化的数据(在本例中是字典形式的块信息)转换为 LangChain 能够理解和处理的文档对象 (Document Object),并附带了重要的元数据。
3. 将块转换为文档列表
# Create metadata wrapper to store additional information in the vector store
# Converts a row from a DataFrame into a Document object suitable for ingestion into Oracle Vector Store.
# - row (dict): A dictionary representing a row of data with keys for 'id', 'link', and 'text'.
docs = [chunks_to_docs_wrapper({'id': str(page_num), 'link': f'Page {page_num}', 'text': text})
for page_num, text in enumerate(chunks)]
-
列表推导式: 这行代码使用列表推导式 (List Comprehension),遍历之前分割好的 chunks 列表(假设 chunks 是一个包含所有文本块的列表)。
-
enumerate(chunks): enumerate 函数在迭代 chunks 列表时,同时提供了每个块 (Chunk) 的索引(在这里用作 page_num,尽管它实际上是块的序号,而非真正的页码)和块的实际文本内容。
-
构建输入字典: 对于每个块,都会构建一个字典作为 chunks_to_docs_wrapper 函数的输入:
-
'id': str(page_num):使用块的序号作为其 ID。
-
'link': f'Page {page_num}':创建一个简单的链接字符串,指示该块可能来源于“Page X”(同样,这里的“Page X”是块的序号概念化表示,并非真实的 PDF 页码)。
-
'text': text:块的实际文本内容。
-
创建 docs 列表: chunks_to_docs_wrapper 函数被调用,将每个处理过的块转换为一个文档对象 (Document Object),所有这些文档对象最终被收集到一个名为 docs 的列表中。
步骤 3:生成嵌入并存储到向量存储 (Embed and Store to Vector Store)
from langchain_community.vectorstores.oraclevs import OracleVS
from langchain_community.embeddings import OCIGenAIEmbeddings
from langchain_community.vectorstores.utils import DistanceStrategy
# Using an embedding model, embed the chunks as vectors into Oracle Database 23ai.
embed_model = OCIGenAIEmbeddings(
model_id="cohere.embed-english-v3.0",
service_endpoint="https://inference.generativeai.eu-frankfurt-1.oci.oraclecloud.com",
compartment_id="...",
auth_type="..."
)
本代码片段展示了检索增强生成 (RAG) 管道的下一步:如何利用 OCI 生成式 AI 服务来生成文档块 (Document Chunks) 的嵌入 (Embeddings),为后续存储到向量数据库 (Vector Database) 做准备。
1. 导入所需库
from langchain_community.vectorstores import OracleVS
from langchain_community.embeddings import OCIGenAIEmbeddings
from langchain_community.vectorstores.utils import DistanceStrategy
-
langchain_community.vectorstores.OracleVS: 导入 OracleVS 类。这个类是 LangChain 社区版中用于与 Oracle 向量存储 (Oracle Vector Store) 进行交互的接口。它将用于后续把嵌入写入数据库。
-
langchain_community.embeddings.OCIGenAIEmbeddings: 导入 OCIGenAIEmbeddings 类。这是 LangChain 社区版中用于通过 OCI 生成式 AI 服务 (OCI Generative AI Service) 生成文本嵌入 (Embeddings) 的封装类。
-
langchain_community.vectorstores.utils.DistanceStrategy: 导入 DistanceStrategy 枚举。这通常用于指定在向量数据库 (Vector Database) 中进行相似性搜索时使用的距离计算方法(例如余弦相似度 (Cosine Similarity)、欧几里得距离 (Euclidean Distance) 等)。
2. 使用嵌入模型将块嵌入为向量
# Using an embedding model, embed the chunks as vectors into Oracle Database 23ai.
embed_model = OCIGenAIEmbeddings(
model_id="cohere.embed-english-v3.0",
service_endpoint="[https://inference.generativeai.eu-frankfurt-1.oci.oraclecloud.com](https://inference.generativeai.eu-frankfurt-1.oci.oraclecloud.com)",
compartment_id="...",
auth_type="..."
)
-
实例化 OCIGenAIEmbeddings: 这行代码创建了一个 OCIGenAIEmbeddings 类的实例,这将作为我们的嵌入模型 (Embedding Model)。
-
model_id: "cohere.embed-english-v3.0" 指定了要使用的具体嵌入模型的 ID。这里使用的是 Cohere 提供的英文嵌入模型版本 3.0。
-
service_endpoint: "https://inference.generativeai.eu-frankfurt-1.oci.oraclecloud.com" 指定了 OCI 生成式 AI 服务的推理 API 端点 (Endpoint) URL。这是一个位于“法兰克福-1”(eu-frankfurt-1)区域的生成式 AI 推理服务端点 (Generative AI Inference Service Endpoint)。
-
compartment_id: "..." (此处被省略) 这是一个占位符,需要替换为您的 OCI 租户 (OCI Tenancy) 中用于部署和管理资源的所属区间 ID (Compartment ID)。这是 OCI 资源管理和访问控制的关键。
-
auth_type: "..." (此处被省略) 这是一个占位符,需要替换为 OCI 的认证类型 (Authentication Type)。常见的认证类型包括:
-
api_key:使用 API 密钥进行认证。
-
instance_principal:在 OCI 实例上运行时使用实例主体 (Instance Principal) 进行认证。
-
resource_principal:在 OCI Functions 等无服务器服务中使用的资源主体 (Resource Principal)。
通过上述配置,embed_model 对象现在能够调用 OCI 生成式 AI 服务来处理文本文档 (Documents) 并将其转换为向量表示 (Vector Representations),即嵌入 (Embeddings)。这些嵌入是后续在向量数据库 (Vector Database) 中进行语义搜索 (Semantic Search) 的基础。
RAG 管道之检索阶段
本节详细阐述了检索增强生成 (RAG) 管道的检索 (Retrieval) 阶段。
当用户输入查询时,首先使用相同的嵌入模型 (Embedding Model) 对查询进行编码。
然后,通过向量搜索 (Vector Search) 在数据库中查找与查询嵌入 (Embedding) 相似的文档块 (Document Chunks),并返回最相关的 Top K 结果作为附加上下文 (Context)。
深入探讨了向量搜索中使用的相似性度量 (Similarity Measures)(点积和余弦相似度)以及索引 (Indexes)(如 HNSW 和 IVF)在提高搜索效率方面的作用。
最后,通过一个代码逻辑示例,演示了如何在 LangChain 中设置检索器和 LLM (大型语言模型),并构建一个检索问答链 (RetrievalQA Chain) 来获取结合了检索结果的响应。
1. 检索阶段概述
- 目的: 当用户输入一个希望 LLM (大型语言模型) 回答的查询时,检索阶段 (Retrieval Phase) 的目标是从向量数据库 (Vector Database) 中找到与该查询最相关的文档块 (Document Chunks),并将这些块作为额外上下文 (Additional Context) 提供给 LLM。
2. 查询编码与相似性搜索
- 查询编码 (Query Encoding): 首先,使用与编码文档块 (Document Chunks) 相同的嵌入模型 (Embedding Model) 来对用户查询 (User Query) 进行编码,将其转换为一个查询嵌入 (Query Embedding)(即向量表示 (Vector Representation))。
- 数据库搜索 (Database Search): 接下来,使用这个编码后的查询 (Encoded Query) 在存储了嵌入块 (Embedded Chunks) 的数据库中进行搜索。
- 返回相似块: 搜索的目的是找回与查询高度相似的文档块。这些相似的块将为用户查询提供必要的额外上下文 (Context)。
- Top K 结果: 向量搜索 (Vector Search) 通常会返回多个 (Multiple) 匹配的块 (Chunks),但为了保持上下文 (Context) 的简洁性和相关性,只会返回前 K 个 (Top K) 最相关的结果。
3. 向量搜索中的相似性度量 (Similarity Measures)
向量搜索通过计算查询嵌入 (Query Embedding) 和存储的块嵌入 (Chunk Embeddings) 之间的相似度来找到相关的块 (Chunks)。常用的相似性度量包括:
-
点积 (Dot Product):
- 定义: 点积 (Dot Product),也称为标量积 (Scalar Product),是两个向量 (Vectors) 的乘积,结果是一个标量值。它衡量了一个向量在另一个向量方向上的投影大小 (Magnitude of Projection)。
- 几何意义:
- 点积的值会受到向量的长度(幅度)(Magnitude) 和它们之间夹角 (Angle) 的影响。
- 点积越大,表示两个向量越相似(在方向和大小上都接近)。
- 在 NLP (自然语言处理) 中,更大的幅度可能表示更“丰富”或更“重要”的语义内容。
-
余弦相似度 (Cosine Similarity) / 余弦距离 (Cosine Distance):
- 定义: 余弦相似度 (Cosine Similarity) 衡量的是两个向量 (Vectors) 在多维空间 (Multidimensional Space) 中的方向一致性。它只关注角度 (Angle),而不受向量长度 (Vector Length) 的影响。
- 几何意义:
- 余弦相似度的值范围通常在 -1 到 1 之间。
- 1 表示两个向量方向完全相同(完全相似)。
- 0 表示两个向量正交(不相关)。
- -1 表示两个向量方向完全相反(完全不相似)。
- 余弦距离的值范围通常在 0 到 2 之间。
- 0 表示两个向量方向完全相同(完全相似,距离最小)。
- 2 表示两个向量方向完全相反(完全不相似,距离最大)。
- 在 NLP 中,余弦相似度是衡量文本(词语、句子、文档)语义相似性 (Semantic Similarity) 的常用指标,因为它对文本的长度不敏感,更侧重于内容的“主题”或“方向”一致性。
- 余弦相似度的值范围通常在 -1 到 1 之间。
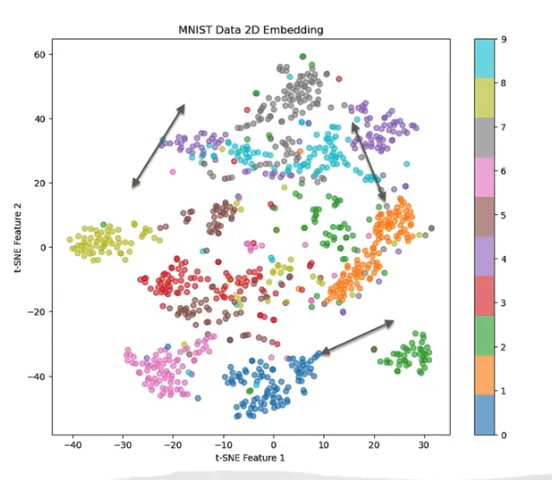
- 图示含义: 图表显示了 MNIST 数据 (手写数字图片) 经过 t-SNE (t-Distributed Stochastic Neighbor Embedding) 算法降维到二维空间后的嵌入 (Embeddings)。
- 数据点聚类:
- 每个点代表一个手写数字图像的嵌入。
- 相同颜色的点代表同一个数字。
- 可以清楚地看到,语义相似 (Semantically Similar) 的数据点(即同一个数字的图像)在二维空间中会聚类 (Cluster) 在一起,形成紧密的簇。
- 相似性直观表示: 这个图直观地展示了:
- 相似的数字嵌入彼此靠近 (Closer By)。
- 不相似的数字嵌入彼此远离 (Further Apart)。
- 这印证了嵌入的核心思想:通过将高维数据映射到低维空间,使得语义相似度 (Semantic Similarity) 可以通过几何距离 (Geometric Distance) 来衡量。箭头可能指向不同的聚类,表示不同类别之间的区分。
4. 索引 (Indexes) 在高效搜索中的作用
- 必要性: 当文档块 (Document Chunks) 的数量很少时,直接比较查询嵌入 (Query Embedding) 与每个块嵌入 (Chunk Embedding) 是可行的。然而,随着块数量的增长,这种方法变得效率低下。
- 索引的作用: 索引 (Indexes) 就像文档的目录 (Table of Contents)。它们是专门为相似性搜索 (Similarity Searches) 设计的数据结构 (Data Structures),能够轻松且高效地找到嵌入 (Embeddings)。
- 索引技术: 各种技术(如聚类 (Clustering)、分区 (Partitioning) 和邻居图 (Neighbor Graph))被用于对嵌入进行分组,从而减少搜索空间 (Reduce the Search Space),提高搜索效率。
- HNSW (Hierarchical Navigable Small-World Graph,分层可导航小世界图):
- 一种内存中 (In-memory) 的邻居图向量索引 (Neighbor Graph Vector Index) 形式。
- 它是用于向量近似相似性搜索 (Vector Approximate Similarity Search) 的非常高效 (Very Efficient) 的索引。
- IVF (Inverted File Flat,倒排文件扁平):
- 一种邻居分区向量索引 (Neighbor Partition Vector Index) 形式。
- 它是一种基于分区 (Partition-based) 的索引,通过使用邻居分区 (Neighbor Partitions) 或簇 (Clusters) 来缩小搜索区域,从而实现搜索效率。
- HNSW (Hierarchical Navigable Small-World Graph,分层可导航小世界图):
5. 生成阶段 (Generation Phase)
- 一旦以相关块 (Relevant Chunks) 的形式检索到上下文 (Retrieved the Context),这些块就会与原始用户查询 (User Query) 一起发送给 LLM (大型语言模型)。
- 最后,LLM 会综合考虑所提供的上下文 (Context) 和用户查询 (User Query),生成一个相关 (Relevant) 且具体 (Specific) 的响应。
6. 检索代码逻辑示例 (使用 LangChain)
from langchain.chains import RetrievalQA
from langchain_community.chat_models.oci_generative_ai import ChatOCIGenAI
from langchain_community.vectorstores.oraclevs import OracleVS
vs = OracleVS(embedding_function=embed_model, client=conn23c, table_name="DEMO_TABLE",
distance_strategy=DistanceStrategy.DOT_PRODUCT)
retv = vs.as_retriever(search_type="similarity", search_kwargs={'k': 3})
llm = ChatOCIGenAI(
model_id="cohere.command-r-16k",
service_endpoint="…",
compartment_id="…",
auth_type="…",
)
chain = RetrievalQA.from_chain_type(llm=llm, retriever=retv, return_source_documents=True)
response = chain.invoke("Tell us which module is most relevant to LLMs and Generative AI")
- 导入必要类: 导入
RetrievalQA(用于构建检索问答链)、ChatOCIGenAI(用于与 OCI 生成式 AI 服务中的聊天模型交互)和OracleVS(用于与 Oracle 向量存储交互)。 - 创建向量存储实例: 使用
OracleVS类创建向量存储 (Vector Store) 实例,传入嵌入模型 (Embedding Model)、数据库连接、表名和距离策略 (Distance Strategy)。 - 创建检索器 (Retriever): 基于向量存储创建一个检索器 (Retriever)。
- 设置
search_type='similarity',表示进行相似性搜索。 - 设置
search_kwargs={'k': 3},表示只返回前 3 个 (Top 3) 最相关的结果。
- 设置
- 创建 LLM 实例: 使用
ChatOCIGenAI创建 LLM 实例,传入模型 ID (Model ID)、服务断点 (Service Endpoint)、所属区间 ID (Compartment ID) 和认证类型 (Auth Type) 等所需参数。 - 创建链 (Chain): 使用
RetrievalQA类创建问答链 (QA Chain)。- 传入之前创建的 LLM 实例和检索器 (Retriever)。
- 设置
return_source_documents=True,这将确保最终响应中包含引用的源文档 (Source Documents),增加可解释性 (Interpretability) 和可信度 (Credibility)。
- 调用链获取响应: 最后,使用用户的问题调用 (Invoke) 创建的链 (Chain),从而获得包含检索到的上下文和 LLM 生成的答案的响应。
这个过程有效地将外部知识集成到 LLM 的响应生成中,使其能够提供更准确、更具信息量且与用户查询高度相关的答案。
RAG 在聊天机器人中的应用及内存机制
本节探讨了检索增强生成 (RAG) 技术在构建聊天机器人 (Chatbots) 中的应用,特别强调了内存 (Memory) 机制在维护对话上下文 (Context) 中的关键作用。
它指出,除了从外部语料库检索 (Retrieval) 相关文档外,聊天历史(即先前的问答对)也能作为重要的附加上下文提供给大型语言模型 (LLM),从而使对话更具连贯性。
LangChain 等框架提供了丰富的内存 (Memory) 和链 (Chain) 类,以支持这种会话式聊天机器人 (Conversational Chatbots) 的实现。
1. RAG 在聊天机器人中的应用背景
- RAG 的核心价值回顾: 我们已经了解 RAG (Retrieval Augmented Generation) 如何通过检索 (Retrieving) 相关文档并将它们作为额外上下文 (Additional Context) 传递给 LLM (大型语言模型),从而提高查询响应的相关性 (Relevance) 和特异性 (Specificity)。
- 聊天机器人中的 RAG: RAG 技术常被用于构建聊天机器人 (Chatbots)。聊天是一个由一系列问题和答案组成的会话 (Conversation) 过程:用户提问,LLM 回答,然后用户可能提出下一个跟进问题,如此循环。
- 基于文本语料库的 RAG: 在聊天机器人中,RAG 用于通过利用提供的文本语料库 (Text Corpus) 中的相关信息来回答问题。
2. 聊天机器人中的上下文维护:内存 (Memory) 的作用
- 聊天历史作为上下文: 在聊天场景中,除了从外部文档检索 (Retrieval) 到的信息外,先前的问答 (Prior Questions and Answers) 也可以作为下一个问题 (Next Question) 的额外上下文 (Additional Context)。
- 示例: 如果用户先问“告诉我关于拉斯维加斯”,接着问“告诉我它全年典型的气温”,第二个问题中的“它”显然指的是“拉斯维加斯”。为了正确理解并回答第二个问题,LLM 需要知道先前的对话内容。
- 内存的概念: 为了维护已提问问题和已给出答案的列表,引入了内存 (Memory) 的概念。
- 内存内容更新: 每当用户提出新问题并生成答案时,内存的内容都会相应地更新。
- 内存传递给 LLM: 内存中的内容(即对话历史 (Conversation History))作为附加上下文 (Additional Context) 传递给 LLM。
- LLM 综合考量: LLM 在回答下一个问题时,会同时考虑检索到的文档 (Retrieved Documents) 和会话历史 (Conversation History),从而生成更准确和连贯的响应。
3. LangChain 对话式机器人的支持
- LangChain 的支持: LangChain 框架为实现会话式聊天机器人 (Conversational Chatbots) 提供了多种内存 (Memory) 和链 (Chain) 类。
- 增强开发: 这些类极大地简化了开发人员在 LLM 应用程序中管理和利用对话上下文的工作,使得构建复杂的多轮对话系统成为可能。
总结:
RAG 技术结合内存 (Memory) 机制,极大地增强了聊天机器人 (Chatbots) 的能力,使其不仅能够访问外部知识,还能保持对话的上下文连贯性 (Contextual Coherence)。LangChain 等框架的出现,进一步简化了这些复杂功能的实现,推动了更智能、更自然的对话式 AI 应用的发展。
Chatbot using Generative AI Agent service
Oracle 生成式 AI 代理
本节详细介绍了 Oracle 生成式 AI 代理 (Oracle Generative AI Agents) 服务,这是一种全托管服务 (Fully Managed Service),它结合了大型语言模型 (LLM) 的能力和智能检索系统 (Intelligent Retrieval System),旨在通过搜索知识库 (Knowledge Base) 生成上下文相关 (Contextually Relevant) 的响应并执行动作。
本节阐述了代理的整体架构,包括接口、记忆、工具和 LLM 的核心能力,并详细介绍了数据源 (Data Source)、数据存储 (Data Store) 和知识库 (Knowledge Base) 的层次结构。
此外,还提供了使用 OCI 对象存储 (Object Storage) 和 Oracle Database 23ai 作为数据源的指南 (Guidelines),并介绍了会话 (Session)、代理端点 (Agent Endpoint)、跟踪 (Trace)、引用 (Citation) 和内容审核 (Content Moderation) 等关键概念,最后概括了创建和使用代理的工作流程。
1. Oracle 生成式 AI 代理概述
- 定义: Oracle 生成式 AI 代理 (Generative AI Agents) 是一种全托管服务 (Fully Managed Service),它将大型语言模型 (LLM) 的强大能力与智能检索系统 (Intelligent Retrieval System) 相结合。
- 目标: 旨在通过搜索用户的知识库 (Knowledge Base) 来创建上下文相关 (Contextually Relevant) 的答案,并根据查询执行相应的动作。
- 示例: 当用户要求代理“预订飞往拉斯维加斯的航班以及希尔顿酒店的房间”时,代理会理解查询、确定下一步行动、从数据存储中检索数据,并最终给出响应或执行操作(例如“您的行程已预订”)。
- 开箱即用 (Out-of-the-Box): 代理是 LLM (大型语言模型) 应用程序的打包、验证和开箱即用 (Ready to Use Out of the Box) 的应用。
- 数据接入方式: 支持多种数据接入方式,用户及其客户可以通过聊天界面 (Chat Interface) 或 API (应用程序编程接口) 与数据进行交互。
2. 代理的整体架构
代理的运行流程是一个复杂的系统,包含多个协同工作的组件:
-
界面 (Interface):
- 作用: 用户与 AI 代理交互的入口点。
- 形式: 可以是聊天机器人、网页应用、语音接口或任何接收用户查询或命令的应用程序。
-
输入到 LLM 的组件:
- 短/长期记忆 (Short/Long Term Memory):
- 作用: 提供过去交互的上下文,确保对话的连贯性和相关性。
- 工具 (Tools):
- 作用: 允许集成不同的外部工具 (External Tools),如 API、数据库 (Databases) 或第三方系统 (Third-party Systems),以增强模型的能力。
- 提示 (Prompt):
- 作用: 包含用户提供的具体查询或任务,指导 AI 如何生成响应。
- 短/长期记忆 (Short/Long Term Memory):
-
大型语言模型 (LLM) 的核心操作: LLM 是系统的核心,执行以下四个关键操作:
- 推理 (Reasoning): 分析输入以生成逻辑且连贯的响应。
- 行动 (Acting): 根据任务确定要执行的动作,例如查询数据库或调用不同的 API。
- 角色 (Persona): 保持与品牌或用例一致的语气、风格和行为。
- 规划 (Planning): 战略性地组织响应或动作,特别是在多步骤工作流程中。
-
外部知识库访问:
- 作用: LLM 可以访问外部知识库 (External Knowledge Bases),如数据库或文档存储库,以利用准确和最新的信息来丰富其响应。
- RAG (检索增强生成): 代理可以通过 RAG 机制,超越其内部训练数据来获取信息。
-
响应生成与反馈循环:
- 生成响应: 基于所有已处理的输入、推理和集成知识,LLM 生成一个针对用户查询和上下文定制的响应。
- 反馈循环: AI 代理生成的输出可以反馈到其短期记忆 (Short Term Memory) 中,从而在后续交互中提供改进的响应,形成一个持续学习和优化的反馈循环 (Feedback Loop)。
-
整体设计: Oracle 生成式 AI 代理旨在实现可伸缩性 (Scalability)、适应性 (Adaptability) 和企业应用程序 (Enterprise Applications) 中的效率 (Efficiency),能够自主执行复杂任务、模拟思维链 (Chain of Thought) 过程、自动化各种用例并利用现有数据完成动作或提供响应。
3. 代理的核心概念
-
生成式 AI 模型 (Generative AI Model):
- 核心: OCI 生成式代理的核心是经过大量数据集训练的大型语言模型 (LLM),能够生成类人文本。
- 功能: 处理新输入以生成连贯且上下文适当的响应,实现自然语言理解 (Natural Language Understanding) 和生成 (Generation)。
-
代理 (Agent) 本身:
- 定义: 这是一个建立在 LLM 之上的自治系统 (Autonomous System),它能够理解和生成文本,同时促进自然语言交互 (Natural Language Interactions)。
- RAG 代理: OCI 支持RAG 代理 (RAG Agents),它们连接到数据源 (Data Sources),检索相关信息,并用这些数据增强模型响应,确保输出更准确和相关。
- 可回答性 (Answerability): 模型能够为不同的用户查询生成相关响应。
- 有依据性 (Groundedness): 模型生成的响应可以追踪到不同的数据源 (Data Sources),确保信息的可靠性。
-
数据访问层次结构: 为了有效运作,代理通过结构化层次访问数据:
- 数据存储 (Data Store): 数据实际存放的存储库 (Repository),例如对象存储桶 (Object Storage Buckets) 或数据库 (Databases)。
- 数据源 (Data Source): 提供到数据存储的连接详细信息 (Connection Details),使代理能够访问和检索数据。
- 知识库 (Knowledge Base): 向量存储系统 (Vector Storage System),它从数据源摄取数据,并将其组织起来,以便代理进行高效检索和使用。这种结构确保代理能够无缝访问和利用必要的信息来生成知情响应 (Informed Responses)。
4. Oracle 生成式 AI 代理的数据选项
Oracle 提供了多种数据选项,使信息可供生成式 AI 代理访问:
-
对象存储数据 (Object Storage Data):
- 方式: 可以直接将数据文件上传到 OCI 对象存储 (Object Storage),服务将自动摄取这些数据。
- 特性: 这是服务托管选项 (Service Managed Option),即由服务负责摄取 (Ingestion) 部分。
-
OpenSearch 数据 (OpenSearch Data):
- 方式: 可以从 OCI Search with OpenSearch 导入已摄取 (Ingested) 和索引 (Indexed) 的数据供代理使用。
-
Oracle Database 向量存储 (Oracle Database Vector Store):
- 方式: 可以将Oracle Database 23ai 或 Autonomous Database 23ai 中的向量嵌入 (Vector Embeddings) 带入生成式 AI 代理。
- 本课程将主要讨论对象存储和 Oracle Database 23ai 选项。
- 数据摄取 (Data Ingestion): 这是从源文档中提取数据,将其转换为适合分析的结构化格式,并存储在知识库 (Knowledge Base) 中的过程。这一步对于准备原始数据至关重要,以便代理在交互过程中高效访问和利用。
5. 更多代理相关概念
-
会话 (Session):
- 定义: 表示由用户发起的交互式对话 (Interactive Conversation)。
- 作用: 在整个交流过程中保持上下文 (Context),以确保响应的连贯性和相关性。
-
代理端点 (Agent Endpoint):
- 定义: 一个特定的访问点 (Access Point),使代理能够与外部系统 (External Systems) 或服务 (Services) 进行通信。
- 作用: 促进数据交换,允许代理根据需要检索或发送信息以有效执行其功能。
-
跟踪 (Trace):
- 定义: 跟踪并显示聊天对话 (Chat Conversation) 的历史,包括用户提示 (User Prompts) 和代理的响应 (Agent's Responses)。
- 作用: 对于监控交互、理解决策过程和确保代理操作的透明度非常有价值。
-
引用 (Citation):
- 定义: 指代理响应中使用的信息来源 (Source of Information)。
- RAG 代理特性: RAG 代理为每个响应提供引用,包括标题、外部路径、文档 ID 和页码等详细信息。
- 作用: 确保用户可以将响应追溯到其原始来源,从而增强信任和可追溯性 (Accountability)。
-
内容审核 (Content Moderation):
- 定义: 一项旨在检测和过滤掉用户提示 (User Prompts) 和生成响应 (Generated Responses) 中有害内容 (Harmful Content) 的功能。
- 关注点: 识别和减轻各种类型的危害,包括仇恨和骚扰、自残、意识形态危害和剥削,确保交互安全和尊重。
- 灵活性: 审核可以应用于仅用户提示、仅生成响应或两者兼有。
6. 对象存储作为数据源的指南
- 文件上传: 将数据文件作为文件上传到 OCI 对象存储桶 (Object Storage Bucket)。
- 单桶限制: 每个数据源 (Data Source) 只能与一个桶关联 (Associated with a Single Bucket)。
- 支持格式: 服务仅支持 PDF 和文本文件格式 (Text File Formats)。
- 文件大小限制: 每个文件不得超过 100 MB。
- PDF 内容要求: PDF 文件可以包含图像、图表和参考表,但这些元素的总大小不得超过 8 MB。
- 图表要求: 图表必须是二维 (Two Dimensional) 且具有标记轴 (Labeled Axes)。模型无需额外准备即可解释和回答关于这些图表的问题。
- 参考表支持: 可以使用具有多行多列的参考表 (Reference Tables),代理可以有效读取和解释此类表格。
- 超链接提取: PDF 文档中存在的所有超链接 (Hyperlinks) 都将被提取并显示为聊天响应中的可点击链接 (Clickable Links)。
- 预设数据源: 如果数据尚未准备好,可以为数据源创建一个空文件夹,稍后填充。这允许提前设置数据源 (Data Source),并在数据可用时再摄取 (Ingest)。
7. Oracle 数据库作为数据源的指南
- 数据库管理: 生成式 AI 代理****不管理数据库 (Does Not Manage the Database)。您必须设置现有的数据库,以便生成式 AI 代理能够连接。
- 表结构: 需要创建 Oracle Database 23ai 表,包含
DOCID、body和vector等字段。- 可选字段: 还有
CHUNKID、URL、title和page_numbers等可选字段。 body: 存储文档块 (Document Chunks) 的原始文本内容。vector(或text_vec): 存储使用嵌入模型 (Embedding Model) 从body生成的向量嵌入 (Vector Embeddings)。
- 可选字段: 还有
- 数据库函数设置: 需要设置一个数据库函数,能够从每个查询返回向量搜索结果 (Vector Search Results)。
- 函数定义: 函数是一个子程序,可以接受参数并返回一个值。
- 参数: 示例中函数
retrieval_func_ai接受p_query(用户查询)和top_k(返回结果数量)作为参数。 - 重要要求:
- 用于函数查询字段的嵌入模型 (Embedding Model) 必须与将数据库表
body内容转换为向量嵌入 (Vector Embeddings) 的嵌入模型相匹配(例如,查询中使用的 Cohere embed multilingual v3 必须与生成text_vec列的模型匹配)。 - 函数的返回字段必须与表的必需字段(
DOCID、body和score)对齐。如果字段名称不同,可以使用别名 (Aliases)。 - 函数内部查询会访问包含向量嵌入 (Vector Embeddings) 的表,计算查询向量和文档嵌入之间的向量距离 (Vector Distance)(使用余弦相似度 (Cosine Similarity) 或欧几里得距离 (Euclidean Distance))。
- 查询会检索按相似度得分降序排序 (Descending Order) 的 Top K 行,确保返回最相关的结果。
- 函数最终返回一个带有
DOCID、body和score字段的SYS_REFCURSOR。
- 用于函数查询字段的嵌入模型 (Embedding Model) 必须与将数据库表
8. 创建代理的整体工作流程 (Concepts Review)
- 创建知识库 (Create Knowledge Base):
- 提供名称、所属区间和其他必要信息。
- 选择数据存储类型 (Data Store Type)(例如对象存储或 Oracle AI 向量搜索)。
- 可以启用混合搜索 (Hybrid Search)(词法搜索与语义搜索的组合)。
- 指定数据源 (Data Source)(例如对象存储桶或 Oracle 23ai 数据库连接)。
- 对象存储支持多个对象(文件),如文本文件和 PDF 文件。
- 创建后,可以选择立即启动摄取任务 (Ingestion Job) 或稍后手动创建。
- 创建代理 (Create Agent):
- 提供必要信息、欢迎消息 (Welcome Message) 和 RAG 生成指令 (RAG Generation Instructions)(如果适用)。
- 选择之前创建的知识库 (Knowledge Base)(对象存储或 Oracle 23ai)。
- 创建代理端点 (Create Agent Endpoint):
- 为代理创建一个访问点 (Access Point),使其能够与外部系统或服务通信。
- 在此阶段,可以配置会话 (Session)、内容审核 (Content Moderation)、跟踪 (Trace) 和引用 (Citation) 等功能。
- 聊天交互 (Chat Interaction):
- 使用创建的代理端点 (Agent Endpoint) 与代理进行实际聊天交互。
- 在聊天界面中可以看到引用 (Citations)(提供答案的来源)和跟踪 (Trace)(显示查询和响应历史)。
9. 默认资源限制
- 在使用服务时,请注意各种资源的默认限制 (Default Limits)。
- 如果需要更高的限制,可以随时提交请求以进行更改 (Raise a Request to Change)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号