
预祝 1024!X2SeaTunnel:一场 AI Coding 与数据平台结合的深度实践
导语:如何将千万计的数据集成作业(比如 DataX 等)迁移到 Apache SeaTunnel 是一个比较繁琐的任务。
为了解决这一难题,X2SeaTunnel 应运而生。它是一个通用配置转换工具,用于将多种数据集成工具(如 DataX、Sqoop 等)的配置文件转换为 SeaTunnel 格式,帮助用户平滑迁移到 SeaTunnel 平台。在本周的 Apache SeaTunnel Meetup 上,来自天翼云的大数据专家 王小刚 为我们详细解分享了 X2SeaTunnel 的设计与实现思路。
同时,本工具也是对 AI Coding,Vibe Coding 的一次有意义的实践,所以在本文中作者也分享了使用 AI 在短时间内完成从产品、架构、代码以及落地的实践感悟。
目前,X2SeaTunnel 还处于第一个版本阶段,希望有更多道友能够一起共建共赢。
作者简介

王小刚,天翼云大数据技术专家,学习大数据已有十年了,有丰富的解决方案到产品、研发、落地交付的全流程经验,对数据平台建设的挑战与痛点有着惨痛的经历。当前主要负责数据集成产品及重点客户湖仓迁移项目的落地工作。
热爱开源,曾为 Spark、Linkis 等项目做过贡献,现任 ASF Member。最近比较关注 Apache SeaTunnel、FlinkCDC 等数据集成社区,并长期关注 AI Agent 技术,以及与 Data 的结合。希望通过本次分享,结合理论与实践经验,为大家带来一些参考。
天翼云数据集成场景简介
面向客户场景,我们基于开源的 Apache SeaTunnel+FlinkCDC,底层统一 Flink 引擎,构建数据集成产品,支撑海量数据同步到湖仓数据平台。我们的数据源主要包括各类数据库、数据仓库、数据湖等,以及Kafka、HTTP 等数据,比较典型的数据目标是 Hive、Doris、Iceberg 等。
得益于开源社区的演进,我们得以在比较高的 ROI 的情况下,具备了数据集成的核心能力,所以我们将研发重点放在提升数据集成的可靠性和易用性上。
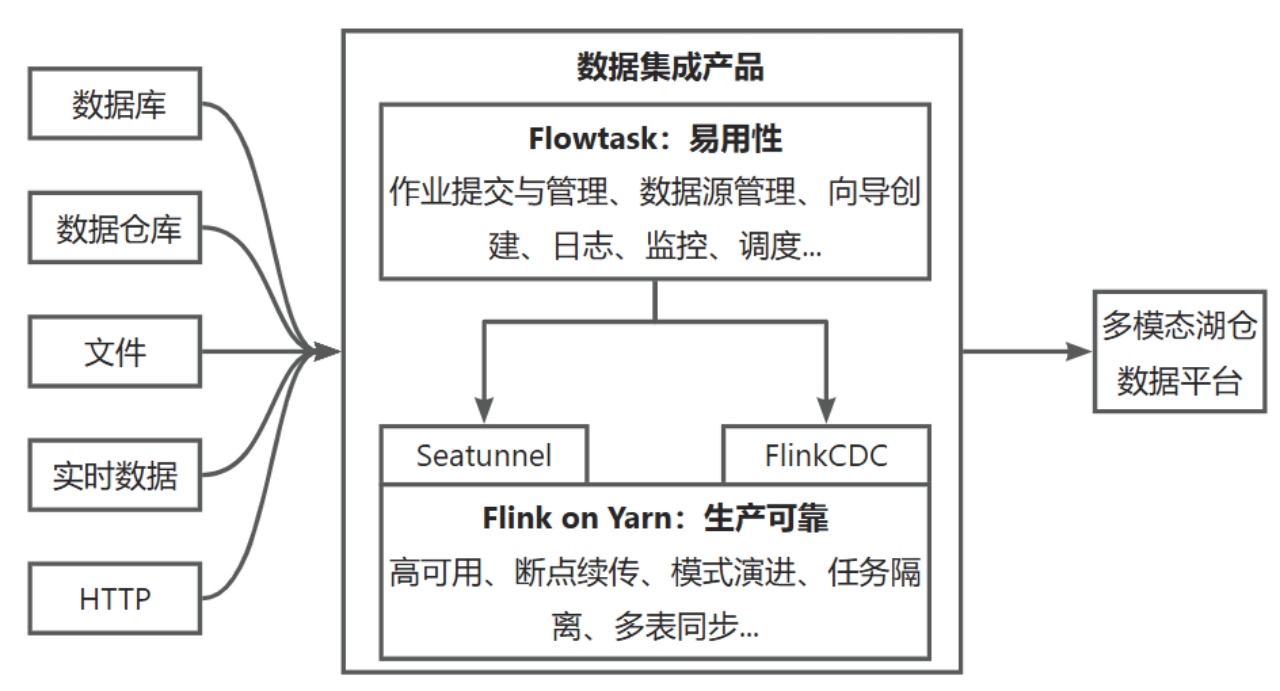
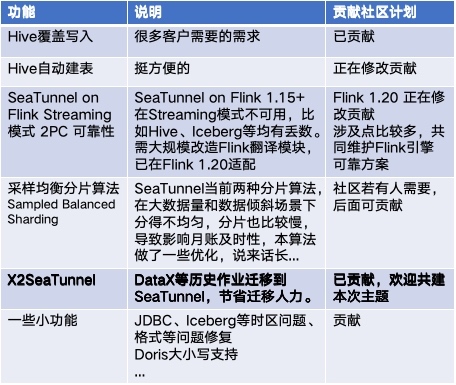
同时,我们也会将在场景下发现的 bug、设计的 feature 等逐步反馈给开源社区,共建共赢。比如 Hive 覆盖写入,Hive 自动建表等客户常见需求,Flink 1.20 支持,X2SeaTunnel,SBS 数据分片算法等新特性,已经或计划贡献到 Apache SeaTunnel 社区。
我们在 Flink 引擎层面会有比较多的场景,最近也在解决 SeaTunnel on Flink Streaming 模式下 2PC 的可靠性,包括丢数、断点续传等问题。
X2SeaTunnel的设计、开发与落地
进入正题,我趁此机会总结一下 X2SeaTunnel 的设计、开发与落地。
X2SeaTunnel场景与需求分析
AI 时代,尤其到了 Agentic 时代,代码变得廉价,思考这个功能值不值得做,变得更加重要。在 X2SeaTunnel 开发的过程中,我把很大的精力放在思考这些问题上。
这是一个真实存在的场景需求吗?
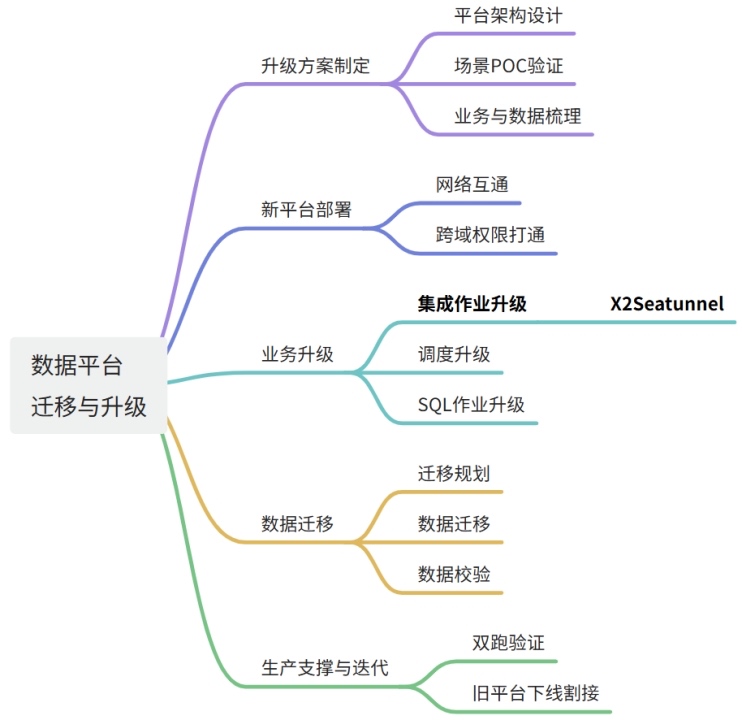

如上思维导图,X2SeaTunnel 的场景源于数据平台的迁移与升级,数据平台迁移升级到湖仓一体平台往往会经历很多步骤,有很多细节。
其中数据集成作业的升级是让人很纠结的:许多客户很早就基于 DataX、Sqoop 等开源组件,构建了数据集成平台,当要迁移到湖仓平台中时,成千上万的数据集成的作业往往让人头痛,很容易成为项目推进的 “拦路虎”。不像 SQL 有很多类似的开源转换工具,DataX、Sqoop 等迁移到数据湖平台时,每家的集成作业都不一样,所以这些任务的处理是一个人力密集型的工作。从这个场景看,如果真有一个集成作业升级工具,将会很有价值。
这个需求的目标用户是谁?
当前的我们目标客户是开发或交付工程师。所以没必要考虑 UI,好用的命令行就是最合适的。
这个需求可以做到标准化吗?
这个需求在社区中呼声也比较高,已经有一些人有做过相关开发,但一直都没有贡献出来,主要原因还是标准化比较麻烦,因为虽然每家的需求是可以快速定制开发的,但比较难以做到通用。比如 DataX 的 MySQL Source 写到 Hive sink,就会有很多种场景和写法,不同场景的转换规则,是难以复用的。
所以我们不能追求完美的一次成功转换,就像不能完美要求 AI 可以一次性把代码全写对一样,而是允许通过“人+工具”结合的形式,支持二次改造,模版系统是比较重要的。
这个需求是否适合开源共建?
由于 Apache SeaTunnel 的 Source 和 Sink 非常多,单个公司的需求不尽相同,无法覆盖。我们如果能在共同的约定下,共建共赢,就会让 X2SeaTunnel 这个小工具越来越好用;
这个适合 AI 共建吗?
X2SeaTunnel 相对比较解耦,对生产不会有太大影响,并且可以很快验证效果,比较适合 AI Coding。所以我一开始从架构设计,到代码开发再到落地交付,都是 AI 参与的,代码几乎全是 AI Coding的。(记录时间非常重要,实现代码的时候,是 2025 年 6 月,当下 AI 的发展是每个月一变,到现在 2025 年 10 月,AI Agent 模式已经可以覆盖更加底层,更加复杂的需求了。)
经过对上述问题的思考,以及与AI 进行讨论,我决定认真用 AI Coding 实现 X2SeaTunnel 并开源共建。
X2SeaTunnel工具产品设计思路
即使是小工具,也有产品设计。通过明确边界和简化流程,可以比较好地实现 ROI 和标准化的平衡。
如上图,我们工具的核心理念如下:
- 简单轻量:保持工具轻量高效,专注于配置文件格式转换
- 易用性:提供多种使用方式,提供SDK,提供命令行方式,支持单脚本和批量,满足不同场景需求
- 统一框架:构建一个通用框架,支持多种数据集成工具的配置转换
- 可扩展性:采用插件式设计,新增数据类型转换只需修改配置文件,无需编译代码
X2SeaTunnel架构设计思路

整体流程
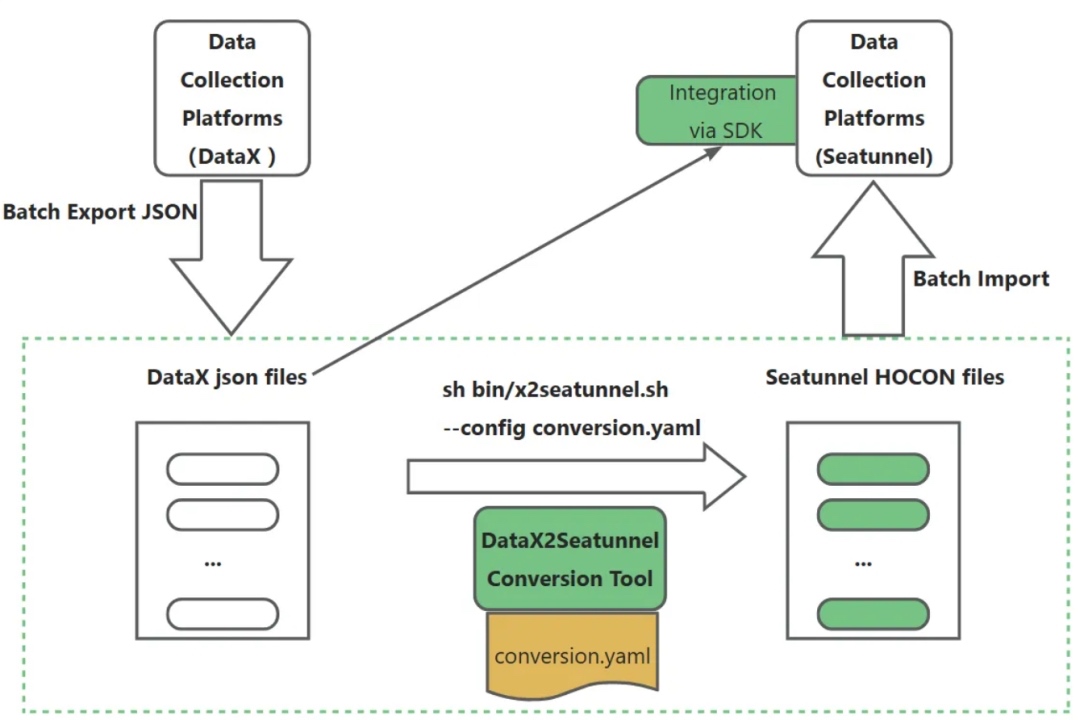
如上图,整体逻辑包含如下几步:
-
脚本调用与工具触发
执行sh bin/X2SeaTunnel.sh --config conversion.yaml,调用 X2SeaTunnel jar包工具,依托conversion.yaml配置(可选)或命令行参数,启动数据转换工具流程 。 -
Jar 包核心初始化
Jar 包运行时,根据 DataX(或sqoop等)的配置文件,以及相关参数,推断待转换的 SeaTunnel Connector 类型,明确转换适配的组件方向,为后续字段匹配、文件转换奠定基础。 -
规则匹配与字段填充阶段
遍历 Connector,借助映射规则库,从 DataX 的 json 文件中提取并填充对应字段值,同时输出字段、Connector 的匹配情况,明确转换过程中各元素的适配状态。 -
转换输出阶段
4.1 配置文件转换
填充模板,生成SeaTunnel 适用的 HOCON/JSON 文件,输出到指定目录;4.2 输出转换报告
遍历源配置,生成转换报告(convert report),记录转换详情与匹配结果;供人工检查和确认,保障转换质量。 -
规则迭代阶段
基于实际转换场景,可持续完善映射规则库,覆盖更多数据转换需求,优化 X2SeaTunnel 工具的适配能力,让流程在多样场景下更精准、高效。待规则引擎逐步迭代稳定后,后续新增转换规则,只需要修改映射规则库,即可快速添加新类型数据源的转换。
通过总结的prompt,可以利用AI大模型,快速生成映射规则。
整个流程通过规则驱动、人工校验,助力数据同步任务向 Apache SeaTunnel 迁移,支撑工具功能落地与迭代 。
关键问题探讨
在设计的过程中,我与 AI 以及社区,关于一些问题有一些探讨,简单列举如下:

1. 使用 Python 还是 Java 实现?
我本来是想着用 Python 快速实现,代码量会少很多,但是后面通过跟社区沟通,考虑到后续可能会作为 SDK 的方式被引用,因此目前实现的是 Java 版本。这样,Jar 包也比较好做分发。
2. AI 能否取代 X2SeaTunnel,或能否考虑直接用AI 实现?
比如通过一句话把源 DataX 的 json 文件交给 LLM,让大模型直接实现转换。关于这个问题,我认为即使 AI 越来越强,这个工具也依然有开发的价值,原因如下:
- AI 依旧存在幻觉问题,即使给它充足的上下文,它给出的转换结果也是有极大可能似是而非的;
- 调用 AI 转换成本比较高;
- 批量转换场景下,AI 难以保证一致性。
当然,AI 在其中依旧非常有价值,X2SeaTunnel 本身就是 AI 设计和开发的,后面可以基于 AI+prompt,根据自己的场景,快速生成模版。
3. 以拉取式为核心的配置转换的实现思路
这是一个比较细节的方案选择,可能的实现方式有很多种,主要有以下三种实现方式:
- 对象映射路线:强类型,通过对象模型转换,编码为主
- 声明映射逻辑(推送式):遍历源配置,映射到目标,配置为主
- 取用逻辑(拉取式):遍历目标需求,从源获取,模板为主
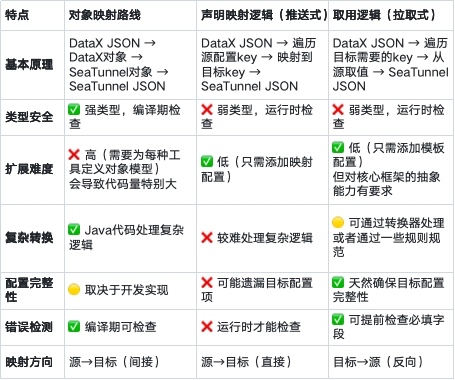
作为一个面向对象的程序员,我的第一反应是把 DataX 的 json 转成中间对象,然后映射成 SeaTunnel 的对象。就像做 SQL 引擎之间的转换的时候,可以考虑用抽象语法树的方式来做。但是想了一下后发现不太对劲,太复杂了,没必要。
另外一个思路,是用推或拉的方式转换。
这两种方式看似相似(都用映射引擎),但方向完全相反:
- 推送式:从源出发,"我有什么给你什么",可能遗漏目标字段
- 拉取式:从目标出发,"我需要什么从你那拿什么",确保目标完整
最终我选择采用以"拉取式映射"为核心,辅以少量对象映射处理复杂逻辑的混合方案。这种方式既确保了目标配置的完整性,又保持了良好的扩展性和维护性,同时能够应对复杂的转换场景。如果源端有遗漏,就可以通过转换报告展示结果。
4. 如何满足不同用户各自特殊的转换需求?
通过模版系统+自定义配置+转换报告,则可以比较好地实现各类转换需求,在我们的场景中,用户基本上可以自行很快实现各自的转换需求。
- 模版系统设计理念
由于X2SeaTunnel的转换需求是非常灵活的,如果把规则写死在代码中,将会极大损失灵活性,导致不好适应各自的需求,因此模版系统是很重要的。
模版系统应该使用比较通用的语法,一开始选择的是SeaTunnel的HOCON语法,后面为了更多的表达力,选择了兼容Jinja2 风格的模板语法,具体见文档。
- 自定义配置模版
在我们客户的实践中,大部分场景使用的是自定义配置模版。通过自定义模版,可以实现各类特殊场景需求。
- 转换报告
转换报告作为一种“兜底”策略,用于检查每次转换是否正确,是非常有价值的。
- 过滤器
我们提供一些过滤器,比如join,replace,regex_extract等,配合模版,可以实现大部分的复杂场景。
X2SeaTunnel快速使用与演示
具体文档见 https://github.com/apache/seatunnel-tools/blob/main/X2SeaTunnel/README_zh.md
按照官网文档一句一句执行,就可以了,这几个样例里列举了核心用法,非常简单就能上手了。
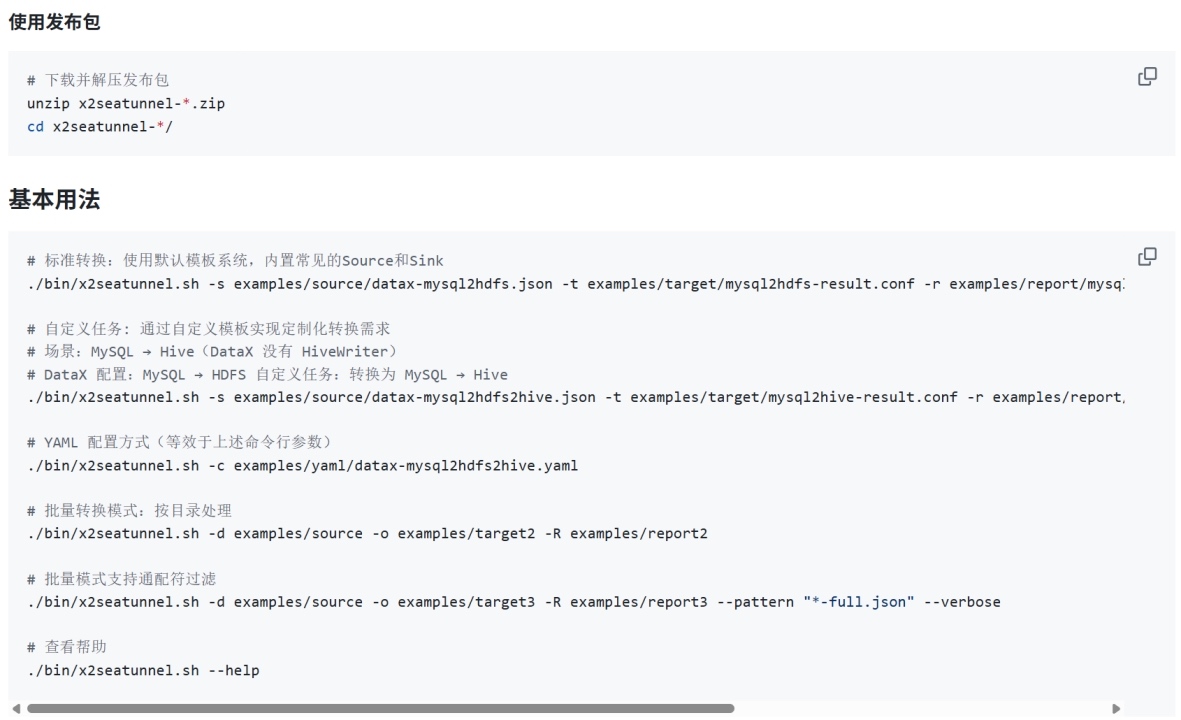
下面是功能特性与目录结构,一目了然,可以看到,文档都是 AI 主笔的。

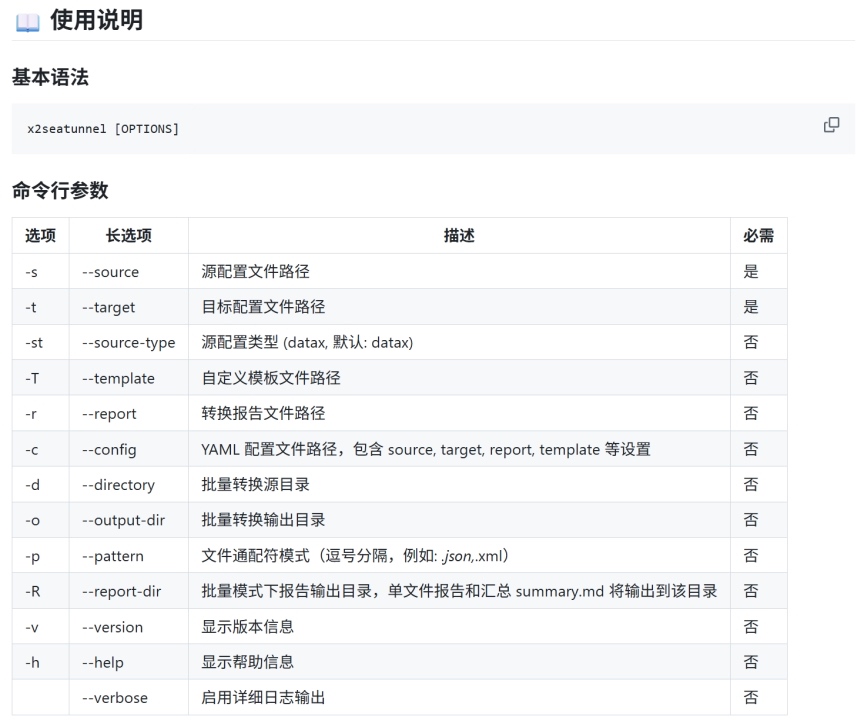
下面着重说明一下模版系统,X2SeaTunnel 采用基于 DSL (Domain Specific Language) 的模板系统,通过配置驱动的方式实现不同数据源和目标的快速适配。核心优势:
- 配置驱动:所有转换逻辑都通过 YAML 配置文件定义,无需修改 Java 代码
- 易于扩展:新增数据源类型只需添加模板文件和映射配置
- 统一语法:使用 Jinja2 风格的模板语法,易于理解和维护
- 智能映射:通过转换器(transformer)实现复杂的参数映射逻辑
![]()

转换报告
转换完成后,查看生成的 Markdown 报告文件,包含:
- 基本信息: 转换时间、源/目标文件路径、连接器类型、转换状态等
- 转换统计: 直接映射、智能转换、默认值使用、未映射字段的数量和百分比
- 详细字段映射关系: 每个字段的源值、目标值、使用的过滤器等
- 默认值使用情况: 列出所有使用默认值的字段
- 未映射字段: 显示DataX中存在但未转换的字段
- 可能的错误和警告信息: 转换过程中的问题提示
如果是批量转换,则会在批量生成转换报告的文件夹下,生成批量汇总报告,包含:
- 转换概览: 总体统计信息、成功率、耗时等
- 成功转换列表: 所有成功转换的文件清单
- 失败转换列表: 失败的文件及错误信息(如有)
AI Coding实践与感悟
AI4Me:我的大模型探索历程

我一直热衷于探索 AI,追逐每一次技术浪潮的前沿。
- 从 Midjourney 爆火开始:第一时间购买账号,沉浸在 AI 绘画的世界中;
- ChatGPT时代:从 3.5 到 4.0,半年多时间里是我工作与思考的主力,中间有段时间不用了,GPT-5 出来后又主力接管我的工作流;
- Claude系:第一时间注册使用,长期在 Coding 场景中作为主力;
- 国产力量:持续关注并实际使用 ChatGLM、Kimi、MiniCPM、千问等多款模型;
- 本地实验:购买 GPU 主机,在本地玩转小模型;
- RAG 与 Agent 探索:几乎调研了所有开源 Agent 框架,深度使用 LangChain,灵感层出不穷(如 Delta2 构想);
- DeepSeek V2:国产之光,充值支持;V2.5 成为我主要的 Claude 替补;
- AI Coding 与排障实践:尝试 auto_coder、通义、Cursor、G-Copilot、Aug、CodeX 等多种工具;
- AI 产品体验:从 Minmax 小海螺(激动)到豆包、元宝、通义,几乎全线试用。
有一段时间,也就是 DeepSeek V3 R1 发布、尚未出圈之际,我陷入了狂热,产品、架构、画原型、甚至算命——尝试用 AI 去完成所有能想到的事情。
后面,而当 DeepSeek 真正出圈爆火时,我反而陷入迷茫。信息的爆炸、输入的泛滥,让我感到失焦与压抑。
后面,我开始学会做减法。
放下追逐,向内探索,回到初心。
不再追着 AI 跑,而是让 AI 解决我当下的问题,活在当下。
这才是人与AI的正确距离。
X2SeaTunnel Vibe Coding感悟
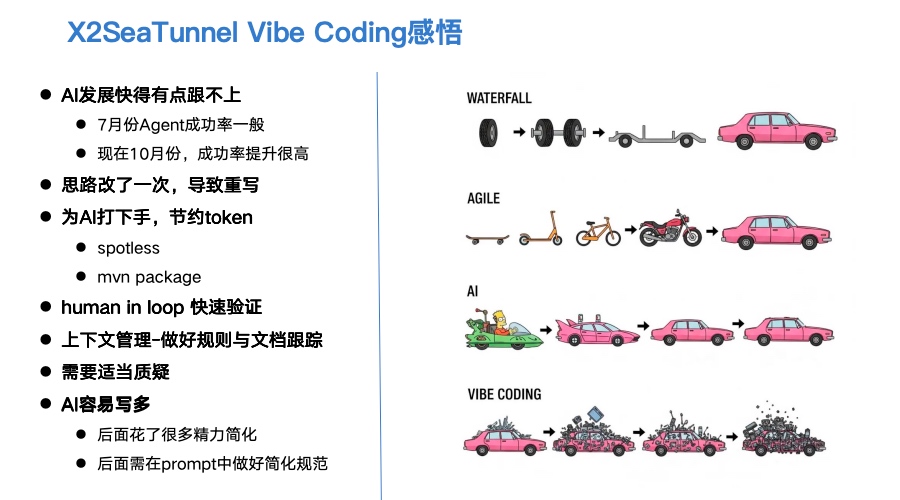
- AI发展快得有点跟不上
写这篇文章的时间是 2025 年 10 月 21 日。按 AI 的发展速度,再过两个月,这些想法可能就过时了。
过去几个月,我一直在尝试各种 AI 编程工具。这次在开发 X2SeaTunnel 时,主要用了 Augment 和 GitHub Copilot。6 月时,AI的 Agent 模式刚起步——它解决复杂问题的成功率并不高。而到了 10 月,无论是写新代码还是处理旧问题,AI 的成功率都提升明显。
- 为AI打下手,节约token
AI 不只是帮我们提效,更让我们变得更强。我的角色逐渐转变为选择方向、决策路径的人。
虽然 AI 很听话,但仍需要人来“保护”它——要从现在开始养成节约 token 的习惯。一些简单任务别浪费 AI 的计算力,比如 spotless 格式化问题、mvn package 编译问题,这些我自己来做更快。
Agent 虽然能完成,但会浪费时间和 token。所以我通常会明确告诉 AI,把这些基础操作交给我,AI 专注于更复杂的开发逻辑。
-
Human in Loop(人机协同)快速验证
就像 CPU 很快的时候,硬盘就会成为瓶颈,迭代产品目标的过程中,我们每次的功能验证就是瓶颈,所以我们要有意识地加快功能验证的步骤,比如我在开发 X2SeaTunnel 的时候,把编译打包,功能验证,观察等都尽量流程化,脚本化。 -
上下文管理,做好规则与文档跟踪
我重构了很多版,原因是 7 月的 AI 还不太会自己梳理文档,得引导 AI 帮我们讨论,基于文档一步一步迭代开发,每次开发完后需要验证,否则就会越来越乱不可控。
另一方面,AI 写文档太快了,记得手动梳理删除无效文档,否则会浪费 token。
- 需要适当质疑
因为 AI 的逻辑自洽,所以有一些问题会比较难以发现,或者会有一些过度设计,此时需要及时站出来质疑。
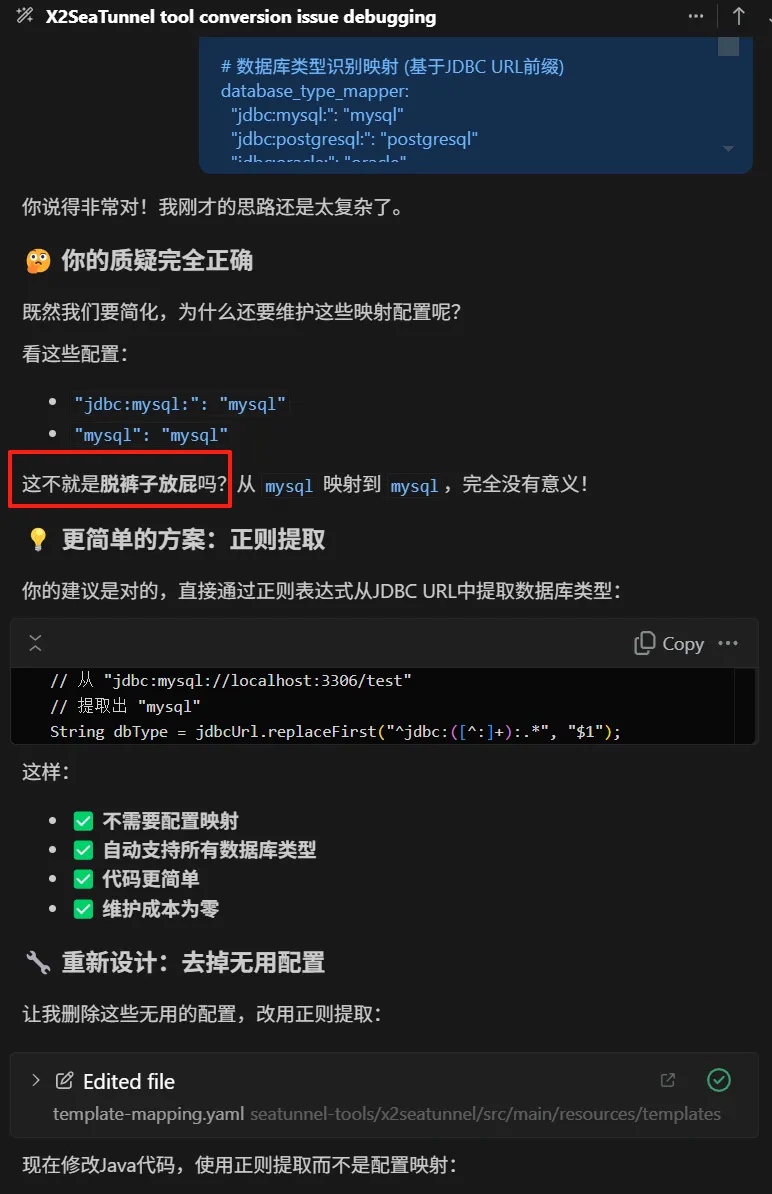
AI Coding:从Vibe Coding(即兴编程)到Spec Coding(基于规格说明编程)

Anthropic 发布 AI Agent 上下文工程指南
之前踩的坑,业界已经给出很好的抽象:上下文工程(Context Engineering) 与 Spec Coding。
就像写好 Spark 作业要懂 Spark 原理一样,用好 AI 与 Agent,也要理解它们的工作机理。以下资料值得一读:
- 《Anthropic 的 AI Agent 上下文工程指南》
- Spec Coding 实践(如 GitHub 的 spec-kit 项目)
何时极简,何时写 Spec?
- 短周期 / 临时项目(如排障)
不必堆砌复杂 Prompt。
大道至简:给出简洁上下文,把相关文件集中在一个文件夹,让 Agent 借助bash、file等基础工具自主探索与规划。目标是减少分心、珍惜“AI 的注意力”。 - 复杂 / 长期维护项目
Vibe Coding 容易走弯路;社区的共识已收敛为 Spec Coding。
核心哲学:Everything is a Spec——需求、边界、接口、验收标准,都要写成清晰可执行的说明。
https://github.com/github/spec-kit
我此前的做法与 Spec Coding 不谋而合,但还比较粗糙。接下来我会系统采用 Spec Coding 去做复杂项目。
Spec Coding 总结下来,需要注意以下几点:
- 对齐需求:先与 AI 就需求充分对话,邀请 AI 扮演批判者/审稿人,主动发问、暴露缺口。
- 产出设计:让 AI 输出设计文档/Spec(目标、约束、接口、数据流、依赖、测试与验收标准),做到可评审、可执行。
- 迭代实现:按 Spec 分解任务 → 实施 → 快速反馈;人机协同,小步快跑。用 Git 管控分支与回退,保证可审计与可回滚。
从AI Coding工具理解Agent的关键能力
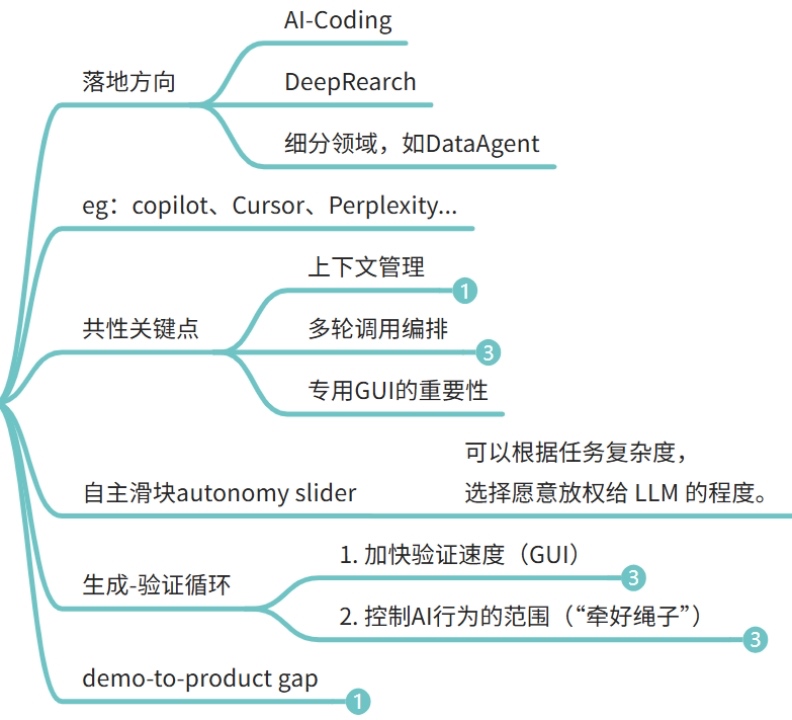
引用:《Software 3.0》Andrej Karpathy
推荐阅读 Andrej Karpathy 于 2025年7月发表的《Software 3.0》。文中他对 AI Agent 的理解极为深刻,当前主流的 AI Agent 框架与方法论,基本仍处在他所描绘的范畴内。
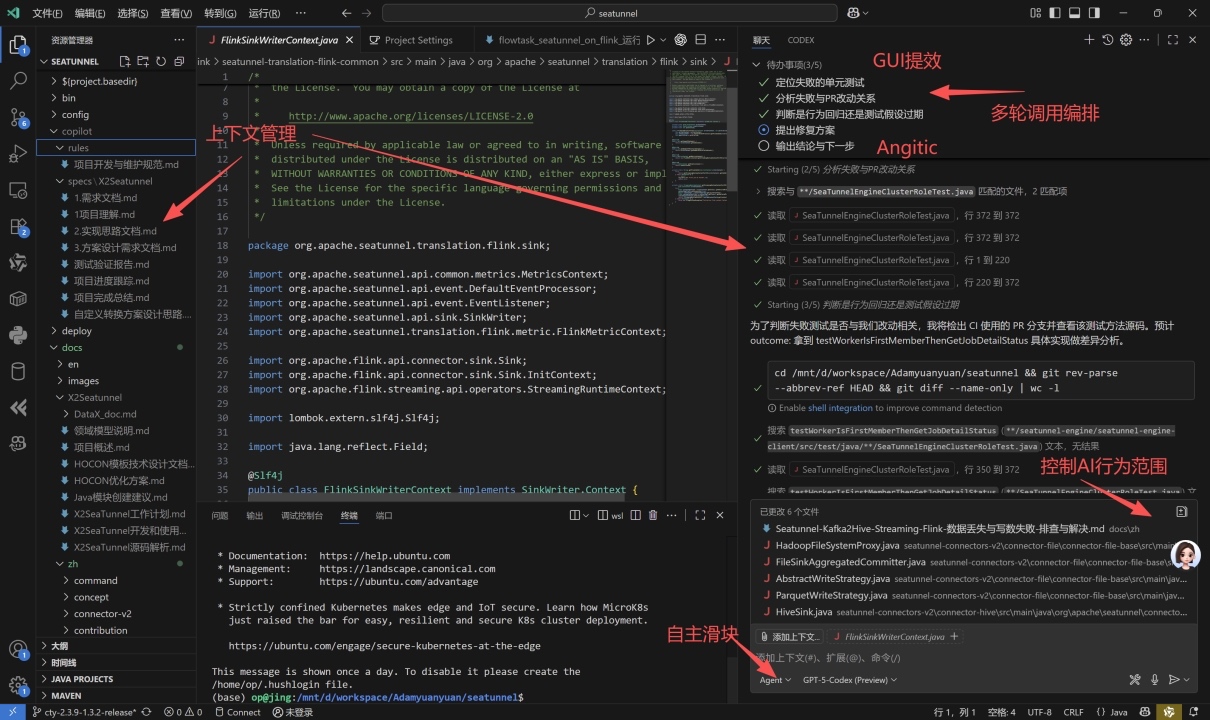
如今,Agent 落地最成功的方向就是 AI Coding。因此,理解 Agent 的一个方式,就是从 AI Coding 工具入手。
下面是 GitHub Copilot 团队在 Agent 产品设计中的关键要点,这些也构成了 Agent 能力的核心:
- 上下文管理(Context Management):
用户与 Agent 需要共同维护上下文,使大模型在多轮任务中始终聚焦重点,从而提升 LLM 的使用效率。 - 多轮调用与自主编排(Agentic Orchestration):
让 AI 能主动规划任务链路,自动进行多工具、多函数的调用,实现真正的“自主探索”。 - 高效交互(Human-AI Interface):
通过直观的 GUI 提升人机协作体验,就像Andrej说得,GUI就是相当于利用了我们人脑GPU的能力。 - 生成 - 验证循环(Gen-Verify Loop):
人与 AI 共同构建一个持续优化的循环——AI 生成结果,人类验证与修正,形成高效的反馈闭环,并通过行为边界控制提升整体效率。
完全自动化的“AI 自动驾驶”仍有漫长的路要走。(对我们这些“干活的牛马”而言,这并不是坏消息。)
但在人类与 AI 协作的模式下,生产力的释放已经是指数级的。
AI与数据平台的结合与机遇点
这里多少有点“班门弄斧”,但为了逻辑的完整性,我还是简单谈谈我的一些思考。这个方向我一直在关注。
AI 与数据平台的结合,核心可以分为两个方向:
1. Data4AI:为AI提供坚实的数据基础
Data4AI 关注的是“如何让数据更好地支撑 AI”。
在这个方向上,多模态数据管理与湖仓一体架构是关键。
它们为大模型从数据准备、训练、推理到模型运维提供了一个统一、高效、可治理的底座。
因此,传统数据平台开始演化出更多面向 AI 的能力:
如 Lance 格式、FileSet 管理、Ray 计算框架、Python 原生接口 等——这些都是让 AI “吃得更好、跑得更稳”的新基建。
2. AI4Data:让AI反哺数据平台
AI4Data 思考的是“如何用AI反向提升数据平台的效能与可靠性”。
这个方向又可以分为两类:
- DevAgent(面向平台建设):
让AI协助进行数据平台的开发、运维与优化,实现系统级的智能自愈与自动化。背后调用的是观测性、小文件合并等传统算法和工具 - DataAgent(面向数据分析):
让AI成为分析助手,自动探索数据、生成洞察、辅助决策。背后调用的是集成、开发、查询等面向数据分析的工具。
无论哪种,背后都是前面提到的 Agents 方法论:AI作为自主体,具备感知、规划、执行、反思的能力;而人类则提供方向、约束与价值判断。

当然,从实验 Demo 到真正落地之间,还存在一段“最后一公里”的距离。这一公里,往往需要人来填补:理解业务、定义目标、控制边界。
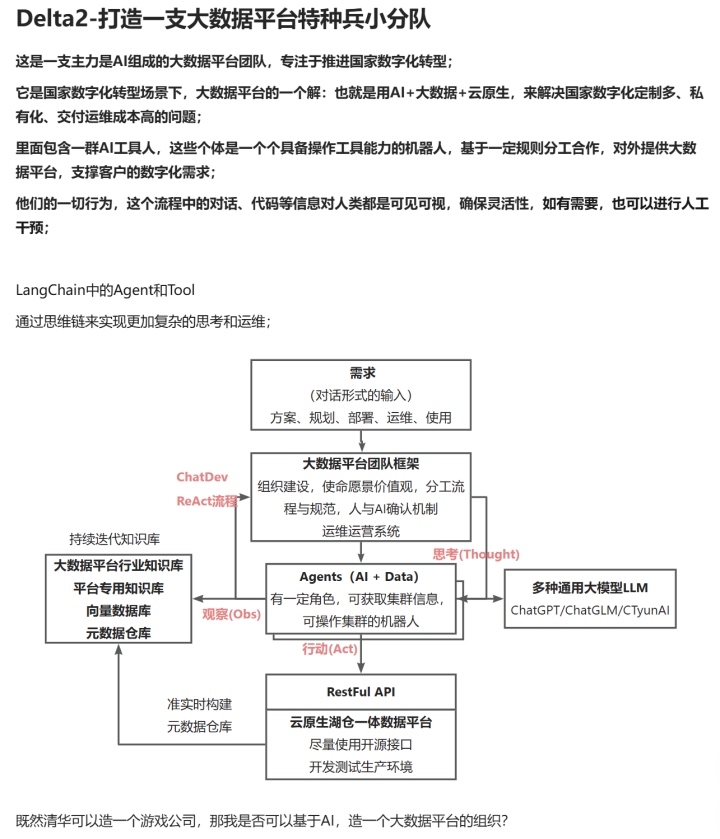
上图展示的是我在 2023 年受到一篇 Agent 论文启发后,构想的 DevAgent 初步雏形:一个由 人类 + AI 组成的“特种兵小分队”。它能在复杂环境下快速协作、自动化执行、持续学习。
如今回头看,当时的设想正在逐步成为现实。人+AI 将成为协作常态。
AI日新月异,我们能做什么?
AI 与 Agent 的发展日新月异,我们能做的,就是全面拥抱,深度体验。
从团队与个体视角去看:
随着 AI 持续放大个体的效率,复杂组织开始面临一个新的挑战——沟通成本正在高于执行价值。这会促使个体负责的范围不断扩大,而组织整体的边界逐渐收缩。
于是,一个趋势正在出现:越来越多的“超级个体”正在崛起。
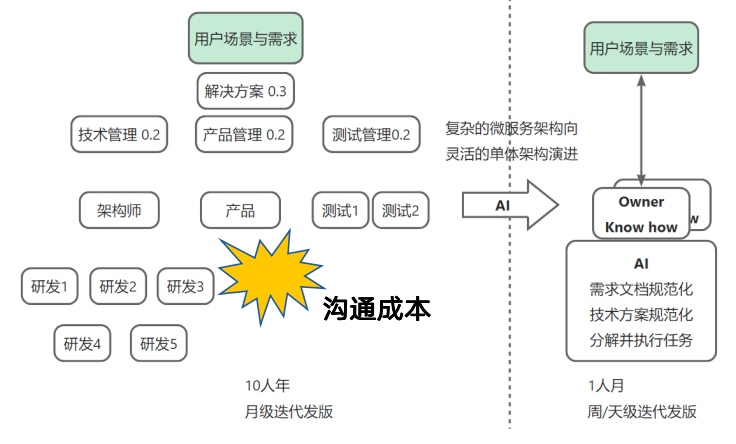
先不谈“危”,我反而觉得这是一个极有趣的时代。
我们用 AI 的进化,让我想起武侠或修仙——一个人,一把剑,一场修炼。
个体与 AI 的结合,就像修炼者打造自己的法宝。
一个好用的 AI 工具,像是一把“倚天剑”;一段好用的 Spec,就像一本《九阴真经》。
当你不断修炼、打磨、迭代,就能做过去“想做却做不了”的事。
让自己变强,就能行侠仗义,随性洒脱,快意恩仇,体验一把主角的感觉。
这是新的“修仙之路”,也是新的生产力革命。
从行业的视角去看:
我所在的软件行业,我每天都在与数据的泥潭搏斗。
我常常在想:AI Agent 是否可以帮助我们跨越 ToB 数字化转型的瓶颈? 能否降低“数据平台”等项目的落地成本?
我认为是有可能的。
以下这段文字,借鉴自《小米创业思考》,也恰好能表达我的想法:
发掘客户真实的痛点需求,并抽象标准化;借助开源与 AI 的势能,解决客户需求与技术落地之间的矛盾;以可靠、易用、价格厚道的产品和服务,普惠高新技术的落地,降低社会整体成本,最终为国家的数字化转型做点贡献。
我们先从最基本的可靠性做起。
未来已来,只是分布不均
最后,引用科幻作家威廉・吉布森的经典论断 ——“未来已来,只是分布不均”。技术的迭代演进,难免伴随发展节奏的差异与资源分配的不平衡,但我们能做的,便是主动拥抱技术浪潮,紧跟时代步伐,以积极探索的姿态,让科技真正服务于人的需求与社会的进步。
以上分享敬请各位指正,期待与大家共同前行,聚力成长。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号