人工智能现代方法学习笔记(2):智能体
第二章:智能体
一、智能体和环境
-
智能体:任何通过 传感器 sensor 感知 环境 environment 并通过 执行器 actuator 作用于该环境的事物都可以被视为 智能体 agent 。
-
感知 percept:表示智能体的传感器所在感知的内容。智能体的 感知序列 percept sequence 是智能体所感知的一切的完整的历史。
一般而言,一个智能体在任何给定时刻的动作选择可能取决于其内置知识和迄今为止观察到的整个感知序列。而不是他未感知到的的事物。
在数学上,我们说智能体的行为由 智能体函数 agent function 描述。人工智能体的智能体函数将由 智能体程序 agent program 实现。
二、良好行为:理性的概念
-
人工智能通常坚持 结果主义 consequentialism :我们通过结果来评估智能体的行为。当智能体进入环境的时候,他会根据接受的感知产生一个动作序列,这一序列又会导致环境发生一系列状态变化。如果这一系列变化是良好的,我们认为智能体表现良好。
-
性能度量 performance measure :用来描述上述的可取性,也就是评估这一系列状态变化是好还是不好。
-
理性:理性取决于以下四个方面
- 定义成功标准的性能度量
- 智能体对环境的先验知识
- 智能体可以执行的动作
- 智能体到目前为止的感知序列
于是我们有理性智能体的定义:对于每个可能的感知序列,给定感知序列提供的证据和智能体所拥有的任何先验知识,理性智能体应该选择一个期望最大化其性能度量的动作。
-
全知、学习、自主
- 全知 omniscience 的智能体能预知其行动和实际结果,以此来采取行动。但是这样的智能体在现实中是不可能存在的。而且理性不等同于完美。理性让期望值最大化,而完美让实际性能最大化。
- 一个智能体需要进行 信息收集 information gathering 和 探索 explore,并且尽可能的痛他所感知到的东西中 学习 learn 。智能体的初始配置可以反应对环境的先验认知,但随着智能体获取经验,这可能会被修改或者增强。在一些极端的环境下,环境完全是先验已知的和完全可预测的,这种情况下只需要智能体正确的执行。、
- 在某种程度上,智能体完全依赖于设计者的先验认知,而不通过其自身的感知和学习过程,我们就说他缺乏 自主性 autonomy。一个理性的智能体应该是自主的,他应该学习如何弥补部分不正确的先验知识。
- 事实上我们很少要求一开始智能体就完全自主。在充分的体验相应环境后,理性智能体的行为可以有效的独立于其先验知识。
三、环境的本质 —— 任务环境 task environment
我们使用 PEAS(Performance Environment Actuator Sensor)描述环境。
| 智能体类型 | 性能度量 | 环境 | 执行器 | 传感器 |
|---|---|---|---|---|
| 自动驾驶出租车 | 安全、速度快、合法、舒适、最大化利润、对其他道路用户影响最小化 | 道路、其他交通工具、警察、行人、客户、天气 | 转向器、加速器、制动、信号、喇叭、显示、语言 | 摄像头、雷达、速度表、GPS、发动机传感器、加速度表、麦克风、触摸屏 |
| 交互式英语老师 | 学生的考试分数 | 一组学生 / 考试机构 | 用于练习、反馈、发言的显示器 | 键盘 / 语言输入、语音感受 |
环境还有如下属性:
- 完全可观测的 fully observable / 部分可观测的 partially observable:如果智能体的传感器能让他在每个时间点都能访问环境的完整状态,那么就是完全可观测的。如果传感器缺少部分状态,那就是部分可观测的。特别的,如果没有传感器,那就是 不可观测的 unobservable 。
- 单智能体 single-agent / 多智能体 multiagent:这个区分很简单,主要看有无多智能体交互。多智能体环境中,通信常常作为一种随机行为出现;某些 竞争性 competitive 环境中,随机行为却是理性的(避免了一些可预测的陷阱)。
- 确定性的 deterministic / 非确定性的 nondeterministic:如果环境的下一个状态完全由当前状态和智能体执行的动作决定,我们就说环境是确定性的。大多数真实情况非常复杂,处于实际目的我们必须要认为环境是“非确定性的”。特别的,随机的 stochastic 这一词不是“非确定性”的同义词。如果环境模型显式处理概率,那么他是随机的;如果只是给出一个随机事件却没有量化其概率,救人位他是非确定性的。
- 回合式的 episodic / 序贯的 sequential (also parallel):回合式的任务环境中,智能体接受一个感知并进行单个动作,并且下一回合不依赖前几个回合采取的动作。但是序贯的环境中当前决策可能会影响未来的所有决策。
- 静态的 static / 动态的 dynamic:如果智能体在思考的时候环境变化了,那么这个环境是动态的;否则是静态的。然而,如果环境环境本身不会随着时间的流逝而改变,但是智能体本身的性能分数会改变,那么就说这个环境是 办动态的 semidynamic。
- 离散度 discrete / 连续的 continuous:离散和连续的区别适用于环境的状态、处理时间的方式和智能体的感知与动作。比如国际象棋的状态就是连续的,一辆汽车速度随时间的变化就是连续的。
- 已知的 known / 未知的 unknown:严格来说这组概念不是区别环境本身,而是指设计者对环境“物理定律”的认知情况。
四、智能体的结构
人工智能的工作是设计一个 智能体程序 agent program 实现智能体函数,即从感知到动作的映射。如果该程序将运行在某种具有物理传感器和执行器的计算设备商,我们称之为 智能体架构 agent architecture 。也就是说:智能体 = 架构 + 程序。
在本书设计的每个智能体都有相同的框架:将当前感知作为传感器输入,并将动作返回给执行器。例如,一个简单的伪代码实现可能是这样的:
function TABLE-DRIVEN-AGENT(percept) returns 一个动作
persistent: percepts, 初始为空的序列
table, 以感知序列为索引的东坐标,初始完全确定
将 percept 添加到 percepts 的末尾
action := LOOKUP(percepts, table)
return action
但是这种用表驱动的智能体构建方法必定是失败的。考虑 \(P\) 是可能的感知集,\(T\) 是智能体的生存周期,查表将包含 $ \sum_{t=1}^{T} |P|^t$ 条记录,然而 \(P,T\) 往往非常大,所以这个查找记录的耗时往往很长。
接下来,我们探讨几种基本的智能体程序
1. 简单反射型智能体
我们引入一个 条件-动作规则 condition-action rule,也就是“如果-那么”语句。这一类智能体的伪代码实现是这样的:
function SIMPLE-REFLEX-AGENT(percept) returns 一个动作
persistent: rules, 一组条件-动作规则
state := INTERPRET-INPUT(percept)
rule := RULE-MATCH(state, rules)
action := rule.ACTION
return action
这是个很简单的智能体,但他的智能有限。此类智能体只有在当前感知的基础上才能做出正确的决策,也就是说,环境必须完全可观测。有的时候,我们可以使用 随机化 randomize 来让他在部分可观测的环境下运行。
2. 基于模型的反射性智能体
该智能体维护某种依赖于感知历史的 内部状态 internal state,从而至少推断当前状态的某种未观测的方面。关于世界如何运转的模型叫做 转移模型 transition model,关于世界状态如何反映到传感器的模型叫做 传感器模型 sensor model。此类智能体称为 基于模型的智能体 model-based agent。一种伪代码如下:
function MODEL-BASED-REFLEX-AGENT(percept) return 一个动作
persistent: state, 智能体当前对世界状态的理解
tansition_model, 关于下一个状态如何决定于当前状态和动作的描述
sensor_model, 关于当前世界状态如何反映到智能体感知的描述
rules, 一组条件-动作规则
action, 最近的动作,初始为空
state := UPDATE-STATE(state, action, percept, transition_model, sensor_model)
rule := RULE-MATCH(state, rules)
action := rule.ACTION
return action
3. 基于目标的智能体
该智能体通过搜索和规划来进行决策。不同于前面的规则,他涉及到了“对未来的考虑”。他会不断尝试“如果我尝试动作 A,那么世界会发生什么”,以此来得出效益最大化的结果。
4. 基于效用的智能体
可以把 效用 utility 理解为一种“快乐”或者“评分”,智能体用 效用函数 utility function 来量化一些特征来决定。与基于目标的智能体不同,他多了一步“如果这样做,我会有多快乐?”来辅助决策。
个人认为效用可以理解为一种“加权”。比如你可以送外卖赚钱你也可以当家教赚钱,但是当家教会让你“更快乐”(也许吧?)那么你的偏好可能是当家教,哪怕送外卖赚钱更多。
5. 学习型智能体 —— 离开了效用函数的智能体
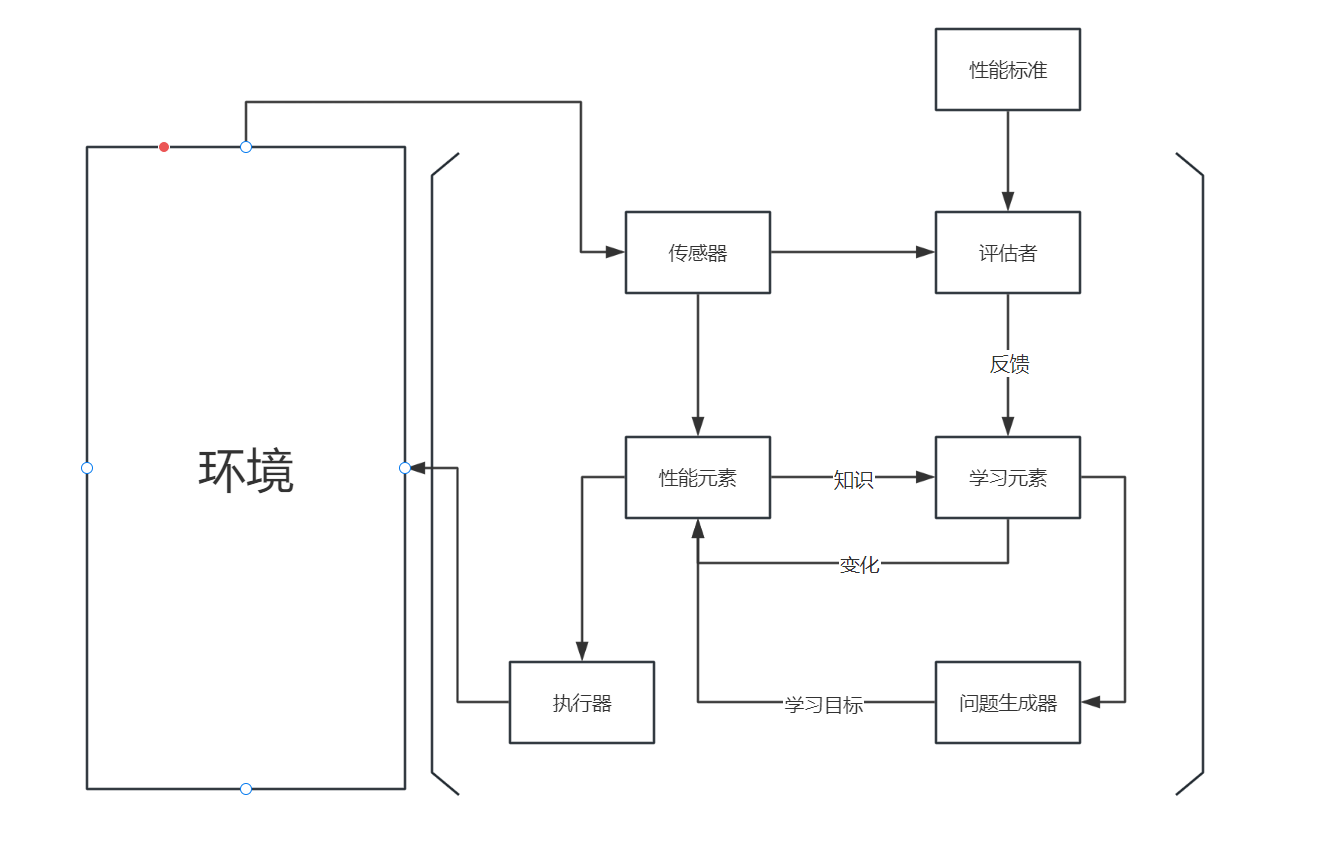
该智能体最重要的就是负责提升的 学习元素 learning element,负责选择外部行动的 性能元素 performance element,学习元素使用来自 评估者 critic 的反馈以进行修正。问题生成器 problem generator 符合建议动作。
为了描述这些组件如何工作的,我们会引入:
- 原子表示 atomic representation:每一个状态不可分割,没有内部结构
- 因子表示 factored representation:将每个状态拆分成一组固定的变量或者属性,每个变量或者属性具有一个值
- 结构化表示 structured representation:表示各个对象自己的属性以及和其他对象的关系
等表达方式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号