
人工智能学习笔记
Deep Learning
基础知识
-
Loss Function:
-
MSE(mean square error loss)(均方误差)
-
CEE(cross entropy error loss)(交叉熵误差)
-
-
Backward:
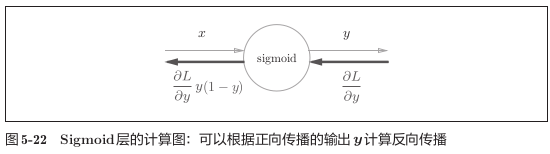
Sigmoid:
![img]()
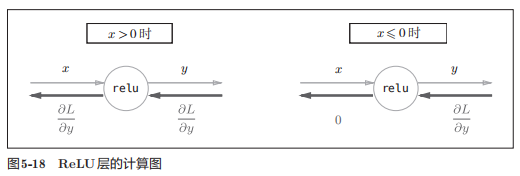
ReLU:(分段讨论)
![img]()
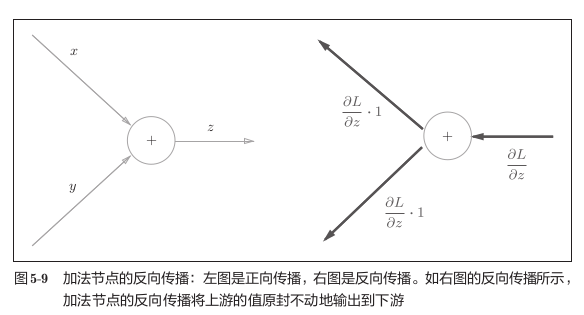
Add:(直接传播,不发生改变)
![img]()
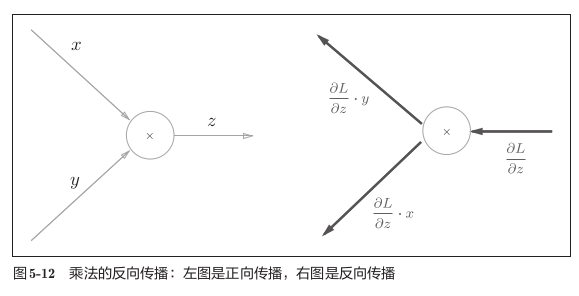
Multiply:(相当于互换输入)
![img]()
Affine:(矩阵乘法,也是交替相乘,不过需要考虑矩阵的形状,进行相应的转置)
![img]()
-
Optimizer:
-
SGD (stochastic gradient descent)
-
Momentum
-
ADAM
-
-
Weight decay:
一般取值weight_decay=1e-4
-
Dropdout:
作用:删除部分神经元,防止模型过拟合
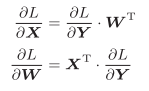
按照概率p删去部分神经元结点后,为使最后输出的期望保持不变,需要等比例增大神经元输出的值(标准化,期望保持不变)
-
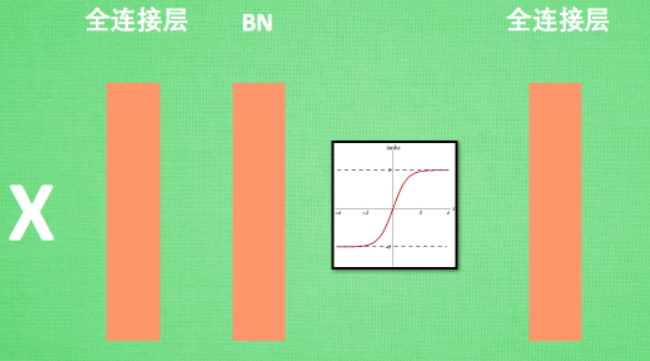
Batch Norm
Covariant(协方差):
定义式:$$\begin{matrix}Cov\left(X,Y\right)&=E\left[\left(X-E\left[X\right]\right)\left(Y-E\left[Y\right]\right)\right]\end{matrix}=E[XY]-E[X]E[Y]$$
意义:表示X、Y两个维度偏离各自均值的程度,如果Cov > 0,则说明两者正相关,如果Cov < 0 则说明负相关,Cov = 0 则说明相互独立
运算符:BN(·)
首先对输入的数据进行归一化:
\[\begin{gathered}\hat{\boldsymbol{\mu}}_{\mathcal{B}}=\frac1{|\mathcal{B}|}\sum_{\mathrm{x}\in\mathcal{B}}\mathrm{x},\\\hat{\boldsymbol{\sigma}}_{\mathcal{B}}^2=\frac1{|\mathcal{B}|}\sum_{\mathbf{x}\in\mathcal{B}}(\mathbf{x}-\hat{\boldsymbol{\mu}}_{\mathcal{B}})^2+\epsilon.\end{gathered} \]得到归一化后的均值和方差(方差加上了一个很小的数 \(\epsilon\) 防止除以0),之后通过批量归一化层(如下)
\[\mathrm{BN}(\mathbf{x})=\boldsymbol{\gamma}\odot\frac{\mathbf{x}-\hat{\boldsymbol{\mu}}_{\mathcal{B}}}{\hat{\boldsymbol{\sigma}}_{\mathcal{B}}}+\boldsymbol{\beta}. \]通过训练 \(\gamma\) (拉伸)和 \(\beta\) (偏移)两个参数,BN运算位于输入之后,激活函数之前
![img]()
-
卷积(CNN)
![img]()
卷积层的参数数量:in_channels * out_channels * kernel_size
解释:
1*1卷积层:一般用于降低通道数(减少参数)
kernel_size=1:相当于全连接层
nn.Flatten():将4D的tensor转换成2D的tensor(只保留了张量个数的维度,将通道和高宽展平了)
-
LeNet
-
AlexNet(相当于层数更多的LeNet网络,最后有一个dropout层用来简化模型参数)
-
VGG(将模型特定的层抽出合并成一个块,称为VGG块)
-> 卷积层 -> 激活函数 (-> 卷积层 -> 激活函数 ...) -> 池化层
每一个vgg块由多个卷积层、激活函数叠加再加上一个池化层组成,一个vgg网络由多个vgg块组成
-
NiN
nin块由卷积层、激活函数和两个1X1的卷积层组成
去掉了全连接层,降低了过拟合的概率,并减少了参数的数量
![img]()
-
GoogLeNet
卷积层数超过100层
重要思想:将不同的卷积模块封装成一个stage
-
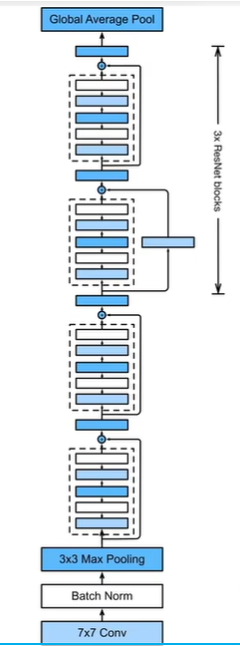
ResNet
ResNet块:
![img]()
重要思想:
将原来的模型 加 到了卷积后的模型中,能够避免梯度变得过小(梯度消失)
*问题:当神经网络较深时,梯度很容易变得很小(网络参数没法更新)
![img]()
-
DenseNet
-
-
RNN(区域神经网络)
-
多GPU并行
-
将批量数据均分到多个GPU上进行计算
-
将模型拆分成多个小模型存在不同的GPU上
-
-
分布式计算
-
train(训练):



torchvision.datasets.ImageFolder(root: str, tranform) -> Dataset
# 读取root中的数据集,并返回处理好后的Dataset
torch.utils.data.DataLoader(dataset: Dataset, batch_size, shuffle, num_workers) -> DataLoader(Iterator)
# 将获取Dataset转换成DataLoader(Iterator类型)
net = torchvision.models.resnet18(pretrained=False)
net.fc = nn.Linear(net.fc.in_features, <out_features>)
nn.init.xavier_uniform_(net.fc.weight)
# 使用定义好的网络结构,并修改最后一层的输出形状
目标检测
将物体识别出来并标出图像中物体的位置和物体的类别
-
基于锚框(anchor)的检测算法
Bounding box(锚框):
![img]()
包含边框左上角和右下角的坐标、边框中物体的类别、置信度
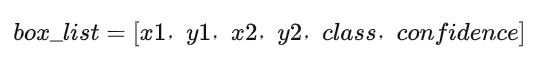
IOU(交并比):
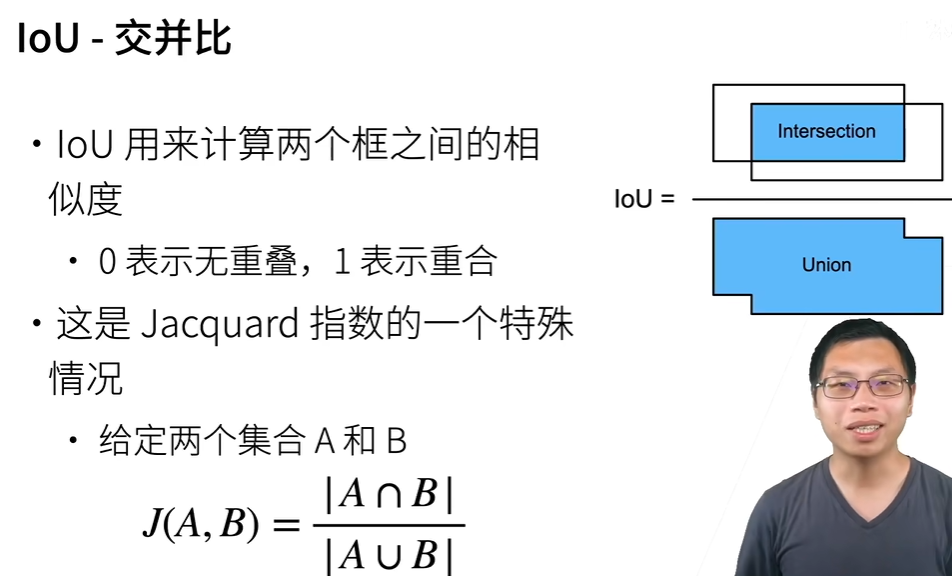
通过计算预测框与预先标定的框的交、并区域面积比较
NMS(非极大值抑制):
语义分割
将物体的边缘分割出来
实例分割
不仅将物体的边缘分割出来,还能够确定每个物体的类别
序列模型
-
自回归模型
马尔科夫链
-
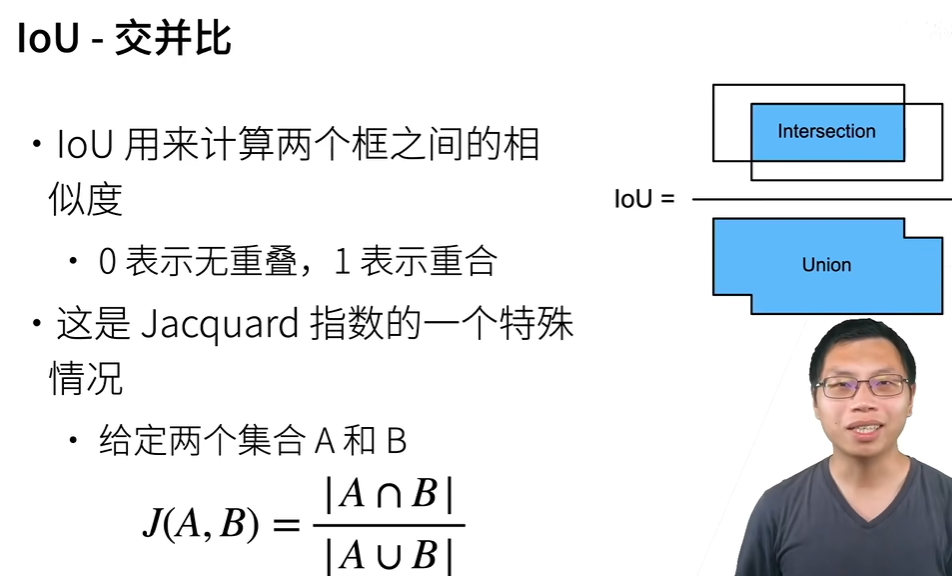
N元语法
认为第N个词的出现只与前面N-1个词有关
![img]() >
>一元语法忽略了文本之间的信息
-
拉普拉斯平滑法
作用:处理零概率问题(在观测某个样本库时,不能因为一个事件没有发生而认为该事件概率为0,即不可能事件)
公式:(将所有的事件数目都+1)
![img]()
![img]()
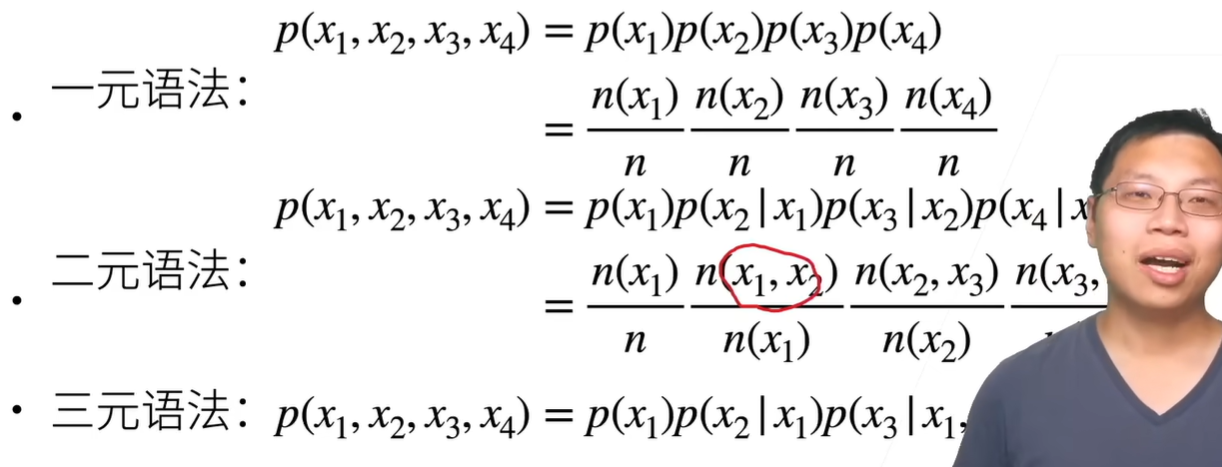 >
>

RNN(循环神经网络)
RNN的输出取决于当前时刻输入和上一时刻的输出(将输出继续作为输入,相当于循环)
-
应用
![img]()

优化算法
损失函数
-
MSE (mean square error)
均方误差,用于数值回归模型
-
CE (cross entropy)
交叉熵损失,用于分类模型
优化算法
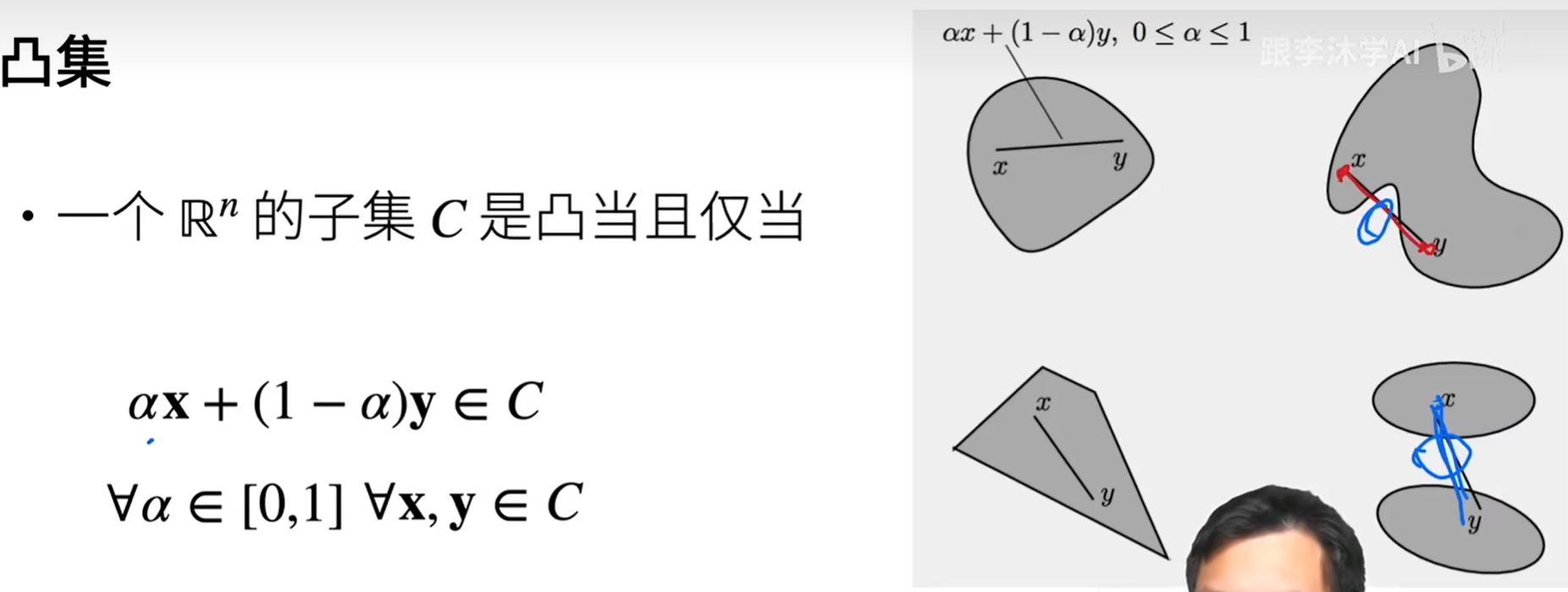
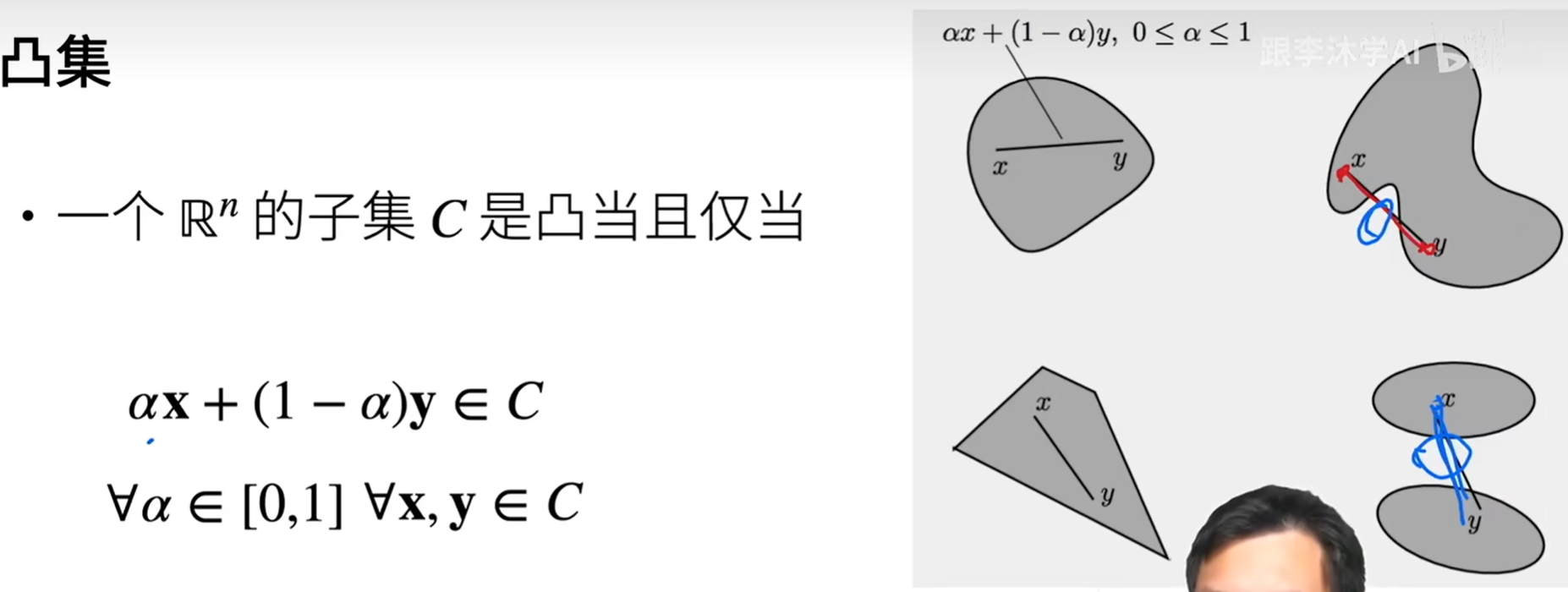
凸集
-
SGD
随机梯度下降
![img]()
-
SGD-Momentum
包含动量(使用指数加权平均法对梯度下降进行平滑处理)
![img]()
指数加权平均
![img]()
\(v_t\) 为第t次的平均值,\(\theta_t\) 为第t次的测量值
![img]()
作用:1. 抚平短期波动,起到了平滑的作用。2. 还能够将长线趋势或周期趋势显现出来。
优点:运用递推的方法求解n时刻的平均值,并且只需要保存 (n-1) 时刻的平均值和 n 时刻的值即可,节省内存(AdaGrad还需要存储 n)。\(\beta\) 经验值取 0.9
-
AdaGrad
![img]()
随着算法不断迭代,r会越来越大,整体的学习率会越来越小
优点:学习率发生改变
-
RMSProp
![img]()
求累计平方梯度的方法与AdaGrad不同
-
Adam(更常用)
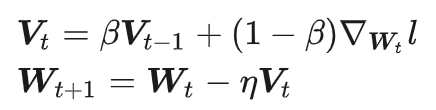
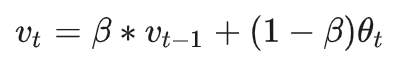
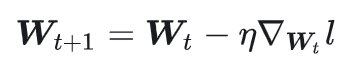


神经网络原理分析
-
越靠近输入层的卷积层(底层)包含更多的边缘轮廓信息,越靠近输出层的卷积层(顶层)包含更多的语言信息(抽象的)
-
越靠近顶层的feature map分辨率越低
经过众多 conv, pooling 操作之后,feature map 的尺寸减小,虽然包含了较多的语言信息,但是缺失了边缘轮廓等的位置信息(一般是进行上采样操作)
经典网络模型
分类/回归
区别在于最后全连接层的输出
-
MLP(多层感知机)
使用全连接层
-
CNN(卷积神经网络)
时序序列
包含文本序列和音频序列
- RNN
- LSTM
生成式模型
-
文本生成模型
-
CNN+RNN
-
transformer
-
-
图像生成模型
- Diffusion
深度学习中的操作
前向传播
-
卷积运算
-
汇聚(pooling)
-
残差连接
反向传播
实践和应用
目标检测
-
RCNN(区域卷积神经网络)
将CNN用于目标检测中
原理:通过Selective Search算法获取2000个选框,然后对每个选框区域使用CNN提取feature map,再将其输入到21个(20个类别+1个背景)SVM分类器中得到每个类别的概率,然后对所有候选框最大概率类别进行NMS操作(非极大值抑制)从而筛选出最后结果。
Selective Search(选择性搜索)
- 穷举法(对每个像素随机生成多个选框)
- 相似性度量
- 颜色相似性(色彩直方图)
- 纹理相似性
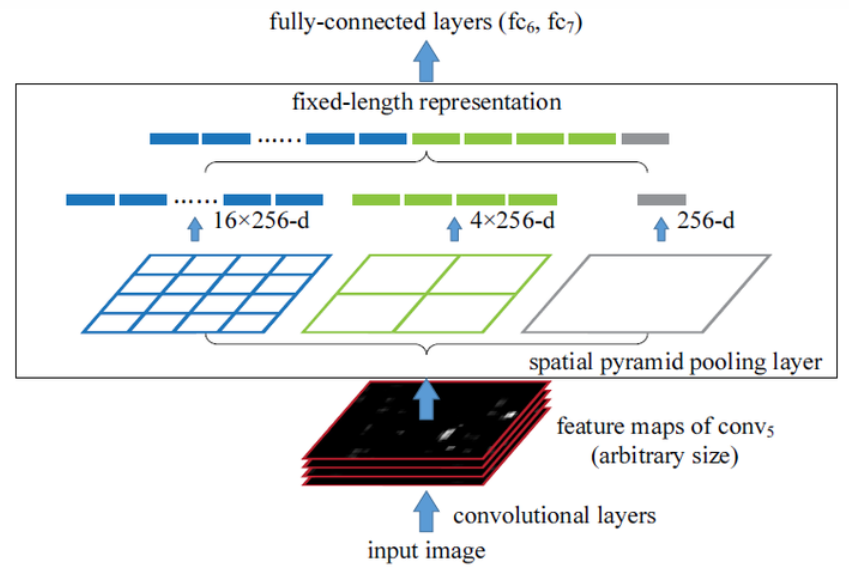
SPPNet(空间金字塔池化层)
![img]()
优点:避免了网络输入时对图像进行resize操作,只在最后的fc层前加入一个SPP层,该层的输出size固定
-
Fast RCNN
-
Faster RCNN
-
FPN(特征金字塔)
OCR文字识别
-
CTPN
检测文本位置
-
CRNN
识别文本区域中的文字内容
-
CTC
常用在语音识别、文本识别等领域的算法,用来解决输入和输出序列长度不一、无法对齐的问题
CTC通常接在RNN的后面,与RNN结合使用
语音识别
-
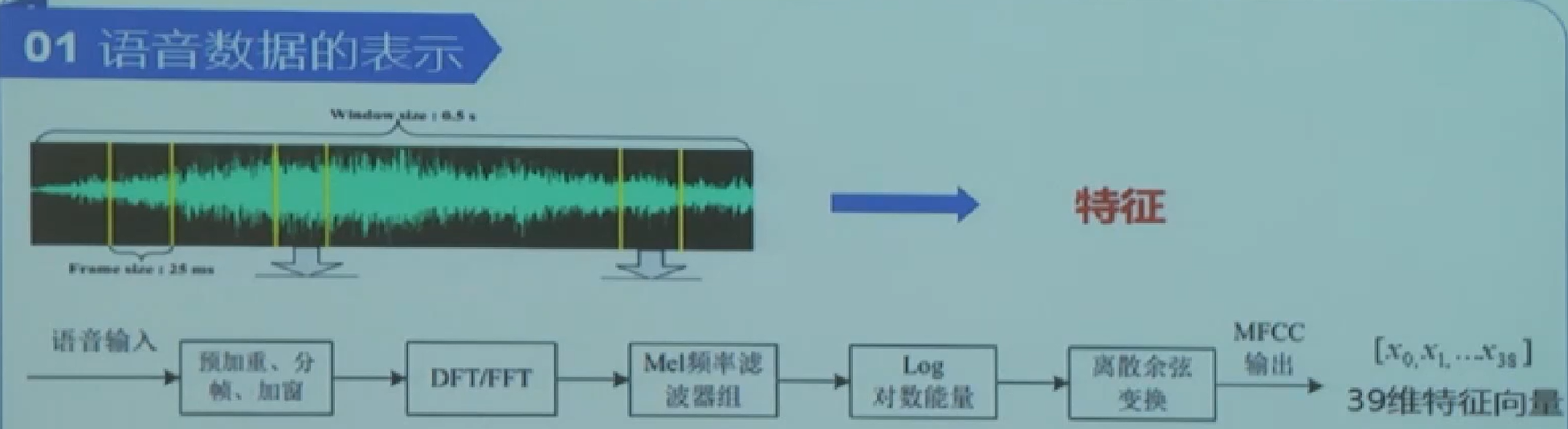
语音数据的表示
![img]()
语音分帧:
DFT/FFT:
梅尔滤波器:
MFCC特征提取:
-
发音单元(建模方式)
![img]()
-
声学模型的训练
![img]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号