
Paper Reading
论文精读
论文精读方法参考B站UP主跟李沐学AI
阅读顺序:Abastract -> Introduction -> Conclusion -> Related Work
ResNet
网络结构
核心模块:Residual Block
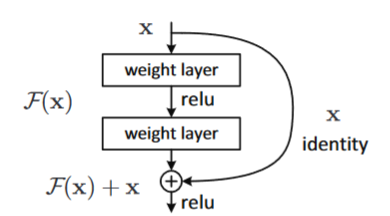
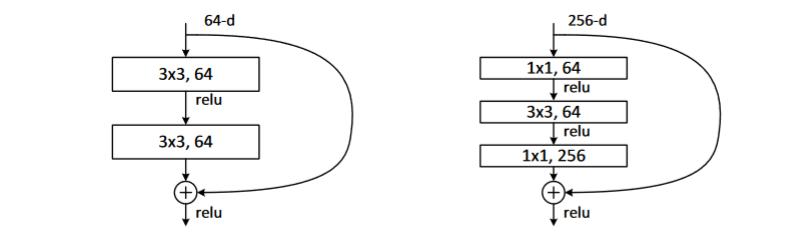
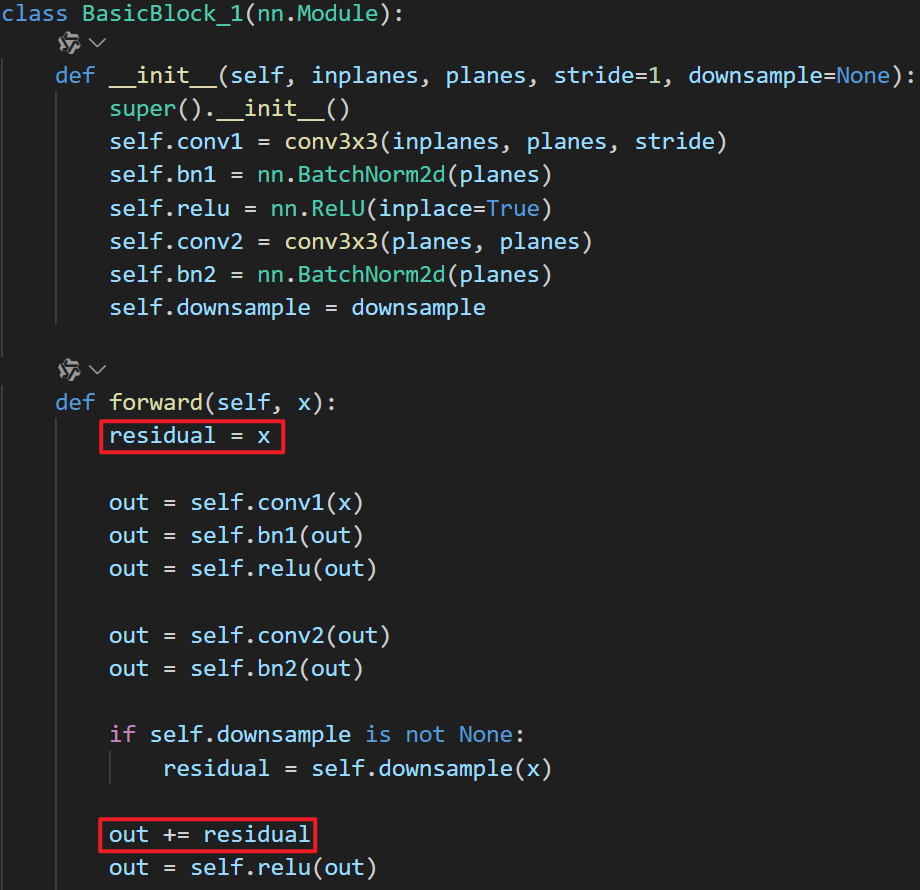
代码实现

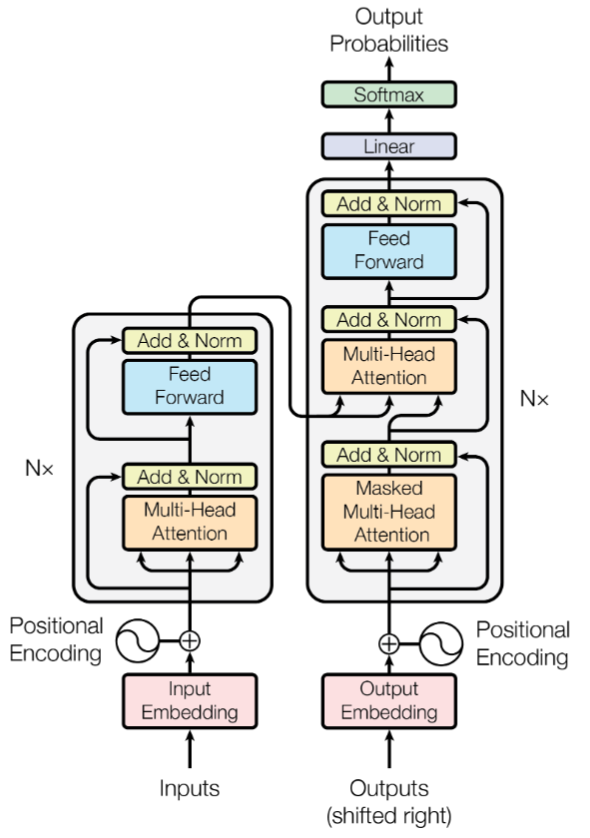
Transformer
网络结构
Multi-Head Attention
-
Q(Query), K(Key), V(Value)
Q 相当于近似的 K
-
\(QK^T\)
向量内积:\(\vec{a} \cdot \vec{b} = abcos<\vec{a}, \vec{b}>\)
两个向量相似度越大的时候向量的内积越大,反之则越小;当两个向量正交时内积为0
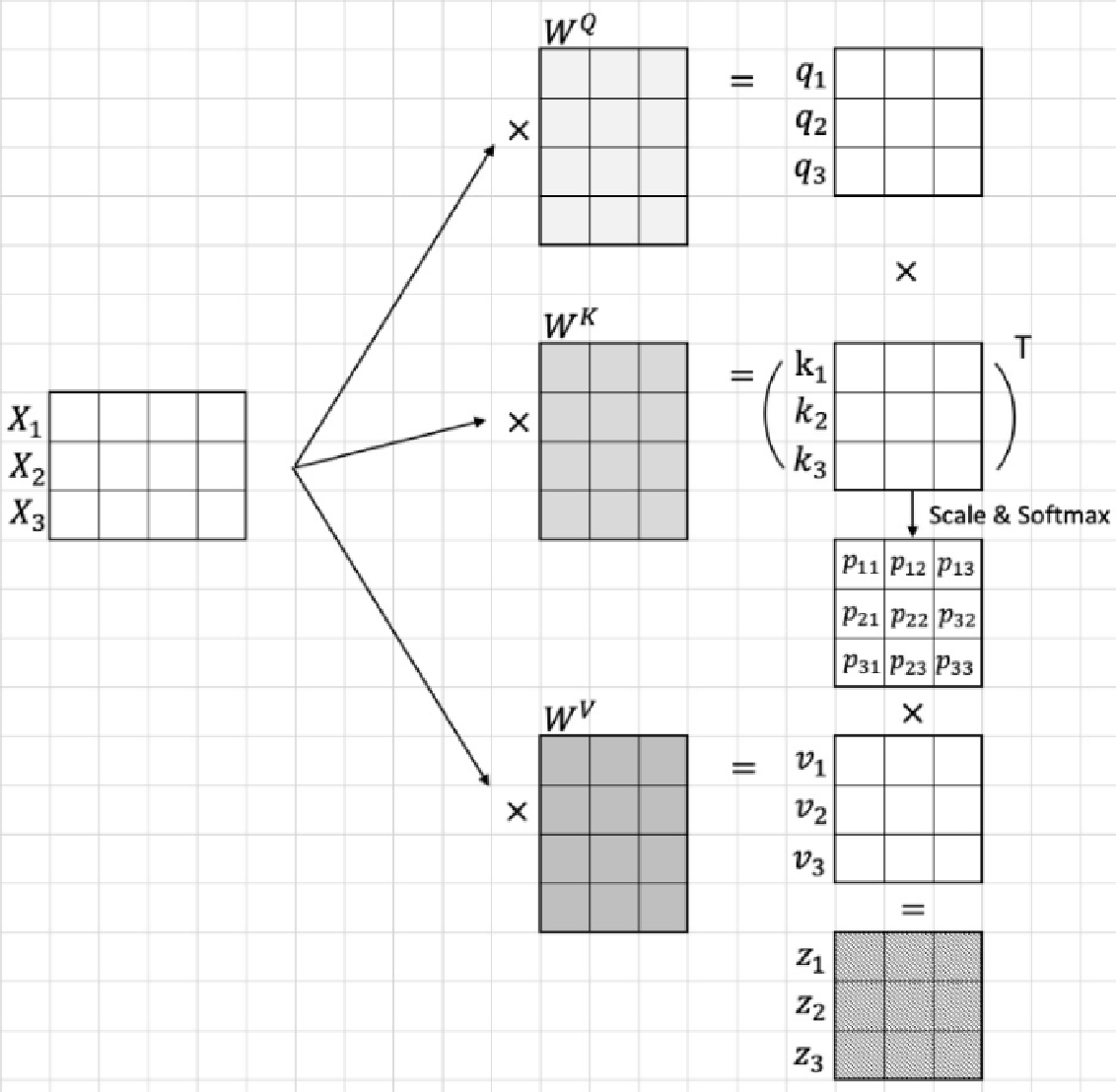
对于每一个输入的Vectorized Token进行线性映射都会得到对应的三个矩阵\(W^Q\), \(W^K\), \(W^V\),这三个矩阵分别与输入的\(Vector\)相乘即可得到对应的\(Q\), \(K\), \(V\),之后再按照上面的注意力计算公式进行计算即可
备注:线性映射(
nn.Linear)实际作用就是将输入张量乘以一个高维权重矩阵\(Weight\)然后再加上一个偏置\(Bias\),因此上面的\(W^Q\), \(W^K\), \(W^V\)实际都是线性层中的权重参数
-
Self-Attention
-
Cross-Attention
Feed-Forward Networks
Positional Encoding
位置编码是为了处理连续的时间序列数据,区别于传统的RNN模型,第 \(t\) 时间步的计算依赖于第 \(t-1\) 步的计算结果,难以进行并行计算
\(PE_{(pos, 2i)} = sin(pos / 10000^{2i/d_{model}})\)
\(PE_{(pos, 2i+1)} = cos(pos / 10000^{2i/d_{model}})\)
将 \(pos\) 位置处的 \(token\) 编码成长度为 \(d_{model}\) 的向量,偶数位置求sine,奇数位置求cosine,保证最后得到的每一个 \(token\) 编码后的向量都是不同的(但是长度相同)
Vision Transformer
Attention机制的由来
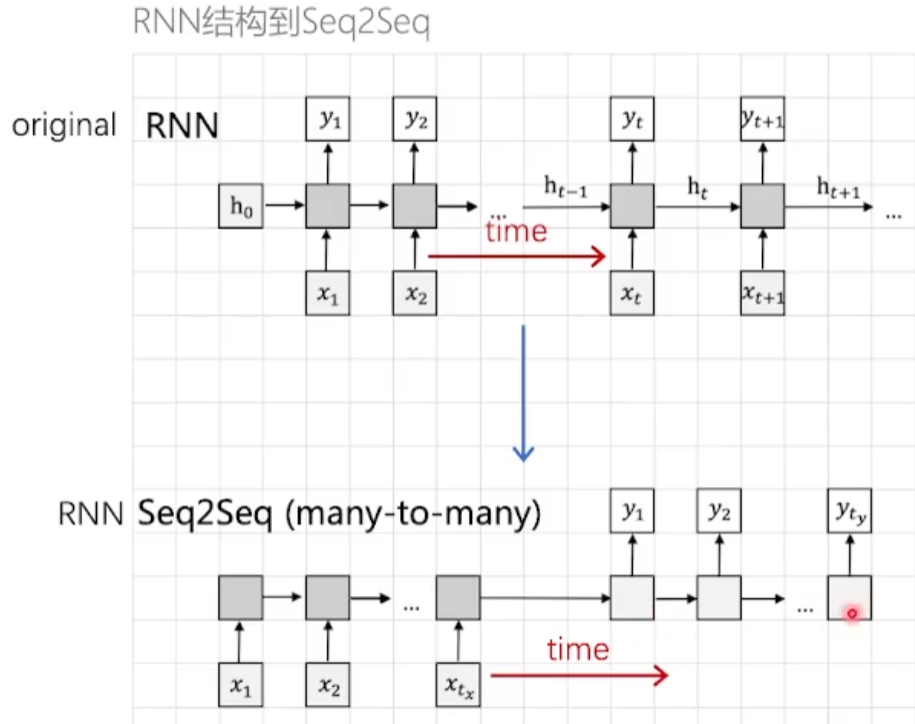
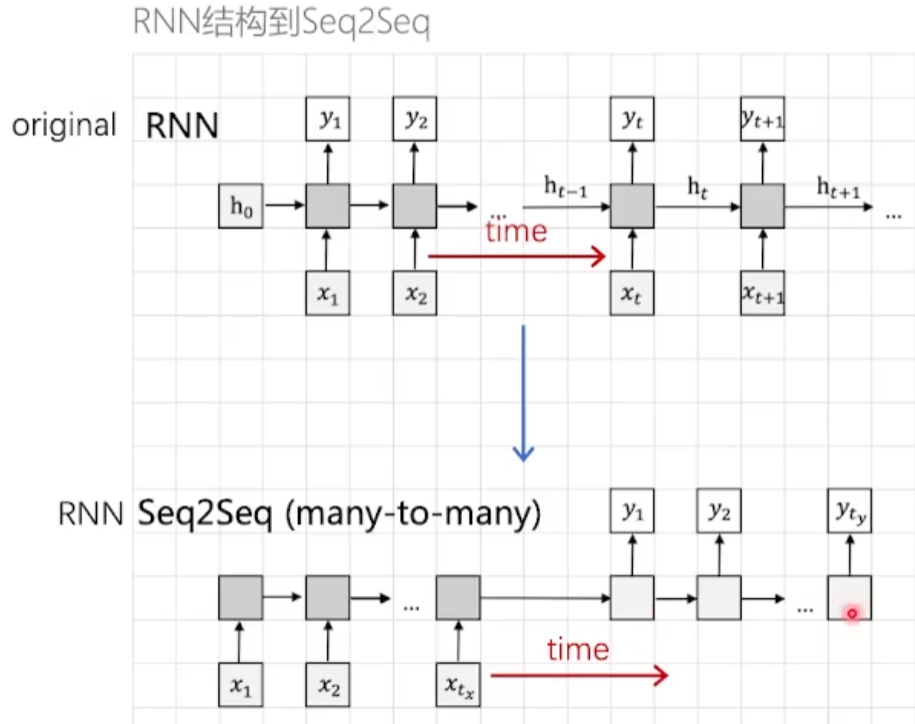
- 原始
RNN网络输入张量和输出张量的长度是相同的 Seq2Seq模型的输入和输出长度是不相同的
BN 和 LN 的区别
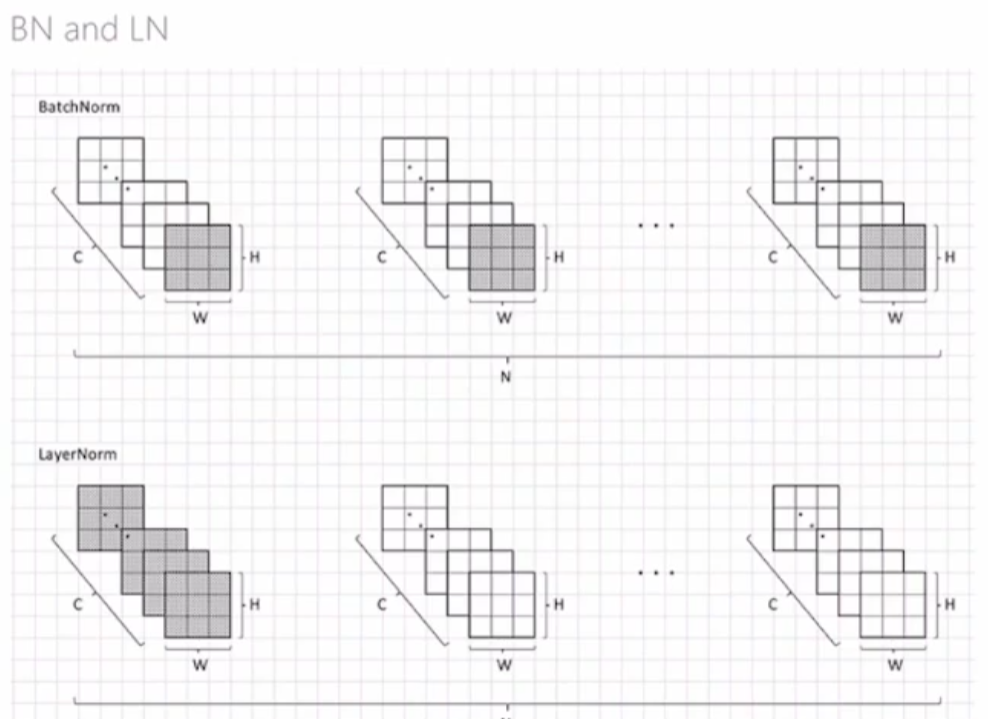
Batch Normalization是在每一个batch中抽取每个位置的张量求均值和方差
Layer Normalization是在每一个layer中抽取所有的张量求均值和方差
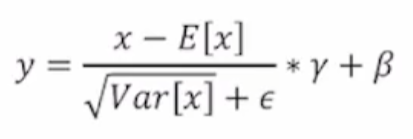
DeiT
知识蒸馏
简单来讲就是使用一个参数量更大,效果更好的模型作为
Teacher model来辅助训练一个参数量更小的Student model模型
GPT1
LSH算法:判断文章的相似度(通过word的集合进行判断)
Beam Search ?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号