
[Mark] KVM 虚拟化基本原理
- 操作系统(内核)需要直接访问硬件和内存,因此它的代码需要运行在最高运行级别 Ring0上,这样它可以使用特权指令,控制中断、修改页表、访问设备等等。
- 应用程序的代码运行在最低运行级别上ring3上,不能做受控操作。如果要做,比如要访问磁盘,写文件,那就要通过执行系统调用(函数),执行系统调用的时候,CPU的运行级别会发生从ring3到ring0的切换,并跳转到系统调用对应的内核代码位置执行,这样内核就为你完成了设备访问,完成之后再从ring0返回ring3。这个过程也称作用户态和内核态的切换。

1.1 基于二进制翻译的全虚拟化(Full Virtualization with Binary Translation)

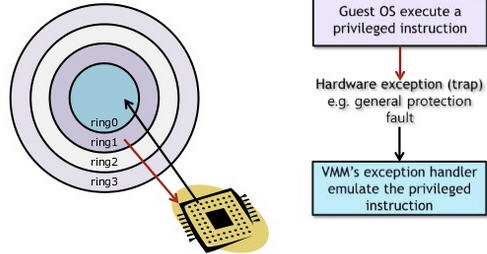
1.2. 超虚拟化(或者半虚拟化/操作系统辅助虚拟化 Paravirtualization)
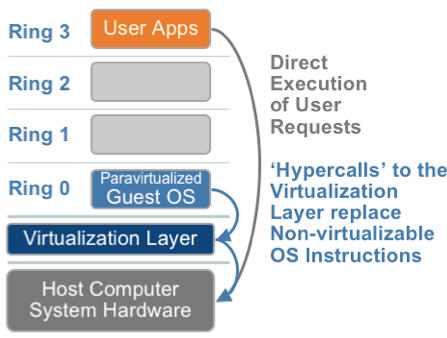
1.3. 硬件辅助的全虚拟化

(1)一个 KVM 虚机即一个Linux qemu-kvm 进程,与其他 Linux 进程一样被Linux 进程调度器调度。
(2)KVM 虚机包括虚拟内存、虚拟CPU和虚机 I/O设备,其中,内存和 CPU 的虚拟化由 KVM 内核模块负责实现,I/O 设备的虚拟化由 QEMU 负责实现。
(3)KVM户机系统的内存是 qumu-kvm 进程的地址空间的一部分。
(4)KVM 虚机的 vCPU 作为 线程运行在 qemu-kvm 进程的上下文中。
支持虚拟化的 CPU 中都增加了新的功能。以 Intel VT 技术为例,它增加了两种运行模式:VMX root 模式和 VMX nonroot 模式。通常来讲,主机操作系统和 VMM 运行在 VMX root 模式中,客户机操作系统及其应用运行在 VMX nonroot 模式中。因为两个模式都支持所有的 ring,因此,客户机可以运行在它所需要的 ring 中(OS 运行在 ring 0 中,应用运行在 ring 3 中),VMM 也运行在其需要的 ring 中 (对 KVM 来说,QEMU 运行在 ring 3,KVM 运行在 ring 0)。CPU 在两种模式之间的切换称为 VMX 切换。从 root mode 进入 nonroot mode,称为 VM entry;从 nonroot mode 进入 root mode,称为 VM exit。可见,CPU 受控制地在两种模式之间切换,轮流执行 VMM 代码和 Guest OS 代码。
对 KVM 虚机来说,运行在 VMX Root Mode 下的 VMM 在需要执行 Guest OS 指令时执行 VMLAUNCH 指令将 CPU 转换到 VMX non-root mode,开始执行客户机代码,即 VM entry 过程;在 Guest OS 需要退出该 mode 时,CPU 自动切换到 VMX Root mode,即 VM exit 过程。可见,KVM 客户机代码是受 VMM 控制直接运行在物理 CPU 上的。QEMU 只是通过 KVM 控制虚机的代码被 CPU 执行,但是它们本身并不执行其代码。也就是说,CPU 并没有真正的被虚级化成虚拟的 CPU 给客户机使用。
主机 Linux 将一个虚拟视作一个 QEMU 进程,该进程包括下面几种线程:
- I/O 线程用于管理模拟设备
- vCPU 线程用于运行 Guest 代码
- 其它线程,比如处理 event loop,offloaded tasks 等的线程
在我的测试环境中(RedHata Linux 作 Hypervisor):
| smp 设置的值 | 线程数 | 线程 |
| 4 | 8 |
1 个主线程(I/O 线程)、4 个 vCPU 线程、3 个其它线程 |
| 6 | 10 | 1 个主线程(I/O 线程)、6 个 vCPU 线程、3 个其它线程 |
要将客户机内的线程调度到某个物理 CPU,需要经历两个过程:
- 客户机线程调度到客户机物理CPU 即 KVM vCPU,该调度由客户机操作系统负责,每个客户机操作系统的实现方式不同。在 KVM 上,vCPU 在客户机系统看起来就像是物理 CPU,因此其调度方法也没有什么不同。
- vCPU 线程调度到物理 CPU 即主机物理 CPU,该调度由 Hypervisor 即 Linux 负责。
KVM 使用标准的 Linux 进程调度方法来调度 vCPU 进程。Linux 系统中,线程和进程的区别是 进程有独立的内核空间,线程是代码的执行单位,也就是调度的基本单位。Linux 中,线程是就是轻量级的进程,也就是共享了部分资源(地址空间、文件句柄、信号量等等)的进程,所以线程也按照进程的调度方式来进行调度。
我们来假设一个主机有 2 个socket,每个 socket 有 4 个core。主频2.4G MHZ 那么一共可用的资源是 2*4*2.4G= 19.2G MHZ。假设主机上运行了三个VM,VM1和VM2设置为1socket*1core,VM3设置为1socket*2core。那么VM1和VM2分别有1个vCPU,而VM3有2个vCPU。假设其他设置为缺省设置。
那么三个VM获得该主机CPU资源分配如下:VM1:25%; VM2:25%; VM3:50%
假设运行在VM3上的应用支持多线程,那么该应用可以充分利用到所非配的CPU资源。2vCPU的设置是合适的。假设运行在VM3上的应用不支持多线程,该应用根本无法同时使用利用2个vCPU. 与此同时,VMkernal层的CPU Scheduler必须等待物理层中两个空闲的pCPU,才开始资源调配来满足2个vCPU的需要。在仅有2vCPU的情况下,对该VM的性能不会有太大负面影响。但如果分配4vCPU或者更多,这种资源调度上的负担有可能会对该VM上运行的应用有很大负面影响。
确定 vCPU 数目的步骤。假如我们要创建一个VM,以下几步可以帮助确定合适的vCPU数目
1 了解应用并设置初始值
该应用是否是关键应用,是否有Service Level Agreement。一定要对运行在虚拟机上的应用是否支持多线程深入了解。咨询应用的提供商是否支持多线程和SMP(Symmetricmulti-processing)。参考该应用在物理服务器上运行时所需要的CPU个数。如果没有参照信息,可设置1vCPU作为初始值,然后密切观测资源使用情况。
2 观测资源使用情况
确定一个时间段,观测该虚拟机的资源使用情况。时间段取决于应用的特点和要求,可以是数天,甚至数周。不仅观测该VM的CPU使用率,而且观测在操作系统内该应用对CPU的占用率。特别要区分CPU使用率平均值和CPU使用率峰值。
假如分配有4个vCPU,如果在该VM上的应用的CPU
- 使用峰值等于25%, 也就是仅仅能最多使用25%的全部CPU资源,说明该应用是单线程的,仅能够使用一个vCPU (4 * 25% = 1 )
- 平均值小于38%,而峰值小于45%,考虑减少 vCPU 数目
- 平均值大于75%,而峰值大于90%,考虑增加 vCPU 数目
3 更改vCPU数目并观测结果
每次的改动尽量少,如果可能需要4vCPU,先设置2vCPU在观测性能是否可以接受。
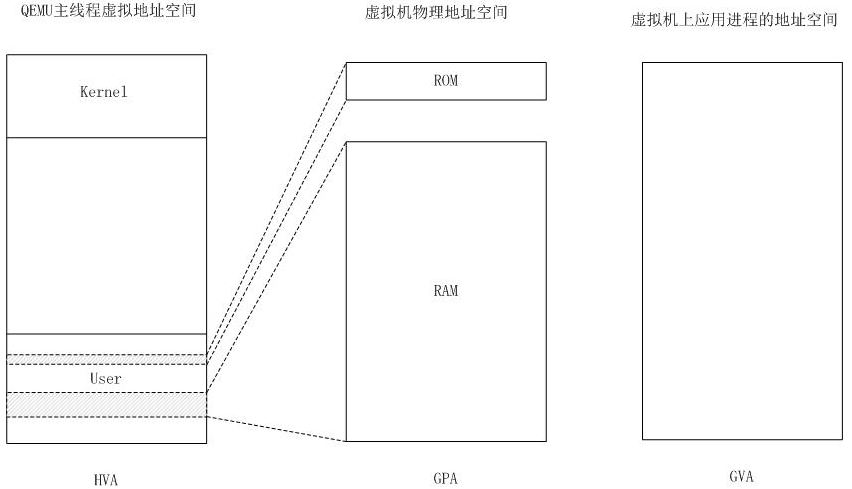
- AMD 平台上的 NPT (Nested Page Tables) 技术
- Intel 平台上的 EPT (Extended Page Tables)技术
EPT 和 NPT采用类似的原理,都是作为 CPU 中新的一层,用来将客户机的物理地址翻译为主机的物理地址。
(1)初始状态:
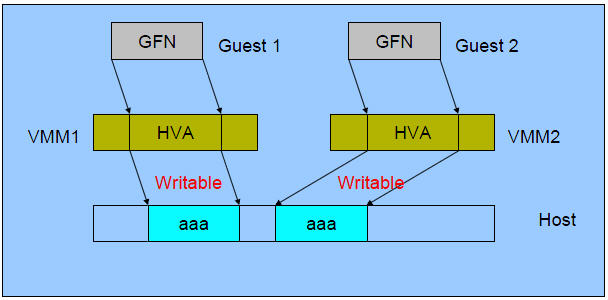
(2)合并后:
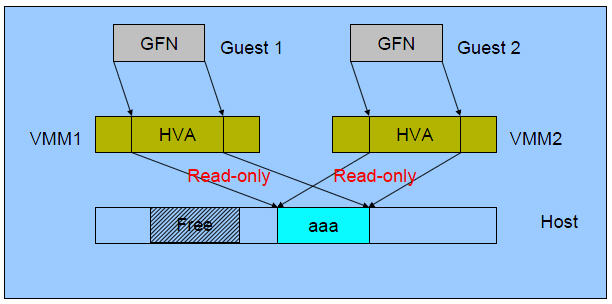
(3)Guest 1 写内存后:

Intel 的 x86 CPU 通常使用4Kb内存页,当是经过配置,也能够使用巨页(huge page): (4MB on x86_32, 2MB on x86_64 and x86_32 PAE)
使用巨页,KVM的虚拟机的页表将使用更少的内存,并且将提高CPU的效率。最高情况下,可以提高20%的效率!
大页面和透明大页面(THP)
过程 7.1. 为客机启用 1GB 大页面
-
Red Hat Enterprise Linux 7.1 系统支持 2MB 或 1GB 大页面,分配将在启动或运行时进行。页面大小均可以在运行时被释放。例如,在启动时分配 4 个 1GB 的大页面和 1,024 个 2MB 的大页面,请使用以下命令行:
'default_hugepagesz=1G hugepagesz=1G hugepages=4 hugepagesz=2M hugepages=1024'
此外,大页面还可以在运行时分配。运行时分配允许系统管理员选择从何种 NUMA 模式分配页面。然而由于内存碎片的存在,运行时的页面分配会比启动时分配更容易造成分配失败。以下运行时的分配示例显示了从node1分配 4 个 1GB 的大页面以及从node3分配 1,024 个 2MB 的大页面:# echo 4 > /sys/devices/system/node/node1/hugepages/hugepages-1048576kB/nr_hugepages # echo 1024 > /sys/devices/system/node/node3/hugepages/hugepages-2048kB/nr_hugepages
-
接下来,将 2MB 和 1GB 的大页面挂载到主机:
# mkdir /dev/hugepages1G # mount -t hugetlbfs -o pagesize=1G none /dev/hugepages1G # mkdir /dev/hugepages2M # mount -t hugetlbfs -o pagesize=2M none /dev/hugepages2M
<memoryBacking>
<hugepages/>
<page size="1" unit="G" nodeset="0-3,5"/>
<page size="2" unit="M" nodeset="4"/>
</hugepages>
</memoryBacking>
/sys/kernel/mm/transparent_hugepage/enabled 被设置为 always,透明大页面将被默认使用。运行以下命令禁用透明大页面:# echo never > /sys/kernel/mm/transparent_hugepage/enabled
例子:
使用方法,需要三部:
mkdir /dev/hugepages
mount -t hugetlbfs hugetlbfs /dev/hugepages
#保留一些内存给巨页 sysctl vm.nr_hugepages=2048 (使用 x86_64 系统时,这相当于从物理内存中保留了2048 x 2M = 4GB 的空间来给虚拟机使用)
#给 kvm 传递参数 hugepages qemu-kvm - qemu-kvm -mem-path /dev/hugepages
也可以在配置文件里加入:
<memoryBacking> <hugepages/> </memoryBacking>
验证方式,当虚拟机正常启动以后,在物理机里查看:
cat /proc/meminfo |grep -i hugepages

 浙公网安备 33010602011771号
浙公网安备 33010602011771号