
第一次个人编程作业
第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 这个作业的目标 | 设计一个论文查重算法,并练习如何对程序进行性能测试和改进 |
| 我的github账号 | https://github.com/scissssor/3223004776 |
1 PSP表格(包括预估与实际耗时)
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 20 | 15 |
| Development | 开发 | ||
| · Analysis | · 需求分析(包括学习新技术) | 90 | 120 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 | 20 | 15 |
| · Coding Standard | · 代码规范(为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 90 | 100 |
| · Coding | · 具体编码 | 120 | 180 |
| · Code Review | · 代码复审 | 30 | 45 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 90 |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | 90 | 120 |
| · Size Measurement | · 计算工作量 | 15 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结,并提出过程改进计划 | 15 | 10 |
| 合计 | 550 | 755 |
2 计算模块接口的设计与实现过程
2.1 函数关系架构
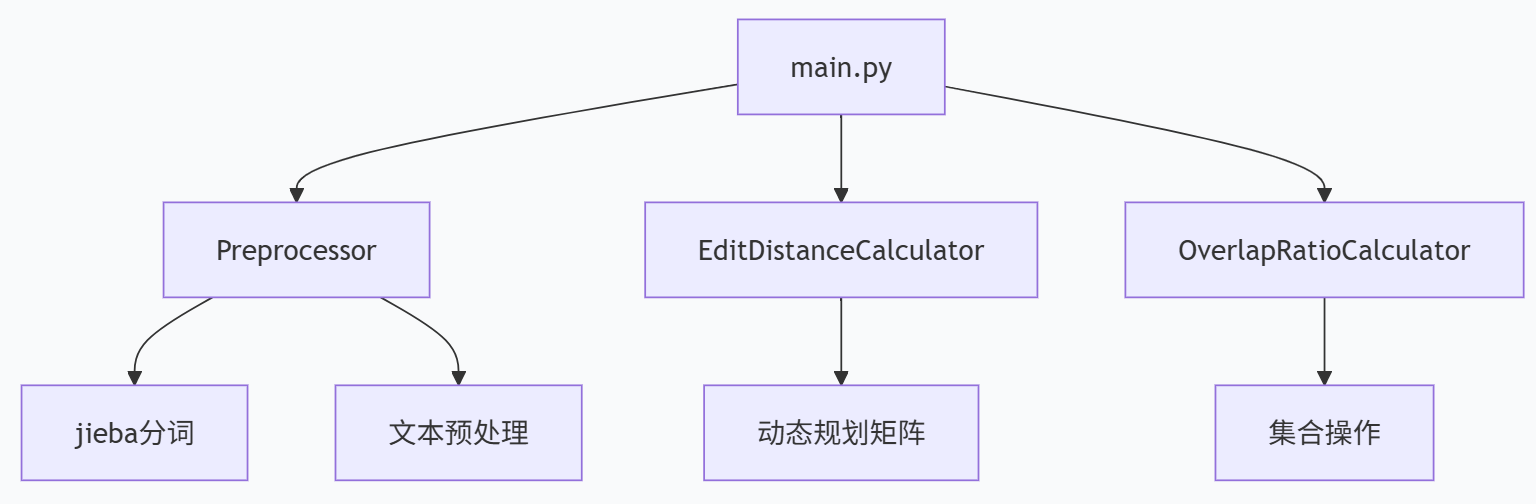
2.2 关键算法
2.2.1 编辑距离算法
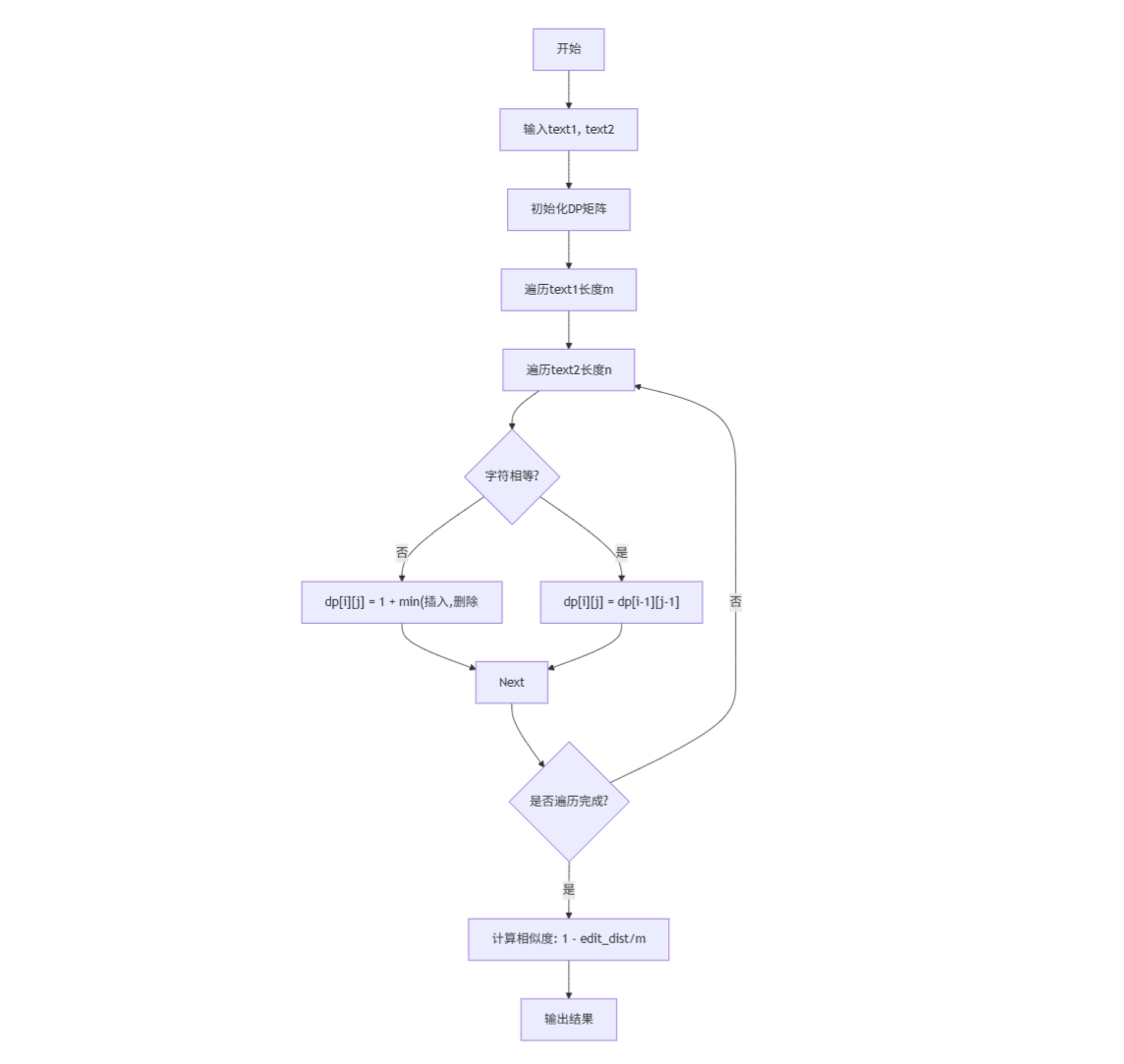
2.2.2 词汇重叠率
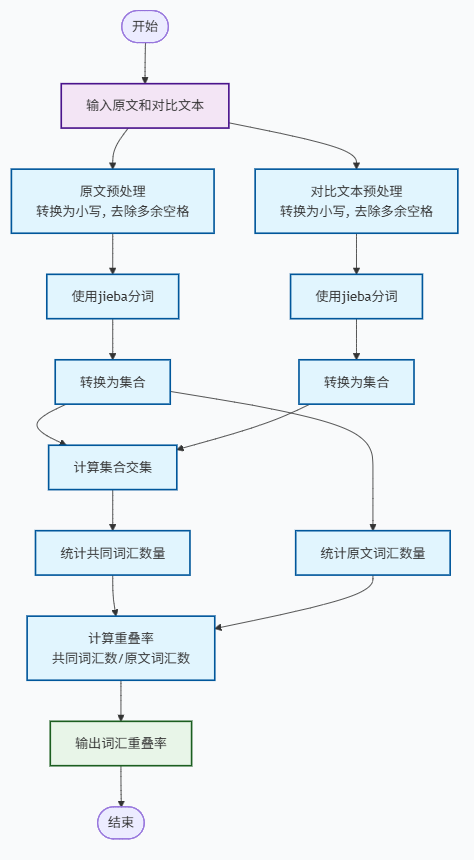
2.3 算法关键和独到之处
2.3.1 多算法融合策略
使用编辑距离相似度和词汇重叠率计算,可检测字符层面的差异和语义层面的内容重叠;利用加权计算综合重叠率,设置动态权重可后期调整
# 加权综合评估
combined_similarity = (0.5 * similarity_edit + 0.5 * similarity_overlap)
2.3.2 针对中文文本优化
采用jieba分词库进行精准分词并保留标点符号,并去除多余空格,统一大小写
# 使用jieba进行专业中文分词
orig_words = list(jieba.cut(orig_text))
3 计算模块接口部分的性能改进
初始性能分析图:

改进优化:编辑距离算法的时间复杂度为O(m×n),对于长文本非常慢。因此使用滚动数组优化时间和空间
prev = list(range(n + 1))
for i in range(1, m + 1):
curr = [0] * (n + 1)
curr[0] = i
for j in range(1, n + 1):
if text1[i - 1] == text2[j - 1]:
curr[j] = prev[j - 1]
else:
curr[j] = 1 + min(curr[j - 1], # 插入
prev[j], # 删除
prev[j - 1]) # 替换
prev = curr
edit_dist = prev[n]
return 1 - (edit_dist / max(m, n))
优化后性能分析图:

| 函数位置 | 原运行时间 | 优化后运行时间 | 原占比 | 优化后占比 | 严重程度 |
|---|---|---|---|---|---|
main.py:1(<module>) |
44.9s | 40.3s | 100% | 100% | |
main.py:62(main) |
44.5s | 39.9s | 99.17% | 99.24% | 高 |
main.py:23(edit_distance_similarity) |
43.6s | 39.8s | 97.23% | 96.86% | 高 |
_init_.py:93(initialize) |
0.339s | 0.279s | 0.76% | 0.69% | 低 |
_init_.py:289(cut) |
0.110s | 0.093s | 0.24% | 0.23% | 低 |
4 计算模块部分单元测试展示
示例:文本预处理功能模块
测试函数类:TestTextPreprocessing TestSegmentText
测试目标:验证文本预处理和分词功能
构造测试数据思路:
- 使用中文、英文和中英混合文本
- 包含连续文本和分隔文本
- 覆盖特殊文本(空格)
测试代码:
class TestTextPreprocessing:
def test_preprocess_text_basic(self):
"""测试基础文本预处理"""
text = " Hello World! "
result = preprocess_text(text)
assert result == "hello world!"
def test_preprocess_text_chinese(self):
"""测试中文文本预处理"""
text = " 作家 写作 "
result = preprocess_text(text)
assert result == "作家 写作"
def test_preprocess_text_empty(self):
"""测试空文本预处理"""
assert preprocess_text("") == ""
assert preprocess_text(" ") == ""
class TestSegmentText:
"""测试分词函数"""
def test_segment_text_basic(self):
"""测试基础分词"""
text = "我是中国人"
result = segment_text(text)
# jieba分词结果可能包含空格分隔的词汇
words = result.split()
assert "我" in words
assert "是" in words
assert "中国" in words or "中国人" in words
def test_segment_text_english(self):
"""测试中英文混合分词"""
text = "hello世界"
result = segment_text(text)
assert "hello" in result
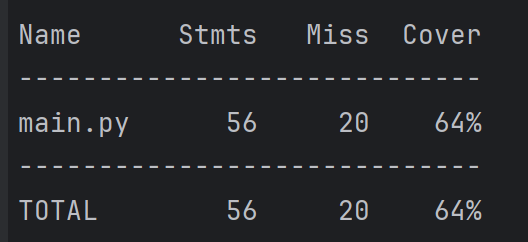
测试覆盖率图
5 计算模块部分异常处理说明
在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。
5.1 文件操作异常
设计目标:
- 处理文件不存在、路径错误、权限不足等情况
- 提供清晰的错误信息,指导用户解决问题,避免程序因文件问题而崩溃
对应场景:用户输入了错误的文件路径,或者程序没有权限读取指定文件。
def test_file_not_found(self):
"""测试文件不存在异常"""
with pytest.raises(FileNotFoundError):
read_file("/不存在的路径/不存在的文件.txt")
def test_file_permission_denied(self):
"""测试文件权限不足异常"""
# 在Windows上创建一个无权限访问的文件进行测试
if os.name == 'nt': # Windows系统
system_file = "C:\\Windows\\System32\\config\\SAM" # 系统保护文件
if os.path.exists(system_file):
with pytest.raises(PermissionError):
read_file(system_file)
5.2 编码异常
设计目标:
- 处理文件编码不匹配的情况
- 支持多种常见编码格式的自动检测
- 提供编码问题的解决方案提示
对应场景:用户提供的文本文件使用了非UTF-8编码(如GBK、GB2312等)。
def test_file_encoding_error(self):
"""测试文件编码错误异常"""
# 创建一个GBK编码的文件,但用UTF-8读取
with tempfile.NamedTemporaryFile(mode='wb', delete=False) as f:
f.write("中文内容".encode('gbk'))
temp_path = f.name
try:
# 默认使用UTF-8读取会导致编码错误
with pytest.raises(UnicodeDecodeError):
read_file(temp_path)
finally:
os.unlink(temp_path)
5.3 内存异常
设计目标:
- 处理大文件导致的内存溢出问题
- 对超长文本进行分块处理,避免内存爆炸
对应场景:用户处理非常大的文本文件(如整本书籍对比)。
def test_memory_overflow_prevention(self):
"""测试内存溢出防护机制"""
# 创建超长文本测试内存处理
huge_text1 = "A" * 1000000 # 100万字符
huge_text2 = "B" * 1000000
# 测试是否能正常处理而不内存溢出
try:
similarity = edit_distance_similarity_optimized(huge_text1, huge_text2)
assert 0.0 <= similarity <= 1.0
except MemoryError:
pytest.skip("内存不足,跳过超长文本测试")
5.4 输入验证异常
设计目标:
- 验证输入参数的合法性和类型安全性,防止无效参数导致的计算错误
- 提供清晰的参数要求说明
对应场景:程序调用者传入了错误类型的参数或空值。
def test_invalid_input_type(self):
"""测试无效输入类型异常"""
with pytest.raises(TypeError):
edit_distance_similarity(123, "文本") # 数字而不是字符串
with pytest.raises(TypeError):
word_overlap_ratio("字符串", ["列表"]) # 字符串而不是列表
def test_empty_text_handling(self):
"""测试空文本处理"""
# 空文本应该返回0相似度,而不是抛出异常
similarity = edit_distance_similarity("", "非空文本")
assert similarity == 0.0
ratio = word_overlap_ratio([], ["词汇"])
assert ratio == 0.0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号