PYTORCH 库的高级使用:从数据准备到可视化
PyTorch 是由 Facebook 开发的现代开源机器学习库。与 TensorFlow 和 Keras 等其他流行库一样,PyTorch 允许您使用视频卡的处理能力,自动计算计算图,对其进行区分和读取。但是,与以前的库不同,它具有更灵活的功能,因为它使用了动态计算图。
本文只是一个初步讲解,详细资料可参见博文深度学习之pytorch电子书百度云下载
现在我们将完成使用 PyTorch 库的所有阶段。我们不会涵盖这个库的所有功能,但它们足以开始使用它。了解如何使用数据准备工具来轻松加载数据并减少您编写的代码量。让我们创建一个简单的神经网络,以及一个训练它的类,它可以用来训练在 PyTorch 中创建的任何模型。最后,我们将结果可视化以评估训练模型的质量。
首先,让我们加载所需的库:
import torch from torch.utils.data import Dataset, DataLoader import matplotlib.pyplot as plt from sklearn.datasets import make_moons from sklearn.model_selection import train_test_split import copy import datetime as dt import pandas as pd import numpy as np
让我们使用sklearn库中的 make_moons 数据集生成器,它以新月的形式在二维空间中生成两个类。生成时添加一些噪音(噪音变量)
X, y = make_moons(n_samples=150, random_state=33, noise=0.2)
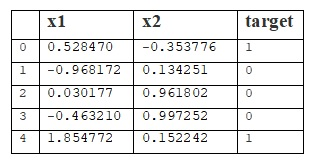
为了清楚起见,让我们将数据包装在pandas.DataFrame中:
df = pd.DataFrame(X, columns=['x1', 'x2']) df['target'] = y df.head(5)
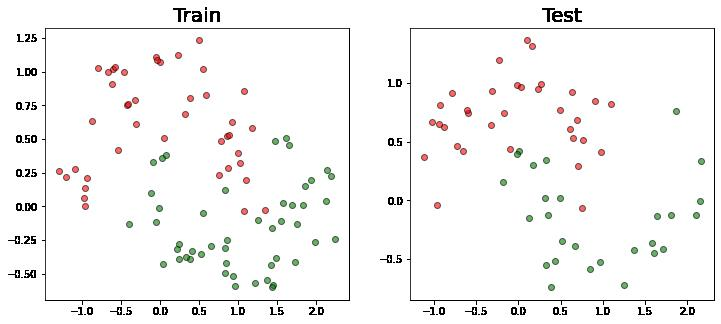
使用sklearn库中的 train_test_split 函数将数据集以 6:4 的比例划分为训练样本和测试样本
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=33)
我们将结果拆分可视化:
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12,5))
ax1.scatter(X_train[:,0][y_train == 0], X_train[:,1][y_train == 0], c='red', marker='o', edgecolors = 'black', alpha = 0.6)
ax1.scatter(X_train[:,0][y_train == 1], X_train[:,1][y_train == 1], c='green', marker = 'o', edgecolors = 'black', alpha = 0.6)
ax1.set_title('Train', fontsize=20)
ax2.scatter(X_test[:,0][y_test == 0], X_test[:,1][y_test == 0], c='red', marker='o', edgecolors = 'black', alpha = 0.6)
ax2.scatter(X_test[:,0][y_test == 1], X_test[:,1][y_test == 1], c='green', marker = 'o', edgecolors = 'black', alpha = 0.6)
ax2.set_title('Test', fontsize=20);
让我们创建MyDataset类,它继承自 torch.utils.data.Dataset 类。让我们重写 __len和 __getitem方法,以便在调用相应的方法时,我们得到样本大小和值标签对。
class MyDataset(Dataset):
def __init__(self, X, y):
self.X = torch.Tensor(X)
self.y = torch.from_numpy(y).float()
def __len__(self):
return self.X.shape[0]
def __getitem__(self, index):
return (self.X[index], self.y[index])
pytorch分布式训练原理及用法详解。让我们用三个完全连接的层来制作我们的玩具神经网络。我们将激活函数ReLU放在层与层之间,sigmoid放在第三层,第一层将取x1和x2作为输入,输出给出50个值。第二个将从第一层取 50 个值,并将 50 个值提供给第三层。并且第三层已经将这 50 个值在 0 到 1 的范围内压缩为 1(这将是将观察分类为“1”的概率)。
import torch.nn as nn
ReLU = nn.ReLU()
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(2, 50)
self.fc2 = nn.Linear(50, 50)
self.fc3 = nn.Linear(50, 1)
def forward(self, x):
x = ReLU(self.fc1(x))
x = ReLU(self.fc2(x))
x = torch.sigmoid(self.fc3(x))
return x.view(-1)
让我们创建一个神经网络实例并显示其结构。我们将看到层数、每层的输入和输出参数的数量以及截距的存在/不存在。
net = Net() print(net)
Net( (fc1): Linear(in_features=2, out_features=50, bias=True) (fc2): Linear(in_features=50, out_features=50, bias=True) (fc3): Linear(in_features=50, out_features=1, bias=True) )
现在让我们创建一个类似于在sklearn库中实现的模型的类。它将预处理数据,训练我们的神经网络,记住训练进度并保存最成功的尝试。所有参数的描述都在类中。
In [9]:
class Trainer():
"""
Parameters:
dataset: пользовательский класс, предобрабатывающий данные
loss_f: функция потерь
learning_rate: величина градиентного шага
epoch_amount: общее количество эпох
batch_size: размер одного бача
max_batches_per_epoch: максимальное количество бачей,
подаваемых в модель в одну эпоху
device: устройство для вычислений
early_stopping: количество эпох без улучшений до остановки обучения
optim: оптимизатор
scheduler: регулятор градиентного шага
permutate: перемешивание тренировочной выборки перед обучением
Attributes:
start_model: необученная модель
best_model: модель, после обучения
train_loss: средние значения функции потерь на тренировочных
данных в каждой эпохе
val_loss: средние значения функции потерь на валидационных
данных в каждой эпохе
Methods:
fit: обучение модели
predict: возвращает предсказание обученной моделью
"""
def __init__(self, dataset, net, loss_f, learning_rate=1e-3,
epoch_amount=10, batch_size=12,
max_batches_per_epoch=None,
device='cpu', early_stopping=10,
optim=torch.optim.Adam,
scheduler=None, permutate=True):
self.loss_f = loss_f
self.learning_rate = learning_rate
self.epoch_amount = epoch_amount
self.batch_size = batch_size
self.max_batches_per_epoch = max_batches_per_epoch
self.device = device
self.early_stopping = early_stopping
self.optim = optim
self.scheduler = scheduler
self.permutate = permutate
self.dataset = dataset
self.start_model = net
self.best_model = net
self.train_loss = []
self.val_loss = []
def predict(self, X):
return self.best_model(X)
def fit(self, X_train, X_test, y_train, y_test):
Net = self.start_model
device = torch.device(self.device)
Net.to(self.device)
optimizer = self.optim(Net.parameters(), lr=self.learning_rate)
if self.scheduler is not None:
scheduler = self.scheduler(optimizer)
train = self.dataset(X_train, y_train)
val = self.dataset(X_test, y_test)
train = DataLoader(train, batch_size=self.batch_size, shuffle=self.permutate)
val = DataLoader(val, batch_size=self.batch_size, shuffle=False)
best_val_loss = float('inf') # Лучшее значение функции потерь на валидационной выборке
# функции потерь на валидационной выборке
best_ep = 0 # Эпоха, на которой достигалось лучшее
# значение функции потерь на валидационной выборке
for epoch in range(self.epoch_amount):
start = dt.datetime.now()
print(f'Эпоха: {epoch}', end=' ')
Net.train()
mean_loss = 0
batch_n = 0
for batch_X, target in train:
if self.max_batches_per_epoch is not None:
if batch_n >= self.max_batches_per_epoch:
break
optimizer.zero_grad()
batch_X = batch_X.to(self.device)
target = target.to(self.device)
predicted_values = Net(batch_X)
loss = self.loss_f(predicted_values, target)
loss.backward()
optimizer.step()
mean_loss += float(loss)
batch_n += 1
mean_loss /= batch_n
self.train_loss.append(mean_loss)
print(f'Loss_train: {mean_loss}, {dt.datetime.now() - start} сек')
Net.eval()
mean_loss = 0
batch_n = 0
with torch.no_grad():
for batch_X, target in val:
if self.max_batches_per_epoch is not None:
if batch_n >= self.max_batches_per_epoch:
break
batch_X = batch_X.to(self.device)
target = target.to(self.device)
predicted_values = Net(batch_X)
loss = self.loss_f(predicted_values, target)
mean_loss += float(loss)
batch_n += 1
mean_loss /= batch_n
self.val_loss.append(mean_loss)
print(f'Loss_val: {mean_loss}')
if mean_loss < best_val_loss:
self.best_model = Net
best_val_loss = mean_loss
best_ep = epoch
elif epoch - best_ep > self.early_stopping:
print(f'{self.early_stopping} без улучшений. Прекращаем обучение...')
break
if self.scheduler is not None:
scheduler.step()
print()
首先,我们将模型的所有训练参数写入 __init__ 方法内的类属性。我们还初始化了两个属性 train_loss 和 val_loss,我们将在训练集和验证集上写入损失函数的值。
然后我们创建一个预测方法来方便地使用训练好的模型。之后,我们创建一个拟合方法来训练我们的模型。在入口处,它将接收用于训练和验证的数据。在其中,我们将模型放置在我们将要执行计算的设备上('cpu' - 用于处理器或'cuda: *',其中 * 是您的显卡编号。这些是最常见的设备可能是其他人)。
接下来,我们指定 torch.optim 优化器,它将采用梯度步骤。如果用户没有选择任何东西,torch.optim.Adam 将被使用。此外,用户可以在训练期间使用 torch.optim.lr_scheduler 配置梯度步长的变化,但这不是必需的。
之后,我们将训练和验证样本的数据放入我们之前创建的类(在我们的例子中,它是 MyDataset)。
然后我们将我们准备好的数据提交给 torch.utils.data.DataLoader,表明批量的大小(一次将有多少数据输入模型)。torch.utils.data.DataLoader 和 torch.Tensor 类 torch.utils.data.Dataset(我们从中继承了 MyDataset 类)用于简化和加快数据加载并节省内存。
准备好数据并创建必要的变量后,我们开始训练过程。为此,我们将模型转移到训练模式。在这种状态下,各种正则化方法将起作用(批量归一化、dropout 等)。在我们的示例中,为简单起见,我们没有向我们的模型添加任何正则化方法。
在第二个循环中,我们迭代 train_dataloader 迭代器提供给我们的批次。我们将每个批次移动到我们在开始时选择的设备。接下来,我们在优化器处重置梯度。在 PyTorch 中,默认情况下,每次迭代后梯度都会累积。之后,我们做了三个主要的动作:我们直接通过神经网络,计算损失函数的值,并在此基础上进行梯度步骤。我们推导出训练样本上损失函数的值以及一个时期内训练所花费的时间。
然后我们在验证集上计算损失函数的值。为此,我们将模型置于 eval 模式并关闭梯度计算。之后,我们做与训练期间相同的事情,但没有梯度步骤。损失函数的结果也显示在屏幕上。如果验证集上的损失函数结果比原来好,那么我们将当前模型保存到变量 best_model 中。
所有这些步骤都重复我们在 epoch_amount 中指定的次数,或者直到验证样本上的损失函数值停止变化(如果指定了 early_stopping 参数)。
在输出中,我们得到一个在验证集上表现最好的模型、这个模型上的损失函数值,以及在训练和验证数据训练期间损失函数值的两个列表。
现在是时候在我们的数据集上试用这个类了。我们将选择二元交叉熵torch.nn.BCELoss作为损失函数,并选择随机梯度下降torch.optim.SGD作为优化器。
让我们将所有选定的参数写入字典并将其提供给 fit 方法。
params = {
'dataset': MyDataset,
'net': net,
'epoch_amount': 1000,
'learning_rate': 1e-2,
'early_stopping': 25,
'loss_f': nn.BCELoss(),
'optim': torch.optim.SGD,
}
clf = Trainer(**params)
clf.fit(X_train, X_test, y_train, y_test)
剩下的就是将结果可视化。
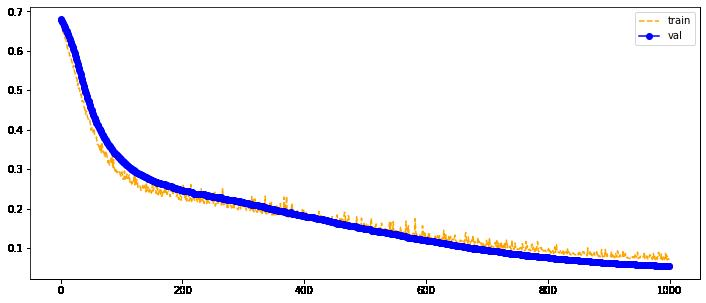
让我们构建一张训练和验证样本上的损失函数值随 epoch 数变化的图。
def plot_loss(Loss_train, Loss_val):
plt.figure(figsize=(12, 5))
plt.plot(range(len(Loss_train)), Loss_train, color='orange', label='train', linestyle='--')
plt.plot(range(len(Loss_val)), Loss_val, color='blue', marker='o', label='val')
plt.legend()
plt.show()
plot_loss(clf.train_loss, clf.val_loss)
我们可视化分离的边界。
def make_meshgrid(x1, x2, h=.02):
x1_min, x1_max = x1.min() - 2, x1.max() + 2
x2_min, x2_max = x2.min() - 2, x2.max() + 2
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, h), np.arange(x2_min, x2_max, h))
return xx1, xx2
def plot_contours(ax, xx1, xx2, **params):
C = clf.predict(torch.Tensor(np.c_[xx1.ravel(), xx2.ravel()])).detach().numpy()
C = C.reshape(xx1.shape)
out = ax.contourf(xx1, xx2, C, **params)
return out
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12,5))
xx1, xx2 = make_meshgrid(X[0], X[1])
ax1.scatter(X_train[:,0][y_train == 0], X_train[:,1][y_train == 0], c='red', marker='o', edgecolors = 'black', alpha = 0.6)
ax1.scatter(X_train[:,0][y_train == 1], X_train[:,1][y_train == 1], c='green', marker = 'o', edgecolors = 'black', alpha = 0.6)
ax1.set_title('Train', fontsize=20)
plot_contours(ax1, xx1, xx2, alpha=0.2)
ax2.scatter(X_test[:,0][y_test == 0], X_test[:,1][y_test == 0], c='red', marker='o', edgecolors = 'black', alpha = 0.6)
ax2.scatter(X_test[:,0][y_test == 1], X_test[:,1][y_test == 1], c='green', marker = 'o', edgecolors = 'black', alpha = 0.6)
ax2.set_title('Test', fontsize=20)
plot_contours(ax2, xx1, xx2, alpha=0.2);
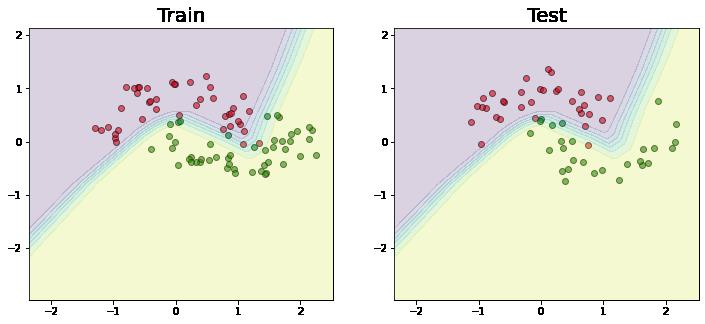
遇到“1”类中的点的概率最大的区域以黄色显示。因此,对于来自“0”类的点,红色区域中的概率最大。正如我们所看到的,分离边界结果是非线性的,因为 非线性激活函数用于神经网络。
更深入的介绍,参见《pytorch反卷积原理及函数用法介绍》。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号