



猿人学web端爬虫攻防大赛赛题第20题——2022新春快乐
题目网址:https://match.yuanrenxue.cn/match/20
解题步骤
解题之前需要先了解wasm是什么:https://docs.pingcode.com/ask/294587.html
- 看数据包。
![image]()
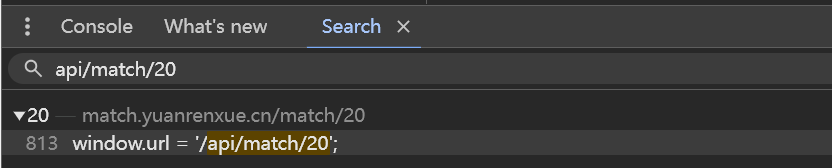
sign是一串加密的字符串,t一看就是时间戳。全局搜索api/match/20,只有一处。
![image]()
- 打断点,触发。
![image]()
- 看下
sign的生成逻辑。
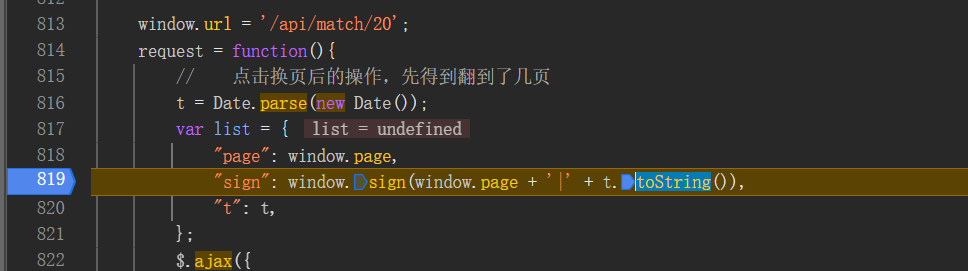
"sign": window.sign(window.page + '|' + t.toString())
window.page:当前的页码
t:时间戳
window.sign:一个函数,主要关键点。
找到定位,打断点,让断点运行到此处。
![image]()
可以看到传进来的content就是页码和时间戳拼接的内容。
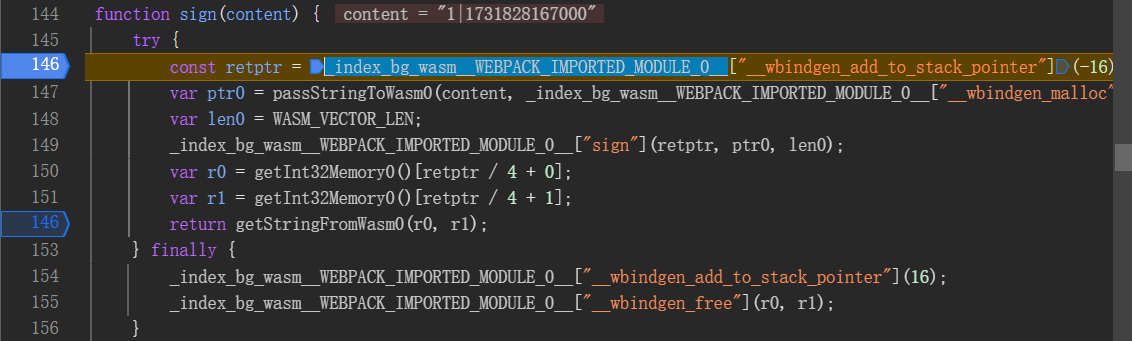
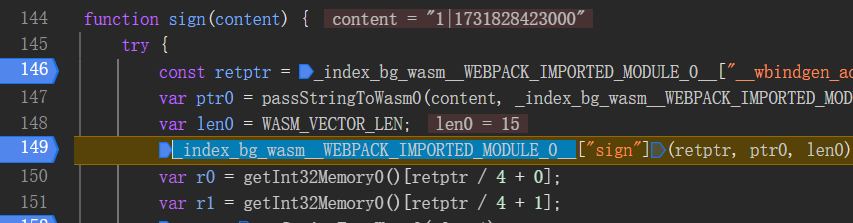
方法调用的名字确实长,靠经验关键函数是_index_bg_wasm__WEBPACK_IMPORTED_MODULE_0__["sign"],不过这个函数有3个传参。retptr
const retptr = _index_bg_wasm__WEBPACK_IMPORTED_MODULE_0__["__wbindgen_add_to_stack_pointer"](-16);
先跟进_index_bg_wasm__WEBPACK_IMPORTED_MODULE_0__["__wbindgen_add_to_stack_pointer"]
![image]()
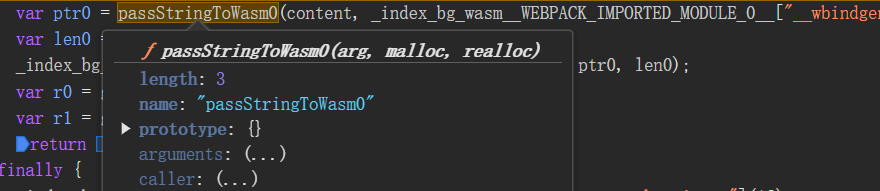
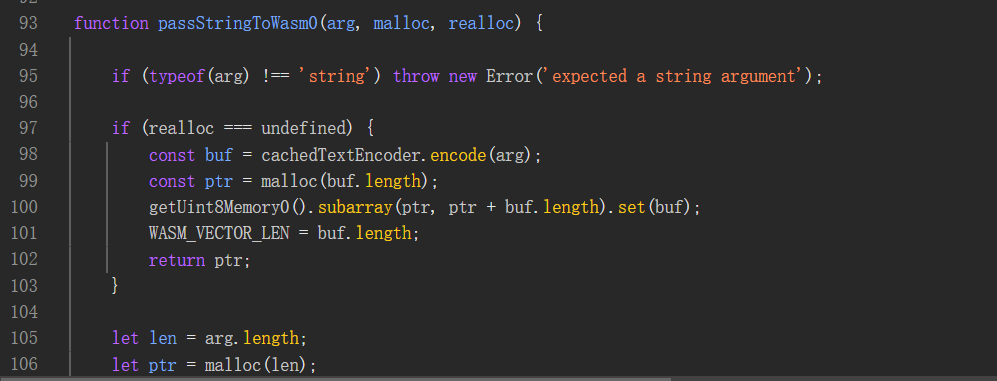
ptr0
var ptr0 = passStringToWasm0(content, _index_bg_wasm__WEBPACK_IMPORTED_MODULE_0__["__wbindgen_malloc"], _index_bg_wasm__WEBPACK_IMPORTED_MODULE_0__["__wbindgen_realloc"]);
主要涉及arg、malloc、realloc三个参数
![image]()
![image]()
len0:值为15
![image]()
经分析,retptr 为指针地址,ptr0 为内存地址
- 重点看
_index_bg_wasm__WEBPACK_IMPORTED_MODULE_0__["sign"],打断点。
![image]()
![image]()
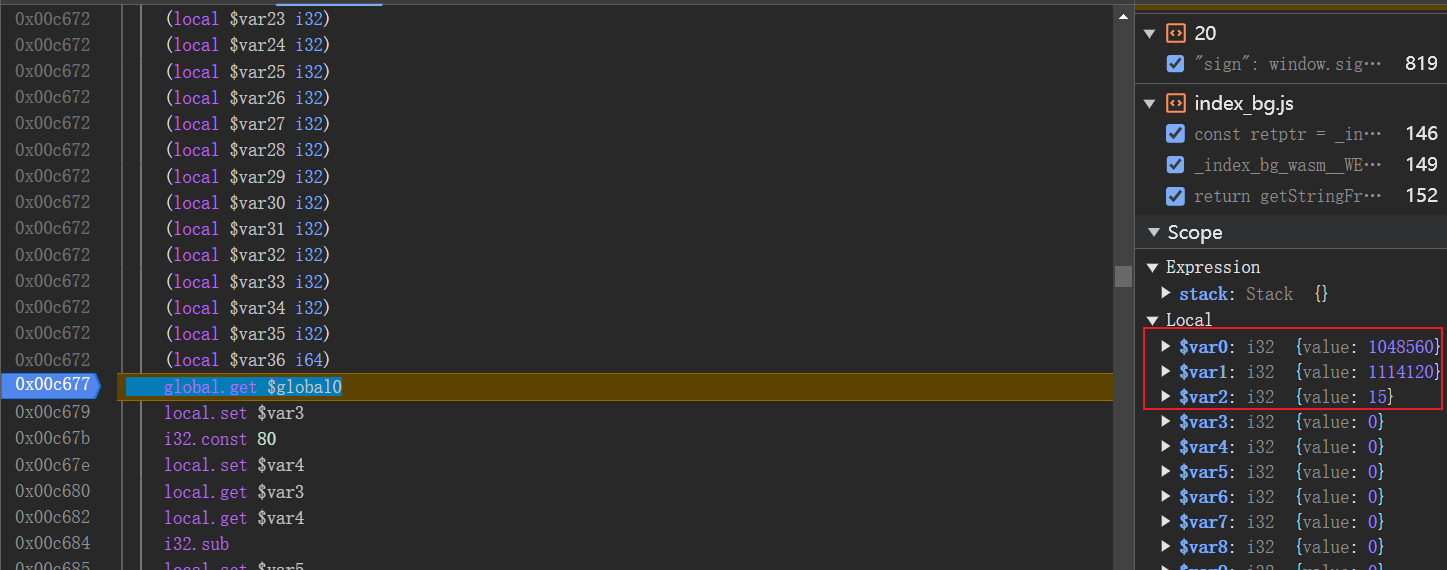
主要传了$var0、$var1、$var2三个参数,重点看这三个变量的值,运行进来。
![image]()
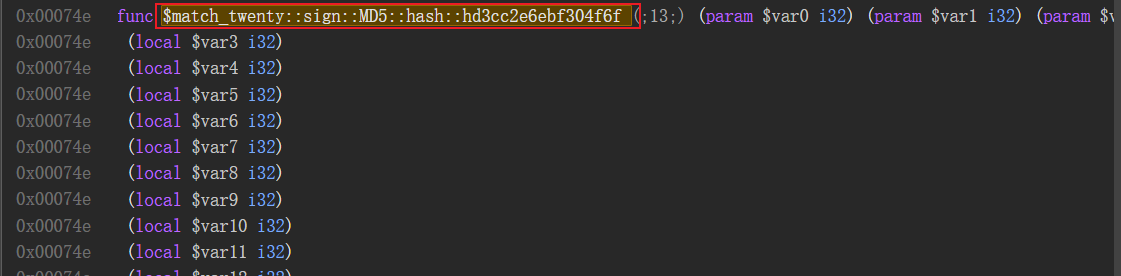
在其余包含有sign关键字的语句也打上断点,释放断点,看会进入哪一个。最终进入$match_twenty::sign::MD5::hash::hd3cc2e6ebf304f6f。
![image]()
![image]()
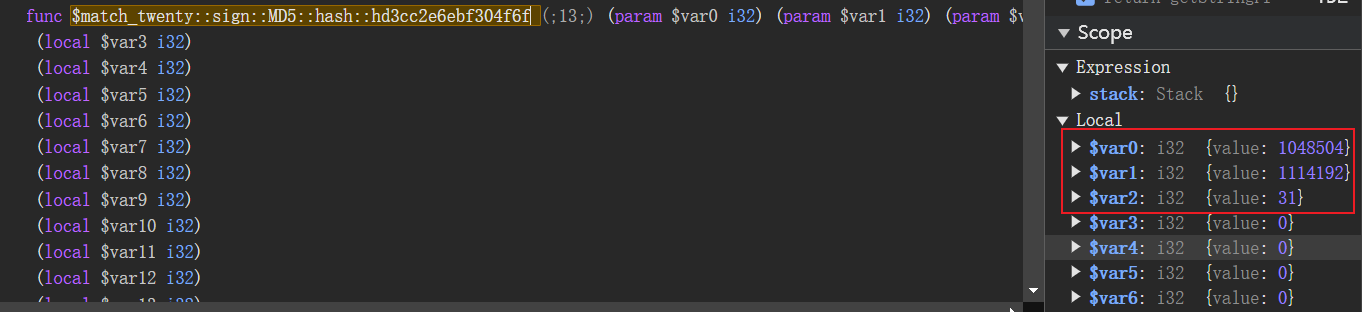
再看$var0、$var1、$var2三个参数的值。
![image]()
长度$var2由15变成了31,说明在这个函数中进行了加密。$var1变成了1114192。
继续释放断点,跳不过的就取消断点,最后回到了getStringFromWasm0函数。
![image]()
- 此时将
$var1、$var2值传入getStringFromWasm0函数,在控制台输出。
![image]()
明文,并且在明文后面加了盐D#uqGdcw41pWeNXm。 - 再结合加密函数的名字为MD5,尝试对明文进行MD5加密。
![image]()
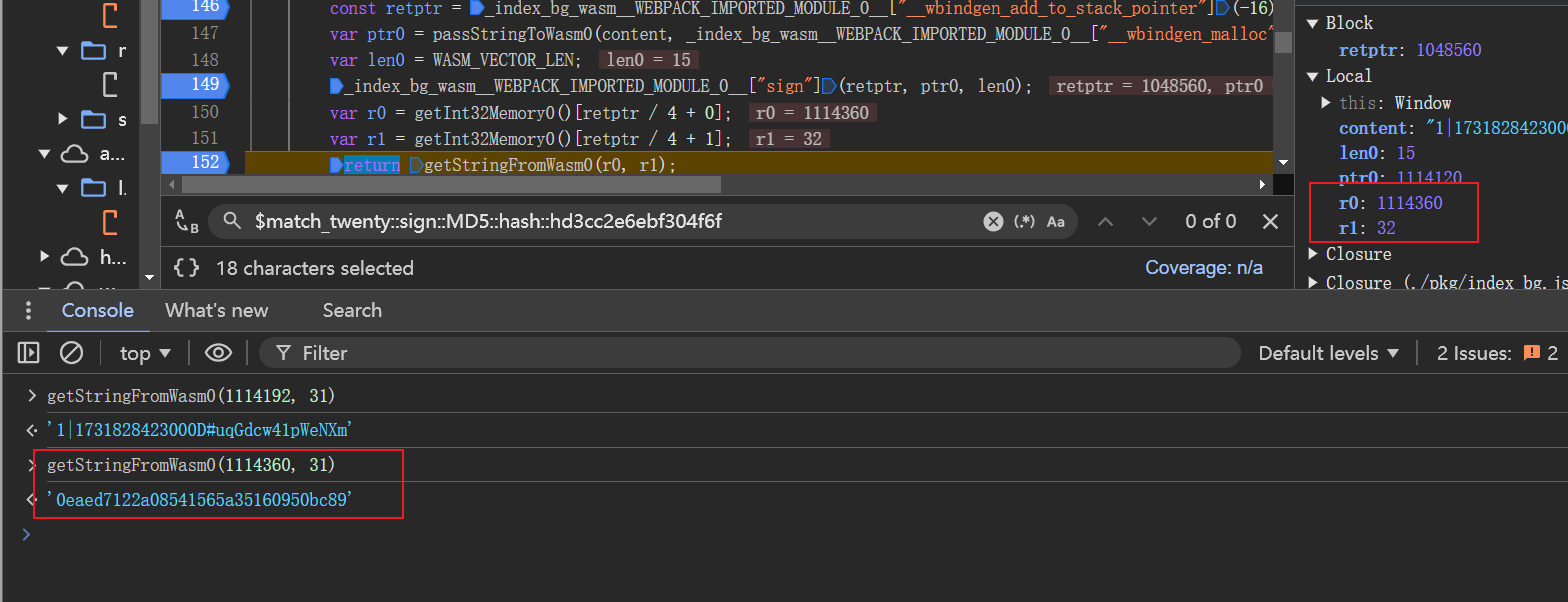
再将得到的r0和r1传入getStringFromWasm0函数,在控制台输出。
![image]()
发现跟我们MD5加密的结果一致, 所以这是个加盐的MD5加密。 - 开始编写python代码了。
运行得到结果。import requests import time import hashlib import re pattern = '{"value": (?P<num>.*?)}' num_sum = 0 headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36"} cookies = {"sessionid": "xxxxx"} for i in range(1, 6): t = str(int(time.time()) * 1000) ming = str(i) + "|" + t + "D#uqGdcw41pWeNXm" sign = hashlib.md5(ming.encode()).hexdigest() url = "https://match.yuanrenxue.cn/api/match/20?page={}&sign={}&t={}".format(i, sign, t) resp = requests.get(url, headers=headers, cookies=cookies) content = resp.text findall = re.findall(pattern, content) for item in findall: num_sum += int(item) print(num_sum)
![image]()
- 提交,成功通过。
![image]()










 浙公网安备 33010602011771号
浙公网安备 33010602011771号