【大模型】【扫盲】几种不同的微调方法
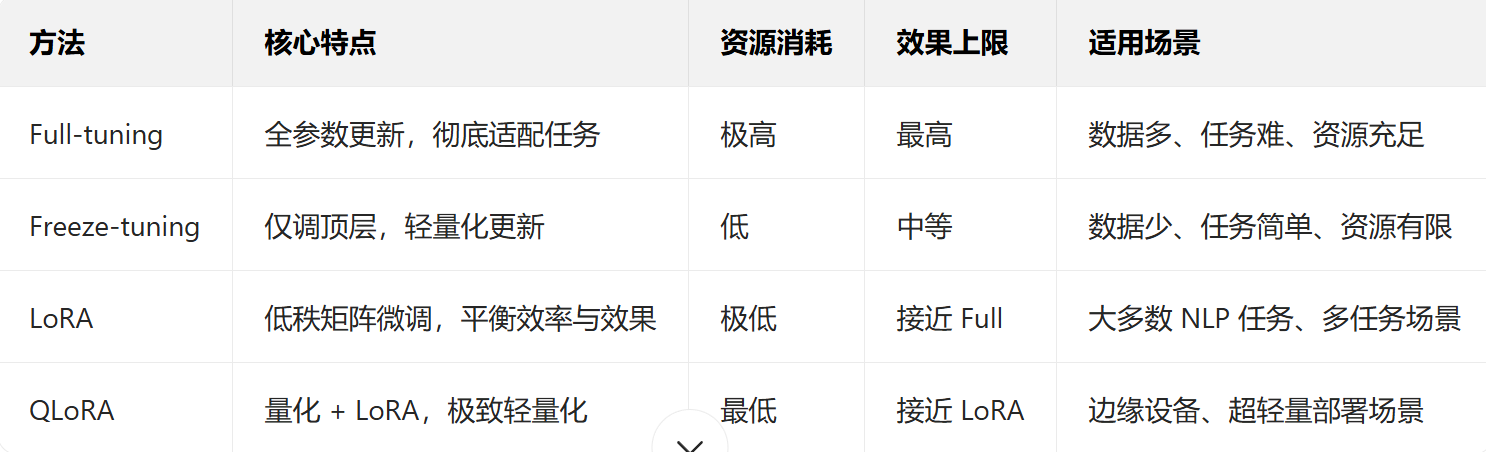
四种微调方式
Full
对预训练模型的所有参数进行微调,让模型从底层到顶层的所有参数都参与更新,彻底适配下游任务
优点:模型对任务的适配性最强,在数据充足、任务复杂时效果通常最优
缺点:
资源消耗极大(千亿参数模型需高端 GPU 集群,训练时长以天 / 周计);
数据量不足时极易过拟合(模型死记训练数据,泛化能力差)
适用于数据量大,复杂度高,计算资源充足的情景
Freeze
仅微调模型的部分参数(通常是 “顶层” 或新增的任务专属层,如分类头、输出层),冻结大部分底层参数(保留预训练阶段学到的通用知识)
适用于数据量少,任务简单,计算资源有限的场景
LoRA Low-Rank Adaptation
不直接修改预训练模型的原始参数,而是在模型的关键层(如注意力层、前馈网络层)
插入低秩矩阵对(可理解为 “小配件”),仅微调这组低秩矩阵,原始模型参数保持冻结
在微调过程中,原始参数全程不更新
优点:训练速度极快、显存消耗极低;效果接近全量微调,且能完美保留原模型知识;支持多任务共享大模型
缺点:
若任务需要 “深度改造” 模型(如极小众领域的知识注入),低秩矩阵可能无法完全捕捉复杂规律,效果略逊于全量微调;
依赖 “低秩假设”,若任务与预训练任务差异过大,适配性会下降
适用于纯文本的任务,多任务场景,边缘设备部署等场景
QLoRA(Quantized LoRA,量化低秩适应)
是 LoRA 的升级版:
先对预训练模型进行量化压缩(如 4 位量化,将浮点数参数转为低精度整数),
再在量化后的模型上应用 LoRA 方法,仅微调新增的低秩矩阵
适合用在资源极其紧张的场景
番外:oft
OFT(Optimized Fine-Tuning,优化微调)是针对视觉-语言-动作模型(VLA,Visual-Language-Action models)的专项微调方案,核心是解决VLA在机器人等场景下微调的效率与可靠性问题,具体特点如下:
1. 背景:传统VLA微调的痛点
VLA需适配不同机器人(硬件配置、动作空间差异大)或新任务(如从物体抓取到复杂组装),但传统微调方法存在缺陷:
- 速度慢:如LoRA等方法采用自回归动作生成,速度仅3 - 5Hz,无法满足机器人高频控制(25 - 50+Hz)需求(如双手机器人快速操作)。
- 复杂任务执行不可靠:自回归VLA在双手机器人协同任务(如折叠衣物)中,动作协调性、精准度不足,易导致任务失败。
2. OFT的核心优化设计
OFT通过多技术组合,针对性解决上述问题:
- 并行解码+动作分块:摒弃自回归生成,改用“并行解码”(单次前向传递生成所有动作),结合“动作分块”(一次预测多个未来时间步的动作),大幅提升推理效率(如在实验中,比基线OpenVLA吞吐量提升26倍)。
- 连续动作表示:用“连续值”替代传统“离散动作表示”,直接建模动作分布,避免离散化导致的细节损失,提升动作预测精度(如在LIBERO基准中,连续动作比离散动作成功率高5%)。
- L1回归学习目标:采用L1回归(最小化预测动作与真实动作的平均L1差异),相比扩散模型等方法,训练收敛更快、推理速度更高,且性能相当。
- 语言增强(可选,如FiLM模块):将语言嵌入融入视觉表示(如用任务描述的语言嵌入生成缩放/偏移向量,对视觉特征做仿射变换),提升模型对语言指令的跟随能力(解决多视角视觉输入下“听不懂语言指令”的问题)。
3. 适用场景与价值
OFT专为机器人等需“视觉-语言-动作协同”的场景设计,能让VLA更高效、精准地适配新机器人(如不同硬件配置的双手机器人)或新任务(如复杂组装、高频操作),在保证任务性能的同时,大幅提升推理效率与可靠性。
简单来说,OFT是一套“为VLA量身定制的优化微调方案”,通过技术组合突破传统微调在机器人场景的瓶颈。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号