Spark的配置和WordCount案例
Spark的配置和WordCount案例
目录
Spark运行模式:
(1)Local:多用于测试
(2)Standalone:独立集群(通常不用)
(3)Mesos:(通常不用)
(4)YARN:最具前景(管理内存的CPU)
(5)k8s:虚拟化模型
一、spark的配置
1、在spark的pom.xml中导入依赖、插件
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.5</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- Scala Compiler -->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
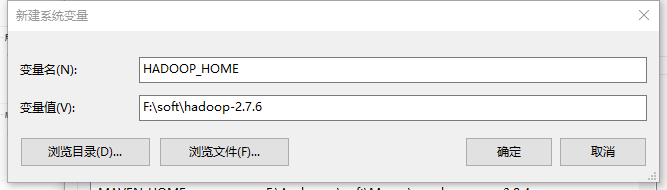
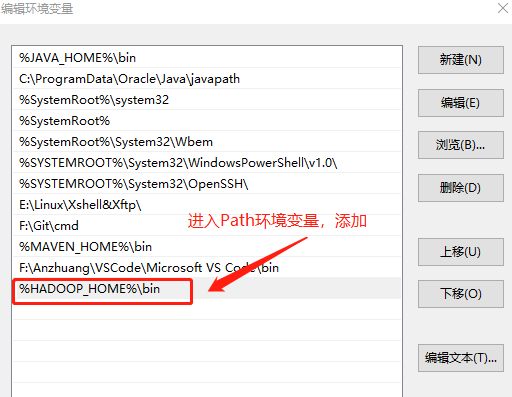
2、配置本地环境变量
-
将
hadoop-2.7.6.tar.gz随便找个目录解压一下,解压后的目录为hadoop-2.7.6 -
将工具
winutils.exe放入到hadoop-2.7.6/bin目录内 -
复制目录
hadoop-2.7.6的路径,例F:\soft\hadoop-2.7.6 -
找到电脑的
高级系统设置,配置环境变量![]()
2、编写spark代码的固定格式
package com.shujia.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo1WordCount {
def main(args: Array[String]): Unit = {
/**
* 1、创建Spark上下文环境
* SparkContext是spark代码的入口
*/
//1、spark配置文件对象
val conf = new SparkConf()
//2、指定任务名(一般填写类的名字)
conf.setAppName("Demo1WordCount")
//3、指定运行模式(local:本地运行)
conf.setMaster("local")
//4、创建上下文对象
val sc = new SparkContext(conf)
/**
* 2、读取文件(通过上下文对象名)
*/
val linesRDD: RDD[String] = sc.textFile("data/words.txt")
/**
* 3、编写逻辑
*/
/**
* 4、保存数据
* 指定的路径是一个目录,里面文件的数量和reduce的数量有关(和mr一样)
* resultRDD.saveAsTextFile("data/word_count")
*/
}
}
3、Spark----WordCount案例
注意:
1、SparkContext是spark代码的入口
2、读取文件:读取hdfs中的文件
3、RDD: 弹性的分布式数据集 -- 可以理解为一个分布式的List集合
4、统计单词的数量: flatMap: 算子,返回一个新的RDD
5、groupBy: 按照指定的key分组: -- 在执行的底层会产生shuffle
6、迭代器和集合的区别:
(1)迭代器只能遍历一次
(2)迭代器的数据没有完全在内存中,集合的数据完全保存在内存中
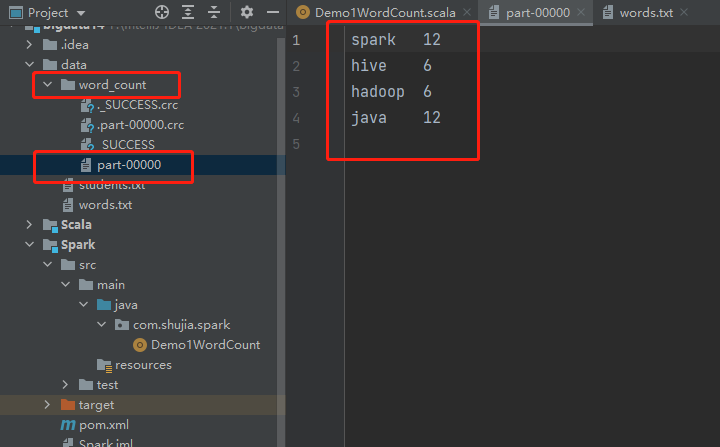
7、保存数据:指定的路径是一个目录,里面文件的数量和reduce的数量有关(和mr一样)
package com.shujia.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo1WordCount {
def main(args: Array[String]): Unit = {
/**
* 1、创建Spark上下文环境
* SparkContext是spark代码的入口
*/
//1、spark配置文件对象
val conf = new SparkConf()
//2、指定任务名(一般填写类的名字)
conf.setAppName("Demo1WordCount")
//3、指定运行模式(local:本地运行)
conf.setMaster("local")
//4、创建上下文对象
val sc = new SparkContext(conf)
/**
* 2、读取文件(通过上下文对象名)
*/
val linesRDD: RDD[String] = sc.textFile("data/words.txt")
/**
* 3、需求:统计单词的数量
*/
//1、将一行拆分成多行:flatMap
val wordsRDD: RDD[String] = linesRDD.flatMap(line => line.split(","))
//2、按照单词分组:groupBy
val groupRDD: RDD[(String, Iterable[String])] = wordsRDD.groupBy(word => word)
//3、统计单词的数量:map
val countRDD = groupRDD.map {
case (word:String,words:Iterable[String])=>
//统计迭代器中单词的数量<=>迭代器的长度
val count: Int = words.size
//返回数据
(word,count)
}
//4、整理数据,使结果展现出来更好看一些(接收一下)
val resultRDD = countRDD.map{
case (word:String,count:Int) =>
s"$word\t$count"
}
/**
* 4、保存数据
* 指定的路径是一个目录,里面文件的数量和reduce的数量有关(和mr一样)
*/
resultRDD.saveAsTextFile("data/word_count")
//会在data目录中,生成一个子目录word_count,运行结果在part-00000中
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号