

统一监控报警平台架构设计思路
谈到运维,监控应该是运维的重中之重。怎么说呢?有很多人说这个监控应该是运维的第三只眼睛,一个好的监控平台对我们这个工作本身来说,应该有很大的帮助。那么,如何要构建一个完善的监控平台。那就是我们今天要讨论的话题:
以我的理解来说这个运维的核心工作其实是监控和故障处理。两个方面的工作首先是对这个业务系统我们要有一个精确的完善的监控。那么他的目的就是能够保证在第一时间去发现问题并且去通知相关人员解决问题。其实出现问题了并不可怕,可怕的是我们很久没有发现问题,那么最终被客户发现我们的业务系统出现故障,那么就是个很严重的问题了,这些都是靠业务系统监控平台来完成的。
提纲介绍:
1、统一监控报警平台设计思路
2、Ganglia作为数据收集模块
3、Centreon作为监控报警模块
4、Ganglia与Centreon的无缝整合
5、统计监控系统架构图
6、数据流向图
第一:统一监控报警平台设计思路
构建一个智能的运维监控平台,必须以运行监控和故障报警这两个方面为重点,将所有业务系统中所涉及的网络资源、硬件资源、软件资源、数据库资源等纳入统一的运维监控平台中,并通过消除管理软件的差别,数据采集手段的差别,对各种不同的数据来源实现统一管理、统一规范、统一处理、统一展现、统一用户登录、统一权限控制,最终实现运维规范化、自动化、智能化的大运维管理。
智能的运维监控平台,设计架构从低到高可以分为6层,三大模块,如图1所示:
数据收集层:位于最底层,主要收集网络数据、业务系统数据、数据库数据、操作系统数据等,然后将收集到的数据进行规范化,并进行存储。
数据展示层:位于第二层,是一个web展示界面,主要是将数据收集层获取到的数据进行统一展示,展示的方式可以是曲线图、柱状图、饼状态等,通过将数据图形化,可以帮助运维人员了解一段时间内主机或网络的运行状态和运行趋势,并作为运维人员排查问题或解决问题的依据。
数据提取层:位于第三层,主要是将数据收集层获取到的数据进行规格化和过滤处理,提取需要的数据到监控报警模块,这个部分是监控和报警两个模块的衔接点。
报警规则配置层:位于第四层,主要是根据第三层获取到的数据进行报警规则设置、报警阀值设置、报警联系人设置和报警方式设置等。
报警事件生成层:位于第五层,主要是将报警事件进行实时记录,并将报警结果存入数据库以备调用,并将报警结果形成分析报表,以统计一段时间内的故障率和故障发生趋势。
用户展示管理层:位于最顶层,是一个web展示界面,主要是将监控统计结果、报警故障结果进行统一展示,并实现多用户、多权限管理,实现统一用户和统一权限控制。
在这6层中,从功能实现划分,又分为三个模块,分别是数据收集模块、数据提取模块和监控报警模块,每个模块完成的功能如下:
数据收集模块:此模块主要完成基础数据的收集与图形展示,数据收集的方式有很多种,可以通过SNMP实现,也可以通过代理模块实现,还可以通过自定义脚本实现,这里采用数据收集工具Ganglia来实现。
数据提取模块:此模板主要完成数据的筛选过滤和采集,将需要的数据从数据收集模块提取到监控报警模块中。可以通过数据收集模块提供的接口或者自定义脚本实现数据的提取。
监控报警模块:此模块主要完成监控脚本的设置、报警规则设置,报警阀值设置、报警联系人设置等,并将报警结果进行集中展现和历史记录,常见的监控报警工具有Nagios、Centreon等。
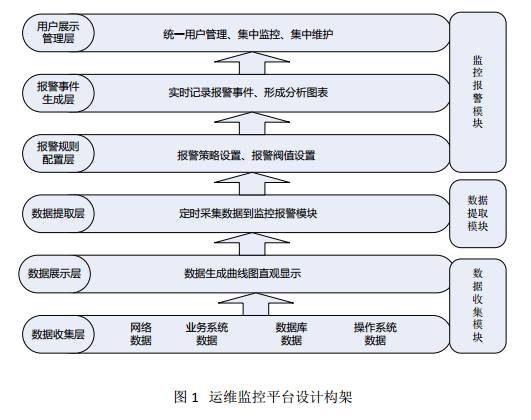
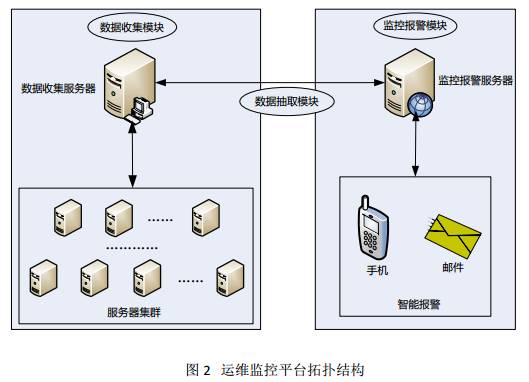
图2是根据图1的设计思路形成的一个运维监控平台实现拓扑图,从图中可以看出,主要有三大部分组成,分别是数据收集模块、监控报警模块和数据提取模块。
其中,数据提取模块用于其它两个模块之间的数据通信,而数据收集模块可以有一台或多台数据收集服务器组成,每个数据收集服务器可以直接从服务器群组收集各种数据指标,经过规范数据格式,最终将数据存储到数据收集服务器中。
监控报警模块通过数据抽取模块从数据收集服务器获取需要的数据,然后对数据设置报警阀值、报警联系人等,最终实现实时报警,报警方式支持手机短信报警、邮件报警等,另外,也可以通过插件或者自定义脚本来扩展报警方式。这样一整套监控报警平台就基本实现了。
第二:Ganglia作为数据收集模块
Ganglia是一款为HPC(高性能计算)集群而设计的可扩展的分布式监控系统,它可以监视和显示集群中的节点的各种状态信息,它由运行在各个节点上的gmond守护进程来采集cpu 、mem、硬盘利用率、I/O负载、网络流量情况等方面的数据,然后汇总到gmetad守护进程下,使用rrdtools存储数据,最后将历史数据以曲线方式通过php页面呈现。
特点如下:
1、灵活的分布式、分层体系结构,使Ganglia支持上万个监控节点的数据收集,并且性能表现稳定,同时,Ganglia也可以根据地域环境、网络结构的不同,分地域、分层次的灵活部署Ganglia数据收集点,而对于数据收集节点可以动态添加或删除,对Ganglia整体监控不产生任何影响。因此,可以灵活的扩展Ganglia数据收集节点。
2、Ganglia收集到的数据更加精确,它不但可以收集实时数据,以图表的形式展示出来,而且还允许用户查看历史统计数据,因此,用户可以通过这些数据,做出性能调整、升级、扩容等决策,从而保证应用系统能够满足不断增长的业务需求。
3、Ganglia可以通过组播、单播的方式收集数据,在监控的节点较多时通过组播方式收集数据可以大大降低数据收集的负载,提高监控和数据收集性能。而对于不能使用组播收集数据的网络环境,还可以通过单播的方式收集数据,因此Ganglia在数据收集方式上非常灵活。
4、Ganglia可收集各种度量的数据,Ganglia默认情况下可收集cpu、memory、disk、I/O、process、network六大方面的数据,同时Ganglia提供了C或者Python接口,用户通过这个接口可以自定义数据收集模块,并且这些模块可以被直接插入到Ganglia中以监控用户自定义的应用。
基于以上Ganglia这些优点,使它非常适合作为监控报警平台的数据收集模块,虽然Cacti/zabbix也可以实现数据的收集和图形报表的展示,但是当监控节点越来越多时,Cacti和zabbix的缺点就慢慢暴露出来了,数据收集的准确性、实时性就很难得到保障了。因此,要构建一个高性能的监控报警平台,Ganglia是首选的数据收集模块。
第三:Centreon作为监控报警模块
有了Ganglia收集数据还是不够的,运维人员不可能天天盯着数据报表,因此,还需要对收集到的数据进行监控和报警:对每个需要监控的主机或服务,设置一个报警阀值,当收集到的数据超过这个阀值时,在第一时间能自动报警并通知到运维人员,而如果收集到的数据没有超过指定的报警阀值,运维人员就可以去做别的事情,而不用时刻盯着数据报表,这是构建智能监控报警平台必须要实现的一个功能。
对主机或服务的状态值进行监控,当达到指定阀值时进行报警,要实现这个功能并不是什么难的事情,可以写个简单的脚本就能实现,但是这样太原始了,没有层次,维护性差,并且当需要监控报警的主机或服务越来越多时,脚本的性能就变得很差,管理也非常不方便,更别说有什么可视化效果了,因此,就需要有一个专业的监控报警工具来实现这个功能。
Centreon就是这样一个专业的分布式监控、报警工具,它通过第三方组件可以实现对网络、操作系统和应用程序的监控与报警,在底层,centreon通过nagios作为监控软件,在数据层,Centreon通过ndoutil模块将监控到的数据定时写入数据库中,在展示层,Centreon提供了Web界面来配置、管理需要监控的主机或服务,并提供多种报警通知方式,同时还可以展现监控数据和报警状态,并可查询历史报警记录。
第四:Ganglia与Centreon的无缝整合
Nagios和Ganglia都是很好的数据中心监控工具,虽然它们的功能有重叠部分,但是两者对监控的侧重点并不相同:Ganglia侧重于收集数据,并随时跟踪数据状态,通过Ganglia不但可以看到数据的历史状态,也可以预计数据的未来发展趋势,为我们的应用程序修正和硬件采购提供决策。而Nagios更侧重与监控数据并进行过载报警,综合Ganglia和Nagios的优缺点,同时运行这两个工具可以相互弥补它们的不足:
Ganglia暂时没有内置报警通知机制,而Nagios这方面是强项。
Nagios没有内置代理和分布式监控机制,而Ganglia设计之初就考虑到了这些。
Nagios没有直观的报表展示(虽然可通过PNP插件实现),而Ganglia报表功能很强大。
Ganglia内置了基于很多开发接口,通过这些接口,可以将Ganglia统计到的数据纳入Nagios监控之下。
确定了以Ganglia作为数据收集模块,Centreon作为监控报警模块的方案,这样,一个智能监控报警平台两大主要功能模块已经基本实现了,但现在的问题是,如何将收集到的数据传送给监控报警模块呢,这就是数据抽取模块要完成的功能。
数据抽取模块要完成的功能是:从数据收集模块中定时采集指定的数据,然后将采集到的数据与指定的报警阀值进行比较,如果发现采集到的数据大于或小于指定的报警阀值,那么就通过监控报警模块设置的报警方式进行故障通知,这个过程,只有采集数据是在数据收集模块中完成,其他操作,例如:采集数据时间间隔、报警阀值设置、报警方式设置、报警联系人设置等都在监控报警模块中完成。
从数据抽取模块完成的功能可以看出,此模块主要用来衔接数据收集模块和监控报警模块,进而完成Ganglia和Centreon的无缝整合。
要实现数据抽取模块的功能,没有现成的方法可用,需要在ganglia基础上做二次开发,较简单的方法是在通过程序在ganglia上开发一个数据提取接口,然后将数据抽取到nagios中,初步方案是通过python程序来实现。
第五:统计监控系统架构图
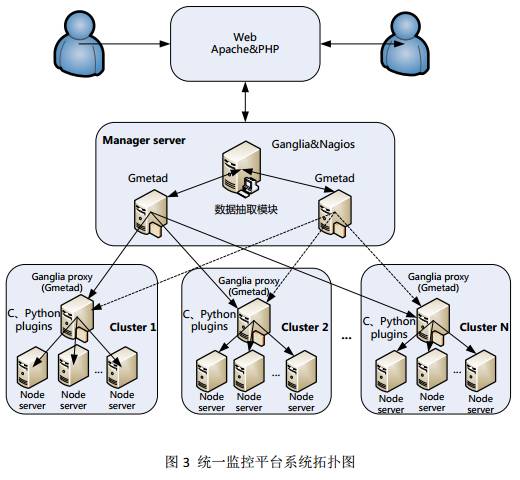
简单描述如下:
Cluster1-N均为一个分布式集群,也可以认为是一个机房数据中心。每个数据中心的Node server都运行一个Gmond守护进程,进行数据收集,将收集到的数据汇总到Ganglia proxy主机,Ganglia proxy主机上运行着Gmetad守护进程。同时Gangliaproxy和Node server都加载通过C或者Python编写的Ganglia插件,扩展Ganglia监控功能。
Managerserver是一个管理主机,主要用于收集从各个机房数据中心的监控数据,通过数据抽取模块将Nagios和Ganglia整合到一起,考虑到数据的安全性,Manager server建议做一个备机,平时主机和备机同时工作,进行数据收集,主机故障时,自动切换到备机,保证管理主机高可用。
监控数据和报表通过Web方式展示出来,将Nagios和Ganglia的web进行整合,并作二次开发,通过一个统一的界面展示监控状态和报表信息。
第六:数据流向图
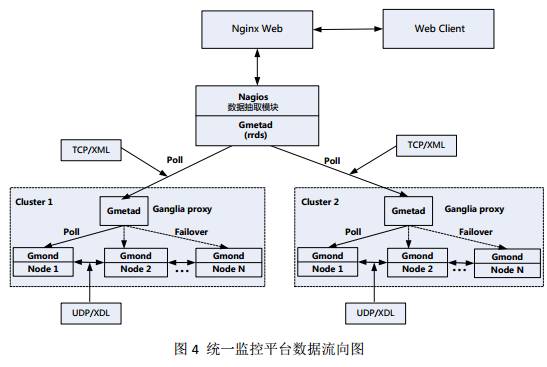
基本流程如下:
Gmond收集本机的监控数据,发送到其他机器上,并收集其他机器的监控数据,gmond之间通过udp通信,传递文件格式为XDL。
Gmond节点间的数据传输方式支持单播点对点传送外,还支持多播传送。
gmetad周期性的去gmond节点或者gmetad节点poll数据,Gmetad只有tcp通道,gmond与gmetad之间的数据都以XML格式传输。
gmetad既可以从gmond也可以从其他的gmetad得到xml数据。
gmetad将获取到的数据更新到rrds数据库中。
Nagios通过数据抽取模块监控ganglia获取到的数据并进行报警。
通过web监控界面,从Gmetad取数据,并且读取rrd数据库,生成图片显示出来。
接下来是QA环节:
1、gmond在客户端之间通过udp方式互相传递的,有什么意义?
答:通过udp方式传输数据,一方面是轻量级传输,在大量服务器监控的情况下,不会过大消耗服务器和网络资源,另一方面udp方式的组播方式可以将数据保存到多个节点,这样可以在管理端设置多个收集数据节点,当一个节点故障时,自动去另一个节点收集数据,保证了数据收集的稳定性。
2、如何监控系统不通过tcpip而是通过读取数据库形式完成数据抓取,发现故障的延时会好很多么?
答:抓取数据的方式决定了是否存在延时,这个跟ganglia无关,ganglia可以接收接口过来的任意数据,但是是否有延时,决定权在你的数据收集脚本。
3、如果为了备份数据的话,采用udp方式,一旦各个节点之间发生网络抖动,数据完整性如何保证?
答:数据在每个节点的保存时间基本在10秒左右,超过这个时间,数据会再次进行更新,因此不存在抖动问题,至于数据完整性,也可以不用考虑,在收集到数据后,gmetad会对数据进行统一整理,更多关注的是数据的及时性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号