




Python发展史,选择Python2还是Python3?Python开发环境
本节内容
- 发展史
- Python 2 or 3?
- 安装
- Hello World程序
- 变量
- 字符编码
- 注释
- 用户输入
- 模块初识
- .pyc是个什么东西?
- 数据类型初识
- 数据运算
- 表达式if ...else语句
- 表达式for 循环
- 表达式while 循环
一、Python发展史
- 1989年,为了打发圣诞节假期,Guido开始写Python语言的编译器。Python这个名字,来自Guido所挚爱的电视剧Monty Python’s Flying Circus。他希望这个新的叫做Python的语言,能符合他的理想:创造一种C和shell之间,功能全面,易学易用,可拓展的语言。
- 1991年,第一个Python编译器诞生。它是用C语言实现的,并能够调用C语言的库文件。从一出生,Python已经具有了:类,函数,异常处理,包含表和词典在内的核心数据类型,以及模块为基础的拓展系统。
- Granddaddy of Python web frameworks, Zope 1 was released in 1999
- Python 1.0 - January 1994 增加了 lambda, map, filter and reduce.
- Python 2.0 - October 16, 2000,加入了内存回收机制,构成了现在Python语言框架的基础
- Python 2.4 - November 30, 2004, 同年目前最流行的WEB框架Django 诞生
- Python 2.5 - September 19, 2006
- Python 2.6 - October 1, 2008
- Python 2.7 - July 3, 2010
- In November 2014, it was announced that Python 2.7 would be supported until 2020, and reaffirmed that there would be no 2.8 release as users were expected to move to Python 3.4+ as soon as possible
- Python 3.0 - December 3, 2008
- Python 3.1 - June 27, 2009
- Python 3.2 - February 20, 2011
- Python 3.3 - September 29, 2012
- Python 3.4 - March 16, 2014
- Python 3.5 - September 13, 2015
二、选择 Python2 还是 Python3
不同于其他编程语言和应用程序,高版本一般都会向下兼容低版本;但Python是一个比较特殊的情况,由于历史原因,Python有两个大的版本分支,并且有部分不兼容的情况,
Python2和Python3,又由于一些库只支持某个版本分支,所以需要在电脑上同时安装Python2和Python3,因此如何让两个版本的Python兼容,如何让脚本在对应的Python版本上运行,这个是值得总结的。
对于Ubuntu 16.04 LTS版本来说,Python2(2.7.12)和Python3(3.5.2)默认同时安装,默认的python版本是2.7.12。
随着时间的推移,Python2终将退出历史舞台,现在绝大部分的库都已支持Python3,诚如Python官方文档给出的的答案:
In summary : Python 2.x is legacy, Python 3.x is the present and future of the language
Python2已经是遗产,Python3才是现在和未来。
Python 3.0 was released in 2008. The final 2.x version 2.7 release came out in mid-2010, with a statement of
extended support for this end-of-life release. The 2.x branch will see no new major releases after that. 3.x is
under active development and has already seen over five years of stable releases, including version 3.3 in 2012,
3.4 in 2014, and 3.5 in 2015. This means that all recent standard library improvements, for example, are only
available by default in Python 3.x.
Guido van Rossum (the original creator of the Python language) decided to clean up Python 2.x properly, with less regard for backwards compatibility than is the case for new releases in the 2.x range. The most drastic improvement is the better Unicode support (with all text strings being Unicode by default) as well as saner bytes/Unicode separation.
Besides, several aspects of the core language (such as print and exec being statements, integers using floor division) have been adjusted to be easier for newcomers to learn and to be more consistent with the rest of the language, and old cruft has been removed (for example, all classes are now new-style, "range()" returns a memory efficient iterable, not a list as in 2.x).
还有谁不支持PYTHON3?
One popular module that don't yet support Python 3 is Twisted (for networking and other applications). Most
actively maintained libraries have people working on 3.x support. For some libraries, it's more of a priority than
others: Twisted, for example, is mostly focused on production servers, where supporting older versions of
Python is important, let alone supporting a new version that includes major changes to the language. (Twisted is
a prime example of a major package where porting to 3.x is far from trivial
在我们后续的章节和内容中会穿插介绍一些Python2和Python3的特性和区别,仅当了解和补充即可。。。
某些库改名了
|
Old Name |
New Name |
|
_winreg |
winreg |
|
ConfigParser |
configparser |
|
copy_reg |
copyreg |
|
Queue |
queue |
|
SocketServer |
socketserver |
|
markupbase |
_markupbase |
|
repr |
reprlib |
|
test.test_support |
test.support |
三、Python开发环境的安装
Windows下基本Python环境需要手动下载安装,Linux、Mac下无需安装,默认会自带Python环境
1、下载安装包 https://www.python.org/downloads/ 2、安装 默认安装路径:C:\python3 3、配置环境变量 【右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】
--》【在第二个内容框中找到 变量名为Path 的一行,双击】 --> 【Python安装目录追加到变值值中,用 ; 分割】 如:原来的值;C:\python3,切记前面有分号
在企业级生产开发环境中(建议学习和项目开发也安装),可以无需安装Python官方包直接下载安装Anaconda+Pycharm
Anaconda指的是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。
因为包含了大量的科学包,Anaconda 的下载文件比较大(约 531 MB),如果只需要某些包,或者需要节省带宽或存储空间,也可以使用Miniconda这个较小的发行版(仅包含conda和 Python),
在国内可以通过清华、阿里、华为、网易镜像等各大镜像站在下载安装即可。
PyCharm是一种Python IDE(集成开发环境),带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。此外,该IDE提供了一些高级功能,以用于支持Django框架下的专业Web开发。分为社区版(免费)和专业版(收费),在一般的开发中,社区版已经可以满足需求,如需专业版,可以参考相关Pycharm专业版激活的文章。
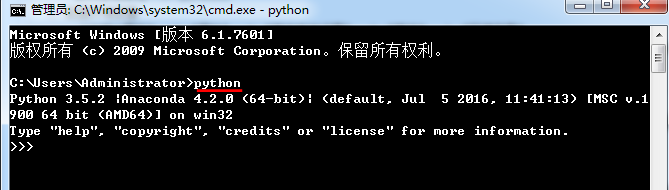
在命令行下输入python,可以看到相关Python的信息,说明配置成功了。
四、Hello World 向世界打招呼
在linux 下创建一个文件叫hello.py,并输入
print('hello world!')
然后执行命令:python hello.py ,输出
hello world!
指定解释器
上一步中执行 python hello.py 时,明确的指出 hello.py 脚本由 python 解释器来执行。
如果想要类似于执行shell脚本一样执行python脚本,例: ./hello.py ,那么就需要在 hello.py 文件的头部指定解释器,如下:
#!/usr/bin/env python print('hello world!')
如此一来,执行: ./hello.py 即可。
ps:执行前需给予 hello.py 执行权限,chmod 755 hello.py
在交互器中执行
除了把程序写在文件里,还可以直接调用python自带的交互器运行代码。
对比下其它语言的hello world
 C++ C JAVA PHP RUBY Go
C++ C JAVA PHP RUBY Go五、变量
Variables are used to store information to be referenced and manipulated in a computer program. They also provide a way of labeling data with a descriptive name, so our programs can be understood more clearly by the reader and ourselves. It is helpful to think of variables as containers that hold information. Their sole purpose is to label and store data in memory. This data can then be used throughout your program.
声明变量
name = 'Sanmy Zeng'
上述代码声明了一个变量,变量名为: name,变量name的值为:"Sanmy Zeng"
变量定义的规则:
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
变量的赋值
# -*- coding:utf-8 -*- name = 'Sanmy Zeng' name2 = name print(name,name2) name = 'Jack' print('what is the value of name2 now?',name2)
在python的idle中输入以上代码,看看运行的结果是什么?
六、字符编码
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256-1,所以,ASCII码最多只能表示 255 个符号。
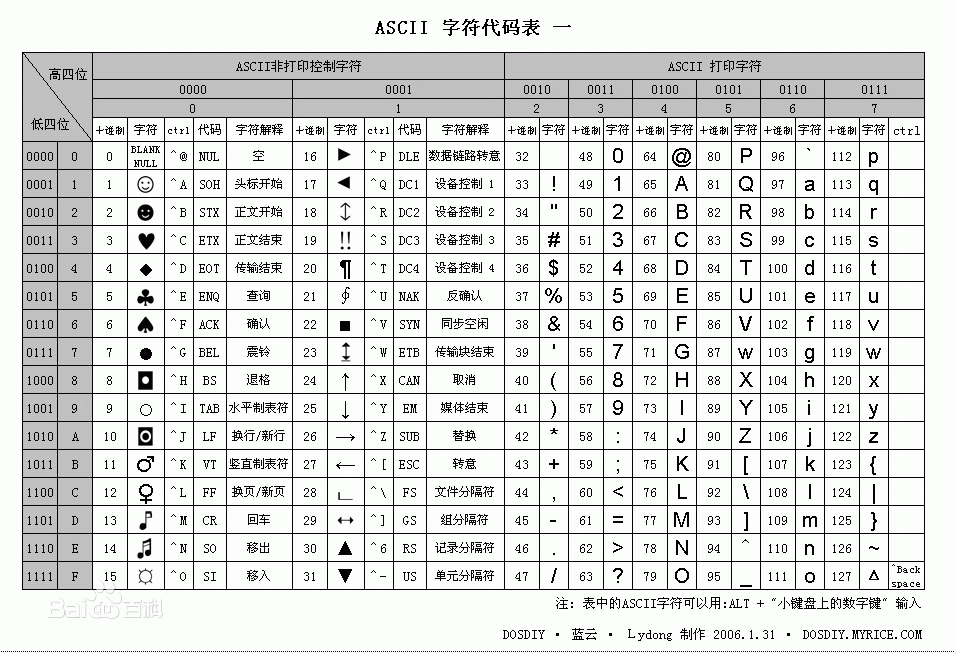
关于中文
为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5。
GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。
GB2312 支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的PC平台必须支持GB18030,对嵌入式产品暂不作要求。所以手机、MP3一般只支持GB2312。
从ASCII、GB2312、GBK 到GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK到GB18030都属于双字节字符集 (DBCS)。
有的中文Windows的缺省内码还是GBK,可以通过GB18030升级包升级到GB18030。不过GB18030相对GBK增加的字符,普通人是很难用到的,通常我们还是用GBK指代中文Windows内码。
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话:
报错:在2.X版本中ascii码无法表示中文
#!/usr/bin/env python print "你好,世界"
改正:应该显示的告诉python解释器,用什么编码来执行源代码,即:
#!/usr/bin/env python # -*- coding: utf-8 -*- print "你好,世界"
七、注释
Python中只有两种注释
单行注释:# 被注释内容
多行注释:""" 被注释内容 """


单行注释:// 注释内容 多行注释:/*... 注释内容....*/ 文本注释:/**.. 注释内容....*/ 可以使用多行,一般用来对类、接口、成员方法、成员变量、静态字段、静态方法、常量进行说明
//单行注释 /*多行注释,不可以嵌套使用*/ #if 0 使用预处理形式,可以避免第二种的不足 #endif
// 单行注释 /**/ 块注释 ///说明注释,注释以后可以自动生成说明文档档
八、用户输入
正常输入时使用input()方法;输入密码时,如果想要不可见,需要利用getpass 模块中的 getpass方法(如在Pycharm的交换界面下不可用),代码:
#!/usr/bin/env python # -*- coding: utf-8 -*- import getpass # 输入用户名,赋值给usr变量 usr = input('请输入用户名:') # 将用户输入的内容赋值给 pwd变量 pwd = getpass.getpass("请输入密码:") # 打印输入的内容 print(usr,pwd)
九、模块初识
模块也叫库,可以用别人已经编写好的库或编写自己的模块,Python的强大之处在于他有非常丰富和强大的标准库和第三方库(Anaconda中包含了很多的第三方库),几乎你想实现的任何功能都有相应的Python库支持,
以后的课程中会深入讲解常用到的各种库,现在,我们先来象征性的学2个简单的。
sys
#!/usr/bin/env python # -*- coding:utf-8 -*-
# 单导入模块时会优先到当前目录下去找有没这个名字的模块 import sys # 是python的搜索模块的路径集(环境变量),是一个list,python 环境下使用sys.path.append(path)添加相关的路径,但在退出python环境后自己添加的路径就会自动消失 print(sys.path) # 输出文件名及文件所在的目录(相对目录) print(sys.argv)
os
import os # 只执行命令,输出到屏幕,保存不了结果到变量,不建议使用 os.system('dir') # 不加read()得到的是内存的对象地址,建议使用 cmd_res = os.popen('dir').read() print(cmd_res) # 在当前目录下创建一个新的目录 os.mkdir('new1')
结合使用
import os,sys os.system(''.join(sys.argv[1:])) #把用户的输入的参数当作一条命令交给os.system来执行
自己写个模块
python tab补全模块
import sys import readline import rlcompleter if sys.platform == 'darwin' and sys.version_info[0] == 2: readline.parse_and_bind("bind ^I rl_complete") else: readline.parse_and_bind("tab: complete") # linux and python3 on mac
#!/usr/bin/env python # python startup file import sys import readline import rlcompleter import atexit import os # tab completion readline.parse_and_bind('tab: complete') # history file histfile = os.path.join(os.environ['HOME'], '.pythonhistory') try: readline.read_history_file(histfile) except IOError: pass atexit.register(readline.write_history_file, histfile) del os, histfile, readline, rlcompleter
写完保存后就可以导入使用了
你会发现,上面自己写的tab.py模块只能在当前目录下导入,如果想在系统的何何一个地方都使用怎么办呢? 此时你就要把这个tab.py放到python全局环境变量目录里啦,基本一般都放在一个叫:Python/版本号/site-packages目录下,
这个目录在不同的OS里放的位置不一样,可以用 print(sys.path) 查看Python环境变量列表。
十、.pyc是个什么东西
1. Python是一门解释型语言?
我初学Python时,听到的关于Python的第一句话就是,Python是一门解释性语言,我就这样一直相信下去,直到发现了*.pyc文件的存在。如果是解释型语言,那么生成的*.pyc文件是什么呢?c应该是compiled的缩写才对啊!
为了防止其他学习Python的人也被这句话误解,那么我们就在文中来澄清下这个问题,并且把一些基础概念给理清。
2. 解释型语言和编译型语言
计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,第一种是编译,第二种是解释。
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby。
通过以上的例子,我们可以来总结一下解释型语言和编译型语言的优缺点,因为编译型语言在程序运行之前就已经对程序做出了“翻译”,所以在运行时就少掉了“翻译”的过程,所以效率比较高。但是我们也不能一概而论,一些解释型语言也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在效率上接近编译型语言。
此外,随着Java等基于虚拟机的语言的兴起,我们又不能把语言纯粹地分成解释型和编译型这两种。
用Java来举例,Java首先是通过编译器编译成字节码文件,然后在运行时通过解释器给解释成机器文件。所以我们说Java是一种先编译后解释的语言。
3. Python到底是什么
其实Python和Java/C#一样,也是一门基于虚拟机的语言,我们先来从表面上简单地了解一下Python程序的运行过程吧。
当我们在命令行中输入python hello.py时,其实是激活了Python的“解释器”,告诉“解释器”:你要开始工作了。可是在“解释”之前,其实执行的第一项工作和Java一样,是编译。
熟悉Java的同学可以想一下我们在命令行中如何执行一个Java的程序:
javac hello.java
java hello
只是我们在用Eclipse之类的IDE时,将这两部给融合成了一部而已。其实Python也一样,当我们执行python hello.py时,他也一样执行了这么一个过程,所以我们应该这样来描述Python,Python是一门先编译后解释的语言。
4. 简述Python的运行过程
在说这个问题之前,我们先来说两个概念,PyCodeObject和pyc文件。
我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。
十一、数据类型初识
1、数字
2 是一个整数的例子。
长整数 不过是大一些的整数。
3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 * 10**-4。
(-5+4j)和(2.3-4.6j)是复数的例子,其中-5,4为实数,j为虚数,数学中表示复数是什么?。
int(整型)
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
float(浮点型)
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
2、布尔值
3、字符串
"hello world!" "你好,北京!"
# 推荐使用 s = ("我一直认为我是一只蜗牛。我一直在爬,也许还没有爬到金字塔的顶端。" "但是只要你在爬,就足以给自己留下令生命感动的日子。") # 不推荐使用 s = "我一直认为我是一只蜗牛。我一直在爬,也许还没有爬到金字塔的顶端\ 但是只要你在爬,就足以给自己留下令生命感动的日子。" print(s)
字符串的格式化输出,比如:#!/usr/bin/env python
# -*- coding:utf-8 -*- name = 'Lisi' age = 28 job = 'IT' salary = 23000.88 addr = '广东省深圳市' # 使用三引号,字符串内容可以分布在多行,'\'为转义字符如果想输出'\',可在前面加r或R
# PS: 字符串是 %s;整数 %d;浮点数%f
info = ''' ---------------- infomation001 of %s ---------------- Name:%s Age:%d Job:%s Salary:%f Address:%s ''' %(name,name,age,job,salary,addr) # 推荐使用的字符串格式化输出 info2 = ''' ---------------- infomation002 of {_name} ---------------- Name:{_name} Age:{_age} Job:{_job} Salary:{_salary} Address:{_addr} '''.format(_name=name, _age=age, _job=job, _salary=salary, _addr=addr) print(info) print(info2)
- 移除空白
- 分割
- 长度
- 索引
- 切片

 浙公网安备 33010602011771号
浙公网安备 33010602011771号