
爬虫-Scrapy(七)抓取招聘信息技能关键词,生成词云图
这个昨晚10点做到今天凌晨2点多,主要是安装wordcount 各种Duang Duang 的报错,建议需要安装的同学自己去下载对应的版本,不要太依赖pip的自动安装。
开搞
1.抓取招聘信息列表
找一个招聘网站,最好不用登录就可以浏览职位的那种,然后输入关键次,先查看下结果。
私心想着如果结果太多,就在加上些企业规模、薪资待遇等条件搜小下爬取范围,因为只为学习研究,数据量大的话太影响效率。
结果发现 关键词:爬虫 + 地区:北京 只有3页110个结果,悲哀,那就全来吧。
a.翻页,实现遍历3页
## 翻页,访问3页的工作列表 def start_requests(self): # url 是有规律的,中间的 1.html ,2.html 分别代表第1页和第2页 for i in range(1,4): url = 'https://某招聘网站/list/2,{}.html?lang=c&postchannel=0000&workyear=99'.format(i)yield scrapy.Request(url, callback=self.parse)
b.每页按招聘列表遍历每个招聘的详情页
## 遍历每页的工作列表 def parse(self, response): job_list = json.loads(response.text)['engine_search_result'] for job in job_list: yield scrapy.Request(job['job_href'], callback=self.parse_job)
c.招聘详情页抓取岗位职责和技能要求,解析后返回给item
# 获取工作职责和技能要求中的英文词 def parse_job(self, response): job_msg_list = response.xpath('//div[@class="bmsg job_msg inbox"]/p/text()').extract() for job_msg in job_msg_list: words = re.sub("[^A-Za-z]", " ", job_msg.strip()).split() for word in words: item = SkillcountItem() item['job_word'] = word yield item
这里用了个正则表达式过滤了下只要应为单词,因为技能要求大部分都是英文的,比如python ,mysql, selenium 什么的。
也尝试过用jieba分词把中文也分成单词来统计,结果发现大部分都没实际意义。
3.item中关键词转为字符,生成词云图
class SkillWordPipeline:
def __init__(self): self.job_items = [] def process_item(self, item, spider): self.job_items.append(copy.deepcopy(item['job_word'])) return item def close_spider(self, spider): job_details = ' '.join(self.job_items) self.generate_image(job_details) def generate_image(self,job_details): print(job_details) wc = wordcloud.WordCloud( background_color='white', # 背景色 width=1200, height=800 # max_words=30, # 最大显示单词数 # max_font_size=60 # 频率最大单词字体大小 ) # 生成词云图 wc.generate(job_details) # 转图片 image = wc.to_image() image.show() # 显示词云 #保存到本地 wc.to_file("D:\skill_word.jpg")
代码简洁,可用。 wordcloud 的WordCloud 还有其他的参数,详细可以查,如果要设置字体需指定 字体ttf文件资源路径。
4.结果展示
没图?没图你说杰巴,呵呵,有图的。
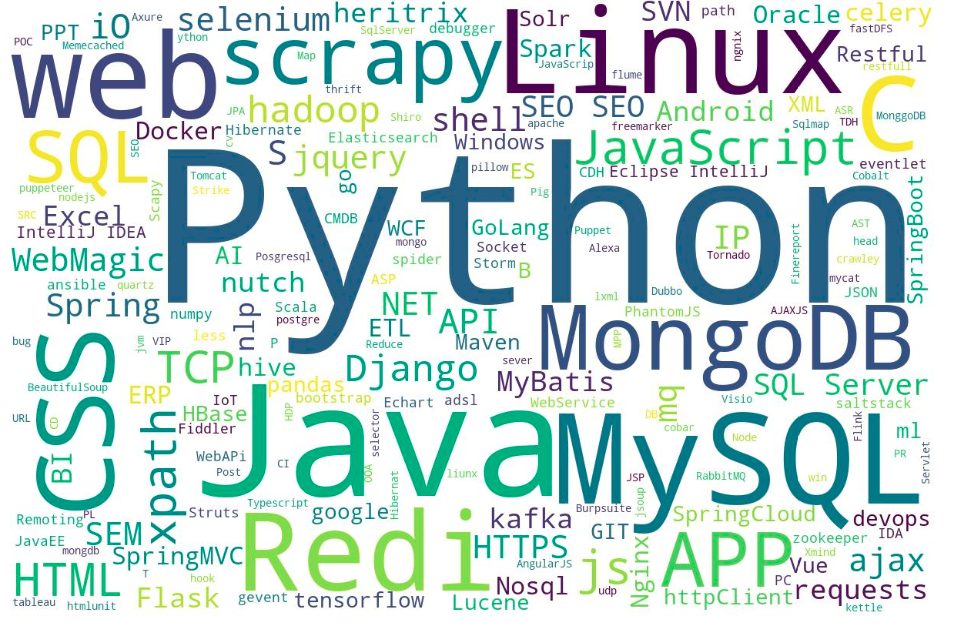
现在知道改学什么了吧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号