
爬虫-Scrapy(四) pipeline将数据存储至mysql库
1. mysql库环境准备
a.服务器,准备一台linux服务器,可以自己机器上装个虚拟化软件,也可以连公司的闲置服务器或者租赁云服务器,不贵的。
b.mysql,安装的5.7,官网应该有8了,但5.7还是最普遍的版本。
c.Navicat for Mysql,非常好用的mysql客户端工具。
安装过程省略,安装完成后新建一个库,起名spider,然后在新建一个表,起名book,准备接收数据用。建表脚本:
CREATE TABLE book(
id INT PRIMARY KEY AUTO_INCREMENT COMMENT 'ID',
code int COMMENT '编号',
name VARCHAR(200) COMMENT '名称',
price double COMMENT '价格'
)
COMMENT='图书信息表'
建表成功,这个就是我们本次要写入数据的目标表。
2.爬取数据存储至item
首先修改items.py ,新增图书的Item
class BookItem(scrapy.Item):
code = scrapy.Field() # 编码
name = scrapy.Field() # 名称
price = scrapy.Field() # 价格
然后写用genspider命令,生成一个名为BookSpider的爬出,引入BookItem,并赋予数据。
因为本次重点不是爬取数据,所以图书数据直接枚举一下,代码如下:
import scrapy
from scpy1.items import BookItem
class BookSpider(scrapy.Spider):
name = 'BookSpider'
allowed_domains = ['baidu.com']
start_urls = ['http://www.baidu.com/']
def parse(self, response):
data = [[100,'MySql-从删库到跑路',23.5], [101,'爬虫-从入门到放弃',30.9]]
for i in range(2):
item = BookItem()
item['code'] = data[i][0]
item['name'] = data[i][1]
item['price'] = data[i][2]
yield item
3.启用pipleline
首先修改settings.py 启用BookPipleLine
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'scpy1.pipelines.BookPipeline': 300,
}
然后在piplelines.py中写BookPipleLine类下的3个方法,1是初始化方法,这里我们设置数据库的连接信息并连接数据库。2是处理item的方法process_item,3是爬虫结束时断开数据库连接。上代码:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import mysql.connector
class BookPipeline:
# 初始化,连接库
def __init__(self):
print('初始化数据库连接')
self.conn = mysql.connector.connect(
host='39.*.*.*', #ip
port='3306', #端口
user='l**', #登录账号
password='Y***', #登录密码
database='spider', #库名
use_unicode=True #unicode
)
self.cur = self.conn.cursor()
# 处理数据,写入库
def process_item(self, item, spider):
self.cur.execute("INSERT INTO book VALUES(null, %s, %s, %s)",
(item['code'], item['name'], item['price']))
self.conn.commit()
# 结束,关闭连接
def close_spider(self, spider):
print('关闭数据库资源')
# 关闭游标
self.cur.close()
# 关闭连接
self.conn.close()
4.存储到mysql库
用crawl命令执行爬虫,然后用Navicat连接库查询结果
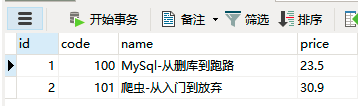
成功,收工。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号