联邦学习:入门概述
联邦学习(Federated Learning)
1 总体概述
联邦学习是分布式学习的一种特殊方式,更强调在充分保护数据隐私的前提下,如何进行尽可能的其他相关数据信息的结合与知识提取。联邦学习是一种保障数据隐私的模型训练方法,能够打破传统企业等机构的数据边界,在医疗、金融等行业中具有广泛的应用前景。联邦学习支持数据在本地训练,训练后局部模型的参数通过加密机制被发送到服务器。服务器聚合所有参与者的局部模型,然后将更新好的全局模型通过加密机制再发送给每个参与者进行下一次训练,直到全局损失函数收敛或达到所需的训练精度为止。
其结构由Server和若干Client组成,在联邦学习方法过程中,没有任何用户数据被传送到Server端,这保护了用户数据的隐私。此外,通信中传输的参数是特定于改进当前模型的,因此一旦应用了它们,Server就没有理由存储它们,这进一步提高了安全性。
下图为联邦学习的总体框架,由Server和若干Client构成,大概的思路是“数据不动模型动”。具体而言,Server提供全局共享的模型,Client下载模型并训练自己的数据集,同时更新模型参数。在Server和Client的每一次通信中,Server将当前的模型参数分发给各个Client(或者说Client下载服务端的模型参数),经过Client的训练之后,将更新后的模型参数返回给Server,Server通过某种方法将聚合得到的N个模型参数融合成一个作为更新后的Server模型参数。以此循环。
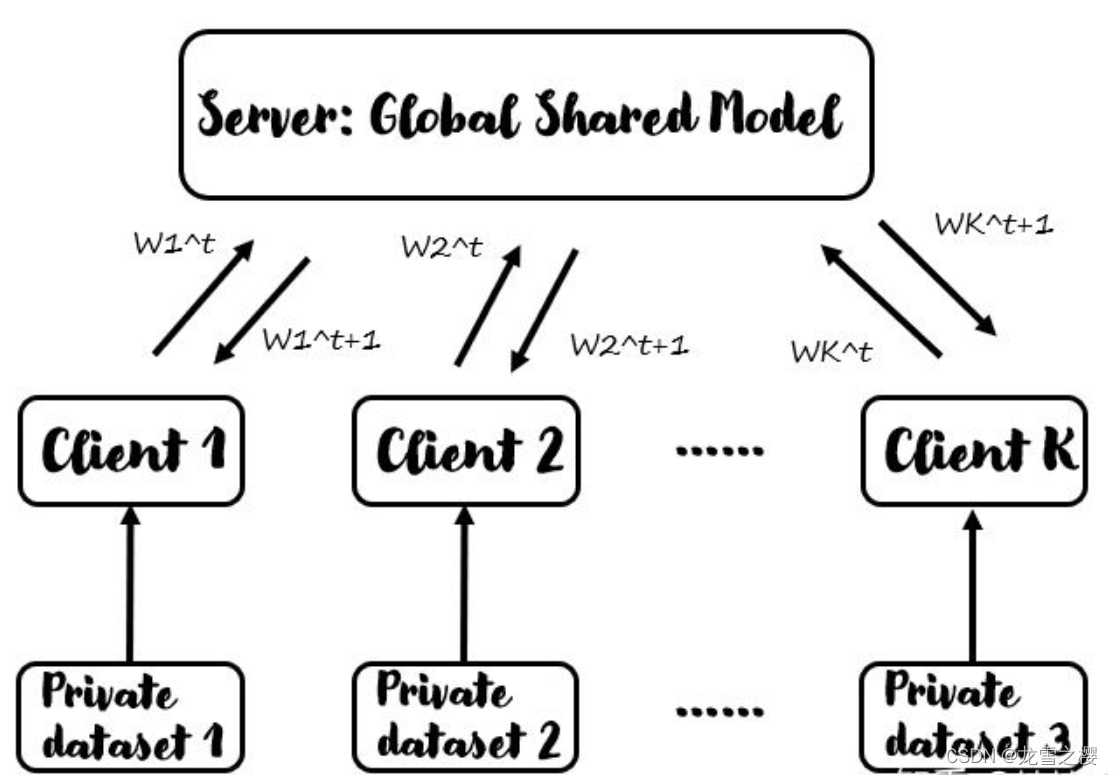
然而,各个参与者的局部模型与服务器的全局模型之间需要频繁交换训练信息将导致通信开销剧增。如果参与者的带宽有限或通信成本高昂,会导致联邦学习效率低下,甚至无法进行。
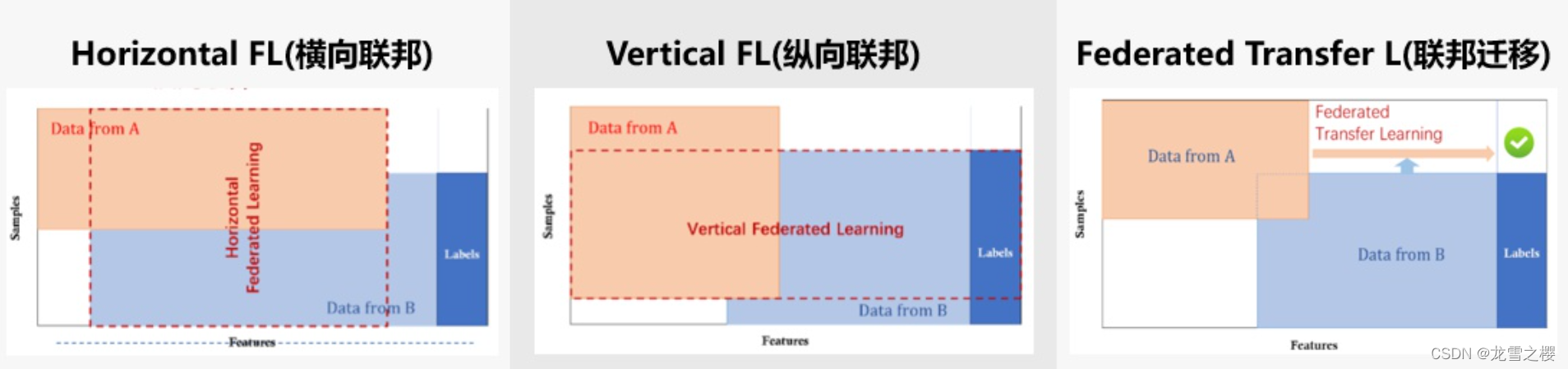
联邦学习分为横向联邦、纵向联邦和迁移联邦,之间的区分主要是样本与特征的重叠程度。不同数据集往往有两个特点之分,一是数量,对应样本,二是具体分布,也就是特征。
- 样本重叠少,特征重叠多:即,各个数据集分布类似,需要的仅仅是数量上的聚合,为多个用户群体在该场景下采集的数据,我们采用的是横向联邦学习
- 样本重叠多,特征重叠少:即,数据集的分布不一致,各有各相异的特点与场景,但被采数据的群体(subjects)几乎是一致的,我们用的是纵向联邦学习
- 样本重叠少,特征重叠少:即,兼之以上两者,称之为迁移联邦学习,不过具体采用的处理方法更偏向于纵向联邦学习。
至于为什么成为横向与纵向,是因为描述联邦学习的概念图的x轴为特征轴,y轴为样本轴,哪个方向重叠多,就称作什么联邦。其他博客上来就是一张图,再进行分块描述,会让读者一头雾水,我采取了先用大白话描述,再给出一个主流描述的图,应该会容易理解。
也就是下图:
2 代码展现
常用的是横向联邦学习,我们以FedAvg方法、Mnist数据集为例,假设共100个Client,简单演示联邦学习方法,梳理流程
首先,我们要为每个客户端分配数据,实际上是每个客户端自身有独有的数据,这里为了模拟,手动划分数据集给各个客户端。
客户端之间的数据可能是独立同分布IID,也可能是非独立同分布Non-IID的。
对于IID的情况,我们首先将数据集打乱,然后为每个Client分配600个样本。
对于Non-IID的情况,我们首先根据数据标签将数据集排序(即MNIST中的数字大小),然后将其划分为200组大小为300的数据切片,然后分给每个Client两个切片。
这两种数据分配方式的代码如下:
if isIID:
order = np.arange(self.train_data_size)
np.random.shuffle(order)
self.train_data = train_images[order]
self.train_label = train_labels[order]
else:
labels = np.argmax(train_labels, axis=1)
order = np.argsort(labels)
self.train_data = train_images[order]
self.train_label = train_labels[order]然后就可以用一个循环来为每个Client分配数据。
首先,Server初始化并共享其模型的参数。
获取到共享的模型参数后,即可开始若干次的Server和Client间通信。通信的流程见代码注释:
net = Model() # 初始化模型
global_parameters = net.state_dict() # 获取模型参数以共享
# num_comm 表示通信次数,此处设置为1k
for i in range(args['num_comm']):
# 随机选择一部分Client,全部选择会增大通信量,且实验效果可能会不好
# clients_in_comm表示每次通讯中随机选择的Client数量
order = np.random.permutation(args['num_of_clients'])
clients_in_comm = ['client{}'.format(i) for i in order[0:num_in_comm]]
sum_parameters = None
# 每个Client基于当前模型参数和自己的数据训练并更新模型,返回每个Client更新后的参数
for client in tqdm(clients_in_comm):
# 获取当前Client训练得到的参数
local_parameters = myClients.clients_set[client].localUpdate(
args['epoch'], args['batchsize'], net, loss_func, opti, global_parameters)
# 对所有的Client返回的参数累加(最后取平均值)
if sum_parameters is None:
sum_parameters = local_parameters
else:
for var in sum_parameters:
sum_parameters[var] = sum_parameters[var] + local_parameters[var]
# 取平均值,得到本次通信中Server得到的更新后的模型参数
for var in global_parameters:
global_parameters[var] = (sum_parameters[var] / num_in_comm) 其中
local_parameters = myClients.clients_set[client].localUpdate(
args['epoch'], args['batchsize'], net,loss_func, opti, global_parameters)这一行代码表示Client端的训练函数,我们详细展开:
def localUpdate(self, localEpoch, localBatchSize, Net, lossFun, opti, global_parameters):
'''
:param localEpoch: 当前Client的迭代次数
:param localBatchSize: 当前Client的batchsize大小
:param Net: Server共享的模型
:param lossFun: 损失函数
:param opti: 优化函数
:param global_parameters: 当前通信中最新全局参数
:return: 返回当前Client基于自己的数据训练得到的新的模型参数
'''
# 加载当前通信中最新全局参数
Net.load_state_dict(global_parameters, strict=True)
# 载入Client自有数据集
self.train_dl = DataLoader(self.train_ds, batch_size=localBatchSize, shuffle=True)
# 设置迭代次数
for epoch in range(localEpoch):
for data, label in self.train_dl:
data, label = data.to(self.dev), label.to(self.dev)
preds = Net(data)
loss = lossFun(preds, label)
loss.backward()
opti.step()
opti.zero_grad()
# 返回当前Client基于自己的数据训练得到的新的模型参数
return Net.state_dict()训练结束之后,我们要通过测试集来验证方法的泛化性,注意,虽然训练时,Server没有得到过任何一条数据,但是联邦学习最终的目的还是要在Server端学习到一个鲁棒的模型,所以在做测试的时候,是在Server端进行的,如下:
with torch.no_grad():
# 加载Server在最后得到的模型参数
net.load_state_dict(global_parameters, strict=True)
sum_accu = 0
num = 0
# 载入测试集
for data, label in testDataLoader:
data, label = data.to(dev), label.to(dev)
preds = net(data)
preds = torch.argmax(preds, dim=1)
sum_accu += (preds == label).float().mean()
num += 1
print('accuracy: {}'.format(sum_accu / num))总结:
回顾上述方法流程,有几个关键的参数。一个是每个Client的训练迭代次数epoch,随着epoch的增加,意味着Client运算量的增加;另一个参数是通信次数,通信次数的增加意味着会增加网络传输的负担,且可能收到网络带宽的限制。
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号