2022 BUAA OO 第一单元总结
2022 BUAA OO 第一单元总结
前言
在第一单元的学习过程中,我最大的感受是在面对巨大的代码量的工作和重复迭代更新的需求之下,对于编程能力能力较弱的同学(just like me),掌握面向对象设计的模式是尤为重要,但是从面向过程到面向对象的这一转变也是一个较大的挑战。这一单元可以说是既注重了架构的设计,也对处理字符串的代码能力进行了考察。
虽然通过了第一单元的测试,但是我在第二次作业的强测中由于输出过程中一个bug的疏忽而挂掉了不少强测测试点,这是这一次作业我最遗憾的一个点,希望能在接下来的作业中,能戒骄戒躁,深刻反思此次的错误,以后避免再次出现类似的低级bug。
下面我将从作业架构分析、程序bug分析、单元设计体验和心得体会三个部分展开OO第一单元的总结。
一、作业架构分析
通过此单元作业的练习,我认识到了对于每个单元的第一次作业,如何初步建立一个具有鲁棒性和扩展性的架构是至关重要的,这就相当于以后三次作业的“地基”。
在第一次作业开始之前,我也做了预习作业和第一单元的实验作业,学习到了一些架构设计的方法,比如工厂法等等。对于第一次作业我尝试使用正则表达式对字符串进行解析,同时尝试使用一些SimpleTerm、SimpleExpr的对Term和Expr进行统一化处理的形式进行化简和输出,虽然这样设计可能不是很优秀,因为我在迭代的过程中进行了一些大的改动,可以算是在局部进行了重构操作,但是这样的架构可能也有一些优点和值得继续思考的点,为此记录一下,方便日后的反思、总结。
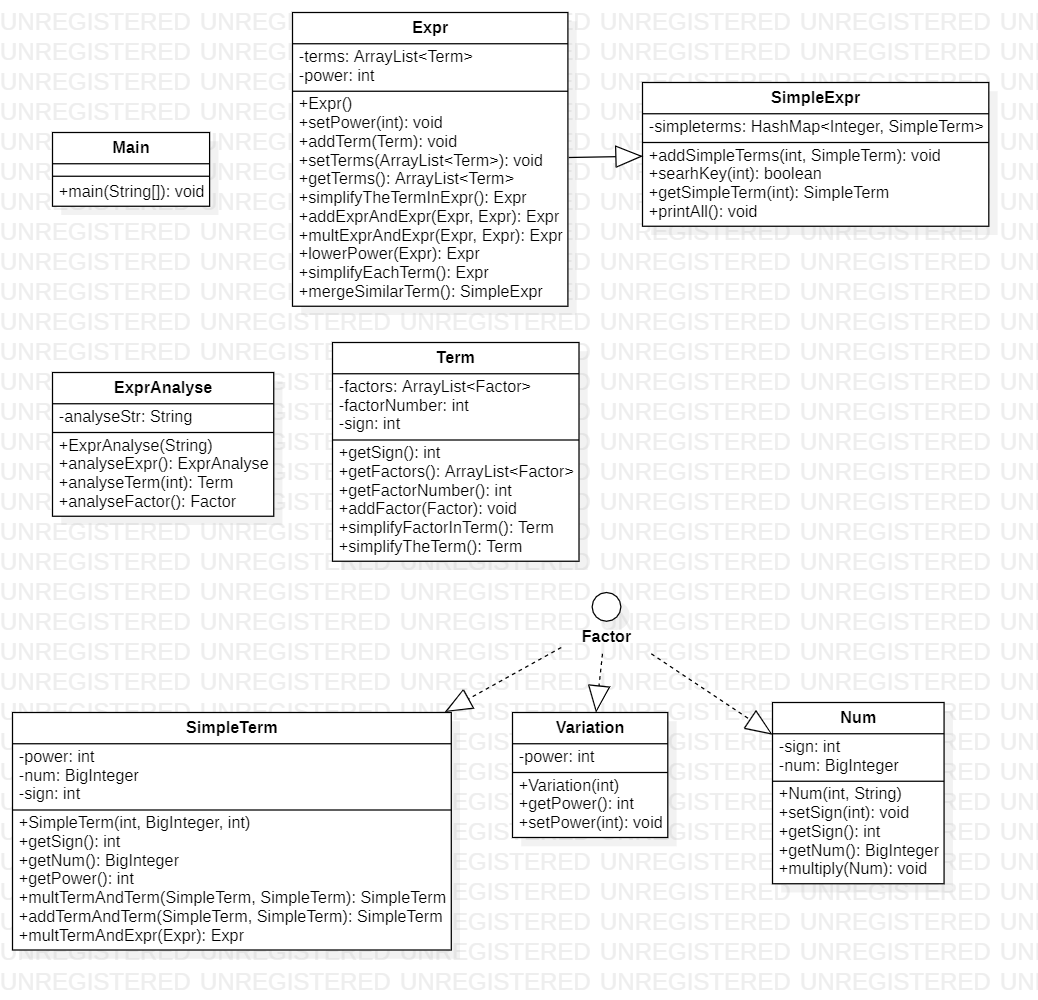
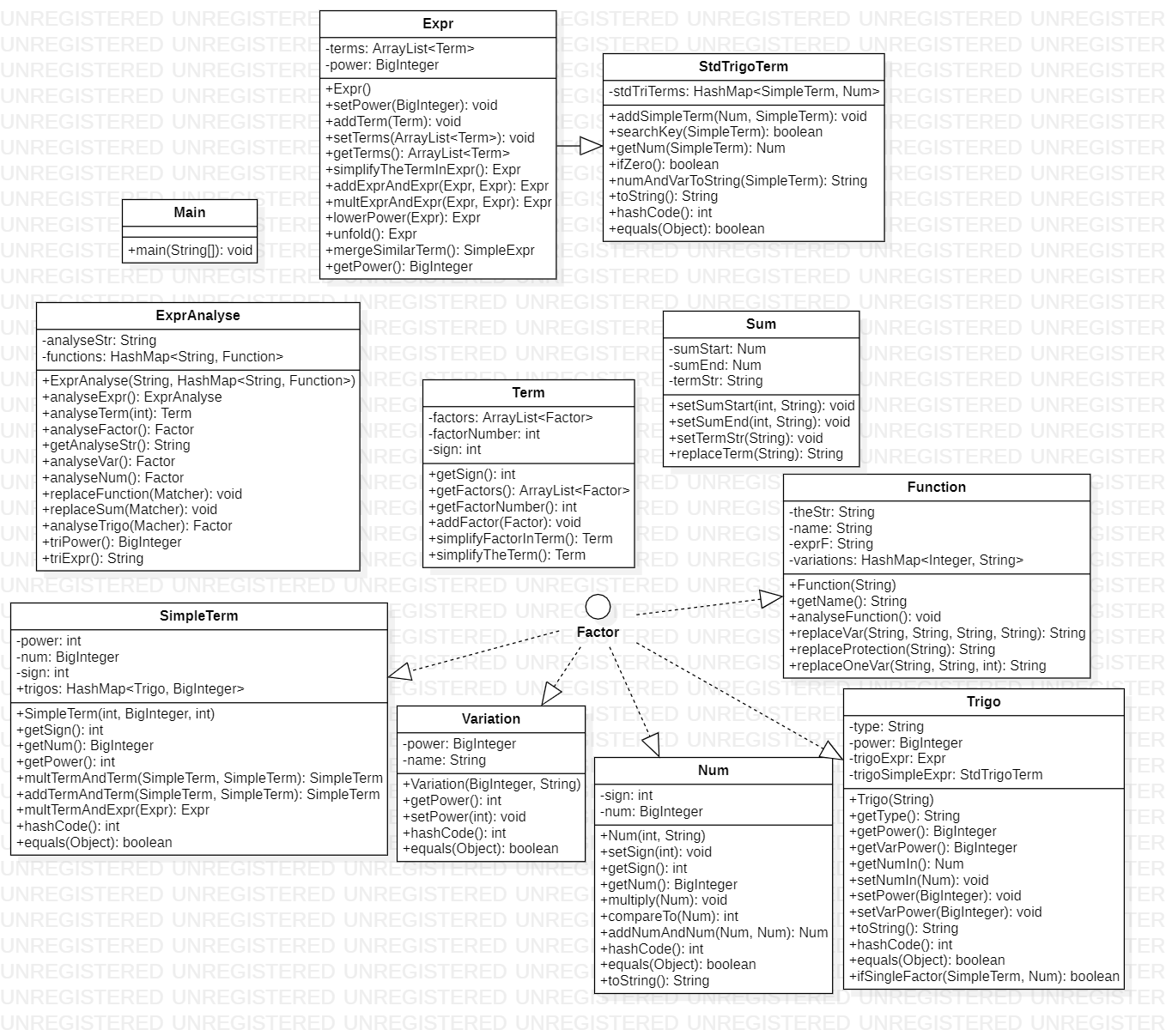
三次作业的UML类图及架构分析、代码分析
首先,本次第一单元的三次作业基本沿用了第一次的架构,但是在第二单元的设计过程中,由于发现原来的一个类设计的不合理、扩展性弱,无法适应第二单元的需求只能进行大改,因此重新设计了该类,可以算是一次比较大的局部重构工作。PS:类中测试使用的入口方法就不展示在UML图中了。
第一次作业
架构UML图及实现方法分析
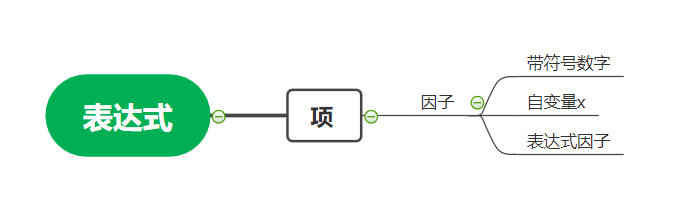
作业的思路分为四个步骤:解析->储存->化简->输出
第一次作业我采用了自顶向下的解析方法,设计了ExprAnalyse类用来逐层解析字符串,首先输入一个要解析的字符串,之后调用ExprAnalyse的analyseExpr方法,用正则表达式匹配的方式对表达式进行逐层的解析,其中把Expr的符号和第一个Term的符号都归到第一个Term里面,这样只有Term和带符号数字是有符号的,可以避免诸如“- - +1“之类的问题,层次解析的思路如下:
为了储存这些解析出来的内容,设计了Expr、Term和Num、Variation四个类,其中Num和Variation均是Factor接口的实现。这样就将刚才解析的内容储了起来,形成了Expr-Term-Factor三层结构。
之后是比较令人头疼的化简部分,由于表达式中的项又含有符号整数、变量等诸如”-100*x*x*+123“等非常不整齐的样子,所以我就想到了可以将每一项都化简成为”[符号]系数*x**指数“的形式,并为这种形式新建一个类名为SimpleTerm,这样就可以把每一项统一成一个形式。这样我们化简的思路就大概有了:统一形式->去括号->合并同类项。这个思路我一直沿用到第三次作业。
其中,统一形式由Term来实现,去括号主要由SimpleTerm中的项乘法和Expr中的表达式乘法实现,合并同类相主要由SimpleTerm中的项的加法和Expr中的表达式加法实现。最后都归结到一个SimpleExpr中进行输出。
架构的优缺点:
优点:
此次作业的优点是我基本把如何完成任务的思路理清楚了,而且建立了比较清晰的层次结构,这个整体的思路在后面两次作业中都没有变化过,避免了大规模的重构,但是在后面需求增长时还是对一个SimpleExpr这个不合适的类进行了局部性的重构。
缺点:
首先,没有考虑到后面嵌套括号的情况,所以在Factor的解析过程中对正则表达式的运用是有局限性的,降低了可扩展性。
其次,在进行输出的时候,选择了在SimpleExpr中写一个printAll方法进行整体输出,而不是在每一个因子中写一个toString方法进行”化整为零“的输出,这就导致了后续添加因子时需要增加SimpleExpr的printAll方法,使得这一方法非常冗长,也就导致了后来我对该类的一个局部重构。这一点也让我吸取了教训,应该在类的设计过程中,如果一个复杂的任务需要由多个类完成,最好的方式是把任务分配给每一个涉及到的类,让每一个类都调用自己的方法,最后用一个类整合所有的方法,而不是使用一个类的一个方法独立完成。这也让我体会到了面向对象设计的优雅之处。
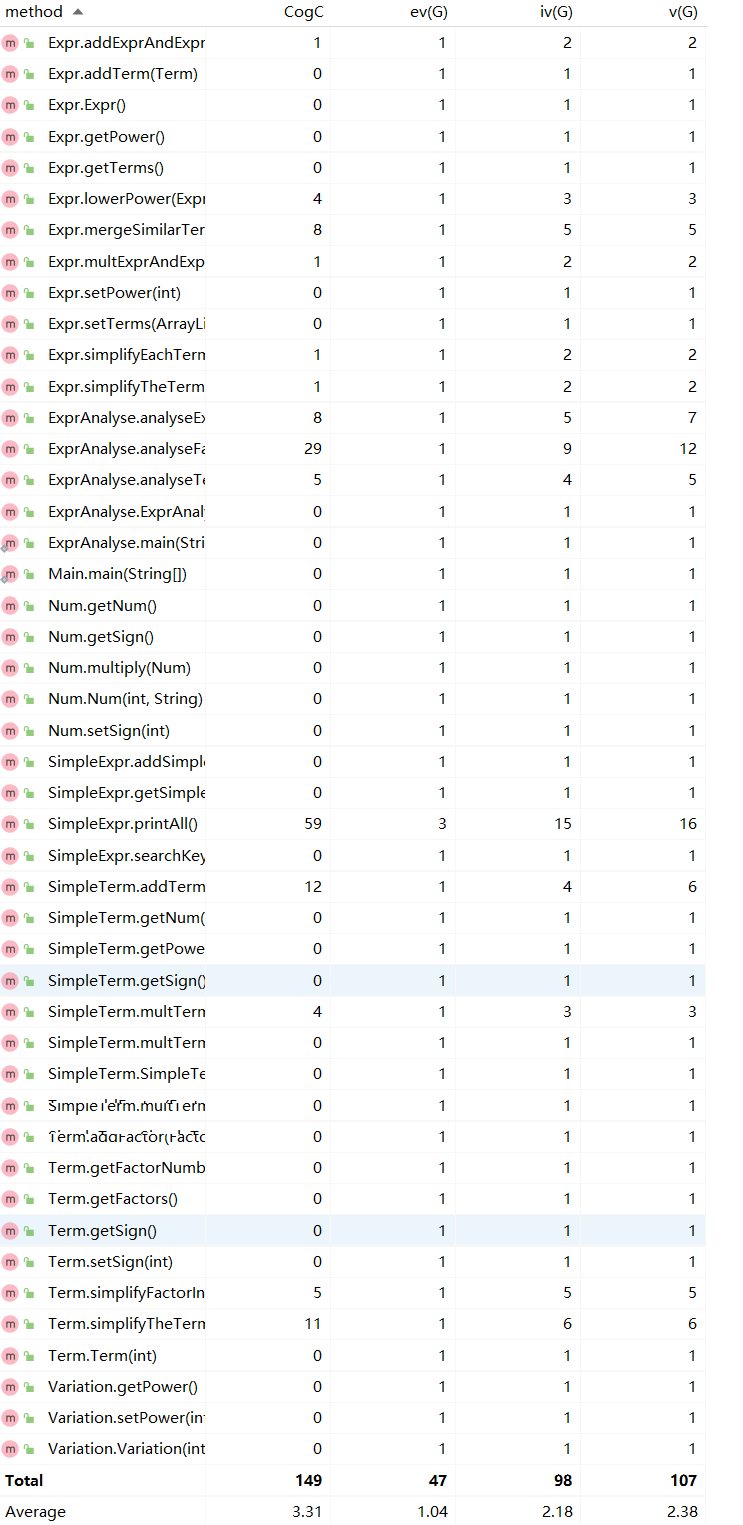
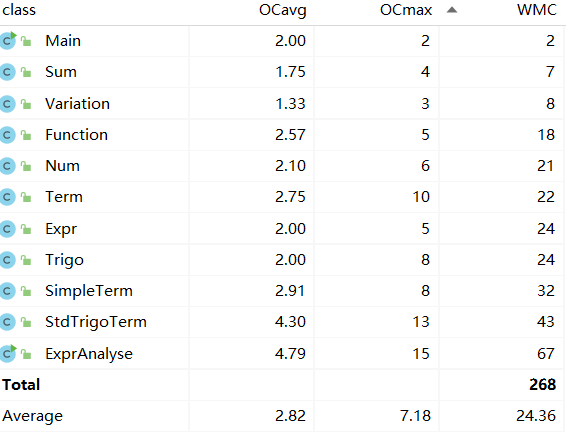
基于度量分析第一次作业的程序结构:
代码规模:

类的OO度量:

方法的复杂度度量:
第一次作业
架构UML图及实现方法分析

第二次作业的需求相比第一次作业有了更大的升级,增加了如下几个方面的内容:
1.括号嵌套
2.新增自定义函数因子,不可递归、不可嵌套
3.新增sum求和因子,不可以递归、不可嵌套
4.新增了sin、cos三角函数,其中内容是一个带符号整数或者变量因子
此次作业的难度应该是这三次作业中难度最大的一次,因为需求量暴增对于第一次作业没有处理好的部分是一次巨大的挑战。
为了应对括号嵌套问题,我先在解析表达式和化简得过程中使用了递归,使得在解析表达式因子的过程中再新建一个ExprAnalyse对象,达到可以解析嵌套括号的表达式的目的,而在化简得过程中,化简表达式也采用了递归处理。
对于新增的自定义函数因子和sum求和因子,先建立了Function和Sum类进行储存,之后可以用”字符串替换“的方式进行替换,不过此处我不是直接对字符串进行替换,而是在解析的过程中,如果遇到了自定义表达式调用或者sum求和因子再进行替换,这就可以在遵循原表达式结构不变的基础之上进行替换,经测试这样bug其实还是比较少的。
由于又涉及到了三角函数这个基本因子,因此我在化简得过程中,在SimpleTerm类里面又新增了一个HashMap用来储存三角函数对象以及对应的指数值。
优化
对于优化部分,我重写了一下hashCode和equals方法,因此可以采用hashmap的直接检索具有相同内容的三角函数对象进行相乘,以及检索具相同的SimpleTerm对象进行相加。不过其实重写hashCode方法具有一定的风险,很容易出一些隐形的bug,这一点跟助教讨论后得知可以直接使用java自带的hashCode更加方便和安全。
缺点
此次作业的缺点也比较地明显,因为我在写SimpleTrigoTerm的时候发现他其实和SimpleExpr差不多,但是后来由于时间的局限,就没有进行改动因此导致了代码的重复和冗余比较多,同时由于我重写了hashCode,有一些疏忽的地方也为后续的迭代埋下了雷。
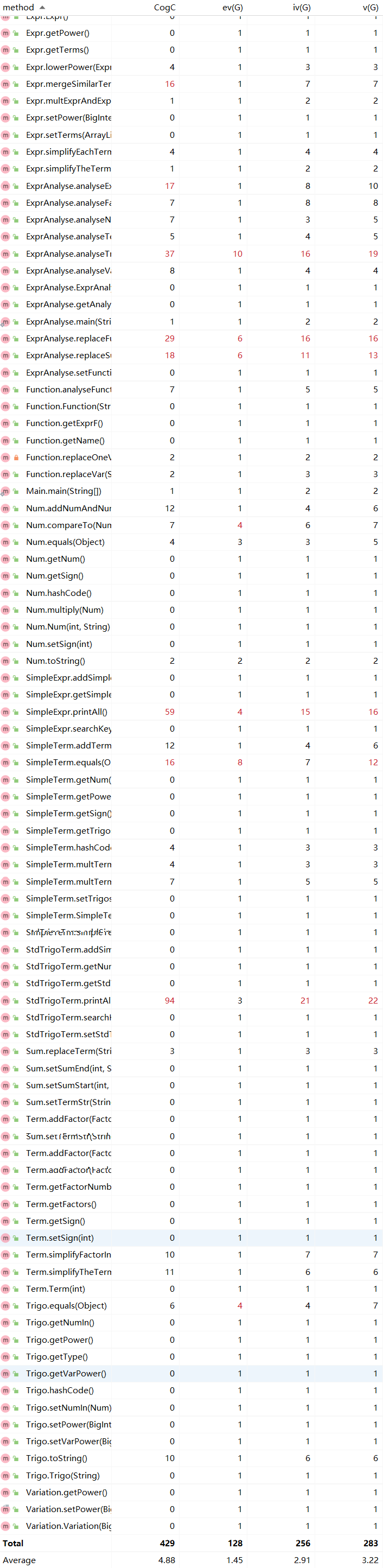
基于度量分析第二次作业的程序结构
代码规模

类的OO度量

方法的复杂度度量
第三次作业
架构UML图及实现方法分析
有了第二次作业设计的基础第三次作业其实就比较简单一点了,主要涉及到如下几个点:
1.自定义函数调用的实参可以是自定义函数调用或者sum
2.Trigo的内容可以是一个表达式因子
主要在升级的过程中,进一步给表达式因子重写hashCode,这样在计算Trigo的hashCode的时候可以直接调用,更加方便。在化简的过程中依然沿用第二次作业的思路。
但是由于第二次作业我写的比较冗余,所以在第三次作业就把SimpleExpr这个类删除了,直接用StdTrigoTerm来代替,同时在每一个需要输出的类内重写了toString方法,方便最后的输出。
缺点
调用的函数比较多,在递归调用时使用的内存空间较大,在计算多层嵌套时的速度会比较慢。
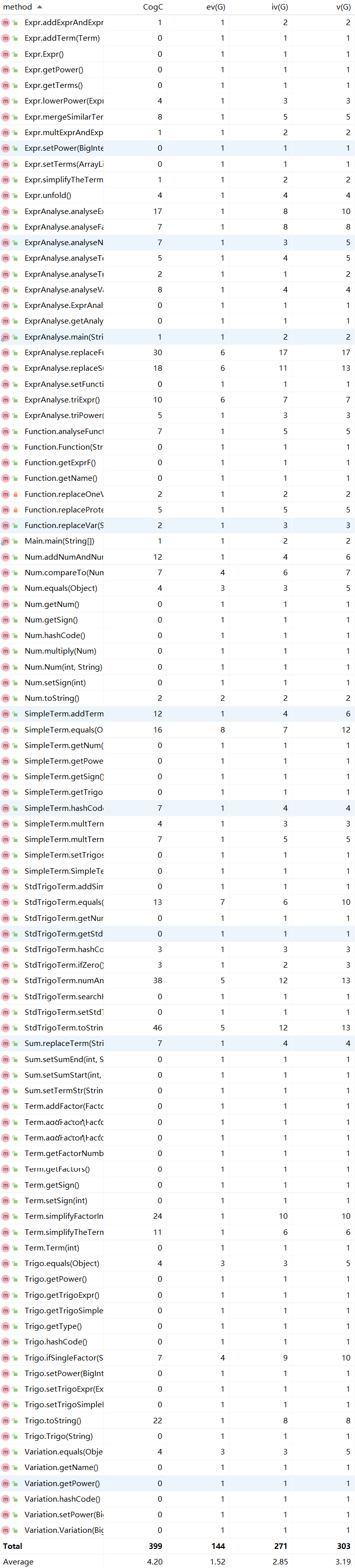
基于度量分析第二次作业的程序结构
代码规模

类的OO度量
方法的复杂度度量
二、bug分析
此次作业的bug主要集中在了第二次作业中。
第一次作业bug:中测通过,强测通过,互测0bug
第二次作业bug:中测通过,强测挂了6个point,互测被hack了5次
第三次作业bug:中测通过,强测挂了1个point,互测0hack
其中,第二次作业主要的bug是在输出的时候,本来应该判断hashMap中对应的系数输出,而当时错误地判断成了hashMap中的SimpleTerm的系数,由于在合并同类项的时候系数改变并没有同步更新到SimpleTerm中,所以就导致了最后输出的错误,造成强测和互测的失利。
在测试程序的过程中,我采用的手搓数据的方法,虽然效率比较低,但是可以保证每一个手搓的数据都比较有针对性,可以发现一些具有特色的奇怪bug。
三、单元设计体验和心得体会
对于编程能力不是很强的我来说,这一单元可谓是一个字:难!难在一开始思路就不好搞清楚,难在编程过程中对字符串处理有一些细节的地方需要花时间去做到位。
但是评价此单元作业的第二个字我觉得是:值!真的学到了不少的东西,比如hashMap、hashCode的使用,比如如何设计类,让不同的类各司其职,不至于某一个类太过于复杂,从而降低代码的复杂度,增加可维护性和可扩展性。体会到了面向对象的设计就像是艺术一样精妙。
希望在接下来的OO课程学习过程中再接再厉,更上一层楼。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号