第五章:向量嵌入技术
Many industries hope to have the capabilities of LLMs and hope that LLMs can solve their own internal problems. This includes employee-related content such as onboarding instructions, leave and reimbursement processes, and benefit inquiries. Enterprise business flow-related content includes relevant documents, regulations, execution processes, etc., as well as some customer-oriented inquiries. Although LLMs have strong knowledge capabilities, industry-based data and knowledge cannot be obtained. So how to inject this industry-based knowledge content? This is also an important step for LLMs to enter the corporate world. In this chapter, we will talk to you about how to inject industry data and knowledge to make LLMs more professional. This is the basis on which we create RAG applications.
许多行业都希望具备大语言模型(LLM)的能力,并期待LLM能解决其内部问题。这包括与员工相关的内容,如入职指引、请假与报销流程、福利查询等;企业业务流程相关的内容则涉及相关文档、规章制度、执行流程等,以及一些面向客户的咨询内容。尽管LLM拥有强大的知识能力,但行业相关的数据和知识却无法直接获取。那么,如何将这些行业知识注入模型呢?这也是LLM进入企业领域的关键一步。在本章中,我们将探讨如何通过注入行业数据和知识,使LLM更加专业化——这正是我们构建RAG(检索增强生成)应用的基础。
In the field of natural language, we know that the finest granularity is words, words constitute sentences, and sentences constitute paragraphs, chapters and final documents. Computers don't know words, so we need to convert words into mathematical representations. This representation is a vector, that is, Vector. Vector is a mathematical concept. It is a directional quantity with magnitude and direction. With vectors, we can effectively vectorize text, which is also the basis of the field of computer natural language. In the field of natural language processing, we have many vectorization methods, such as One-hot, TF-IDF, Word2Vec, Glove, ELMO, GPT, BERT, etc. These vectorization methods have their own advantages and disadvantages, but they are all based on word vectorization, that is, word vectors. Word vectors are the basis of natural language processing and the basis of all OpenAI models. Let’s look at several common methods in word vectors respectively.
在自然语言领域,我们知道最细的粒度是词语,词语构成句子,句子再组成段落、章节直至完整文档。计算机无法直接理解词语,因此需要将词语转化为数学表示形式——这种表示形式就是向量(Vector)。
向量是一个数学概念,指具有大小和方向的量。通过向量,我们可以有效地将文本向量化,这也是计算机自然语言处理领域的基础。在自然语言处理(NLP)中,存在多种文本向量化方法,例如:One-hot,TF-IDF,Word2Vec,Glove,ELMO,GPT,BERT这些方法各有优劣,但本质上都是基于词向量(Word Embedding)的技术。词向量是自然语言处理的基石,也是所有OpenAI模型的基础。接下来,我们将分别探讨词向量中的几种常见方法。
One-hot encoding uses 0 and 1 encoding to represent words. For example, we have 4 words, namely: I, love, Beijing, and Tiananmen. Then we can use 4 vectors to represent these 4 words, which are:
One-Hot编码采用0和1的组合来表示词语。例如,假设我们有4个词语,分别是: I, love, Beijing, 和 Tiananmen。那么我们可以用 4 个向量来表示这 4 个词,分别是:
I = [1, 0, 0, 0] love = [0, 1, 0, 0] Beijing = [0, 0, 1, 0] Tiananmen = [0, 0, 0, 1]
In traditional natural language application scenarios, we regard each word as represented by a One-Hot vector as a unique discrete symbol. The number of words in our vocabulary is the dimension of the vector. For example, the above example contains a total of four words, so we can use a four-dimensional vector to represent it. In this vector, each word is unique, which means that each word is independent and has no relationship. Such vectors are called One-Hot vectors. The advantage of One-Hot vector is that it is simple, easy to understand, and each word is unique without any relationship. However, the disadvantage of One-Hot vector is also obvious, that is, the dimension of the vector will increase as the number of words increases. For example, if we have 1000 words, then our vector will be 1000 dimensions. Such a vector is very sparse, that is, most of its values are 0. Such vectors will cause a very large amount of computer calculations and are not conducive to computer calculations. Therefore, the disadvantage of One-Hot encoding is that the vector dimension is large, the calculation amount is large, and the calculation efficiency is low.
在传统自然语言处理应用场景中,我们将每个词视为由One-Hot向量表示的独立离散符号。此时,词汇表的大小决定了向量的维度。以上述示例为例,四个单词对应四维向量表示。在这种向量表示中,每个词都是独一无二的,这意味着词语之间完全独立且不存在任何关联关系。这种向量被称为One-Hot向量。One-Hot向量的优势在于其简单直观,每个词都具有唯一性表示。但它的缺陷也十分明显:向量维度会随着词汇量增长而急剧增加。例如,当词汇量达到1000个时,向量维度就会扩展至1000维。这样的向量会导致计算机的计算量非常大,而且也不利于计算机的计算。所以 One-Hot 编码的缺点就是向量维度大,计算量大,计算效率低。
TF-IDF is a statistic that evaluates the importance of a word to a corpus. TF-IDF is the abbreviation of Term Frequency - Inverse Document Frequency, which is called Term Frequency-Inverse Document Frequency in Chinese. The main idea of TF-IDF is: if a word appears frequently in an article and rarely appears in other articles, then this word is the keyword of this article. Generally, we are used to splitting this concept into two parts: TF and IDF.
TF-IDF(词频-逆文档频率)是一种用于评估词语在语料库中重要程度的统计方法。。TF-IDF 是 Term Frequency - Inverse Document Frequency 的缩写,中文叫做词频-逆文档频率。TF-IDF的核心思想是:若某个词在特定文档中出现频率高,而在其他文档中出现频率低,则该词可视为该文档的关键词。一般我们习惯把这个概念拆分,分为 TF 和 IDF 两个部分。其中:TF(Term Frequency,词频)表示某个词在文档中出现的频率,IDF(Inverse Document Frequency,逆文档频率)衡量该词在整个语料库中的稀有程度。
TF - Term Frequency TF(Term Frequency,词频)
Term Frequency refers to the frequency with which a word appears in an article. The formula for calculating word frequency is as follows:
词频(Term Frequency,TF)指某个词语在文档中出现的频率,其计算公式如下:
TF = The number of times a word appears in the article / the total number of words in the article
TF = 某个词在文章中出现的次数 / 文章的总词数
One problem with TF is that if a word appears many times in an article, the TF value of the word will be very large. In this case, we will consider this word to be the keyword of this article. But in this case, we will find that many words are keywords in this article. In this case, we will not be able to distinguish which words are keywords in this article. So we need to make some adjustments to TF, and this adjustment is IDF.
TF(词频)存在一个显著问题:若某个词在文章中频繁出现,其TF值会变得极大,导致系统可能将大量高频词都判定为文章关键词。这种情况会使我们难以区分真正具有代表性的关键词。因此,我们需要对TF值进行修正——这就是引入IDF(逆文档频率)的原因。
Inverse Document Frequency refers to the frequency of a certain word appearing in all articles. The formula for calculating inverse document frequency is as follows:
逆文档频率(Inverse Document Frequency,IDF)用于衡量某个词语在所有文档中的出现频率,其计算公式如下:
IDF = log(Total number of documents in the corpus / (number of documents containing the word + 1))
IDF = log(语料库的文档总数 / (包含该词的文档数 + 1))
In the calculation formula of IDF, 1 is added to the denominator to avoid the situation where the denominator is 0. In the calculation formula of IDF, the total number of documents in the corpus is fixed, so we only need to calculate the number of documents containing the word. If a word appears in many articles, the IDF value of this word will be small. If a word appears in few articles, the IDF value of this word will be large. In this case, we can calculate the TF-IDF value of a word by multiplying TF and IDF. The calculation formula of TF-IDF is as follows:
IDF 的计算公式中,分母加 1 是为了避免分母为 0 的情况。IDF 的计算公式中,语料库的文档总数是固定的,所以我们只需要计算包含该词的文档数就可以了。如果一个词在很多文章中都出现,那么这个词的 IDF 值就会很小。如果一个词在很少的文章中出现,那么这个词的 IDF 值就会很大。这样的话,我们就可以通过 TF 和 IDF 的乘积来计算一个词的 TF-IDF 值。TF-IDF 的计算公式如下:
TF-IDF = TF * IDF
We also call Word2Vec Word Embeddings, which is called word embedding in Chinese. The main idea of Word2Vec is that the semantics of a word can be determined by its context. Word2Vec has two models, CBOW and Skip-Gram. CBOW is the abbreviation of Continuous Bag-of-Words, which is called the continuous bag-of-words model in Chinese. Skip-Gram is the abbreviation of Skip-Gram Model, which is called skip model in Chinese. The idea of the CBOW model is to predict a word through its context. The idea of the Skip-Gram model is to predict the context of a word from a word. The advantage of Word2Vec is that it can get the semantics of words and the relationship between words. Compared with One-Hot encoding and TF-IDF encoding, the advantage of Word2Vec encoding is that it can obtain the semantics of words and the relationship between words. The disadvantage of Word2Vec encoding is that it is computationally intensive and requires a large corpus.
Word2Vec 我们也叫它做 Word Embeddings,中文叫做词嵌入。Word2Vec 的主要思想是:一个词的语义可以通过它的上下文来确定。Word2Vec 有两种模型,分别是 CBOW 和 Skip-Gram。CBOW 是 Continuous Bag-of-Words 的缩写,中文叫做连续词袋模型。Skip-Gram 是 Skip-Gram Model 的缩写,中文叫做跳字模型。CBOW 模型的思想是通过一个词的上下文来预测这个词。Skip-Gram 模型的思想是通过一个词来预测这个词的上下文。对比 One-Hot 编码和 TF-IDF 编码,Word2Vec 编码的优点是可以得到词的语义,而且可以得到词与词之间的关系。Word2Vec 编码的缺点是计算量大,而且需要大量的语料库。
We mentioned before that the dimension of One-Hot encoding is the number of words, while the dimension of Word2Vec encoding can be specified. Generally we will specify 100 dimensions or 300 dimensions. The higher the dimensionality of Word2Vec encoding, the richer the relationships between words, but the greater the computational complexity. The lower the dimensionality of Word2Vec encoding, the simpler the relationship between words, but the smaller the calculation amount. The dimensionality of Word2Vec encoding is generally 100 or 300 dimensions, which can meet most application scenarios.
之前我们提及过,One-Hot 编码的维度是词的个数,而 Word2Vec 编码的维度是可以指定的。一般我们会指定为 100 维或者 300 维。Word2Vec 编码的维度越高,词与词之间的关系就越丰富,但是计算量也就越大。Word2Vec 编码的维度越低,词与词之间的关系就越简单,但是计算量也就越小。Word2Vec 编码的维度一般是 100 维或者 300 维,这样的维度可以满足大部分的应用场景。
The calculation formula of Word2Vec encoding is very simple, which is Word Embeddings. Word Embeddings is a word vector whose dimensions can be specified. The dimensions of Word Embeddings are generally 100 or 300 dimensions, which can meet most application scenarios. The calculation formula for Word Embeddings is as follows:
Word2Vec编码的计算公式非常简单,其实就是生成词向量(Word Embeddings)。Word Embeddings 是一个词向量,它的维度是可以指定的。Word Embeddings 的维度一般是 100 维或者 300 维,这样的维度可以满足大部分的应用场景。Word Embeddings 的计算公式如下:
Word Embeddings = Semantics of words + relationships between words
Word Embeddings = 词的语义 + 词与词之间的关系
Think of Word2Vec as a simplified neural network.
可以把 Word2Vec 看作是简单化的神经网络。
The full name of the GPT model is Generative Pre-Training, which is called pre-training generative model in Chinese. The GPT model was proposed by OpenAI in 2018. Its main idea is that the semantics of a word can be determined through its context. The advantage of the GPT model is that it can obtain the semantics of words and the relationship between words. The disadvantage of the GPT model is that it is computationally intensive and requires a large corpus. The structure of the GPT model is a multi-layered unidirectional Transformer structure. Its structure is shown in the figure below:
GPT 模型的全称是 Generative Pre-Training,中文叫做预训练生成模型。GPT 模型是 OpenAI 在 2018 年提出的,它的主要思想是:一个词的语义可以通过它的上下文来确定。GPT 模型的优点是可以得到词的语义,而且可以得到词与词之间的关系。GPT 模型的缺点是计算量大,而且需要大量的语料库。GPT 模型的结构是一个多层单向的 Transformer 结构,它的结构如下图所示:
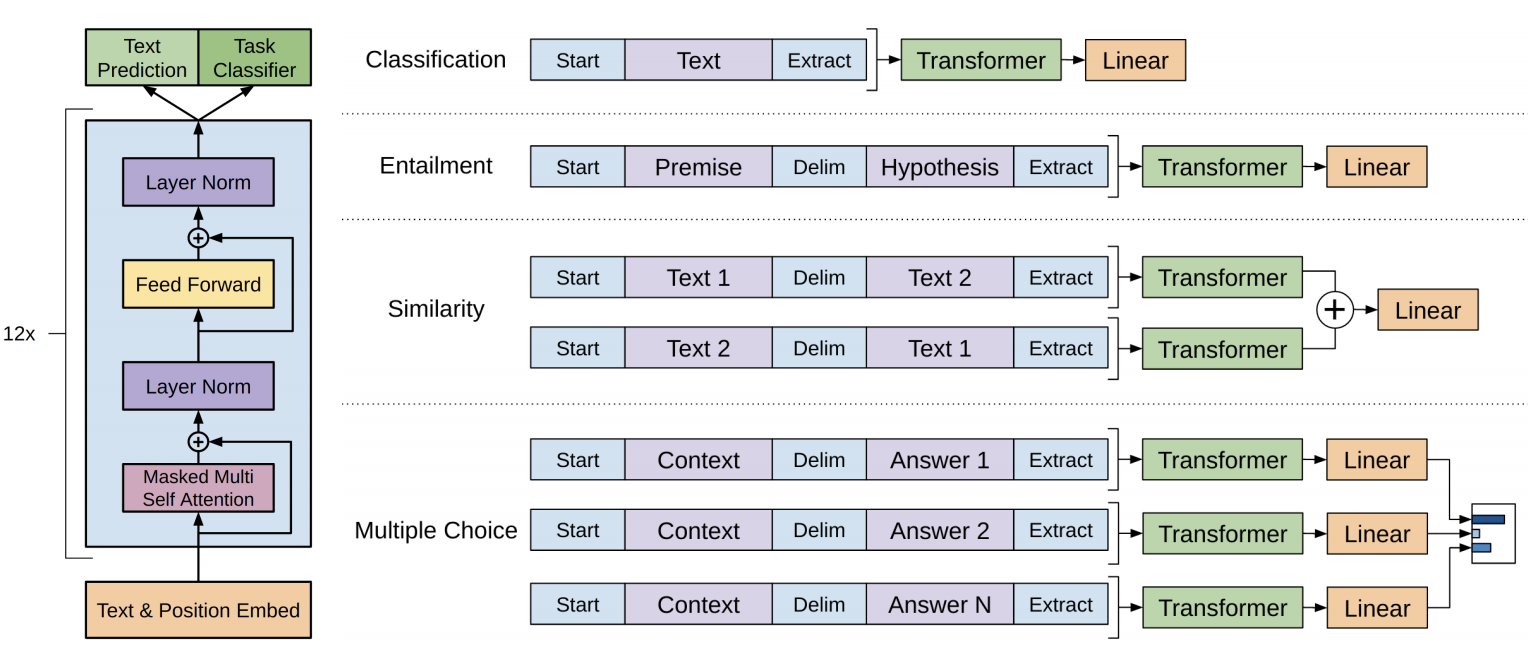
The training process is divided into two stages, the first stage is pre-training and the second stage is fine-tuning. The pre-training corpora are Wikipedia and BookCorpus, and the fine-tuning corpora are different natural language tasks. The goal of pre-training is to predict a word through its context, and the goal of fine-tuning is to fine-tune the semantic model to obtain different models based on different natural language tasks, such as text classification, text generation, question and answer systems, etc.
训练过程分为两个阶段:第一阶段是预训练(pre-training),第二阶段是微调(fine-tuning)。预训练采用的语料是维基百科和BookCorpus数据集,而微调则根据不同自然语言处理任务使用相应的语料。预训练的目标是通过上下文预测词语,微调的目标则是调整语义模型,使其适配不同的自然语言处理任务——例如文本分类、文本生成、问答系统等——从而获得针对不同任务的定制化模型。
The GPT model has gone through four stages, the most famous of which are GPT-3.5 and GPT 4 used by ChatGPT. GPT opens a new era, and its emergence allows us to see the infinite possibilities of natural language processing. The advantage of the GPT model is that it can obtain the semantics of words and the relationship between words. The disadvantage of the GPT model is that it is computationally intensive and requires a large corpus. Many people hope to have a GPT that benchmarks their own industry. This is also a problem we need to solve in this chapter.
GPT模型的发展历经四个阶段,其中最负盛名的当属ChatGPT所采用的GPT-3.5和GPT-4版本。GPT开创了一个全新时代,它的出现让我们看到了自然语言处理的无限可能。该模型的优势在于能够捕捉词语语义及词间关联,但其劣势是计算资源消耗巨大且需依赖海量语料库。目前许多从业者都期待能打造出适配自身行业的GPT基准模型,这也正是本章需要解决的核心问题。
BERT is the abbreviation of Bidirectional Encoder Representations from Transformers, which is called Transformer of Bidirectional Encoder in Chinese. BERT is a pre-trained model, and its training corpus is Wikipedia and BookCorpus. The main idea of BERT is that the semantics of a word can be determined by its context. The advantage of BERT is that it can obtain the semantics of words and the relationship between words. Compared with One-Hot encoding, TF-IDF encoding and Word2Vec encoding, the advantage of BERT encoding is that it can obtain the semantics of words and the relationship between words. The disadvantage of BERT encoding is that it is computationally intensive and requires a large corpus.
BERT 是 Bidirectional Encoder Representations from Transformers 的缩写,中文叫做双向编码器的 Transformer。BERT 是一个预训练的模型,它的训练语料是维基百科和 BookCorpus。BERT 的主要思想是:一个词的语义可以通过它的上下文来确定。对比起 One-Hot 编码、TF-IDF 编码和 Word2Vec 编码,BERT 编码的优点是可以得到词的语义,而且可以得到词与词之间的关系。BERT 编码的缺点是计算量大,而且需要大量的语料库。
We mentioned One-Hot encoding, TF-IDF encoding, Word2Vec encoding, BERT encoding, and GPT models. These codes and models are all a type of Embeddings embedding technology. Embeddings The main idea of embedding technology is that the semantics of a word can be determined by its context. The advantage of Embeddings technology is that it can obtain the semantics of words and the relationship between words. Embeddings are the basis of natural language deep learning. Its emergence allows us to see the infinite possibilities of natural language processing.
我们提及了 One-Hot 编码、TF-IDF 编码、Word2Vec 编码、BERT 编码和 GPT 模型。这些编码和模型都是 Embeddings 嵌入技术的一种。Embeddings 嵌入技术的主要思想是:一个词的语义可以通过它的上下文来确定。Embeddings 嵌入技术的优点是可以得到词的语义,而且可以得到词与词之间的关系。Embeddings 是作为自然语言深度学习的基础,它的出现让我们看到了自然语言处理的无限可能。
For the Embeddings method of text content, let’s combine it with the previous section. You will find that since the birth of word2vec technology, the Embeddings of text content have been continuously strengthened. From word2vec to GPT to BERT, the effect of Embeddings technology is getting better and better. The essence of Embeddings technology is "compression", using fewer dimensions to represent more information. The advantage of this is that it can save storage space and improve computing efficiency.
对于文本内容的 Embeddings 方法,我们结合上一节,你会发现从 word2vec 技术诞生后,文本内容的 Embeddings 就不断得到加强,从 word2vec 到 GPT 再到 BERT ,Embeddings 技术的效果越来越好 。Embeddings 技术的本质就是“压缩”,用更少的维度来表示更多的信息。这样的好处是可以节省存储空间,提高计算效率。
In Azure OpenAI Service, Embeddings technology is widely used to convert text strings into floating-point vectors and measure the similarity between texts by the distance between vectors. If different industries want to add their own data, we can use these enterprise-level data to query the vectors through the OpenAI Embeddings - text-embedding-ada-002 model, and save them through mapping. When using them, we can also convert the questions into vectors, and use similar Compare the algorithms to find the closest TopN results, so as to find the enterprise content related to the problem.
在 Azure OpenAI Service 中,Embeddings 技术的应用非常广泛,将文本字符串转换为浮点向量,通过向量之间的距离来衡量文本之间的相似度。不同行业希望加入自己的数据 我们就可以把这些企业级的数据通过 OpenAI Embeddings - text-embedding-ada-002 模型查询出向量,并通过映射进行保存,在使用时将问题也转换为向量,通过相似度的算法对比,找出最接近的 TopN 结果,从而找到与问题相关联的企业内容。
We can vectorize the enterprise data through the vector database and save it, and then use the text-embedding-ada-002 model to query through the similarity of the vectors to find the enterprise content associated with the problem. Commonly used vector databases include Qdrant, Milvus, Faiss, Annoy, NMSLIB, etc.
我们可以通过向量数据库将企业数据向量化后保存,结合 text-embedding-ada-002 模型通过向量的相似度进行查询,从而找到与问题相关联的企业内容。现在常用的向量数据库就包括 Qdrant, Milvus, Faiss, Annoy, NMSLIB 等。
Correlation of text strings with text embedding vectors from OpenAI. Embedding is usually used in the following scenarios
文本字符串与OpenAI文本嵌入向量的关联性。嵌入技术通常适用于以下场景:
- Search (results sorted by relevance to query string) 搜索(结果按与查询字符串的相关性排序)
- Clustering (where text strings are grouped by similarity) 聚类(其中文本字符串按相似性分组)
- Recommend (recommend items with relevant text strings) 推荐(推荐具有相关文本字符串的项目)
- Anomaly detection (identify outliers with little correlation) 异常检测(识别出相关性很小的异常值)
- Diversity measurement (analyzing similarity distribution) 多样性测量(分析相似性分布)
- Classification (where text strings are classified by their most similar tags) 分类(其中文本字符串按其最相似的标签分类)
Embeddings are vectors (lists) of floating point numbers. The distance between two vectors measures their correlation. Small distances indicate high correlation, and large distances indicate low correlation. For example, if you have a string "dog" with an embedding of [0.1,0.2,0.3], that string is more similar to a string "cat" with an embedding of [0.2,0.3,0.4] than to a string "cat" with an embedding of [0.9,0.8 ,0.7] the string "car" is more relevant.
嵌入是浮点数的向量(列表)。 两个向量之间的距离衡量它们的相关性。 小距离表示高相关性,大距离表示低相关性。 例如,如果您有一个嵌入为[0.1,0.2,0.3]的字符串“狗”,则该字符串与嵌入为[0.2,0.3,0.4]的字符串“猫”比与嵌入为[0.9,0.8,0.7]的字符串“汽车”更相关。
The support for Embeddings in Semantic Kernel is very good. In addition to supporting text-embedding-ada-002, it also supports vector databases. Semantic Kernel abstracts the vector database, and developers can use a consistent API to call the vector database. This case uses Qdrant as an example. In order for you to run the example smoothly, please install Docker first, install the Qdrant container and run it. The running script is as follows:
Semantic Kernel 对嵌入技术的支持非常完善。除了支持 text-embedding-ada-002 模型外,还兼容多种向量数据库。Semantic Kernel 对向量数据库进行了抽象封装,开发者可以通过统一的 API 接口调用向量数据库功能。 本次案例以 Qdrant 为例,为了您顺利运行例子,请先安装好 Docker,并安装好 Qdrant 容器并运行,运行脚本如下:
docker pull qdrant/qdrant docker run -p 6333:6333 qdrant/qdrant
Add Nuget library
添加 Nuget 引用
#r "nuget: Microsoft.SemanticKernel.Connectors.Qdrant, *-*"
Reference library
引用库
using Microsoft.SemanticKernel.Memory; using Microsoft.SemanticKernel.Connectors.Qdrant;
Create instances and Memory bindings
创建实例并建立 Memory 绑定
var textEmbedding = new AzureOpenAITextEmbeddingGenerationService("Your Azure OpenAI Service Embedding Models Deployment Name" , "Your Azure OpenAI Service Endpoint", "Your Azure OpenAI Service API Key"); var qdrantMemoryBuilder = new MemoryBuilder(); qdrantMemoryBuilder.WithTextEmbeddingGeneration(textEmbedding); qdrantMemoryBuilder.WithQdrantMemoryStore("http://localhost:6333", 1536); var qdrantBuilder = qdrantMemoryBuilder.Build();
Note: Semantic Kernel Memory component is still in the adjustment stage, so you need to pay attention to the risk of interface changes, and you also need to ignore the following information
注意: Memory 组件还在调整阶段所以你需要注意接口有改变风险,还需要忽略以下信息
#pragma warning disable SKEXP0003 #pragma warning disable SKEXP0011 #pragma warning disable SKEXP0026
In Semantic Kernel, the methods of different vector data are unified through abstraction. You can easily save and search your vectors.
在 Semantic Kernel 中,通过抽象化设计统一了各类向量数据的操作方法,开发者可以轻松实现向量的存储与检索。
Save vector data
存储向量数据
await qdrantBuilder.SaveInformationAsync(conceptCollectionName, id: "info1", text: "Kinfey is Microsoft Cloud Advocate"); await qdrantBuilder.SaveInformationAsync(conceptCollectionName, id: "info2", text: "Kinfey is ex-Microsoft MVP"); await qdrantBuilder.SaveInformationAsync(conceptCollectionName, id: "info3", text: "Kinfey is AI Expert"); await qdrantBuilder.SaveInformationAsync(conceptCollectionName, id: "info4", text: "OpenAI is a company that is developing artificial general intelligence (AGI) with widely distributed economic benefits.");
Search vector data
检索向量数据
string questionText = "Do you know kinfey ?"; var searchResults = qdrantBuilder.SearchAsync(conceptCollectionName, questionText, limit: 3, minRelevanceScore: 0.7); await foreach (var item in searchResults) { Console.WriteLine(item.Metadata.Text + " : " + item.Relevance); }
You can easily and conveniently access any vector database to complete related operations, which also means that you can build RAG applications very simply.
您可以非常简单方便地接入任意的向量数据库来完成相关的操作,也意味着您可以非常轻松地构建 RAG 应用。
.NET Sample Please click here .NET 例子 请点击访问这里
Python Sample Please click here Python 例子 请点击访问这里
Many enterprise data enter LLMs using Embeddings to build RAG applications. Semantic Kernel gives us a very simple way to complete related functions in both Python and .NET, so it is very helpful for those who want to add RAG applications to their projects.
当前,众多企业通过Embeddings技术将数据接入大语言模型(LLMs)来构建RAG应用。Semantic Kernel为此提供了极其便捷的实现方案,同时支持Python和.NET双平台的相关功能开发。这一特性使得项目集成RAG应用变得异常简单,对开发者极具实用价值。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号