烂翻译系列之学习领域驱动设计——第十一章:演进设计决策
In the modern, fast-paced world we inhabit, companies cannot afford to be lethargic. To keep up with the competition, they have to continually change, evolve, and even reinvent themselves over time. We cannot ignore this fact when designing systems, especially if we intend to design software that’s well adapted to the requirements of its business domain. When changes are not managed properly, even the most sophisticated and thoughtful design will eventually become a nightmare to maintain and evolve. This chapter discusses how changes in a software project’s environment can affect design decisions and how to evolve the design accordingly. We will examine the four most common vectors of change: business domain, organizational structure, domain knowledge, and growth.
在我们所生活的现代化、快节奏的世界里,公司不能懈怠。为了跟上竞争的步伐,它们必须与时俱进,甚至重塑自我。在设计系统时,我们绝不能忽视这一事实,尤其是当我们打算设计能够适应其业务领域需求的软件时。如果变化没有得到妥善管理,即使是最巧妙和最周到的设计最终也会成为维护和演化的噩梦。本章讨论了软件项目环境中的变化如何影响设计决策以及如何相应地演变设计。我们将探讨四种最常见的变化向量:业务领域、组织结构、领域知识和增长。
Changes in Domains
领域变化
In Chapter 2, you’ve learned the three types of business subdomains and how they are different from one another:
在第二章中,你已经了解了三种类型的业务子域,以及它们之间的区别:
Core 核心子域
Activities the company is performing differently from its competitors to gain a competitive advantage 公司正在进行的与竞争对手不同的活动,以获得竞争优势
Supporting 支撑子域
Things the company is doing differently from its competitors, but that do not provide a competitive edge 公司正在做的与竞争对手不同的事情,但这些并没有带来竞争优势
Generic 通用子域
Things all companies do in the same way 所有公司都以相同方式做的事情
In the previous chapters, you saw that the type of subdomain at play affects strategic and tactical design decisions:
在前面的章节中,您看到了子域的类型影响战略和战术设计决策:
翻译:在之前的章节中,您已经看到所涉及的子域类型会影响战略和战术设计决策:
- How to design the bounded contexts’ boundaries 如何设计有界上下文的边界
- How to orchestrate integration between the contexts 如何协调上下文之间的集成
- Which design patterns to use to accommodate the complexity of the business logic 使用哪种设计模式来适应业务逻辑的复杂性
To design software that is driven by the business domain’s needs, it’s crucial to identify the business subdomains and their types. However, that’s not the whole story. It’s equally important to be alert to the evolution of the subdomains. As an organization grows and evolves, it’s not unusual for some of its subdomains to morph from one type to another. Let’s look at some examples of such changes.
要设计由业务领域需求驱动的软件,识别业务子域及其类型是至关重要的。然而,这并不是全部,同样重要的是要对子域的演变保持警惕。随着组织的成长和发展,它的一些子域从一种类型转变为另一种类型并不罕见。让我们看看这些变化的一些例子。
Core to Generic
核心子域转变为通用子域
Imagine that an online retail company called BuyIT has been implementing its own order delivery solution. It developed an innovative algorithm to optimize its couriers’ delivery routes and thus is able to charge lower delivery fees than its competitors.
假设一个名为BuyIT的在线零售公司一直在实施自己的订单配送解决方案。它开发了一种创新的算法来优化快递员的配送路线,因此能够向顾客收取比竞争对手更低的配送费用。
One day, another company—DeliverIT—disrupts the delivery industry. It claims it has solved the “traveling salesman” problem and provides path optimization as a service. Not only is DeliverIT’s optimization more advanced, it is offered at a fraction of the price that it costs BuyIT to perform the same task.
有一天,另一家公司DeliverIT颠覆了配送行业。它声称已经解决了“旅行商”问题,并将路径优化作为服务提供。DeliverIT的优化不仅更先进,而且其价格仅为BuyIT执行相同任务所需成本的一小部分。
From BuyIT’s perspective, once DeliverIT’s solution became available as an off-the-shelf product, its core subdomain turned into a generic subdomain. As a result, the optimal solution became available to all of BuyIT’s competitors. Without massive investments in research and development, BuyIT can no longer gain a competitive advantage in the path optimization subdomain. What was previously considered a competitive advantage for BuyIT has become a commodity available to all of its competitors.
从BuyIT的角度来看,一旦DeliverIT的解决方案作为一款现成的产品上市,BuyIT的核心业务子域就变成了通用子域。因此,BuyIT的所有竞争对手都可以获得最佳解决方案。如果没有大量的研发投入,BuyIT 就不能在路径优化子领域获得竞争优势。以前被认为是BuyIT的竞争优势,现在已经变成了所有竞争对手都可以获得的商品。
Generic to Core
通用子域转变为核心子域
Since its inception, BuyIT has been using an off-the-shelf solution to manage its inventory. However, its business intelligence reports are continuously showing inadequate predictions of its customers’ demands. Consequently, BuyIT fails to replenish its stock of the most popular products and is wasting warehouse real estate on the unpopular products. After evaluating a few alternative inventory management solutions, BuyIT’s management team makes the strategic decision to invest in designing and building an in-house system. This in-house solution will consider the intricacies of the products BuyIT sells and make better predictions of customers’ demands.
自创立以来,BuyIT一直使用现成的解决方案来管理其库存。然而,其商业智能报告不断显示对客户需求的预测不足。因此,BuyIT无法及时补充最畅销产品的库存,并在不受欢迎的产品上浪费了仓库空间。在评估了几种替代的库存管理解决方案后,BuyIT的管理团队做出了战略决策,即投资设计和构建内部系统。这个内部解决方案将考虑BuyIT销售产品的复杂性,并更好地预测客户需求。
BuyIT’s decision to replace the off-the-shelf solution with its own implementation has turned inventory management from a generic subdomain into a core subdomain: successful implementation of the functionality will provide BuyIT additional competitive advantage over its competitors—the competitors will remain “stuck” with the generic solution and will not be able to use the advanced demand prediction algorithms invented and developed by BuyIT.
BuyIT决定将现成的解决方案替换为自己的实现,使库存管理从通用子域转变为核心子域:成功实现该功能将使BuyIT相对于竞争对手获得额外的竞争优势——竞争对手将继续“坚持”使用通用解决方案,并且无法使用BuyIT发明和开发的先进需求预测算法。
A real-life textbook example of a company turning a generic subdomain into a core subdomain is Amazon. Like all service providers, Amazon needed an infrastructure on which to run its services. The company was able to “reinvent” the way it managed its physical infrastructure and later even turned it into a profitable business: Amazon Web Services.
亚马逊是将通用子域转变为核心子域的现实教科书案例的一家公司。像所有的服务提供商一样,亚马逊需要一个运行其服务的基础设施。该公司能够“重造”管理其物理基础设施的方式,后来甚至把它变成了一个有利可图的业务: Amazon Web Services(亚马逊网络服务)。
Supporting to Generic
支撑子域转变为通用子域
BuyIT’s marketing department implements a system for managing the vendors it works with and their contracts. There is nothing special or complex about the system—it’s just some CRUD user interfaces for entering data. In other words, it is a typical supporting subdomain.
BuyIT 的市场部实现了一个系统来管理与之合作的供应商及其合同。该系统没有什么特别或复杂的地方——它只是一些用于输入数据的 CRUD 用户接口。换句话说,它是一个典型的支撑子域。
However, a few years after BuyIT began implementing the in-house solution, an open source contracts management solution came out. The open source project implements the same functionality as the existing solution and has more advanced features, like OCR and full-text search. These additional features had been on BuyIT’s backlog for a long time but were never prioritized because of their low business impact. Hence, the company decides to ditch the in-house solution in favor of integrating the open source solution. In doing so, the document management subdomain turns from a supporting into a generic subdomain.
然而,在BuyIT开始实施内部解决方案几年后,一个开源合同管理解决方案问世了。这个开源项目实现了与现有解决方案相同的功能,并具有更高级的功能,如OCR和全文搜索。这些额外的功能在BuyIT的待办事项列表中已经存在很长时间了,但由于其业务影响较低,从未被优先考虑。因此,公司决定放弃内部解决方案,转而集成开源解决方案。这样做之后,文档管理子域从支撑子域转变为通用子域。
Supporting to Core
支撑子域转变为核心子域
A supporting subdomain can also turn into a core subdomain—for example, if a company finds a way to optimize the supporting logic in such a way that it either reduces costs or generates additional profits.
支撑子域也可能转变为核心子域——例如,如果一家公司找到一种方法来优化支撑逻辑,从而降低成本或产生额外利润。
The typical symptom of such a transformation is the increasing complexity of the supporting subdomain’s business logic. Supporting subdomains, by definition, are simple, mainly resembling CRUD interfaces or ETL processes. However, if the business logic becomes more complicated over time, there should be a reason for the additional complexity. If it doesn’t affect the company’s profits, why would it become more complicated? That’s accidental business complexity. On the other hand, if it enhances the company’s profitability, it’s a sign of a supporting subdomain becoming a core subdomain.
这种转变的典型征兆是支撑子域的业务逻辑日益复杂。根据定义,支撑子域是简单的,主要类似于 CRUD 接口或 ETL 过程。但是,如果业务逻辑随着时间的推移变得更加复杂,那么这种额外的复杂性一定有其原因。如果它不影响公司的利润,为什么它会变得更复杂? 这是偶然的业务复杂性。另一方面,如果它提高了公司的盈利能力,这是一个支撑子域转变为核心子域的迹象。
Core to Supporting
核心子域转变为支撑子域
A core subdomain can, over time, become a supporting subdomain. This can happen when the subdomain’s complexity isn’t justified. In other words, it’s not profitable. In such cases, the organization may decide to cut the extraneous complexity, leaving the minimum logic needed to support implementation of other subdomains.
核心子域随着时间的推移可能会转变为支撑子域。当子域的复杂性得不到合理证明时,即它不再盈利时,就会发生这种情况。在这种情况下,组织可能会决定削减多余的复杂性,仅保留支持其他子域实现所需的最少逻辑。
Generic to Supporting
通用子域转变为支撑子域
Finally, for the same reason as a core subdomain, a generic subdomain can turn into a supporting one. Going back to the example of BuyIT’s document management system, assume the company has decided that the complexity of integrating the open source solution doesn’t justify the benefits and has resorted back to the in-house system. As a result, the generic subdomain has turned into a supporting subdomain.
最后,出于与核心子域相同的原因,通用子域可能转变为支撑子域。回到 BuyIT 的文档管理系统的例子,假设该公司已经决定,集成开源解决方案的复杂性并不能证明其好处的合理性,并重新使用内部系统。因此,通用子域已经转变为支撑子域。
The changes in subdomains we just discussed are demonstrated in Figure 11-1.
我们刚刚讨论的子域变化在图11-1中得到了展示。
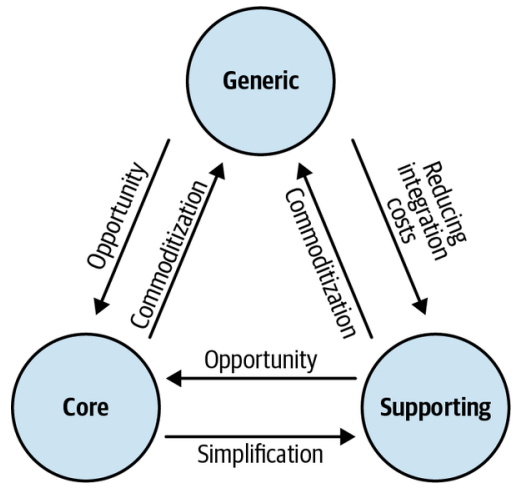
Figure 11-1. Subdomain type change factors
图11-1. 子域类型变化因素
Strategic Design Concerns
战略设计问题
A change in a subdomain’s type directly affects its bounded context and, consequently, corresponding strategic design decisions. As you learned in Chapter 4, different bounded context integration patterns accommodate the different subdomain types. The core subdomains have to protect their models by using anticorruption layers and have to protect consumers from frequent changes in the implementation models by using published languages (OHS).
子域类型的改变直接影响到其限界上下文,进而影响相应的战略设计决策。正如你在第4章中学到的,不同的有界上下文集成模式适应不同的子域类型。核心子域必须使用防腐层来保护其模型,并使用发布语言(OHS)来保护使用者免受核心子域实现模型频繁变化的影响。
Another integration pattern that is affected by such changes is the separate ways pattern. As you saw earlier, teams can use this pattern for supporting and generic subdomains. If the subdomain morphs into a core subdomain, duplicating its functionality by multiple teams is no longer acceptable. Hence, the teams have no choice but to integrate their implementations. The customer–supplier relationship will make the most sense in this case, since the core subdomain will only be implemented by one team.
另一个受这些变化影响的集成模式是独立模式(各行其道)。如前所述,团队可以为支撑子域和通用子域使用此模式。如果子域转变为一个核心子域,多个团队重复其功能将不再被接受。因此,团队别无选择,只能整合他们的实现。在这种情况下,客户-供应商关系最有意义,因为核心子域只由一个团队实现。
From an implementation strategy standpoint, core and supporting subdomains differ in how they can be implemented. Supporting subdomains can be outsourced or used as “training wheels” for new hires. Core subdomains must be implemented in-house, as close as possible to the sources of domain knowledge. Therefore, when a supporting subdomain turns into a core subdomain, its implementation should be moved in-house. The same logic works the other way around. If a core subdomain turns into a supporting subdomain, it’s possible to outsource the implementation to let the in-house R&D teams concentrate on the core subdomains.
从实现策略的角度来看,核心子域和支撑子域在如何实现方面有所不同。支撑子域可以外包或用作新员工的“训练轮”。核心子域必须在公司内部实现,尽可能接近领域知识的来源。因此,当支撑子域转变为核心子域时,其实现应该交给公司内部进行。同样的逻辑反过来也适用。如果一个核心子域转变为一个支撑子域,就有可能将实现外包出去,让公司内部研发团队能够专注于核心子域。
Tactical Design Concerns
战术设计问题
The main indicator of a change in a subdomain’s type is the inability of the existing technical design to support current business needs.
子域类型变化的主要指标是现有的技术设计无法满足当前的业务需求。
Let’s go back to the example of a supporting subdomain becoming a core subdomain. Supporting subdomains are implemented with relatively simple design patterns for modeling the business logic: namely, the transaction script or active record pattern. As you saw in Chapter 5, these patterns are not a good fit for business logic involving complex rules and invariants.
让我们回到支撑子域转变为核心子域的例子。支撑子域是用相对简单的设计模式实现的,这种简单的设计模式(即事务脚本或活动记录模式)用于建模业务逻辑。正如您在第5章中看到的,这些模式并不适合涉及复杂规则和不变性的业务逻辑。
If complicated rules and invariants are added to the business logic over time, the codebase will become increasingly complex as well. It will be painful to add the new functionality, as the design won’t support the new level of complexity. This “pain” is an important signal. Use it as a call to reassess the business domain and design choices.
如果随着时间的推移,业务逻辑中添加了复杂的规则和不变性,代码库也会变得越来越复杂。添加新功能会变得困难,因为设计无法支持新的复杂度级别。这种“困难”是一个重要的信号。将其用作重新评估业务领域和设计选择的契机。
The need for change in the implementation strategy is nothing to fear. It’s normal. We cannot foresee how a business will evolve down the road. We also cannot apply the most elaborate design patterns for all types of subdomains; that would be wasteful and ineffective. We have to choose the most appropriate design and evolve it when needed.
对实施策略进行调整的需求并不可怕,这是正常的。我们无法预见企业的未来发展。我们也不能对所有类型的子域都应用最复杂的设计模式,那将是浪费且无效的。我们必须选择最合适的设计,并在需要时对其进行调整。
If the decision for how to model the business logic is made consciously, and you are aware of all the possible design choices and the differences between them, migrating from one design pattern to another is not that troublesome. The following subsections highlight a few examples.
如果关于如何建模业务逻辑的决策是有意识地做出的,并且您知道所有可能的设计选择以及它们之间的差异,那么从一种设计模式迁移到另一种模式并不是那么麻烦。下面的小节将重点介绍一些示例。
Transaction Script to Active Record
事务脚本转变为活动记录
At their core, both the transaction script and active record patterns are based on the same principle: the business logic is implemented as a procedural script. The difference between them is how the data structures are modeled: the active record pattern introduces the data structures to encapsulate the complexity of mapping them to the storage mechanism.
事务脚本和活动记录模式的核心都基于同一原则:业务逻辑被实现为一个过程脚本。它们之间的区别在于数据结构的建模方式:活动记录模式引入了数据结构来封装将数据映射到存储机制的复杂性。
As a result, when working with data becomes challenging in a transaction script, refactor it into the active record pattern. Look for complicated data structures and encapsulate them in active record objects. Instead of accessing the database directly, use active records to abstract its model and structure.
因此,当在事务脚本中处理数据变得具有挑战性时,可以将其重构为活动记录模式。找出复杂的数据结构,并将它们封装在活动记录对象中。不要直接访问数据库,而是使用活动记录来抽象其模型和结构。
Active Record to Domain Model
活动记录转变为领域模型
If the business logic that manipulates active records becomes complex and you notice more and more cases of inconsistencies and duplications, refactor the implementation to the domain model pattern.
如果操作活动记录的业务逻辑变得复杂,并且您发现越来越多的不一致和重复情况,请将实现重构为领域模型模式。
Start by identifying value objects. What data structures can be modeled as immutable objects? Look for the related business logic, and make it a part of the value objects as well.
首先识别值对象。哪些数据结构可以被建模为不可变对象?寻找相关的业务逻辑,并将其也作为值对象的一部分。
Next, analyze the data structures and look for transactional boundaries. To ensure that all state-modifying logic is explicit, make all of the active records’ setters private so that they can only be modified from inside the active record itself. Obviously, expect the compilation to fail; however, the compilation errors will make it clear where the state-modifying logic resides. Refactor it into the active record’s boundaries. For example:
接下来,分析数据结构并找出事务边界。为了确保所有修改状态的逻辑都是显而易见的,将所有活动记录的 setter 设置为私有的,以便只能从活动记录内部修改它们。显然,预计编译会失败;但是,编译错误将清楚地指出修改状态的逻辑位于何处。将其重构到活动记录的边界内。例如:
1 public class Player 2 { 3 public Guid Id { get; set; } 4 public int Points { get; set; } 5 } 6 public class ApplyBonus 7 { 8 ... 9 public void Execute(Guid playerId, byte percentage) 10 { 11 var player = _repository.Load(playerId); 12 player.Points *= 1 + percentage/100.0; 13 _repository.Save(player); 14 } 15 }
In the following code, you can see the first steps toward the transformation. The code won’t compile yet, but the errors will make it explicit where external components are controlling the object’s state:
在以下代码中,你可以看到向这种转换迈出的第一步。代码目前还无法编译,但编译错误将明确指出哪些外部组件正在控制对象的状态:
1 public class Player 2 { 3 public Guid Id { get; private set; } 4 public int Points { get; private set; } 5 } 6 public class ApplyBonus 7 { 8 ... 9 public void Execute(Guid playerId, byte percentage) 10 { 11 var player = _repository.Load(playerId); 12 player.Points *= 1 + percentage/100.0; 13 _repository.Save(player); 14 } 15 }
In the next iteration, we can move that logic inside the active record’s boundary:
在下一轮迭代中,我们可以将该逻辑移动到活动记录的边界内:
1 public class Player 2 { 3 public Guid Id { get; private set; } 4 public int Points { get; private set; } 5 public void ApplyBonus(int percentage) 6 { 7 this.Points *= 1 + percentage/100.0; 8 } 9 }
When all the state-modifying business logic is moved inside the boundaries of the corresponding objects, examine what hierarchies are needed to ensure strongly consistent checking of business rules and invariants. Those are good candidates for aggregates. Keeping in mind the aggregate design principles we discussed in Chapter 6, look for the smallest transaction boundaries, that is, the smallest amount of data that you need to keep strongly consistent. Decompose the hierarchies along those boundaries. Make sure the external aggregates are only referenced by their IDs.
当所有修改状态的业务逻辑移动到相应对象的边界内时,检查需要哪些层次结构来确保对业务规则和不变性的强一致性检查。这些层次结构是聚合的绝佳候选者。请记住我们在第6章中讨论的聚合设计原则,寻找最小的事务边界,即需要保持强一致性的最少数量的数据。沿着这些边界分解层次结构。确保外部聚合仅能通过其ID进行引用。
Finally, for each aggregate, identify its root, or the entry point for its public interface. Make the methods of all the other internal objects in the aggregate private and only callable from within the aggregate.
最后,对于每个聚合,确定其根或其公共接口的入口点。将聚合中所有其他内部对象的方法设为私有,并且只能从聚合内部调用。
Domain Model to Event-Sourced Domain Model
领域模型转为事件溯源领域模型
Once you have a domain model with properly designed aggregate boundaries, you can transition it to the event-sourced model. Instead of modifying the aggregate’s data directly, model the domain events needed to represent the aggregate’s lifecycle.
一旦你拥有了一个具有适当设计的聚合边界的领域模型,你就可以将其转换为事件源模型。不是直接修改聚合的数据,而是对表示聚合生命周期所需的领域事件进行建模。
The most challenging aspect of refactoring a domain model into an event-sourced domain model is the history of the existing aggregates: migrating the “timeless” state into the event-based model. Since the fine-grained data representing all the past state changes is not there, you have to either generate past events on a best-effort basis or model migration events.
将领域模型重构为基于事件的领域模型最具挑战性的是现有聚合的历史:将“无时间”状态迁移到基于事件的模型。由于表示所有过去状态更改的细粒度数据不存在,您必须尽最大努力生成过去的事件,或者对迁移事件进行建模。
Generating Past Transitions
生成过去的转换
This approach entails generating an approximate stream of events for each aggregate so that the stream of events can be projected into the same state representation as in the original implementation. Consider the example you saw in Chapter 7, as represented in Table 11-1.
这种方法需要为每个聚合生成一个近似的事件流,以便可以将事件流投影到与原始实现中相同的状态表示中。思考一下你在第7章看到的例子,如表11-1所示。
Table11-1.A state-based representation of the aggregate’s data
表11-1. 聚合数据的基于状态的表示形式
| lead-in | first-name | last-name | phone_number | status | last-contacted-on | order-placed-on | |
| 12 | Shauna | Mercia | 555-4753 | converted | 2020- 05-27 T 12:02:12.51Z | 2020- 05-27 T 12:02:12.51Z |
We can assume from the business logic perspective that the instance of the aggregate has been initialized; then the person has been contacted, an order has been placed, and finally, since the status was “converted,” the payment for the order has been confirmed. The following set of events can represent all of these assumptions:
从业务逻辑的角度来看,我们可以假设聚合的实例已经被初始化;然后已经联系了人,下了订单,最后,由于状态是“已转换”,订单的付款已被确认。以下一系列事件可以表示所有这些假设:
1 { 2 "lead-id": 12, 3 "event-id": 0, 4 "event-type": "lead-initialized", 5 "first-name": "Shauna", 6 "last-name": "Mercia", 7 "phone-number": "555-4753" 8 }, 9 { 10 "lead-id": 12, 11 "event-id": 1, 12 "event-type": "contacted", 13 "timestamp": "2020-05-27T12:02:12.51Z" 14 }, 15 { 16 "lead-id": 12, 17 "event-id": 2, 18 "event-type": "order-submitted", 19 "payment-deadline": "2020-05-30T12:02:12.51Z", 20 "timestamp": "2020-05-27T12:02:12.51Z" 21 }, 22 { 23 "lead-id": 12, 24 "event-id": 3, 25 "event-type": "payment-confirmed", 26 "status": "converted", 27 "timestamp": "2020-05-27T12:38:44.12Z" 28 }
When applied one by one, these events can be projected into the exact state representation as in the original system. The “recovered” events can be easily tested by projecting the state and comparing it to the original data.
当这些事件被逐一应用时,它们可以被投影到与原始系统中完全相同的状态表示中。通过投射状态并将其与原始数据进行比较,可以很容易地对“recovered”(重新转换)的事件进行测试。
However, it’s important to keep in mind the disadvantage of this approach. The goal of using event sourcing is to have a reliable, strongly consistent history of the aggregates’ domain events. When this approach is used, it’s impossible to recover the complete history of state transitions. In the preceding example, we don’t know how many times the sales agent has contacted the person, and therefore, how many “contacted” events we have missed.
然而,重要的是要记住这种方法的缺点。使用事件源的目标是对聚合的领域事件有一个可靠的、强一致的历史记录。使用这种方法时,不可能恢复(重新填补)状态转换的完整历史。在上面的示例中,我们不知道销售客服联系了这个客户多少次,因此也不知道缺失了多少个“contacted”事件。
Modeling Migration Events
对迁移事件建模
The alternative approach is to acknowledge the lack of knowledge about past events and explicitly model it as an event. Instead of recovering the events that may have led to the current state, define a migration event and use it to initialize the event streams of existing aggregate instances:
另一种方法是承认缺乏对过去事件的了解,并将其明确地建模为一个事件。定义一个迁移事件并使用它来初始化现有聚合实例的事件流,而不是恢复(重新填补)可能导致当前状态的事件:
1 { 2 "lead-id": 12, 3 "event-id": 0, 4 "event-type": "migrated-from-legacy", 5 "first-name": "Shauna", 6 "last-name": "Mercia", 7 "phone-number": "555-4753", 8 "status": "converted", 9 "last-contacted-on": "2020-05-27T12:02:12.51Z", 10 "order-placed-on": "2020-05-27T12:02:12.51Z", 11 "converted-on": "2020-05-27T12:38:44.12Z", 12 "followup-on": null 13 }
The advantage of this approach is that it makes the lack of past data explicit. At no stage can someone mistakenly assume that the event stream captures all of the domain events that happened during the aggregate instance’s lifecycle. The disadvantage is that the traces of the legacy system will remain in the event store forever. For example, if you are using the CQRS pattern (and with the event-sourced domain model you most likely will), the projections will always have to take into account the migration events.
这种方法的优点是它使过去数据的缺乏变得明确。在任何阶段,都不会有人错误地假设事件流捕获了聚合实例生命周期期间发生的所有领域事件。缺点是旧系统的痕迹将永远保留在事件存储中。例如,如果你正在使用CQRS模式(在基于事件的领域模型中,你很可能会使用CQRS模式),那么投影将始终需要考虑迁移事件。
Organizational Changes
组织变化
Another type of change that can affect a system’s design is a change in the organization itself. Chapter 4 looked at different patterns of integrating bounded contexts: partnership, shared kernel, conformist, anticorruption layer, open-host service, and separate ways. Changes in the organization’s structure can affect teams’ communication and collaboration levels and, as a result, the ways the bounded contexts should be integrated.
另一种可能影响系统设计的变化是组织本身的变化。第4章探讨了集成有界上下文的不同模式:合作伙伴关系、共享内核、遵奉者、防腐层、开放主机服务和独立方式(各行其道)。组织结构的变化会影响团队间的沟通和协作水平,从而影响集成有界上下文的方式。
A trivial example of such change is growing development centers, as shown in Figure 11-2. Since a bounded context can be implemented by only one team, adding new development teams can cause the existing wider bounded context boundaries to split into smaller ones so that each team can work on its own bounded context.
这种变化的一个简单例子是开发中心的扩张,如图11-2所示。由于一个有界上下文只能由一个团队来实现,增加新的开发团队可能会导致现有的更广泛的有界上下文边界分裂成更小的边界,以便每个团队都可以在自己的有界上下文中工作。
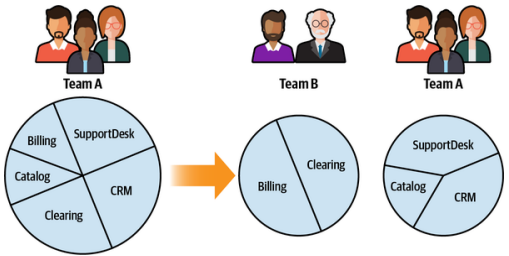
Figure 11-2. Splitting a wide bounded context to accommodate growing engineering teams
图11-2. 将宽泛的有界上下文拆分以适应不断扩大的工程团队
Moreover, the organization’s development centers are often located in different geographical locations. When the work on the existing bounded contexts is shifted to another location, it may negatively impact the teams’ collaboration. As a result, the bounded contexts’ integration patterns have to evolve accordingly, as described in the following scenarios.
此外,组织的研发中心通常分布在不同的地理位置。当现有有界上下文的工作转移到另一个位置时,可能会对团队的协作产生负面影响。因此,有界上下文的集成模式必须相应地演变,如下面的场景所述。
Partnership to Customer–Supplier
合作关系转变为客户——供应商
The partnership pattern assumes there is strong communication and collaboration among teams. As time goes by, that might cease to be the case; for example, when work on one of the bounded contexts is moved to a distant development center. Such a change will negatively affect the teams’ communication, and it may make sense to move away from the partnership pattern toward a customer–supplier relationship.
合作关系模式假设团队之间有很好的沟通和协作。随着时间的推移,这种情况可能不复存在; 例如,当在一个有界上下文上的工作被转移到一个遥远的研发中心时。这样的变化会对团队的沟通产生负面影响,从合作关系模式转变为客户——供应商关系可能是有意义的。
Customer–Supplier to Separate Ways
客户——供应商转为独立(分离)
Unfortunately, it’s not uncommon for teams to have severe communication problems. The issues might be caused by geographical distance or organizational politics. Such teams may experience more and more integration issues over time. At some point, it may become more cost-effective to duplicate the functionality instead of continuously chasing one another’s tails.
不幸的是,团队之间存在严重的沟通问题并不罕见。这些问题可能由地理距离或组织政治造成。这样的团队可能会随着时间的推移遇到越来越多的集成问题。在某一时刻,复制功能可能比不断相互追赶更具成本效益。
Domain Knowledge
领域知识
As you’ll recall, the core tenet of domain-driven design is that domain knowledge is essential for designing a successful software system. Acquiring domain knowledge is one of the most challenging aspects of software engineering, especially for the core subdomains. A core subdomain’s logic is not only complicated, but also expected to change often. Moreover, modeling is an ongoing process. Models have to improve as more knowledge of the business domain is acquired.
你可能还记得,领域驱动设计的核心原则是领域知识对于设计一个成功的软件系统是必不可少的。获取领域知识是软件工程最具挑战性的方面之一,尤其是对于核心子域。核心子域的逻辑不仅复杂,而且预计会经常发生变化。此外,建模是一个持续的过程,随着对业务领域的更多了解,模型必须不断演进。
Many times, the business domain’s complexity is implicit. Initially, everything seems simple and straightforward. The initial simplicity is often deceptive and it quickly morphs into complexity. As more functionality is added, more and more edge cases, invariants, and rules are discovered. Such insights are often disruptive, requiring rebuilding the model from the ground up, including the boundaries of the bounded contexts, aggregates, and other implementation details.
很多时候,业务领域的复杂性是不明显的。最初,一切看起来简单明了。最初的简单性常常具有欺骗性,它很快就变得复杂。随着越来越多的功能被添加,越来越多的边缘情况,不变性和规则被发现。这样的洞察往往是颠覆性的,需要从头开始重建模型,包括有界上下文的边界,聚合和其他实现细节。
From a strategic design standpoint, it’s a useful heuristic to design the bounded contexts’ boundaries according to the level of domain knowledge. The cost of decomposing a system into bounded contexts that, over time, turn out to be incorrect can be high. Therefore, when the domain logic is unclear and changes often, it makes sense to design the bounded contexts with broader boundaries. Then, as domain knowledge is discovered over time and changes to the business logic stabilize, those broad bounded contexts can be decomposed into contexts with narrower boundaries, or microservices. We will discuss the interplay between bounded contexts and microservices in more detail in Chapter 14.
从战略设计的角度来看,根据领域知识水平来设计有界上下文的边界是一种有用的启示。将系统分解为多个有界上下文,但随着时间的推移,这些有界上下文的划分是不正确的,这样的成本可能会很高。因此,当领域逻辑不清晰且经常发生变化时,设计具有更宽泛边界的有界上下文是有道理的。然后,随着领域知识的发现和业务逻辑变化的稳定,可以将那些宽泛的有界上下文分解为具有较窄边界的上下文或微服务。我们将在第14章中更详细地讨论有界上下文和微服务之间的相互作用。
When new domain knowledge is discovered, it should be leveraged to evolve the design and make it more resilient. Unfortunately, changes in domain knowledge are not always positive: domain knowledge can be lost. As time goes by, documentation often becomes stale, people who were working on the original design leave the company, and new functionality is added in an ad hoc manner until, at one point, the codebase gains the dubious status of a legacy system. It’s vital to prevent such degradation of domain knowledge proactively. An effective tool for recovering domain knowledge is the EventStorming workshop, which is the topic of the next chapter.
当发现新的领域知识时,应该利用新的领域知识来改进设计并使其更具弹性。不幸的是,领域知识的变化并不总是积极正面的:领域知识可能会丢失。随着时间的推移,文档常常变得过时,负责原始设计的人员离开公司,新功能以临时的方式添加,直到某一时刻,代码库到了遗留系统的可疑状态。主动地防止领域知识的退化是至关重要的。一个有效的恢复领域知识的工具是 EventStorming 研讨会,这是下一章的主题。
Growth
增长
Growth is a sign of a healthy system. When new functionality is continuously added, it’s a sign that the system is successful: it brings value to its users and is expanded to further address users’ needs and keep up with competing products. But growth has a dark side. As a software project grows, its codebase can grow into a big ball of mud:
增长是系统健康的标志。当不断添加新功能时,这表明系统是成功的:它为用户带来价值,并不断扩大以满足用户的需求并跟上竞争对手的产品。但增长也有其阴暗面。随着软件项目的增长,其代码库可能会变成一个“大泥球”:
A big ball of mud is a haphazardly structured, sprawling, sloppy, duct-tape-and-baling-wire, spaghetti-code jungle. These systems show unmistakable signs of unregulated growth, and repeated, expedient repair.—Brian Foote and Joseph Yoder
“大泥球”是一个结构杂乱无章、蔓延、草率、用胶带和捆扎线拼凑、像意大利面条一样的代码丛林。这些系统表现出明显的不受控制的增长和重复、快速的修补痕迹(迹象)。——Brian Foote 和 Joseph Yoder
The unregulated growth that leads to big balls of mud results from extending a software system’s functionality without re-evaluating its design decisions. Growth blows up the components’ boundaries, increasingly extending their functionality. It’s crucial to examine the effects of growth on design decisions, especially since many domain-driven design tools are all about setting boundaries: business building blocks (subdomains), model (bounded contexts), immutability (value objects), or consistency (aggregates).
导致“大泥球”的无序增长,源于在扩展软件系统功能时,没有重新评估其设计决策。增长使得组件的边界不断扩大,其功能也逐渐增加。检查增长对设计决策的影响至关重要,尤其是因为许多领域驱动设计的工具都是关于设定边界的:业务构建块(子域)、模型(有界上下文)、不可变性(值对象)或一致性(聚合)。
The guiding principle for dealing with growth-driven complexity is to identify and eliminate accidental complexity: the complexity caused by outdated design decisions. The essential complexity, or inherent complexity of the business domain, should be managed using domain-driven design tools and practices.
处理由增长驱动的复杂性的指导原则是识别和消除偶然复杂性:即由过时的设计决策引起的复杂性。对于业务领域的本质复杂性或内在复杂性,应该使用领域驱动设计的工具和实践来管理。
When we discuss DDD in earlier chapters, we follow the process of first analyzing the business domain and its strategic components, designing the relevant models of the business domain, and then designing and implementing the models in code. Let’s follow the same script for dealing with growth-driven complexity.
在前面的章节中讨论DDD时,我们遵循了首先分析业务领域及其战略组件、设计业务领域的相关模型,然后使用代码设计和实现模型的过程。让我们遵循相同的步骤来处理由增长驱动的复杂性。
Subdomains
子域
As we discussed in Chapter 1, the subdomains’ boundaries can be challenging to identify, and as a result, instead of striving for boundaries that are perfect, we must strive for boundaries that are useful. That is, the subdomains should allow us to identify components of different business value and use the appropriate tools to design and implement the solution.
正如我们在第1章中所讨论的,子域的边界可能很难确定,因此,我们不必追求完美的边界,而应该追求有用的边界。也就是说,子域应该使我们能够识别不同业务价值的组件,并使用适当的工具来设计和实现解决方案。
As the business domain grows, the subdomains’ boundaries can become even more blurred, making it harder to identify cases of a subdomain spanning multiple, finer-grained subdomains. Hence, it’s important to revisit the identified subdomains and follow the heuristic of coherent use cases (sets of use cases working on the same set of data) to try to identify where to split a subdomain (see Figure 11-3).
随着业务领域的增长,子域的边界可能会变得更加模糊,使得识别跨越多个更细粒度子域的子域情况变得更加困难。因此,重新审视已识别的子域,并遵循连贯用例(在相同数据集上工作的一组用例)的启示,以尝试确定在哪里拆分子域,这一点非常重要(见图11-3)。

Figure 11-3. Optimizing subdomains’ boundaries to accommodate growth
图11-3. 优化子域边界以适应增长
If you are able to identify finer-grained subdomains of different types, this is an important insight that will allow you to manage the business domain’s essential complexity. The more precise the information about the subdomains and their types is, the more effective you will be at choosing technical solutions for each subdomain.
如果你能够识别出不同类型的更细粒度的子域,这是一个重要的见解,它将使你能够管理业务领域的本质复杂性。你对子域及其类型的了解越精确,你在为每个子域选择技术解决方案时就会越有效。
Identifying inner subdomains that can be extracted and made explicit is especially important for core subdomains. We should always aim to distill core subdomains as much as possible from all others so that we can invest our effort where it matters most from a business strategy perspective.
识别可以提取和明确化的内部子域对于核心子域尤为重要。我们应该始终努力尽可能地从其他所有子域中提取核心子域,以便从业务战略角度出发,将我们的努力投入到最重要的地方。
Bounded Contexts
有界上下文
In Chapter 3, you learned that the bounded context pattern allows us to use different models of the business domain. Instead of building a “jack of all trades, master of none” model, we can build multiple models, each focused on solving a specific problem.
在第3章中,您了解到有界上下文模式允许我们使用业务领域的不同模型。我们可以建立多个模型,每个模型专注于解决一个特定的问题,而不是建立一个“杂而不精”的模型。
As a project evolves and grows, it’s not uncommon for the bounded contexts to lose their focus and accumulate logic related to different problems. That’s accidental complexity. As with subdomains, it’s crucial to revisit the bounded contexts’ boundaries from time to time. Always look for opportunities to simplify the models by extracting bounded contexts that are laser focused at solving specific problems.
随着项目的演进和增长,有界上下文失去焦点并积累与不相关的逻辑是很常见的。这就是偶然复杂性。与子域一样,不时地重新审视有界上下文的边界至关重要。始终寻找机会,通过提取专注于解决特定问题的有界上下文来简化模型。
Growth can also make existing implicit design issues explicit. For example, you may notice that a number of bounded contexts become increasingly “chatty” over time, unable to complete any operation without calling another bounded context. That can be a strong signal of an ineffective model and should be addressed by redesigning the bounded contexts’ boundaries to increase their autonomy.
增长也可能使现有的隐性的设计问题变得明显。例如,你可能会注意到,随着时间的推移,许多有界上下文变得越来越“健谈”,无法在不调用另一个有界上下文的情况下完成任何操作。这可能是模型效率低下的强烈信号,应该通过重新设计有界上下文的边界来增加其自主性来解决。
Aggregates
聚合
When we discussed the domain model pattern in Chapter 6, we used the following guiding principle for designing aggregates’ boundaries:
当我们在第6章中讨论领域模型模式时,我们使用了以下指导原则来设计聚合的边界:
The rule of thumb is to keep the aggregates as small as possible and include only objects that are required to be in a strongly consistent state by the business domain.
经验法则是保持聚合尽可能小,并且只包含业务领域要求处于强一致状态的对象。
As the system’s business requirements grow, it can be “convenient” to distribute the new functionalities among the existing aggregates, without revisiting the principle of keeping aggregates small. If an aggregate grows to include data that is not needed to be strongly consistent by all of its business logic, again, that’s accidental complexity that has to be eliminated.
随着系统业务需求的增长,将新功能分布在现有聚合中可能会“很方便”,而无需重新考虑保持聚合较小的原则。如果一个聚合增长到了包含其所有业务逻辑都不需要强一致性的数据,那么这同样是必须消除的偶然复杂性。
Extracting business functionality into a dedicated aggregate not only simplifies the original aggregate, but potentially can simplify the bounded context it belongs to. Often, such refactoring uncovers an additional hidden model that, once made explicit, should be extracted into a different bounded context.
将业务功能提取到专用聚合中不仅可以简化原始聚合,而且还(潜在地)可以简化其所属的有界上下文。通常,这种重构会发现一个额外的隐藏模型,一旦将其明确化,就应该提取到不同的有界上下文中。
Conclusion
总结
As Heraclitus famously said, the only constant in life is change. Businesses are no exception. To stay competitive, companies constantly strive to evolve and reinvent themselves. Those changes should be treated as first-class elements of the design process.
正如赫拉克利特(Heraclitus)所说,生活中唯一不变的就是变化。企业也不例外。为了保持竞争力,公司不断努力进化和重塑自己。这些变化应被视为设计过程中的一流要素。
As the business domain evolves, changes to its subdomains must be identified and acted on in the system’s design. Make sure your past design decisions are aligned with the current state of the business domain and its subdomains. When needed, evolve your design to better match the current business strategy and needs.
随着业务领域的发展,必须识别并在其系统设计中对子域的变化采取行动。确保你过去的设计决策与业务领域及其子域的当前状态保持一致。在需要时,改进你的设计以更好地匹配当前的业务战略和需求。
It’s also important to recognize that changes in the organizational structure can affect communication and cooperation among teams and the ways their bounded contexts can be integrated. Learning about the business domain is an ongoing process. As more domain knowledge is discovered over time, it has to be leveraged to evolve strategic and tactical design decisions.
同样重要的是要认识到组织结构的变化可能会影响团队之间的沟通和合作方式,以及它们的有界上下文可以被集成的方式。了解业务领域是一个持续的过程。随着时间的推移,随着更多领域知识的发现,必须利用这些知识来改进战略和战术设计决策。
Finally, software growth is a desired type of change, but when it is not managed correctly, it may have disastrous effects on the system design and architecture. Therefore:
最后,软件增长是一种期望的变化类型,但如果没有得到正确管理,它可能会对系统设计和架构产生灾难性的影响。因此:
- When a subdomain’s functionality is expanded, try to identify more finer-grained subdomain boundaries that will enable you to make better design decisions. 当子域的功能扩展时,尝试识别更细粒度的子域边界,这将使您能够做出更好的设计决策。
- Don’t allow a bounded context to become a “jack of all trades.” Make sure the models encompassed by bounded contexts are focused to solve specific problems. 不要让有界上下文变得“杂而不精”。确保有界上下文所包含的模型专注于解决特定的问题。
- Make sure your aggregates’ boundaries are as small as possible. Use the heuristic of strongly consistent data to detect possibilities to extract business logic into new aggregates. 确保聚合的边界尽可能小。使用强一致性数据的启示来检测将业务逻辑提取到新聚合中的可能性。
My final words of wisdom on the topic are to continuously check the different boundaries for signs of growth-driven complexity. Act to eliminate accidental complexities, and use domain-driven design tools to manage the business domain’s essential complexity.
关于这个话题,我最后的建议是不断检查不同边界上是否存在由增长驱动的复杂性迹象。采取行动消除偶然复杂性,并使用领域驱动设计工具来管理业务领域的本质(内在)复杂性。
Exercises
练习
1. What kind of changes in bounded context integration are often caused by organizational growth? 有界上下文集成中的哪些变化通常是由组织增长引起的?
a. Partnership to customer–supplier (conformist, anticorruption layer, or open-host service) 从合作伙伴转变为客户-供应商(遵奉者、防腐层或开放主机服务)
b. Anticorruption layer to open-host service 从防腐层转变为开放主机服务
c. Conformist to shared kernel 从遵奉者转变为共享内核
d. Open-host service to shared kernel 从开放主机服务转变为共享内核
答案:a。As an organization grows, it can become more challenging for teams to integrate their bounded contexts in an ad hoc fashion. As a result, they switch to a more formal integration pattern. 随着组织的增长,团队以临时方式集成其有界上下文可能会变得更加困难。因此,他们转向更正式的集成模式。
2. Assume that the bounded contexts’ integration shifts from a conformist relationship to separate ways. What information can you deduce based on the change? 假设有界上下文的集成从一个遵奉关系转换为独立(各行其道)的方式。你能根据变化推断出什么信息?
a. The development teams struggled to cooperate. 研发团队在合作方面遇到了困难。
b. The duplicate functionality is either a supporting or a generic subdomain. 重复的功能要么是一个支撑子域,要么是一个通用子域。
c. The duplicate functionality is a core subdomain. 重复的功能是一个核心子域。
d. A and B. A和B。
e. A and C. A和C。
答案:d。A is correct because bounded contexts go separate ways when the cost of duplication is lower than the overhead of collaboration. C is incorrect because it’s a terrible idea to duplicate implementation of a core subdomain. Consequently, B is correct because the separate ways pattern can be used for supporting and generic subdomains. A 是正确的,因为当重复的成本低于合作的开销时,有界上下文会走向独立。C 是错误的,因为重复核心子域的实现是一个糟糕的主意。因此,B 也是正确的,因为独立(各行其道)模式可以用于支撑子域和通用子域。
3. What are the symptoms of a supporting subdomain becoming a core subdomain? 支撑子域转变为核心子域的征兆是什么?
a. It becomes easier to evolve the existing model and implement the new requirements. 现有模型的演进和新需求的实现变得更加容易。
b. It becomes painful to evolve the existing model. 现有模型的演进变得困难重重。
c. The subdomain changes at a higher frequency. 子域的变化频率更高。
d. B and C. B和C。
e. None of the above. 以上都不对。
答案:d。
4. What change results from discovering a new business opportunity? 发现新的商业机会会带来什么变化?
a. A supporting subdomain turns into a core one. 一个支撑子域变成了一个核心子域。
b. A supporting subdomain turns into a generic one. 一个支撑子域变成了一个通用子域。
c. A generic subdomain turns into a core one. 一个通用子域变成了一个核心子域。
d. A generic subdomain turns into a supporting one. 一个通用子域变成了一个支撑子域。
e. A and B. A和B。
f. A and C. A和C。
答案:f。
5. What change in the business strategy could turn one of WolfDesk’s (the fictitious company described in the Preface) generic subdomains into a core subdomain? 业务战略中的哪些变化可以将 WolfDesk(前言中描述的虚构公司)的一个通用子域转变为一个核心子域?
答案:Upon reaching a certain level of growth, WolfDesk could follow the footsteps of Amazon and implement its own compute platform to further optimize its ability to scale elastically and optimize its infrastructure costs. 在达到一定的增长水平后,WolfDesk 可以效仿亚马逊,实施自己的计算平台,以进一步优化其弹性扩展能力和基础设施成本。
1 Brian Foote and Joseph Yoder. Big Ball of Mud. Fourth Conference on Patterns Languages of Programs (PLoP ’97/EuroPLoP ’97), Monticello, Illinois, September 1997. Brian Foote 和 Joseph Yoder。大泥球。第四届程序模式语言会议(ploP’97/europloP’97) ,蒙蒂塞洛,伊利诺伊州,1997年9月。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号