烂翻译系列之学习领域驱动设计——第八章:架构模式
The tactical patterns discussed up to this point in the book defined the different ways to model and implement business logic. In this chapter, we will explore tactical design decisions in a broader context: the different ways to orchestrate the interactions and dependencies between a system’s components.
本书迄今为止讨论的战术模式定义了建模和实现业务逻辑的不同方式。在本章中,我们将在更广泛的背景下探讨战术设计决策:即组织系统组件之间的交互和依赖关系的不同方式。
Business Logic Versus Architectural Patterns
业务逻辑与架构模式
Business logic is the most important part of software; however, it is not the only part of a software system. To implement functional and nonfunctional requirements, the codebase has to fulfill more responsibilities. It has to interact with users to gather input and provide output, and it has to use different storage mechanisms to persist state and integrate with external systems and information providers.
业务逻辑是软件最重要的部分,但它并不是软件系统的唯一部分。为了实现功能性和非功能性需求,代码库必须承担更多的职责。它必须与用户交互以收集输入并提供输出,它还必须使用不同的存储机制来持久化状态,并与外部系统和信息提供者进行集成。
The variety of concerns that a codebase has to take care of makes it easy for its business logic to become diffused among the different components: that is, for some of the logic to be implemented in the user interface or database, or be duplicated in different components. Lacking strict organization in implementation concerns makes the codebase hard to change. When the business logic has to change, it may not be evident what parts of the codebase have to be affected by the change. The change may have unexpected effects on seemingly unrelated parts of the system. Conversely, it may be easy to miss code that has to be modified. All of these issues dramatically increase the cost of maintaining the codebase.
代码库需要处理的各种关注点使得其业务逻辑容易在不同组件之间扩散:也就是说,部分逻辑可能在用户界面或数据库中实现,或者在不同组件中重复。在实现关注点方面缺乏严格的组织使得代码库难以更改。当业务逻辑需要更改时,可能不清楚代码库的哪些部分会受到影响。业务逻辑的更改可能会对系统看似不相关的部分产生意外的影响。相反,可能很容易遗漏需要修改的代码。所有这些问题都极大地增加了维护代码库的成本。
Architectural patterns introduce organizational principles for the different aspects of a codebase and present clear boundaries between them: how the business logic is wired to the system’s input, output, and other infrastructural components. This affects how these components interact with each other: what knowledge they share and how the components reference each other.
架构模式为代码库的不同方面引入了组织原则,并在它们之间划定了明确的界限:即业务逻辑如何与系统输入、输出和其他基础设施组件连接。这影响了这些组件如何相互交互:它们共享什么知识以及组件如何相互引用。
Choosing the appropriate way to organize the codebase, or the correct architectural pattern, is crucial to support implementation of the business logic in the short term and alleviate maintenance in the long term. Let’s explore three predominant application architecture patterns and their use cases: layered architecture, ports & adapters, and CQRS.
选择适当的方式来组织代码库,或者选择正确的架构模式,对于短期内支持业务逻辑的实现和长期内减轻维护负担至关重要。让我们探讨三种主要的应用程序架构模式及其用例:分层架构、端口与适配器(Ports and Adapters)以及命令查询职责分离(CQRS)。
Layered Architecture
分层架构
Layered architecture is one of the most common architectural patterns. It organizes the codebase into horizontal layers, with each layer addressing one of the following technical concerns: interaction with the consumers, implementing business logic, and persisting the data. You can see this represented in Figure 8-1.
分层架构是最常见的架构模式之一。它将代码库组织成水平层,每一层解决下列技术关注点之一:与使用者的交互,实现业务逻辑和持久化数据。您可以在图8-1中看到这种表示。
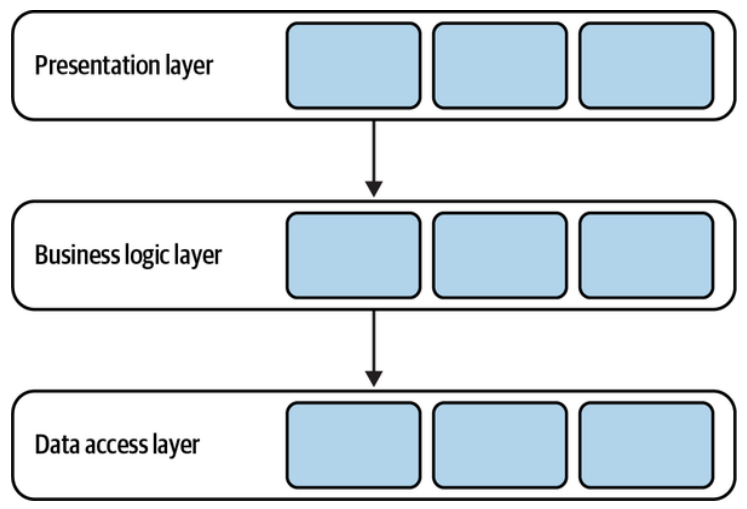
Figure 8-1. Layered architecture
图8-1分层架构
In its classic form, the layered architecture consists of three layers: the presentation layer (PL), the business logic layer (BLL), and the data access layer (DAL).
在其经典形式中,分层架构由三层组成: 展示层(PL)、业务逻辑层(BLL)和数据访问层(DAL)。
Presentation Layer
展示层
The presentation layer, shown in Figure 8-2, implements the program’s user interface for interactions with its consumers. In the pattern’s original form, this layer denotes a graphical interface, such as a web interface or a desktop application.
展示层,如图8-2所示,实现了程序的用户界面,用于与使用者进行交互。在模式的原始形式中,这一层表示图形界面,如 Web 界面或桌面应用程序。
In modern systems, however, the presentation layer has a broader scope: that is, all means for triggering the program’s behavior, both synchronous and asynchronous. For example:
然而,在现代系统中,展示层的范围更广:即触发程序行为的所有方式,无论是同步还是异步。例如:
- Graphical user interface (GUI) 图形用户界面(GUI)
- Command-line interface (CLI) 命令行界面(CLI)
- API for programmatic integration with other systems 用于与其他系统进行编程集成的 API
- Subscription to events in a message broker 在消息代理中订阅事件
- Message topics for publishing outgoing events 用于发布传出事件的消息主题
All of these are the means for the system to receive requests from the external environment and communicate the output. Strictly speaking, the presentation layer is the program’s public interface.
所有这些都是系统接收来自外部环境的请求并传达输出的手段。严格地说,展示层是程序的公共接口。

Figure 8-2. Presentation layer
图8-2. 展示层
Business Logic Layer
业务逻辑层
As the name suggests, this layer is responsible for implementing and encapsulating the program’s business logic. This is the place where business decisions are implemented. As Eric Evans says, this layer is the heart of software.
顾名思义,这一层负责实现和封装程序的业务逻辑。这是实现业务决策的地方,正如 Eric Evans 所说,这一层是软件的核心。
This layer is where the business logic patterns described in Chapters 5–7 are implemented—for example, active records or a domain model (see Figure 8-3).
这一层是实现第5-7章中描述的业务逻辑模式的地方——例如,活动记录或领域模型(参见图8-3)。

Figure 8-3. Business logic layer
图8-3. 业务逻辑层
Data Access Layer
数据访问层
The data access layer provides access to persistence mechanisms. In the pattern’s original form, this referred to the system’s database. However, as in the case of the presentation layer, the layer’s responsibility is broader for modern systems.
数据访问层提供对持久化机制的访问。在模式的原始形式中,这指的是系统的数据库。但是,与展示层的情况一样,对于现代系统来说,数据访问层的职责更广泛。
First, ever since the NoSQL revolution broke out, it is common for a system to work with multiple databases. For example, a document store can act as the operational database, a search index for dynamic queries, and an in-memory database for performance-optimized operations.
首先,自从 NoSQL 革命爆发以来,一个系统使用多个数据库是很常见的。例如,文档存储可以充当操作型数据库(数据库分为操作型数据库和分析型数据库,操作型数据库就是常用的数据库,用于联机事务处理(即日常数据维护),而分析型数据库主要用于联机分析处理,即用来存储并追踪历史性和时间性的数据,从而根据这些数据做出判断与预测),搜索引擎用于动态查询,内存数据库用于性能优化操作。
Second, traditional databases are not the only medium for storing information. For example, cloud-based object storage can be used to store the system’s files, or a message bus can be used to orchestrate communication between the program’s different functions.
其次,传统数据库并不是存储信息的唯一媒介。例如,基于云的对象存储可以用来存储系统的文件,或者可以使用消息总线来协调程序不同功能之间的通信。
Finally, this layer also includes integration with the various external information providers needed to implement the program’s functionality: APIs provided by external systems, or cloud vendors’ managed services, such as language translation, stock market data, and audio transcription (see Figure 8-4).
最后,这一层还包括与实现程序功能所需的各种外部信息提供商的集成:外部系统提供的API,或云提供商的托管服务,如语言翻译、股票市场数据和音频转录(见图8-4)。

Figure 8-4. Data access layer
图8-4. 数据访问层
Communication Between Layers
层间通信
The layers are integrated in a top-down communication model: each layer can hold a dependency only on the layer directly beneath it, as shown in Figure 8-5. This enforces decoupling of implementation concerns and reduces the knowledge shared between the layers. In Figure 8-5, the presentation layer references only the business logic layer. It has no knowledge of the design decisions made in the data access layer.
这些层通过自上而下的通信模型进行集成:每一层只能依赖其直接下方的层,如图8-5所示。这强制实现关注点的解耦,并减少了各层之间的知识共享(最少知识法则)。在图8-5中,层示层仅引用业务逻辑层。它不知道数据访问层中做出的设计决策。
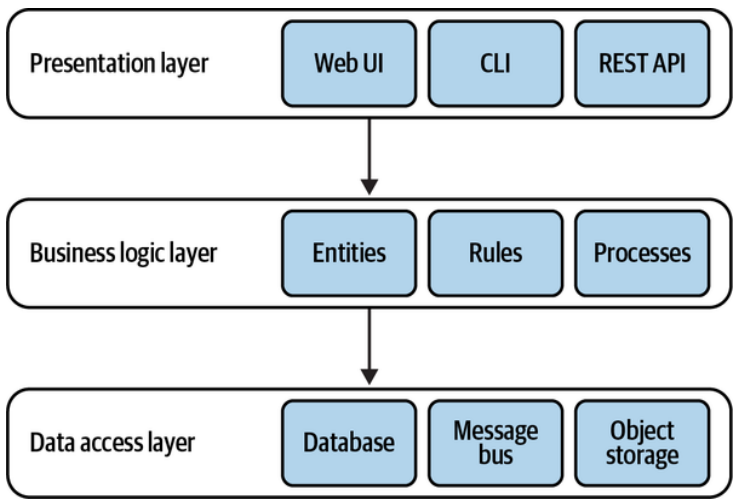
Figure 8-5. Layered architecture
图 8-5. 分层架构
Variation
变体
It’s common to see the layered architecture pattern extended with an additional layer: the service layer.
经常可以看到分层架构模式通过添加另一层来扩展:服务层。
Service layer
服务层
Defines an application’s boundary with a layer of services that establishes a set of available operations and coordinates the application’s response in each operation. —Patterns of Enterprise Application Architecture
通过服务层(一组服务)来定义应用程序的边界,服务层(这组服务)建立了一组可用的操作,并协调每个操作中的应用程序响应。 ——《企业应用架构模式》
The service layer acts as an intermediary between the program’s presentation and business logic layers. Consider the following code:
服务层充当程序展示层和业务逻辑层之间的中介。思考下面的代码:
1 namespace MvcApplication.Controllers 2 { 3 public class UserController: Controller 4 { 5 6 ... 7 [AcceptVerbs(HttpVerbs.Post)] 8 public ActionResult Create(ContactDetails contactDetails) 9 { 10 OperationResult result = null; 11 try 12 { 13 _db.StartTransaction(); 14 15 var user = new User(); 16 user.SetContactDetails(contactDetails) 17 user.Save(); 18 19 _db.Commit(); 20 result = OperationResult.Success; 21 } catch (Exception ex) { 22 _db.Rollback(); 23 result = OperationResult.Exception(ex); 24 } 25 return View(result); 26 } 27 } 28 }
The MVC controller in this example belongs to the presentation layer. It exposes an endpoint that creates a new user. The endpoint uses the User active record object to create a new instance and save it. Moreover, it orchestrates a database transaction to ensure that a proper response is generated in case of an error.
本例中的 MVC 控制器属于展示层。它公开创建新用户的端点。该端点使用 User 活动记录对象创建一个新实例并保存它。此外,它还编排数据库事务以确保在发生错误时生成适当的响应。
To further decouple the presentation layer from the underlying business logic, such orchestration logic can be moved into a service layer, as shown in Figure 8-6.
为了进一步将展示层与底层业务逻辑解耦,这样的编排逻辑可以移动到服务层,如图8-6所示。
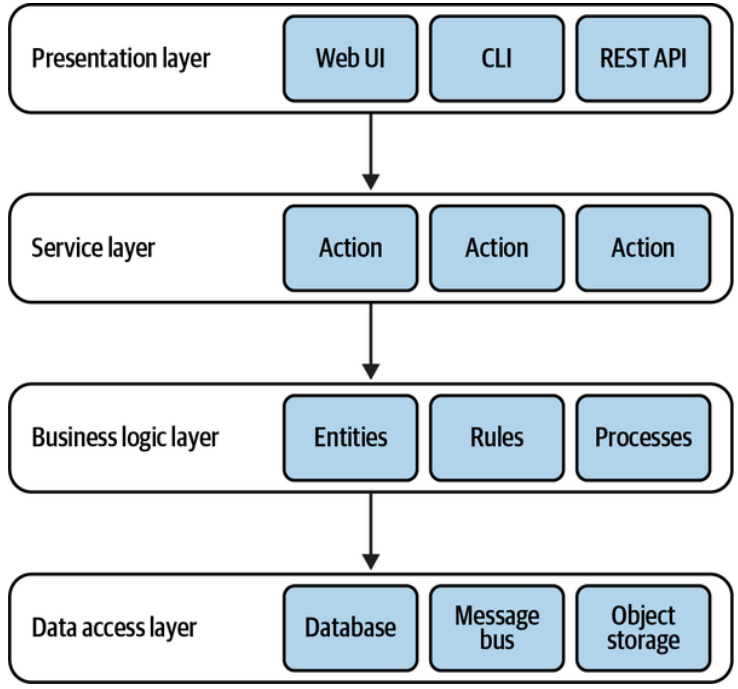
Figure 8-6. Service layer
图8-6. 服务层
It’s important to note that in the context of the architectural pattern, the service layer is a logical boundary. It is not a physical service.
需要注意的是,在架构模式的语境中,服务层是一个逻辑边界。而不是物理服务。
The service layer acts as a façade for the business logic layer: it exposes an interface that corresponds with the public interface’s methods, encapsulating the required orchestration of the underlying layers. For example:
服务层充当业务逻辑层的门面:它公开了一个与公共接口的方法相对应的接口,封装了底层所需的编排。例如:
1 interface CampaignManagementService 2 { 3 OperationResult CreateCampaign(CampaignDetails details); 4 OperationResult Publish(CampaignId id, PublishingSchedule 5 schedule); 6 OperationResult Deactivate(CampaignId id); 7 OperationResult AddDisplayLocation(CampaignId id, 8 DisplayLocation newLocation); 9 ... 10 }
All of the preceding methods correspond to the system’s public interface. However, they lack presentation-related implementation details. The presentation layer’s responsibility becomes limited to providing the required input to the service layer and communicating its responses back to the caller.
上述所有方法都对应于系统的公共接口。但是,它们缺乏与展示相关的实现细节。展示层的职责仅限于向服务层提供所需的输入,并将其响应传回给调用者。
Let’s refactor the preceding example and extract the orchestration logic into a service layer:
让我们重构前面的例子,并将编排逻辑提取到服务层中:
1 namespace ServiceLayer 2 { 3 public class UserService 4 { 5 ... 6 7 public OperationResult Create(ContactDetails 8 contactDetails) 9 { 10 OperationResult result = null; 11 try 12 { 13 _db.StartTransaction(); 14 15 var user = new User(); 16 user.SetContactDetails(contactDetails) 17 user.Save(); 18 _db.Commit(); 19 result = OperationResult.Success; 20 } catch (Exception ex) { 21 _db.Rollback(); 22 result = OperationResult.Exception(ex); 23 } 24 return result; 25 } 26 ... 27 } 28 } 29 namespace MvcApplication.Controllers 30 { 31 public class UserController: Controller 32 { 33 ... 34 [AcceptVerbs(HttpVerbs.Post)] 35 public ActionResult Create(ContactDetails contactDetails) 36 { 37 var result = _userService.Create(contactDetails); 38 return View(result); 39 } 40 } 41 }
Having an explicit service level has a number of advantages:
具有明确的服务层具有以下优点:
- We can reuse the same service layer to serve multiple public interfaces; for example, a graphical user interface and an API. No duplication of the orchestration logic is required. 我们可以重用相同的服务层来为多个公共接口提供服务;例如,图形用户界面和API。无需重复编排逻辑。
- It improves modularity by gathering all related methods in one place. 通过将所有相关方法集中在一个地方,它提高了模块性。
- It further decouples the presentation and business logic layers. 它进一步解耦了展示层和业务逻辑层。
- It makes it easier to test the business functionality. 它使得测试业务功能变得更加容易。
That said, a service layer is not always necessary. For example, when the business logic is implemented as a transaction script, it essentially is a service layer, as it already exposes a set of methods that form the system’s public interface. In such a case, the service layer’s API would just repeat the transaction scripts’ public interfaces, without abstracting or encapsulating any complexity. Hence, either a service layer or a business logic layer will suffice.
话虽如此,服务层并不是总是必要的。例如,当业务逻辑被实现为事务脚本时,它本质上就是一个服务层,因为它已经暴露了一组方法,这些方法构成了系统的公共接口。在这种情况下,如果仍然坚持实现服务层的话,服务层的API将只是重复事务脚本的公共接口,而不会抽象或封装任何复杂性。因此,服务层和业务逻辑层二者只需要一个就足够了。
On the other hand, the service layer is required if the business logic pattern requires external orchestration, as in the case of the active record pattern. In this case, the service layer implements the transaction script pattern, while the active records it operates on are located in the business logic layer.
另一方面,如果业务逻辑模式需要外部编排(如活动记录模式),则服务层是必需的。在这种情况下,服务层实现事务脚本模式,而它所操作的活动记录则位于业务逻辑层中。
Terminology
术语
Elsewhere, you may encounter other terms used for the layered architecture:
在其他地方,您可能会遇到用于分层架构的其他术语:
- Presentation layer = user interface layer 展示层 = 用户界面层
- Service layer = application layer 服务层 = 应用层
- Business logic layer = domain layer = model layer 业务逻辑层 = 领域层 = 模型层
- Data access layer = infrastructure layer 数据访问层 = 基础设施层
To eliminate confusion, I present the pattern using the original terminology. That said, I prefer “user interface layer” and “infrastructure layer” as these terms better reflect the responsibilities of modern systems and an application layer to avoid confusion with the physical boundaries of services.
为了消除混淆,我使用原始术语来描述分层架构模式。尽管如此,我更喜欢“用户界面层”和“基础设施层”,因为这些术语更好地反映了现代系统的职责,而“应用层”则避免了与服务物理边界的混淆。
When to Use Layered Architecture
何时使用分层架构
The dependency between the business logic and the data access layers makes this architectural pattern a good fit for a system with its business logic implemented using the transaction script or active record pattern.
业务逻辑层和数据访问层之间的依赖关系使得这种架构模式非常适合使用事务脚本或活动记录模式实现其业务逻辑的系统。
However, the pattern makes it challenging to implement a domain model. In a domain model, the business entities (aggregates and value objects) should have no dependency and no knowledge of the underlying infrastructure. The layered architecture’s top-down dependency requires jumping through some hoops to fulfill this requirement. It is still possible to implement a domain model in a layered architecture, but the pattern we will discuss next fits much better.
然而,分层架构模式使得实现领域模型变得具有挑战性。在领域模型中,业务实体(聚合和值对象)应该没有依赖底层基础设施,也不知道底层基础设施。分层架构的自上而下的依赖关系需要通过一些手段来满足这一要求。尽管在分层架构中仍然可以实现领域模型,但接下来我们将讨论的模式更加适合。
OPTIONAL: LAYERS VERSUS TIERS 可选的(选修):LAYERS 与 TIERS
The layers architecture is often confused with the N-Tier architecture, and vice versa. Despite the similarities between the two patterns, layers and tiers are conceptually different: a layer is a logical boundary, whereas a tier is a physical boundary. All layers in the layered architecture are bound by the same lifecycle: they are implemented, evolved, and deployed as one single unit. On the other hand, a tier is an independently deployable service, server, or system. For example, consider the N-Tier system in Figure 8-7.
分层架构常常与 N 层架构相混淆,反之亦然。尽管这两种模式有相似之处,但layer和tier在概念上是不同的: layer是逻辑边界,而tier是物理边界。分层架构中的所有层都受到相同的生命周期的约束: 它们作为一个单一单元实现、演化和部署。另一方面,tier是一个可独立部署的服务、服务器或系统。例如,思考图8-7中的 N 层系统。

Figure 8-7. N-Tier system
图8-7. N 层系统
The system depicts the integration between physical services involved in a web-based system. The consumer uses a browser, which can run on a desktop computer or a mobile device. The browser interacts with a reverse proxy that forwards the requests to the actual web application. The web application runs on a web server and communicates with a database server. All of these components may run on the same physical server, such as containers, or be distributed among multiple servers. However, since each component can be deployed and managed independent of the rest, these are tiers and not layers. Layers, on the other hand, are logical boundaries inside the web application.
该系统描述了基于 Web 的系统中所涉及的物理服务之间的集成。使用者使用浏览器(可以运行在桌面计算机或移动设备上)。浏览器与反向代理进行交互,反向代理将请求转发给实际的 Web 应用程序。Web 应用程序运行在 Web 服务器上,并与数据库服务器进行通信。所有这些组件都可以运行在同一个物理服务器上,比如容器,或者分布在多个服务器之间。但是,由于每个组件都可以独立于其他组件进行部署和管理,因此这些组件是tier而不是layer。另一方面,layers是 Web 应用程序内部的逻辑边界。
Ports & Adapters
端口和适配器
The ports & adapters architecture addresses the shortcomings of the layered architecture and is a better fit for implementation of more complex business logic. Interestingly, both patterns are quite similar. Let’s “refactor” the layered architecture into ports & adapters.
端口与适配器架构解决了分层架构的缺点,更适合实现更复杂的业务逻辑。有趣的是,这两种模式非常相似。让我们将分层架构“重构”为端口与适配器架构。
Terminology
术语
Essentially, both the presentation layer and data access layer represent integration with external components: databases, external services, and user interface frameworks. These technical implementation details do not reflect the system’s business logic; so, let’s unify all such infrastructural concerns into a single “infrastructure layer,” as shown in Figure 8-8.
本质上,展示层和数据访问层都表示与外部组件的集成:数据库、外部服务和用户界面框架。这些技术实现细节并不反映系统的业务逻辑; 因此,让我们将所有这些基础设施关注点统一到一个单独的“基础设施层”,如图8-8所示。

Figure 8-8. Presentation and data access layers combined into an infrastructure layer
图8-8. 展示层和数据访问层合并为一个基础设施层
Dependency Inversion Principle
依赖倒置原则
The dependency inversion principle (DIP) states that high-level modules, which implement the business logic, should not depend on low-level modules. However, that’s precisely what happens in the traditional layered architecture. The business logic layer depends on the infrastructure layer. To conform with the DIP, let’s reverse the relationship, as shown in Figure 8-9.
依赖倒置原则(DIP)指出,实现业务逻辑的高级模块不应该依赖于低级模块。然而,这正是传统分层架构中所发生的事情。业务逻辑层依赖于基础设施层。为了符合DIP,让我们反转这种关系,如图8-9所示。
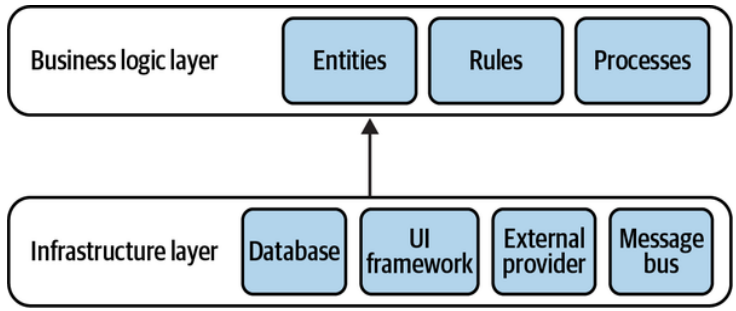
Figure 8-9. Reversed dependencies
图8-9. 反转依赖关系,现在基础设施层依赖于业务逻辑层
Instead of being sandwiched between the technological concerns, now the business logic layer takes the central role. It doesn’t depend on any of the system’s infrastructural components.
现在,业务逻辑层不再夹在技术关注点之间,而是扮演核心角色。它不依赖于任何系统的基础设施组件。
Finally, let’s add an application layer as a façade for the system’s public interface. As the service layer in the layered architecture, it describes all the operations exposed by the system and orchestrates the system’s business logic for executing them. The resultant architecture is depicted in Figure 8- 10.
最后,让我们增加一个应用层作为系统公共接口的门面。就像分层架构中的服务层一样,它描述系统公开的所有操作,并协调系统的业务逻辑来执行这些操作。最终得到的架构如图8-10所示。
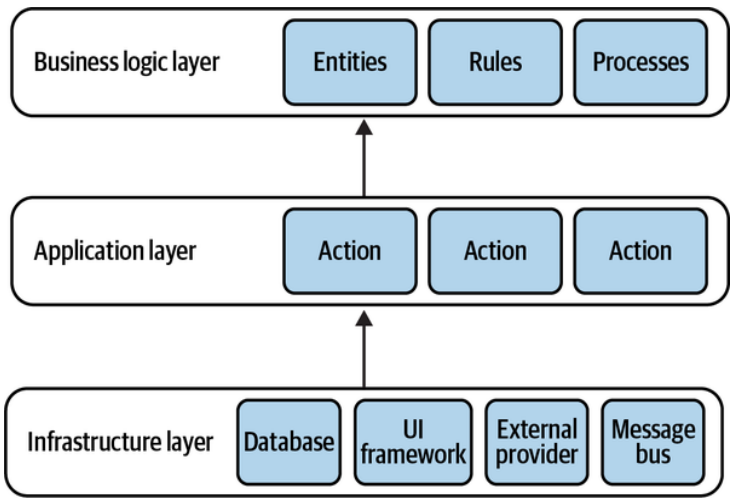
Figure 8-10. Traditional layers of the ports & adapters architecture
图8-10. 端口和适配器架构的传统层
The architecture depicted in Figure 8-10 is the ports & adapters architectural pattern. The business logic doesn’t depend on any of the underlying layers, as required for implementing the domain model and event-sourced domain model patterns.
图8-10描述的架构是端口和适配器架构模式。业务逻辑不依赖于任何底层,这是实现领域模型和基于事件的领域模型模式所必需的。
Why is this pattern called ports & adapters? To answer this question, let’s see how the infrastructural components are integrated with the business logic.
为什么这个模式被称为端口与适配器?为了回答这个问题,让我们看看基础设施组件是如何与业务逻辑集成的。
Integration of Infrastructural Components
基础设施组件的集成
The core goal of the ports & adapters architecture is to decouple the system’s business logic from its infrastructural components.
端口与适配器架构的核心目标是将系统的业务逻辑与其基础设施组件解耦。
Instead of referencing and calling the infrastructural components directly, the business logic layer defines “ports” that have to be implemented by the infrastructure layer. The infrastructure layer implements “adapters”: concrete implementations of the ports’ interfaces for working with different technologies (see Figure 8-11).
业务逻辑层不直接引用和调用基础设施组件,而是定义必须由基础设施层实现的“端口”。基础设施层实现了“适配器”: 用于端口的接口的使用不同技术的具体实现(参见图8-11)。
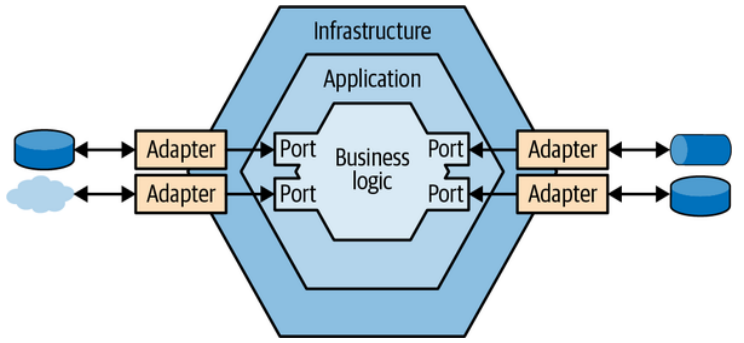
Figure 8-11. Ports & adapters architecture
图8-11. 端口和适配器架构
The abstract ports are resolved into concrete adapters in the infrastructure layer, either through dependency injection or by bootstrapping.
可以通过依赖注入或引导程序,将抽象端口解析为基础设施层实现的具体适配器。
For example, here is a possible port definition and a concrete adapter for a message bus:
例如,这是一个可能的消息总线端口定义和具体的适配器:
1 namespace App.BusinessLogicLayer 2 { 3 public interface IMessaging 4 { 5 void Publish(Message payload); 6 void Subscribe(Message type, Action callback); 7 } 8 } 9 namespace App.Infrastructure.Adapters 10 { 11 public class SQSBus: IMessaging { ... } 12 }
Variants
变体
The ports & adapters architecture is also known as hexagonal architecture, onion architecture, and clean architecture. All of these patterns are based on the same design principles, have the same components, and have the same relationships between them, but as in the case of the layered architecture, the terminology may differ:
端口与适配器架构也被称为六边形架构、洋葱架构和整洁架构。所有这些模式都基于相同的设计原则,具有相同的组件,并且它们之间具有相同的关系,但就像分层架构一样,术语可能有所不同:
- Application layer = service layer = use case layer 应用层 = 服务层 = 用例层
- Business logic layer = domain layer = core layer 业务逻辑层 = 领域层 = 核心层
Despite that, these patterns can be mistakenly treated as conceptually different. That’s just another example of the importance of a ubiquitous language.
尽管如此,这些模式可能会被误认为是不同的概念。这再次说明了通用语言的重要性。
When to Use Ports & Adapters
何时使用端口和适配器架构
The decoupling of the business logic from all technological concerns makes the ports & adapters architecture a perfect fit for business logic implemented with the domain model pattern.
业务逻辑与所有技术问题的解耦,使得端口与适配器架构非常适合使用领域模型模式实现的业务逻辑。
Command-Query Responsibility Segregation
命令查询职责分离
The command-query responsibility segregation (CQRS) pattern is based on the same organizational principles for business logic and infrastructural concerns as ports & adapters. It differs, however, in the way the system’s data is managed. This pattern enables representation of the system’s data in multiple persistent models.
命令-查询职责分离(CQRS)模式在业务逻辑和基础设施问题的组织原则上与端口与适配器相同。然而,它在管理系统数据的方式上有所不同。这个模式使得系统数据能够在多个持久化模型中表示。
Let’s see why we might need such a solution and how to implement it.
让我们来看看为什么我们可能需要这样的解决方案,以及如何实现它。
Polyglot Modeling
多语言建模
In many cases, it may be difficult, if not impossible, to use a single model of the system’s business domain to address all of the system’s needs. For example, as discussed in Chapter 7, online transaction processing (OLTP) and online analytical processing (OLAP) may require different representations of the system’s data.
在许多情况下,使用系统的业务领域的一个单一模型来满足系统的所有需求可能是困难的,甚至是不可能的。例如,正如第7章所讨论的,联机事务处理(OLTP)和联机分析处理(OLAP)可能需要系统数据的不同表示形式。
Another reason for working with multiple models may have to do with the notion of polyglot persistence. There is no perfect database. Or, as Greg Young says, all databases are flawed, each in its own way: we often have to balance the needs for scale, consistency, or supported querying models. An alternative to finding a perfect database is the polyglot persistence model: using multiple databases to implement different data-related requirements. For example, a single system might use a document store as its operational database, a column store for analytics/reporting, and a search engine for implementing robust search capabilities.
使用多个模型的另一个原因可能与多语言持久化的概念有关。没有完美的数据库。或者,正如格雷格·杨(Greg Young)所说,所有的数据库都是有缺陷的,各有各的缺点:我们通常需要平衡规模、一致性或支持的查询模型的需求。寻找完美数据库的替代方案是多语言持久化模型:使用多个数据库来实现不同的数据相关需求。例如,一个单独的系统可能会同时使用文档存储作为其操作型数据库,同时使用列式存储进行分析/报告,以及同时使用搜索引擎来实现强大的搜索功能。
Finally, the CQRS pattern is closely related to event sourcing. Originally, CQRS was defined to address the limited querying possibilities of an event-sourced model: it is only possible to query events of one aggregate instance at a time. The CQRS pattern provides the possibility of materializing projected models into physical databases that can be used for flexible querying options.
最后,CQRS 模式与事件源密切相关。最初,CQRS 的定义是为了解决事件溯源模型的查询局限性:一次只能查询一个聚合实例的事件。CQRS 模式提供了将投影模型具体化到物理数据库的可能性,这些物理数据库可用于灵活的查询选项。
That said, this chapter “decouples” CQRS from event sourcing. I intend to show that CQRS is useful even if the business logic is implemented using any of the other business logic implementation patterns.
话虽如此,本章将“解耦”CQRS与事件溯源。我打算展示,即使业务逻辑是使用其他任何业务逻辑实现模式实现的,CQRS也是有用的。
Let’s see how CQRS allows the use of multiple storage mechanisms for representing different models of the system’s data.
让我们看看CQRS是如何允许使用多种存储机制来表示系统数据的不同模型的。
Implementation
实现
As the name suggests, the pattern segregates the responsibilities of the system’s models. There are two types of models: the command execution model and the read models.
顾名思义,该模式将系统模型的职责分离开来。有两种类型的模型: 命令执行模型和读模型。
Command execution model
命令执行模型
CQRS devotes a single model to executing operations that modify the system’s state (system commands). This model is used to implement the business logic, validate rules, and enforce invariants.
CQRS使用一个单独的模型来执行修改系统状态的操作(系统命令)。此模型(命令执行模型)用于实现业务逻辑、验证规则和强制不变性。
The command execution model is also the only model representing strongly consistent data—the system’s source of truth. It should be possible to read the strongly consistent state of a business entity and have optimistic concurrency support when updating it.
命令执行模型也是唯一表示强一致性数据的模型——系统的真相来源。命令执行模型应该能够读取业务实体的强一致性状态,并在更新它时具有乐观并发支持。
Read models (projections)
读模型(投射、投影)
The system can define as many models as needed to present data to users or supply information to other systems.
系统可以根据需要定义尽可能多的模型,以便向用户呈现数据或向其他系统提供信息。
A read model is a precached projection. It can reside in a durable database, flat file, or in-memory cache. Proper implementation of CQRS allows for wiping out all data of a projection and regenerating it from scratch. This also enables extending the system with additional projections in the future —models that couldn’t have been foreseen originally.
读模型是一个预缓存的投影。它可以驻留在持久性数据库、文本文件或内存缓存中。CQRS 的正确实现允许清除投射的所有数据并从头开始重新生成它。这也使得系统能够在未来扩展其它的投射——这些模型在最初是无法预见的。
Finally, read models are read-only. None of the system’s operations can directly modify the read models’ data.
最后,读模型是只读的,系统的任何操作都不能直接修改读模型的数据。
Projecting Read Models
投影读模型
For the read models to work, the system has to project changes from the command execution model to all its read models. This concept is illustrated in Figure 8-12.
为了让读模型正常工作,系统必须将命令执行模型的变化投影到所有的读模型上。这个概念在图8-12中有所说明。
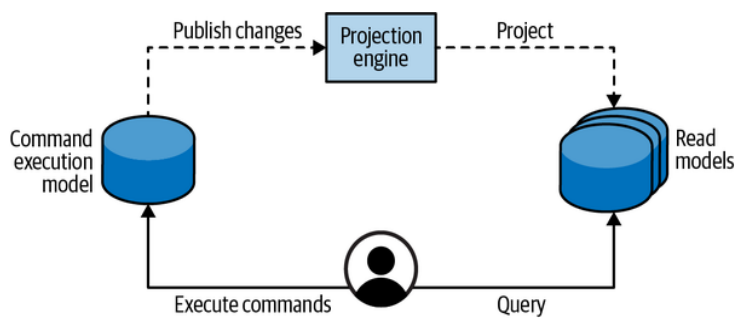
Figure 8-12. CQRS architecture
图8-12. CQRS 架构
The projection of read models is similar to the notion of a materialized view in relational databases: whenever source tables are updated, the changes have to be reflected in the precached views.
读模型的投影类似于关系数据库中物化视图的概念:每当源表被更新时,变化都必须反映在预缓存的视图中。
Next, let’s see two ways to generate projections: synchronously and asynchronously.
接下来,让我们看看生成投影的两种方式:同步和异步。
Synchronous projections
同步投影
Synchronous projections fetch changes to the OLTP data through the catch-up subscription model:
同步投影通过追赶订阅模型获取OLTP数据的变化:
- The projection engine queries the OLTP database for added or updated records after the last processed checkpoint. 投影引擎查询OLTP数据库,以获取自上次处理的检查点以来添加或更新的记录。
- The projection engine uses the updated data to regenerate/update the system’s read models. 投影引擎使用更新的数据来重新生成/更新系统的读模型。
- The projection engine stores the checkpoint of the last processed record. This value will be used during the next iteration for getting records added or modified after the last processed record. 投影引擎存储最近一次处理记录的检查点。在下一次迭代中,将使用此值来获取自上次处理的记录之后添加或修改的记录。
This process is illustrated in Figure 8-13 and shown as a sequence diagram in Figure 8-14.
这个过程如图8-13所示,并在图8-14中以序列图的形式展示。
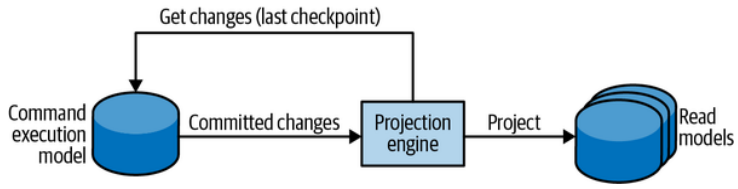
Figure 8-13. Synchronous projection model
图8-13. 同步投影模型
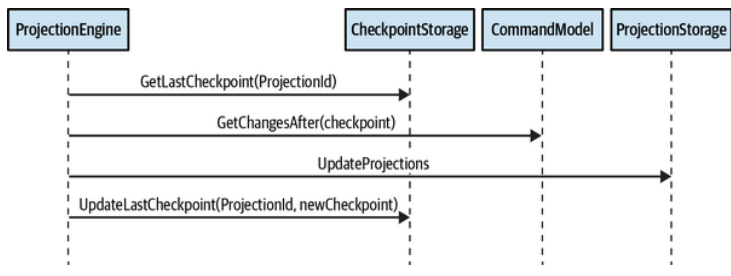
Figure 8-14. Synchronous projection of read models through catch-up subscription
图8-14. 通过追赶订阅同步投影读模型
For the catch-up subscription to work, the command execution model has to checkpoint all the appended or updated database records. The storage mechanism should also support the querying of records based on the checkpoint.
为了让追赶订阅工作,命令执行模型必须对所有添加或更新的数据库记录进行检查点处理。存储机制也应该支持基于检查点的记录查询。
The checkpoint can be implemented using the databases’ features. For example, SQL Server’s “rowversion” column can be used to generate unique, incrementing numbers upon inserting or updating a row, as illustrated in Figure 8-15. In databases that lack such functionality, a custom solution can be implemented that increments a running counter and appends it to each modified record. It’s important to ensure that the checkpoint-based query returns consistent results. If the last returned record has a checkpoint value of 10, on the next execution no new requests should have values lower than 10. Otherwise, these records will be skipped by the projection engine, which will result in inconsistent models.
检查点可以使用数据库的特性来实现。例如,SQLServer 的“ rowversion(行版本)”列可用于在插入或更新行时生成唯一的、递增的数字,如图8-15所示。在缺乏此类功能的数据库中,可以实现一个自定义解决方案,该解决方案增加一个运行计数器,并将其附加到每个修改后的记录上。确保基于检查点的查询返回一致的结果非常重要。如果最近一次返回的记录的检查点值为10,则在下一次执行时,任何新请求的值都不应低于10。否则,这些记录将被投射引擎跳过,从而导致模型不一致。
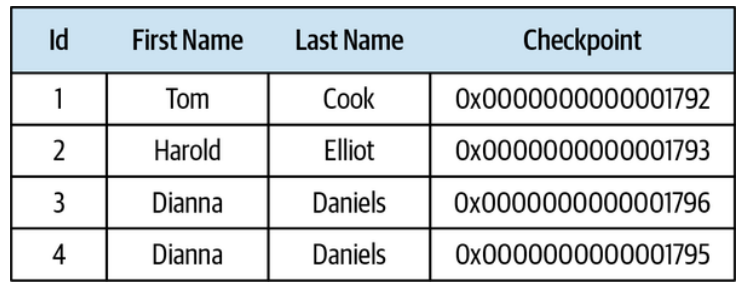
Figure 8-15. Auto-generated checkpoint column in a relational database
图8-15. 关系数据库中自动生成的检查点列
The synchronous projection method makes it trivial to add new projections and regenerate existing ones from scratch. In the latter case, all you have to do is reset the checkpoint to 0; the projection engine will scan the records and rebuild the projections from the ground up.
同步投影方法使得添加新投影和从头开始重新生成现有投影变得轻而易举。在后一种情况下,您所要做的就是将检查点重置为0;投影引擎将扫描记录并从头开始重建投影。
Asynchronous projections
异步投影
In the asynchronous projection scenario, the command execution model publishes all committed changes to a message bus. The system’s projection engines can subscribe to the published messages and use them to update the read models, as shown in Figure 8-16.
在异步投影场景中,命令执行模型将所有已提交的更改发布到消息总线。系统的投影引擎可以订阅发布的消息,并使用它们来更新读模型,如图8-16所示。
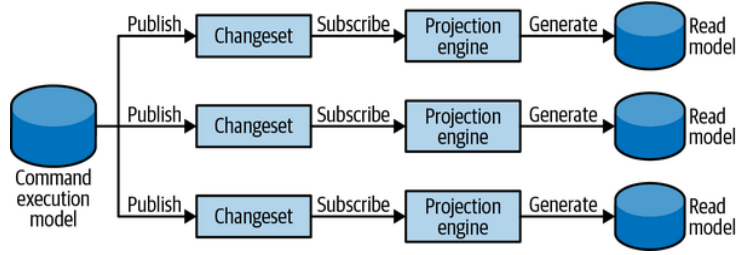
Figure 8-16. Asynchronous projection of read models
图8-16. 读模型的异步投影
Challenges
挑战
Despite the apparent scaling and performance advantages of the asynchronous projection method, it is more prone to the challenges of distributed computing. If the messages are processed out of order or duplicated, inconsistent data will be projected into the read models.
尽管异步投影方法在扩展性和性能方面有着明显的优势,但它更容易受到分布式计算挑战的影响。如果消息处理顺序错误或重复,则不一致的数据将被投影到读模型中。
This method also makes it more challenging to add new projections or regenerate existing ones.
这种方法也使得添加新的投影或重新生成现有的投影更具挑战性。
For these reasons, it’s advisable to always implement synchronous projection and, optionally, an additional asynchronous projection on top of it.
由于这些原因,建议始终实现同步投射,并且可以选择在同步投射基础之上再另外实现异步投影。
翻译:出于这些原因,建议始终实现同步投影,并可选地在同步投影基础上添加额外的异步投影。
Model Segregation
模型分离
In the CQRS architecture, the responsibilities of the system’s models are segregated according to their type. A command can only operate on the strongly consistent command execution model. A query cannot directly modify any of the system’s persisted state—neither the read models nor the command execution model.
在CQRS架构中,系统模型的职责根据其类型进行了分离。命令只能在强一致性的命令执行模型上操作。查询不能直接修改系统的任何持久化状态——无论是读模型还是命令执行模型。
A common misconception about CQRS-based systems is that a command can only modify data, and data can be fetched for display only through a read model. In other words, the command executing the methods should never return any data. This is wrong. This approach produces accidental complexities and leads to a bad user experience.
关于基于CQRS的系统的一个常见误解是,命令只能修改数据,并且只能通过读模型来获取数据以进行显示。换句话说,执行方法的命令永远不应该返回任何数据。这是错误的。这样做会产生意外的复杂性,并导致糟糕的用户体验。
A command should always let the caller know whether it has succeeded or failed. If it has failed, why did it fail? Was there a validation or technical issue? The caller has to know how to fix the command. Therefore, a command can—and in many cases should—return data; for example, if the system’s user interface has to reflect the modifications resulting from the command. Not only does this make it easier for consumers to work with the system since they immediately receive feedback for their actions, but the returned values can be used further in the consumers’ workflows, eliminating the need for unnecessary data round trips.
命令应该始终让调用者知道它是成功了还是失败了。如果失败了,为什么失败? 是验证问题还是技术问题?调用者必须知道如何修复命令。因此,因此,命令可以——并且在很多情况下应该——返回数据;例如,如果系统的用户界面必须反映由命令导致的修改。这不仅使使用者更容易使用系统,因为他们可以立即收到操作的反馈,而且返回的值可以在使用者的工作流中进一步使用,从而消除了不必要的数据往返的需求。
The only limitation here is that the returned data should originate from the strongly consistent model—the command execution model—as we cannot expect the projections, which will eventually be consistent, to be refreshed immediately.
这里的唯一限制是,返回的数据必须来自强一致性模型——即命令执行模型——因为我们不能期望最终一致性的投影会立即刷新。
When to Use CQRS
何时使用CQRS
The CQRS pattern can be useful for applications that need to work with the same data in multiple models, potentially stored in different kinds of databases. From an operational perspective, the pattern supports domain-driven design’s core value of working with the most effective models for the task at hand, and continuously improving the model of the business domain. From an infrastructural perspective, CQRS allows for leveraging the strength of the different kinds of databases; for example, using a relational database to store the command execution model, a search index for full text search, and prerendered flat files for fast data retrieval, with all the storage mechanisms reliably synchronized.
CQRS模式对于需要在多个模型中处理相同数据的应用程序很有用,这些模型可能存储在不同类型的数据库中。从操作的角度来看,该模式支持领域驱动设计的核心价值,即使用最有效的模型来处理当前任务,并不断改进业务领域的模型。从基础设施的角度来看,CQRS允许利用不同类型数据库的优势;例如,使用关系数据库来存储命令执行模型,使用搜索引擎进行全文搜索,使用预渲染的文本文件来快速检索数据,同时确保所有存储机制可靠地同步。
Moreover, CQRS naturally lends itself to event-sourced domain models. The event-sourcing model makes it impossible to query records based on the aggregates’ states, but CQRS enables this by projecting the states into queryable databases.
此外,CQRS天然地适用于基于事件源的领域模型。事件源模型使得基于聚合状态查询记录变得不可能,但CQRS通过将状态投影到可查询的数据库中来实现这一点。
Scope
范围
The patterns we’ve discussed—layered architecture, ports & adapters architecture, and CQRS—should not be treated as systemwide organizational principles. These are not necessarily high-level architecture patterns for a whole bounded context either.
我们讨论的模式——分层架构、端口与适配器架构和CQRS——不应被视为全局的组织原则。它们也不一定是整个有界上下文的高级架构模式。
Consider a bounded context encompassing multiple subdomains, as shown in Figure 8-17. The subdomains can be of different types: core, supporting, or generic. Even subdomains of the same type may require different business logic and architectural patterns (that’s the topic of Chapter 10).
思考一个包含多个子域的有界上下文,如图8-17所示。子域可以是不同类型的:核心子域,支撑子域或通用子域。即使是相同类型的子域也可能需要不同的业务逻辑和架构模式(这是第10章的主题)。
Enforcing a single, bounded, contextwide architecture will inadvertently lead to accidental complexity.
强制使用单一、有界、全上下文范围的架构将不可避免地导致意外的复杂性。
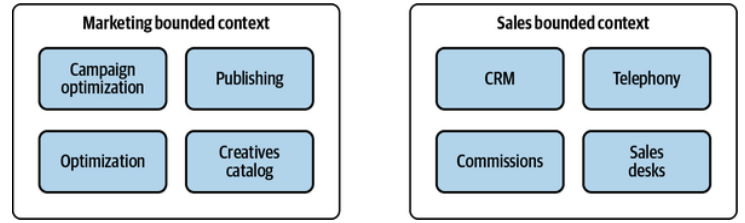
Figure 8-17. Bounded contexts spanning multiple subdomains
图8-17. 跨越多个子域的有界上下文
Our goal is to drive design decisions according to the actual needs and business strategy. In addition to the layers that partition the system horizontally, we can introduce additional vertical partitioning. It’s crucial to define logical boundaries for modules encapsulating distinct business subdomains and use the appropriate tools for each, as demonstrated in Figure 8-18.
我们的目标是根据实际需求和业务策略来推动设计决策。除了将系统水平分割的分层之外,我们还可以引入额外的垂直分割。为封装不同业务子域的模块定义逻辑边界,并针对每个子域使用适当的工具,这是至关重要的,如图8-18所示。
Appropriate vertical boundaries make a monolithic bounded context a modular one and help to prevent it from becoming a big ball of mud. As we will discuss in Chapter 11, these logical boundaries can be refactored later into physical boundaries of finer-grained bounded contexts.
适当的垂直边界将单体的有界上下文变为模块化的,并防止它变成一个大泥球。正如我们将在第11章中讨论的,这些逻辑边界以后可以重构为更细粒度的有界上下文的物理边界。
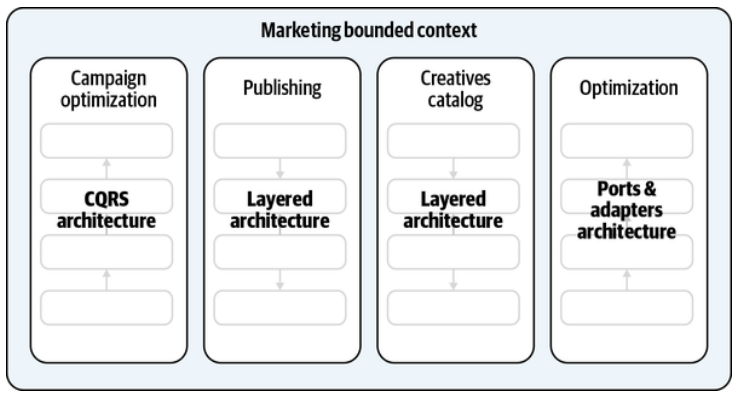
Figure 8-18. Architectural slices
图8-18. 架构切片
Conclusion
总结
The layered architecture decomposes the codebase based on its technological concerns. Since this pattern couples business logic with data access implementation, it’s a good fit for active record–based systems.
分层架构基于技术关注点对代码库进行分解。由于这种模式将业务逻辑与数据访问实现结合在一起,因此非常适合基于活动记录的系统。
The ports & adapters architecture inverts the relationships: it puts the business logic at the center and decouples it from all infrastructural dependencies. This pattern is a good fit for business logic implemented with the domain model pattern.
端口和适配器架构反转了这种依赖关系:它将业务逻辑放在中心位置,并将其与所有基础设施依赖关系解耦。此模式非常适合用领域模型模式实现业务逻辑。
The CQRS pattern represents the same data in multiple models. Although this pattern is obligatory for systems based on the event-sourced domain model, it can also be used in any systems that need a way of working with multiple persistent models.
:CQRS模式在多个模型中表示相同的数据。虽然这种模式对于基于事件源领域模型的系统是必需的,但它也可以用于任何需要处理多个持久化模型的系统。
The patterns we will discuss in the next chapter address architectural concerns from a different perspective: how to implement reliable interaction between different components of a system.
我们将在下一章讨论的模式将从不同的角度解决架构问题:如何实现系统不同组件之间的可靠交互。
Exercises
练习
1. Which of the discussed architectural patterns can be used with business logic implemented as the active record pattern? 在讨论过的架构模式中,哪些可以与作为活动记录模式实现的业务逻辑一起使用?
a. Layered architecture 分层架构
b. Ports & adapters 端口与适配器
c. CQRS 命令查询职责分离
d. A and C A和C
答案:d。
2. Which of the discussed architectural patterns decouples the business logic from infrastructural concerns? 在讨论过的架构模式中,哪些模式将业务逻辑与基础设施关注点解耦(分离)?
a. Layered architecture 分层架构
b. Ports & adapters 端口与适配器
c. CQRS 命令查询职责分离
d. B and C B和C
答案:d。
3. Assume you are implementing the ports & adapters pattern and need to integrate a cloud provider’s managed message bus. In which layer should the integration be implemented? 假设你正在实现端口与适配器模式,并且需要集成云提供商的托管消息总线。集成应该在哪个层实现?
a. Business logic layer 业务逻辑层
b. Application layer 应用层
c. Infrastructure layer 基础设施层
d. Any layer 任意层
答案:c。
4. Which of the following statements is true regarding the CQRS pattern? 关于 CQRS 模式,下列哪个陈述是正确的?
a. Asynchronous projections are easier to scale. 异步投影更容易缩放。
b. Either synchronous or asynchronous projection can be used, but not both at the same time. 可以使用同步投影或异步投影,但不能同时使用两者。
c. A command cannot return any information to the caller. The caller should always use the read models to get the results of the executed actions. 命令不能向调用者返回任何信息。调用者应该始终使用读模型来获取执行操作的结果。
d. A command can return information as long as it originates from a strongly consistent model. 只要命令来源于强一致性模型,它就可以返回信息。
e. A and D. A和D
答案:e。
5. The CQRS pattern allows for representing the same business objects in multiple persistent models, and thus allows working with multiple models in the same bounded context. Does it contradict the bounded context’s notion of being a model boundary? CQRS模式允许在多个持久化模型中表示相同的业务对象,因此允许在同一有界上下文中使用多个模型。这是否与有界上下文作为模型边界的概念相矛盾?
答案:Working with multiple models projected by the CQRS pattern doesn’t contradict the bounded context’s requirement of being a model boundary, since only one of the models is defined as the source of truth and is used for making changes in the aggregates’ states. 使用 CQRS 模式投影的多个模型并不违背有界上下文作为模型边界的要求,因为只有一个模型(命令执行模型)被定义为真相来源,并用于改变聚合的状态。
1 Evans, E. (2003). Domain-Driven Design: Tackling Complexity in the Heart of Software. Boston: Addison-Wesley. 领域驱动设计: 处理软件核心的复杂性。
2 Such as AWS S3 or Google Cloud Storage. 比如 AWS S3或 Google 云存储。
3 In this context, the message bus is used for the system’s internal needs. If it were exposed publicly, it would belong to the presentation layer. 在这种情况下,消息总线用于系统的内部需求。如果它被公开暴露,那么它将属于表示层。
4 Fowler, M. (2002). Patterns of Enterprise Application Architecture. Boston: Addison-Wesley. 企业应用架构模式。波士顿: Addison-Wesley。
5 Since we are not in the context of the layered architecture, I will take the freedom to use the term application layer instead of service layer, as it better reflects the purpose. 由于我们现在不是在分层架构的上下文中,我将自由地使用“应用层”这个术语来代替“服务层”,因为它更好地反映了目的。
6 Polyglot data by Greg Young. (n.d.). Retrieved June 14, 2021, from YouTube. 多语言数据由 Greg Young 提供,2021年6月14日,来自 YouTube。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号