烂翻译系列之学习领域驱动设计——第七章:对时间维度进行建模
In the previous chapter, you learned about the domain model pattern: its building blocks, purpose, and application context. The event-sourced domain model pattern is based on the same premise as the domain model pattern. Again, the business logic is complex and belongs to a core subdomain. Moreover, it uses the same tactical patterns as the domain model: value objects, aggregates, and domain events.
在上一章中,您了解了领域模型模式:其构建块、用途和应用背景(场景)。事件源领域模型模式与领域模型模式基于相同的理念。同样,业务逻辑复杂并且属于核心子域。此外,它使用与领域模型相同的战术模式:值对象、聚合和领域事件。
The difference between these implementation patterns lies in the way the aggregates’ state is persisted. The event-sourced domain model uses the event sourcing pattern to manage the aggregates’ states: instead of persisting an aggregate’s state, the model generates domain events describing each change and uses them as the source of truth for the aggregate’s data.
这些实现模式之间的区别在于聚合状态的持久化方式。事件源领域模型使用事件源模式来管理聚合的状态:该模型不是直接持久化聚合的状态,而是生成描述每个更改的领域事件,并将这些事件作为聚合数据的真相来源。
This chapter starts by introducing the notion of event sourcing. Then it covers how event sourcing can be combined with the domain model pattern, making it an event-sourced domain model.
本章首先介绍事件源的概念。然后讨论如何将事件源与领域模型模式相结合,使其成为事件源领域模型。
Event Sourcing
事件源
Show me your flowchart and conceal your tables, and I shall continue to be mystified. Show me your tables, and I won’t usually need your flowchart; it’ll be obvious. —Fred Brooks
给我看你的流程图,而不给我看你的表格,我会继续感到困惑。给我看你的表格,我通常就不需要你的流程图了,事情就会变得一目了然。——弗雷德 · 布鲁克斯
Let’s use Fred Brooks’s reasoning to define the event sourcing pattern and understand how it differs from traditional modeling and persisting of data. Examine Table 7-1 and analyze what you can learn from this data about the system it belongs to.
让我们使用 弗雷德 · 布鲁克斯 的推理来定义事件源模式,并理解它与传统的数据建模和持久化有何不同。查看表7-1,并分析您可以从这些数据中了解它所属的系统信息。
Table 7-1. State-based model
表7-1. 基于状态的模型
| lead-id | first-name | last-name | status | phone-number | followup-on | created-on | upd |
| 1 | Sean | Callahan | CONVERTED | 555-1246 | 2019- 01-31 T 10:02:40.32Z | ||
| 2 | Sarah | Estrada | CLOSED | 555-4395 | 2019- 03-29 T 22:01:41.44Z | ||
| 3 | Stephanie | Brown | CLOSED | 555-1176 | 2019- 04-15 T 23:08:45.59Z | ||
| 4 | Sami | Calhoun | CLOSED | 555-1850 | 2019- 04-25 T 05:42:17.07Z | ||
| 5 | William | Smith | CONVERTED | 555-3013 | 2019- 05-14 T 04:43:57.51Z | ||
| 6 | Sabri | Chan | NEW_LEAD | 555-2900 | 2019- 06-19 T 15:01:49.68Z | ||
| 7 | Samantha | Espinosa | NEW_LEAD | 555-8861 | 2019- 07-17 T 13:09:59.32Z | ||
| 8 | Hani | Cronin | CLOSED | 555-3018 | 2019- 10-09 T 11:40:17.13Z | ||
| 9 | Sian | Espinoza | FOLLOWUP_SET | 555-6461 | 2019- 12-04 T 01:49:08.05Z | 2019- 12-04 T 01:49:08.05Z | |
| 10 | Sophia | Escamilla | CLOSED | 555-4090 | 2019- 12-06 T 09:12:32.56Z | ||
| 11 | William | White | FOLLOWUP_SET | 555-1187 | 2020- 01-23 T 00:33:13.88Z | 2020- 01-23 T 00:33:13.88Z | |
| 12 | Casey | Davis | CONVERTED | 555-8101 | 2020- 05-20 T 09:52:55.95Z | ||
| 13 | Walter | Connor | NEW_LEAD | 555-4753 | 2020- 04-20 T 06:52:55.95Z | ||
| 14 | Sophie | Garcia | CONVERTED | 555-1284 | 2020- 05-06 T 18:47:04.70Z | ||
| 15 | Sally | Evans | PAYMENT_FAILED | 555-3230 | 2020- 06-04 T 14:51:06.15Z | ||
| 16 | Scott | Chatman | NEW_LEAD | 555-6953 | 2020- 06-09 T 09:07:05.23Z | ||
| 17 | Stephen | Pinkman | CONVERTED | 555-2326 | 2020- 07-20 T 00:56:59.94Z | ||
| 18 | Sara | Elliott | PENDING_PAYMENT | 555-2620 | 2020- 08-12 T 17:39:43.25Z | ||
| 19 | Sadie | Edwards | FOLLOWUP_SET | 555-8163 | 2020- 10-22 T 12:40:03.98Z | 2020- 10-22 T 12:40:03.98Z | |
| 20 | William | Smith | PENDING_PAYMENT | 555-9273 | 2020- 11-13 T 08:14:07.17Z |
It’s evident that the table is used to manage potential customers, or leads, in a telemarketing system. For each lead, you can see their ID, their first and last names, when the record was created and updated, their phone number, and the lead’s current status.
很明显,该表格是在电话营销系统中用来管理潜在客户,或线索(即潜在商机)。对于每个线索(即潜在商机),您可以看到他们的 ID、他们的姓和名、记录的创建时间和更新时间、他们的电话号码以及线索(即潜在商机)的当前状态。
By examining the various statuses, we can also assume the processing cycle each potential customer goes through:
通过检查各种状态,我们还可以推测每个潜在客户所经历的处理流程:
- The sales flow starts with the potential customer in the NEW_LEAD status. 销售流程从处于 NEW _ LEAD 状态的潜在客户开始。
- A sales call can end with the person not being interested in the offer (the lead is CLOSED), scheduling a follow-up call (FOLLOWUP_SET), or accepting the offer (PENDING_PAYMENT). 销售电联的结果可能是潜在客户对报价(提议)不感兴趣(潜在商机被关闭,即 CLOSED),安排后续电话(FOLLOWUP_SET),或接受报价(提议)(PENDING_PAYMENT)。
- If the payment is successful, the lead is CONVERTED into a customer. Conversely, the payment can fail— PAYMENT_FAILED. 如果支付成功,潜在客户将被转化为正式客户。相反,支付可能会失败——PAYMENT_FAILED。
That’s quite a lot of information that we can gather just by analyzing a table’s schema and the data stored in it. We can even assume what ubiquitous language was used when modeling the data. But what information is missing from that table?
仅仅通过分析表的架构和存储在其中的数据,我们就可以收集到相当多的信息。我们甚至可以推测在建模数据时使用了什么样的通用语言。但是,这个表缺少了哪些信息?
The table’s data documents the leads’ current states, but it misses the story of how each lead got to their current state. We can’t analyze what was happening during the lifecycles of leads. We don’t know how many calls were made before a lead became CONVERTED. Was a purchase made right away, or was there a lengthy sales journey? Based on the historical data, is it worth trying to contact a person after multiple follow-ups, or is it more efficient to close the lead and move to a more promising prospect? None of that information is there. All we know are the leads’ current states.
表中的数据记录了潜在客户的当前状态,但它遗漏了每个潜在客户如何达到当前状态的故事。我们无法分析潜在客户的生命周期中发生了什么。我们不知道在潜在客户转化为正式客户(进入CONVERTED状态)之前打了多少通电话。是立即购买,还是经历了一个漫长的推销过程?根据历史数据,在多次跟进后是否值得继续尝试联系,还是关闭这个潜在客户并转向更有希望的潜在客户更为有效?这些信息都没有。我们所知道的只是潜在客户的当前状态。
These questions reflect business concerns essential for optimizing the sales process. From a business standpoint, it’s crucial to analyze the data and optimize the process based on the experience. One of the ways to fill in the missing information is to use event sourcing.
这些问题反映了对优化销售流程至关重要的业务关注点。从业务角度来看,基于经验分析数据并优化流程是至关重要的。填补缺失信息的方法之一是使用事件源。
The event sourcing pattern introduces the dimension of time into the data model. Instead of the schema reflecting the aggregates’ current state, an event sourcing–based system persists events documenting every change in an aggregate’s lifecycle.
事件源模式将时间维度引入到数据模型中。与传统的基于聚合当前状态的架构不同,基于事件源的系统持久化事件(这些事件记录了聚合生命周期中的每一个变化)。
Consider the CONVERTED customer on line 12 in Table 7-1. The following listing demonstrates how the person’s data would be represented in an event-sourced system:
思考表7-1中第12行的 CONVERTED 客户。下面的清单演示了如何在事件源系统中表示人员的数据:
1 { 2 "lead-id": 12, 3 "event-id": 0, 4 "event-type": "lead-initialized", 5 "first-name": "Casey", 6 "last-name": "David", 7 "phone-number": "555-2951", 8 "timestamp": "2020-05-20T09:52:55.95Z" 9 }, 10 { 11 "lead-id": 12, 12 "event-id": 1, 13 "event-type": "contacted", 14 "timestamp": "2020-05-20T12:32:08.24Z" 15 }, 16 { 17 "lead-id": 12, 18 "event-id": 2, 19 "event-type": "followup-set", 20 "followup-on": "2020-05-27T12:00:00.00Z", 21 "timestamp": "2020-05-20T12:32:08.24Z" 22 }, 23 { 24 "lead-id": 12, 25 "event-id": 3, 26 "event-type": "contact-details-updated", 27 "first-name": "Casey", 28 "last-name": "Davis", 29 "phone-number": "555-8101", 30 "timestamp": "2020-05-20T12:32:08.24Z" 31 }, 32 { 33 "lead-id": 12, 34 "event-id": 4, 35 "event-type": "contacted", 36 "timestamp": "2020-05-27T12:02:12.51Z" 37 }, 38 { 39 "lead-id": 12, 40 "event-id": 5, 41 "event-type": "order-submitted", 42 "payment-deadline": "2020-05-30T12:02:12.51Z", 43 "timestamp": "2020-05-27T12:02:12.51Z" 44 }, 45 { 46 "lead-id": 12, 47 "event-id": 6, 48 "event-type": "payment-confirmed", 49 "status": "converted", 50 "timestamp": "2020-05-27T12:38:44.12Z" 51 }
The events in the listing tell the customer’s story. The lead was created in the system (event 0) and was contacted by a sales agent about two hours later (event 1). During the call, it was agreed that the sales agent would call back a week later (event 2), but to a different phone number (event 3). The sales agent also fixed a typo in the last name (event 3). The lead was contacted on the agreed date and time (event 4) and submitted an order (event 5). The order was to be paid in three days (event 5), but the payment was received about half an hour later (event 6), and the lead was converted into a new customer.
清单中的事件讲述了客户的故事。潜在客户在系统中被创建(事件0),大约两小时后被销售客服联系(事件1)。在电话中,双方约定销售客服将在一周后进行电话回访(事件2),但打另外的电话号码(更新潜在客户信息)(事件3)。销售客服还修正了姓氏中的拼写错误(事件3)。在约定的日期和时间,销售客服再次联系潜在客户(事件4),客户提交了订单(事件5)。订单将在三天内付款(事件5) ,但付款是在大约半小时后收到的(事件6),且潜在客户因此转化为新客户。
As we saw earlier, the customer’s state can easily be projected out from these domain events. All we have to do is apply simple transformation logic sequentially to each event:
正如我们之前所看到的,可以很容易地根据这些领域事件推算出客户的状态。我们只需要按顺序对每个事件应用简单的转换逻辑即可:
1 public class LeadSearchModelProjection 2 { 3 public long LeadId { get; private set; } 4 public HashSet<string> FirstNames { get; private set; } 5 public HashSet<string> LastNames { get; private set; } 6 public HashSet<PhoneNumber> PhoneNumbers { get; private set; } 7 public int Version { get; private set; } 8 public void Apply(LeadInitialized @event) 9 { 10 LeadId = @event.LeadId; 11 FirstNames = new HashSet<string>(); 12 LastNames = new HashSet<string>(); 13 PhoneNumbers = new HashSet<PhoneNumber>(); 14 FirstNames.Add(@event.FirstName); 15 LastNames.Add(@event.LastName); 16 PhoneNumbers.Add(@event.PhoneNumber); 17 Version = 0; 18 } 19 public void Apply(ContactDetailsChanged @event) 20 { 21 FirstNames.Add(@event.FirstName); 22 LastNames.Add(@event.LastName); 23 PhoneNumbers.Add(@event.PhoneNumber); 24 Version += 1; 25 } 26 public void Apply(Contacted @event) 27 { 28 Version += 1; 29 } 30 public void Apply(FollowupSet @event) 31 { 32 Version += 1; 33 } 34 public void Apply(OrderSubmitted @event) 35 { 36 Version += 1; 37 } 38 public void Apply(PaymentConfirmed @event) 39 { 40 Version += 1; 41 } 42 }
Iterating an aggregate’s events and feeding them sequentially into the appropriate overrides of the Apply method will produce precisely the state representation modeled in the table in Table 7-1.
遍历聚合的事件,并将它们按顺序传入 Apply 方法的适当重写中,将精确地产生表7-1中建模的状态表示。
Pay attention to the Version field that is incremented after applying each event. Its value represents the total number of modifications made to the business entity. Moreover, suppose we apply a subset of events. In that case, we can “travel through time”: we can project the entity’s state at any point of its lifecycle by applying only the relevant events. For example, if we need the entity’s state in version 5, we can apply only the first five events.
请注意,在应用每个事件后,Version 字段的值都会递增。该值表示对业务实体进行的修改总数。此外,假设我们应用一组事件的一个子集。在这种情况下,我们可以“穿越时空”:我们只需要应用相关的事件,就可以推算出实体在其生命周期中任何时间点的状态。例如,如果我们需要版本 5 的实体状态,我们只需要应用前五个事件。
Finally, we are not limited to projecting only a single state representation of the events! Consider the following scenarios.
最后,我们并不局限于只投影事件的单个状态表示。请思考以下场景。
Search
搜索
You have to implement a search. However, since a lead’s contact information can be updated—first name, last name, and phone number—sales agents may not be aware of the changes applied by other agents and may want to locate leads using their contact information, including historical values. We can easily project the historical information:
你需要实现一个搜索功能。但是,由于潜在客户的联系信息(包括名字、姓氏和电话号码)可能会被更新,销售客服可能不知道其他客服所做的更改,并可能希望使用联系信息(包括历史信息)来查找潜在客户。我们可以很容易地投影出历史信息:
1 public class LeadSearchModelProjection 2 { 3 public long LeadId { get; private set; } 4 public HashSet<string> FirstNames { get; private set; } 5 public HashSet<string> LastNames { get; private set; } 6 public HashSet<PhoneNumber> PhoneNumbers { get; private set; } 7 public int Version { get; private set; } 8 public void Apply(LeadInitialized @event) 9 { 10 LeadId = @event.LeadId; 11 FirstNames = new HashSet<string>(); 12 LastNames = new HashSet<string>(); 13 PhoneNumbers = new HashSet<PhoneNumber>(); 14 FirstNames.Add(@event.FirstName); 15 LastNames.Add(@event.LastName); 16 PhoneNumbers.Add(@event.PhoneNumber); 17 Version = 0; 18 } 19 public void Apply(ContactDetailsChanged @event) 20 { 21 FirstNames.Add(@event.FirstName); 22 LastNames.Add(@event.LastName); 23 PhoneNumbers.Add(@event.PhoneNumber); 24 Version += 1; 25 } 26 public void Apply(Contacted @event) 27 { 28 Version += 1; 29 } 30 public void Apply(FollowupSet @event) 31 { 32 Version += 1; 33 } 34 public void Apply(OrderSubmitted @event) 35 { 36 Version += 1; 37 } 38 public void Apply(PaymentConfirmed @event) 39 { 40 Version += 1; 41 } 42 }
The projection logic uses the LeadInitialized and ContactDetailsChanged events to populate the respective sets of the lead’s personal details. Other events are ignored since they do not affect the specific model’s state.
投影逻辑使用 LeadInitialized 和 ContactDetailsChanged 事件来填充潜在客户个人信息的相应集合。其他事件被忽略,因为它们不会影响特定模型的状态。
Applying this projection logic to Casey Davis’s events from the earlier example will result in the following state:
将这种投影逻辑应用于前面示例中 Casey Davis 的事件将产生以下状态:
LeadId: 12 FirstNames: ['Casey'] LastNames: ['David', 'Davis'] PhoneNumbers: ['555-2951', '555-8101'] Version: 6
Analysis
分析
Your business intelligence department asks you to provide a more analysis-friendly representation of the leads data. For their current research, they want to get the number of follow-up calls scheduled for different leads. Later they will filter the converted and closed leads data and use the model to optimize the sales process. Let’s project the data they are asking for:
您的商业智能部门要求您提供一个更便于分析的潜在客户数据表示形式。为了他们当前的研究,他们希望获取为不同潜在客户安排的跟进电话的数量。之后,他们将筛选已转化和已关闭的潜在客户数据,并使用该模型来优化销售流程。让我们投影出他们所需的数据:
1 public class AnalysisModelProjection 2 { 3 public long LeadId { get; private set; } 4 public int Followups { get; private set; } 5 public LeadStatus Status { get; private set; } 6 public int Version { get; private set; } 7 public void Apply(LeadInitialized @event) 8 { 9 LeadId = @event.LeadId; 10 Followups = 0; 11 Status = LeadStatus.NEW_LEAD; 12 Version = 0; 13 } 14 public void Apply(Contacted @event) 15 { 16 Version += 1; 17 } 18 public void Apply(FollowupSet @event) 19 { 20 Status = LeadStatus.FOLLOWUP_SET; 21 Followups += 1; 22 Version += 1; 23 } 24 public void Apply(ContactDetailsChanged @event) 25 { 26 Version += 1; 27 } 28 public void Apply(OrderSubmitted @event) 29 { 30 Status = LeadStatus.PENDING_PAYMENT; 31 Version += 1; 32 } 33 public void Apply(PaymentConfirmed @event) 34 { 35 Status = LeadStatus.CONVERTED; 36 Version += 1; 37 } 38 }
The preceding logic maintains a counter of the number of times follow-up events appeared in the lead’s events. If we were to apply this projection to the example of the aggregate’s events, it would generate the following state:
前面的逻辑维护了一个计数器,用于记录跟进事件在潜在客户事件中出现的次数。如果我们将这种投影应用于聚合的事件示例中,它将生成以下状态:
LeadId: 12 Followups: 1 Status: Converted Version: 6
The logic implemented in the preceding examples projects the search-optimized and analysis-optimized models in-memory. However, to actually implement the required functionality, we have to persist the projected models in a database. In Chapter 8, you will learn about a pattern that allows us to do that: command-query responsibility segregation (CQRS).
前面示例中实现的逻辑在内存中投影了搜索优化和分析优化的模型。但是,为了实际实现所需的功能,我们必须在数据库中持久化投影模型。在第8章中,您将了解一种允许我们这样做的模式:命令查询责任分离(CQRS)。
Source of Truth
真相来源
For the event sourcing pattern to work, all changes to an object’s state should be represented and persisted as events. These events become the system’s source of truth (hence the name of the pattern). This process is shown in Figure 7-1.
要使事件源模式起作用,对象状态的所有更改都应表示为事件并持久化。这些事件成为系统的真相来源(因此得名该模式)。这个过程如图7-1所示。
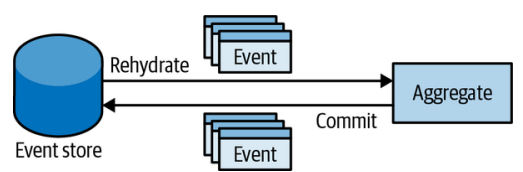
Figure 7-1. Event-sourced aggregate
图7-1. 事件源聚合
The database that stores the system’s events is the only strongly consistent storage: the system’s source of truth. The accepted name for the database that is used for persisting events is event store.
存储系统事件的数据库是唯一一个强一致性的存储:系统的真相来源。用于持久化事件的数据库的公认名称是事件存储(event store)。
Event Store
事件存储
The event store should not allow modifying or deleting the events since it’s append-only storage. To support implementation of the event sourcing pattern, at a minimum the event store has to support the following functionality: fetch all events belonging to a specific business entity and append the events. For example:
事件存储不应该允许修改或删除事件,因为它是只追加的存储。为了支持事件源模式的实现,事件存储至少必须支持以下功能:获取属于特定业务实体的所有事件并追加事件。例如:
1 interface IEventStore 2 { 3 IEnumerable<Event> Fetch(Guid instanceId); 4 void Append(Guid instanceId, Event[] newEvents, int expectedVersion); 5 }
The expectedVersion argument in the Append method is needed to implement optimistic concurrency management: when you append new events, you also specify the version of the entity on which you are basing your decisions. If it’s stale, that is, new events were added after the expected version, the event store should raise a concurrency exception.
Append 方法中的 expectedVersion 参数是为了实现乐观并发管理而必需的:当你追加新事件时,你还指定了你做出决策所依据的实体的版本。如果该版本已过时(即,在预期版本之后添加了新事件),事件存储应该引发一个并发异常。
In most systems, additional endpoints are needed for implementing the CQRS pattern, as we will discuss in the next chapter.
在大多数系统中,为了实现 CQRS 模式,需要额外的端点,我们将在下一章中讨论这一点。
NOTE
备注
In essence, the event sourcing pattern is nothing new. The financial industry uses events to represent changes in a ledger. A ledger is an append-only log that documents transactions. A current state (e.g., account balance) can always be deduced by “projecting” the ledger’s records.
从本质上讲,事件源模式并不是什么新鲜事物。金融业使用事件来表示账本中的变化。账本是一个只追加的日志,用于记录交易。当前状态(例如,账户余额)总是可以通过“投影”账本中的记录来推断出来。
Event-Sourced Domain Model
事件源领域模型
The original domain model maintains a state representation of its aggregates and emits select domain events. The event-sourced domain model uses domain events exclusively for modeling the aggregates’ lifecycles. All changes to an aggregate’s state have to be expressed as domain events.
原始领域模型维护其聚合的状态表示,并发出选定的领域事件。事件源领域模型只通过使用领域事件来建模聚合的生命周期(只通过使用领域事件,不通过其它途径或事物)。对聚合状态的所有更改都必须表示为领域事件。
Each operation on an event-sourced aggregate follows this script:
对事件源聚合的每个操作都遵循以下脚本:
- Load the aggregate’s domain events. 加载聚合的领域事件。
- Reconstitute a state representation—project the events into a state representation that can be used to make business decisions. 重新构建状态表示——将事件投影为可用于做出业务决策的状态表示。
- Execute the aggregate’s command to execute the business logic, and consequently, produce new domain events. 执行聚合的命令以执行业务逻辑,并因此产生新的领域事件。
- Commit the new domain events to the event store. 将新的领域事件提交到事件存储中。
Going back to the example of the Ticket aggregate from Chapter 6, let’s see how it would be implemented as an event-sourced aggregate.
回到第6章中的 Ticket 聚合示例,让我们看看如何将其实现为事件源聚合。
The application service follows the script described earlier: it loads the relevant ticket’s events, rehydrates the aggregate instance, calls the relevant command, and persists changes back to the database:
应用服务遵循前面描述的脚本:它加载相关工单的事件,重新激活聚合实例,调用相关命令,并将更改持久化回数据库:
01 public class TicketAPI 02 { 03 private ITicketsRepository _ticketsRepository; 04 ... 05 06 public void RequestEscalation(TicketId id, EscalationReason reason) 07 { 08 var events = _ticketsRepository.LoadEvents(id); 09 var ticket = new Ticket(events); 10 var originalVersion = ticket.Version; 11 var cmd = new RequestEscalation(reason); 12 ticket.Execute(cmd); 13 _ticketsRepository.CommitChanges(ticket, originalVersion); 14 } 15 16 ... 17 }
The Ticket aggregate’s rehydration logic in the constructor (lines 27 through 31) instantiates an instance of the state projector class, TicketState, and sequentially calls its AppendEvent method for each of the ticket’s events:
在Ticket构造函数中的 Ticket 聚合的重新激活逻辑(第 27 行到第 31 行)实例化了一个状态投影器类 TicketState 的实例,并依次为每个工单事件调用Ticket的 AppendEvent 方法:
18 public class Ticket 19 { 20 ... 21 private List<DomainEvent> _domainEvents = new List<DomainEvent>(); 22 private TicketState _state; 23 ... 24 25 public Ticket(IEnumerable<IDomainEvents> events) 26 { 27 _state = new TicketState(); 28 foreach (var e in events) 29 { 30 AppendEvent(e); 31 } 32 }
The AppendEvent passes the incoming events to the TicketState projection logic, thus generating the in-memory representation of the ticket’s current state:
AppendEvent 方法将传入的事件传递给 TicketState 投影逻辑,从而生成工单当前状态的内存表示:
33 private void AppendEvent(IDomainEvent @event) 34 { 35 _domainEvents.Append(@event); 36 // Dynamically call the correct overload of the "Apply" method. 37 ((dynamic)state).Apply((dynamic)@event); 38 }
Contrary to the implementation we saw in the previous chapter, the event-sourced aggregate’s RequestEscalation method doesn’t explicitly set the IsEscalated flag to true. Instead, it instantiates the appropriate event and passes it to the AppendEvent method (lines 43 and 44):
与我们在前一章中看到的实现相反,基于事件源的聚合的 RequestEscalation 方法没有显式地将 IsEscalated 标志设置为 true。相反,它实例化恰当的事件并将其传递给 AppendEvent 方法(第43和44行):
39 public void Execute(RequestEscalation cmd) 40 { 41 if (!_state.IsEscalated && _state.RemainingTimePercentage <= 0) 42 { 43 var escalatedEvent = new TicketEscalated(_id, cmd.Reason); 44 AppendEvent(escalatedEvent); 45 } 46 } 47 48 ... 49 }
All events added to the aggregate’s events collection are passed to the state projection logic in the TicketState class, where the relevant fields’ values are mutated according to the events’ data:
添加到聚合的事件集合中的所有事件都传递给 TicketState 类中的状态投影逻辑,其中相关字段的值根据事件的数据进行更改:
50 public class TicketState 51 { 52 public TicketId Id { get; private set; } 53 public int Version { get; private set; } 54 public bool IsEscalated { get; private set; } 55 ... 56 public void Apply(TicketInitialized @event) 57 { 58 Id = @event.Id; 59 Version = 0; 60 IsEscalated = false; 61 .... 62 } 63 64 public void Apply(TicketEscalated @event) 65 { 66 IsEscalated = true; 67 Version += 1; 68 } 69 70 ... 71 }
Now let’s look at some of the advantages of leveraging event sourcing when implementing complex business logic.
现在让我们看看在实现复杂业务逻辑时利用事件源的一些优势。
WHY “EVENT-SOURCED DOMAIN MODEL”? 为什么选择“事件源领域模型”?
I feel obliged to explain why I use the term event-sourced domain model rather than just event sourcing. Using events to represent state transitions—the event sourcing pattern—is possible with or without the domain model’s building blocks. Therefore, I prefer the longer term to explicitly state that we are using event sourcing to represent changes in the lifecycles of the domain model’s aggregates.
我觉得有必要解释一下为什么我使用“事件源领域模型”这个术语而不是仅仅使用“事件源”。使用事件来表示状态转换——即事件源模式——在有或没有领域模型构建块的情况下都可以实现。因此,我更喜欢使用更长的术语来明确说明我们正在使用事件源来表示领域模型聚合生命周期中的变化。
Advantages
优势
Compared to the more traditional model, in which the aggregates’ current states are persisted in a database, the event-sourced domain model requires more effort to model the aggregates. However, this approach brings significant advantages that make the pattern worth considering in many scenarios:
与传统的模型(聚合的当前状态保存在数据库中)相比,事件源领域模型需要更多的工作来对聚合进行建模。然而,这种方法带来了显著的优势,使得该模式在许多场景中值得考虑:
Time traveling 时间旅行
Just as the domain events can be used to reconstitute an aggregate’s current state, they can also be used to restore all past states of the aggregate. In other words, you can always reconstitute all the past states of an aggregate.
正如领域事件可以用来重新构建聚合的当前状态一样,它们也可以用来恢复聚合的所有过去状态。换句话说,你总是可以重新构建聚合的所有过去状态。
This is often done when analyzing the system’s behavior, inspecting the system’s decisions, and optimizing the business logic.
这通常在分析系统行为、检查系统决策和优化业务逻辑时进行。
Another common use case for reconstituting past states is retroactive debugging: you can revert the aggregate to the exact state it was in when a bug was observed.
重新构建过去状态的另一个常见用例是回溯调试:你可以将聚合回滚到发现bug时的确切状态。
Deep insight 深度见解
In Part I of this book, we saw that optimizing core subdomains is strategically important for the business. Event sourcing provides deep insight into the system’s state and behavior. As you learned earlier in this chapter, event sourcing provides the flexible model that allows for transforming the events into different state representations—you can always add new projections that will leverage the existing events’ data to provide additional insights.
在本书的第一部分中,我们看到优化核心子域对于业务具有重要的战略意义。事件源提供了对系统状态和行为的深入了解。正如您在本章前面所学到的,事件源提供了灵活的模型,允许将事件转换为不同的状态表示——你总是可以添加新的投影,这些投影将利用现有事件的数据来提供额外的见解。
Audit log 审计日志
The persisted domain events represent a strongly consistent audit log of everything that has happened to the aggregates’ states. Laws oblige some business domains to implement such audit logs, and event sourcing provides this out of the box.
持久化的领域事件代表了聚合状态所发生一切事件的强一致性审计日志。法律规定某些业务领域必须实现这样的审计日志,而事件源则直接提供了这一功能。
This model is especially convenient for systems managing money or monetary transactions. It allows us to easily trace the system’s decisions and the flow of funds between accounts.
这种模型特别适用于管理货币或货币交易的系统。它使我们能够轻松地追踪系统的决策以及资金在账户之间的流动。
Advanced optimistic concurrency management 高级乐观并发管理
The classic optimistic concurrency model raises an exception when the read data becomes stale—overwritten by another process—while it is being written.
传统的乐观并发模型在写入数据时,如果读取的数据被另一个进程覆盖(数据过时,如读取时的版本号与当前版本号不一致),将抛出异常。
When using event sourcing, we can gain deeper insight into exactly what has happened between reading the existing events and writing the new ones. You can query the exact events that were concurrently appended to the event store and make a business domain–driven decision as to whether the new events collide with the attempted operation or the additional events are irrelevant and it’s safe to proceed.
在使用事件源时,我们可以更深入地了解在读取现有事件和写入新事件之间究竟发生了什么。你可以查询正好被并发追加到事件存储中的事件,并基于业务领域进行决策,以确定新事件是否与尝试的操作冲突,或者追加的事件是无关紧要的,并可以安全地继续进行。
Disadvantages
劣势
So far it may seem that the event-sourced domain model is the ultimate pattern for implementing business logic and thus should be used as often as possible. Of course, that would contradict the principle of letting the business domain’s needs drive the design decisions. So, let’s discuss some of the challenges presented by the pattern:
到目前为止,事件源领域模型似乎是实现业务逻辑的终极模式,因此应该尽可能多地使用它。当然,这违背了让业务领域需求驱动设计决策的原则。因此,让我们讨论一下该模式带来的一些挑战:
Learning curve 学习曲线
The obvious disadvantage of the pattern is its sharp difference from the traditional techniques of managing data. Successful implementation of the pattern demands training of the team and time to get used to the new way of thinking. Unless the team already has experience implementing event-sourced systems, the learning curve has to be taken into account.
该模式的明显缺点是它与传统的数据管理技术存在显著差异。成功实现该模式需要对团队进行培训,并花时间适应新的思维方式。除非团队已经具备实现事件源系统的经验,否则必须考虑到学习曲线的问题。
Evolving the model 改进模型
Evolving an event-sourced model can be challenging. The strict definition of event sourcing says that events are immutable. But what if you need to adjust the event’s schema? The process is not as simple as changing a table’s schema. In fact, a whole book was written on this subject alone: Versioning in an Event Sourced System by Greg Young.
演进一个事件源模型可能会很有挑战性。事件源的严格定义指出事件是不可变的。但如果你需要调整事件的架构(结构组成)怎么办?这个过程并不像更改表的架构(结构组成)那么简单。事实上,格雷格·扬(Greg Young)就这一主题写了一整本书:《事件源系统中的版本控制》(Versioning in an Event Sourced System)。
Architectural complexity 架构复杂性
Implementation of event sources introduces numerous architectural “moving parts,” making the overall design more complicated. This topic will be covered in more detail in the next chapter, when we discuss the CQRS architecture.
事件源的实现引入了许多架构上的“移动部件”,使得整体设计更加复杂。这个话题将在下一章讨论 CQRS 体系结构时进行更详细的介绍。
All of these challenges are even more acute if the task at hand doesn’t justify the use of the pattern and instead can be addressed by a simpler design. In Chapter 10, you will learn simple rules of thumb that can help you decide which business logic implementation pattern to use.
如果手头的任务并不需要使用这种模式,而是可以通过更简单的设计来解决,那么所有这些挑战就会更加突出。在第10章中,您将学习一些简单的经验法则,这些法则可以帮助您决定使用哪种业务逻辑实现模式。
Frequently Asked Questions
常见问题及解答
When engineers are introduced to the event sourcing pattern, they often ask several common questions, so I find it obligatory to address them in this chapter.
当工程师接触到事件源模式时,他们经常会问一些常见问题,因此我认为有必要在本章中回答这些问题。
Performance
性能
Reconstituting an aggregate’s state from events will negatively affect the system’s performance. It will degrade as events are added. How can this even work?
从事件中重新构建聚合的状态会对系统性能产生负面影响。随着事件的增加,性能会下降。这怎么可能有效呢?
Projecting events into a state representation indeed requires compute power, and that need will grow as more events are added to an aggregate’s list.
将事件投影到状态表示确实需要计算能力,并且随着聚合事件列表中事件的增加,这种需求(计算能力)也会增长。
It’s important to benchmark a projection’s impact on performance: the effect of working with hundreds or thousands of events. The results should be compared with the expected lifespan of an aggregate—the number of events expected to be recorded during an average lifespan.
评估投影对性能的影响是很重要的:需要测试处理成百上千个事件的效果。应该将结果与聚合的预期寿命(即在平均寿命期间预期记录的事件数量)进行比较。
In most systems, the performance hit will be noticeable only after 10,000+ events per aggregate. That said, in the vast majority of systems, an aggregate’s average lifespan won’t go over 100 events.
在大多数系统中,只有当每个聚合的事件数量超过10,000个时,性能下降才会变得明显。话说回来,在绝大多数系统中,聚合的平均寿命不会超过100个事件。
In the rare cases when projecting states does become a performance issue, another pattern can be implemented: snapshot. This pattern, shown in Figure 7-2, implements the following steps:
在极少数情况下,当投影状态成为性能问题时,可以实施另一种模式:快照。如图7-2所示,该模式实现了以下步骤:
- A process continuously iterates new events in the event store, generates corresponding projections, and stores them in a cache. 一个进程不断地遍历事件存储中的新事件,生成相应的投影,并将它们存储在缓存中。
- An in-memory projection is needed to execute an action on the aggregate. In this case: 要在聚合上执行操作,需要一个内存中的投影。在这种情况下:
- The process fetches the current state projection from the cache. 进程从缓存中获取当前状态的投影。
- The process fetches the events that came after the snapshot version from the event store. 进程从事件存储中获取快照版本之后的事件。
- The additional events are applied in-memory to the snapshot. 将追加的事件在内存中应用到快照上。
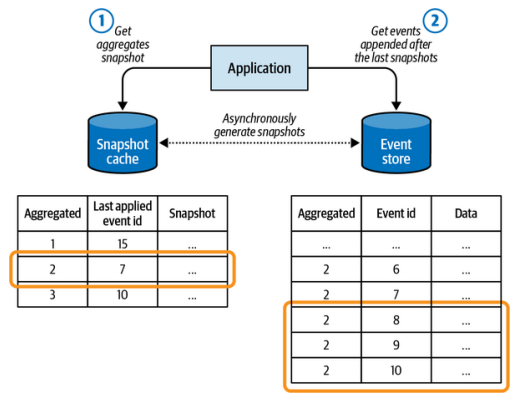
Figure 7-2. Snapshotting an aggregate’s events
图7-2。聚合的事件快照
It’s worth reiterating that the snapshot pattern is an optimization that has to be justified. If the aggregates in your system won’t persist 10,000+ events, implementing the snapshot pattern is just an accidental complexity. But before you go ahead and implement the snapshot pattern, I recommend that you take a step back and double-check the aggregate’s boundaries.
值得重申的是,快照模式是一种需要合理论证的优化。如果系统中的聚合不会持久化超过10,000个事件,那么实施快照模式就只是一种不必要的复杂性。但在你着手实施快照模式之前,我建议你先退一步,再次检查聚合的边界。
This model generates enormous amounts of data. Can it scale?
这个模型产生了大量的数据,它可以扩展吗?
The event-sourced model is easy to scale. Since all aggregate-related operations are done in the context of a single aggregate, the event store can be sharded by aggregate IDs: all events belonging to an instance of an aggregate should reside in a single shard (see Figure 7-3).
事件源模型很容易扩展。由于所有与聚合相关的操作都是在单个聚合的上下文中完成的,因此可以按聚合ID对事件存储进行分片:属于聚合实例的所有事件都应该驻留在单个分片中(见图7-3)。
Deleting Data
删除数据
The event store is an append-only database, but what if I do need to delete data physically; for example, to comply with GDPR?
事件存储是一个仅追加的数据库,但如果我确实需要物理上删除数据怎么办?例如,为了遵守GDPR(欧盟通用数据保护条例),该怎么办呢?
This need can be addressed with the forgettable payload pattern: all sensitive information is included in the events in encrypted form. The encryption key is stored in an external key–value store: the key storage, where the key is a specific aggregate’s ID and the value is the encryption key. When the sensitive data has to be deleted, the encryption key is deleted from the key storage. As a result, the sensitive information contained in the events is no longer accessible.
这个问题可以通过可遗忘有效载荷模式来解决:所有敏感信息都以加密的形式包含在事件中。加密密钥存储在一个外部键值存储中:密钥存储,其中键(key)是特定聚合的ID,值(value)是加密密钥。当需要删除敏感数据时,只需从密钥存储中删除加密密钥。结果,事件中包含的敏感信息将无法再被访问。
Why Can’t I Just…?
为什么我不能只是...?
Why can’t I just write logs to a text file and use it as an audit log?
为什么我不能只是将日志写入文本文件并将其用作审计日志?
Writing data both to an operational database and to a logfile is an error-prone operation. In its essence, it’s a transaction against two storage mechanisms: the database and the file. If the first one fails, the second one has to be rolled back. For example, if a database transaction fails, no one cares to delete the prior log messages. Hence, such logs are not consistent, but rather, eventually inconsistent.
将数据同时写入操作型数据库(数据库分为操作型数据库和分析型数据库,操作型数据库就是常用的数据库,用于联机事务处理(即日常数据维护),而分析型数据库主要用于联机分析处理,即用来存储并追踪历史性和时间性的数据,从而根据这些数据做出判断与预测)和日志文件是一个容易出错的操作。从本质上讲,它是对两个存储机制(数据库和文件)进行的事务操作。如果第一个操作失败,第二个操作就必须回滚。例如,如果数据库事务失败,没有人会关心去删除先前的日志消息。因此,这样的日志不是一致的,而是最终不一致的。
Why can’t I keep working with a state-based model, but in the same database transaction, append logs to a logs table?
为什么我不能在同一个数据库事务中,继续使用基于状态的模型,并将日志追加到日志表中?
From an infrastructural perspective, this approach does provide consistent synchronization between the state and the log records. However, it is still error prone. What if the engineer who will be working on the codebase in the future forgets to append an appropriate log record?
从基础设施的角度来看,这种方法确实提供了状态和日志记录之间的一致同步。然而,它仍然容易出错。如果将来在代码库上工作的工程师忘记追加适当的日志记录怎么办?
Furthermore, when the state-based representation is used as the source of truth, the additional log table’s schema usually degrades into chaos quickly. There is no way to enforce that all required information is written and that it is written in the correct format.
此外,当使用基于状态的表示作为真相来源时,额外日志表的模式通常会迅速陷入混乱。没有办法强制要求所有必需的信息都以正确的格式写入。
Why can’t I just keep working with a state-based model but add a database trigger that will take a snapshot of the record and copy it into a dedicated “history” table?
为什么我不能继续使用基于状态的模型,但添加一个数据库触发器,该触发器将捕获记录的快照并将其复制到专用的“history”表中?
This approach overcomes the previous one’s drawback: no explicit manual calls are needed to append records to the log table. That said, the resultant history only includes the dry facts: what fields were changed. It misses the business contexts: why the fields were changed. The lack of “why” drastically limits the ability to project additional models.
这种方法克服了前一种方法的缺点:不需要显式地手动调用以将日志追加到日志表中。然而,生成的历史记录仅包含枯燥的事实:哪些字段发生了变化。它忽略了业务上下文:为什么这些字段会被更改。缺乏“为什么”会极大地限制投影其他模型的能力。
Conclusion
总结
This chapter explained the event sourcing pattern and its application for modeling the dimension of time in the domain model’s aggregates.
本章解释了事件源模式及其在领域模型的聚合中建模时间维度的应用。
In an event-sourced domain model, all changes to an aggregate’s state are expressed as a series of domain events. That’s in contrast to the more traditional approaches in which a state change just updates a record in the databases. The resultant domain events can be used to project the aggregate’s current state. Moreover, the event-based model gives us the flexibility to project the events into multiple representation models, each optimized for a specific task.
在基于事件源的领域模型中,对聚合状态的所有更改都表示为一系列领域事件。这与更传统的方法形成对比,传统方法中状态更改只是更新数据库中的记录。组合领域事件可以用于投影聚合的当前状态。此外,基于事件的模型为我们提供了将事件投影到多个表示模型的灵活性,每个模型都针对特定任务进行了优化。
This pattern fits cases in which it’s crucial to have deep insight into the system’s data, whether for analysis and optimization or because an audit log is required by law.
这种模式适用于需要深入了解系统数据的情况,无论是为了分析和优化,还是因为法律要求审计日志。
This chapter completes our exploration of the different ways to model and implement business logic. In the next chapter, we will shift our attention to patterns belonging to a higher scope: architectural patterns.
本章完成了我们对建模和实现业务逻辑的不同方式的探索。在下一章中,我们将把注意力转移到属于更高层次范围的模式上:架构模式。
Exercises
练习
1. Which of the following statements is correct regarding the relationship between domain events and value objects? 关于领域事件和值对象之间的关系,下列哪个陈述是正确的?
a. Domain events use value objects to describe what has happened in the business domain. 领域事件使用值对象来描述业务领域中发生的事情。
b. When implementing an event-sourced domain model, value objects should be refactored into event-sourced aggregates. 在实现基于事件源的领域模型时,值对象应该被重构为基于事件源的聚合。
c. Value objects are relevant for the domain model pattern, and are replaced by domain events in the event-sourced domain model. 值对象与领域模型模式相关,但在基于事件源的领域模型中,它们被领域事件所替代。
d. All of the statements are incorrect. 所有的陈述都是不正确的。
答案:a。
2. Which of the following statements is correct regarding the options of projecting state from a series of events? 关于从一系列事件中投影状态的选项,下列哪个陈述是正确的?
a. A single state representation can be projected from an aggregate’s events. 可以从聚合的事件中投影出单一的状态表示。
b. Multiple state representations can be projected, but the domain events have to be modeled in a way that supports multiple projections. 可以投影出多个状态表示,但领域事件必须以支持多个投影的方式进行建模。
c. Multiple state representations can be projected and you can always add additional projections in the future. 可以投影出多个状态表示,并且未来总是可以添加额外的(其它)投影。
d. All of the statements are incorrect. 所有的陈述都是不正确的。
答案:c。
3. Which of the following statements is correct regarding the difference between state-based and event-sourced aggregates? 关于基于状态的聚合和基于事件源的聚合之间的区别,下列哪个陈述是正确的?
a. An event-sourced aggregate can produce domain events, while a state-based aggregate cannot produce domain events. 基于事件源的聚合可以产生领域事件,而基于状态的聚合不能产生领域事件。(这个陈述是不正确的,因为两者都可以产生事件,但处理方式和用途不同)
b. Both variants of the aggregate pattern produce domain events, but only event-sourced aggregates use domain events as the source of truth. 聚合模式的两种变体都会产生领域事件,但只有基于事件源的聚合将领域事件作为真相来源。
c. Event-sourced aggregates ensure that domain events are generated for every state transition. 基于事件源的聚合确保每次状态转换都会生成领域事件。
d. Both B and C are correct. B 和 C 都是正确的。
答案:d。
4. Going back to the WolfDesk company described in the book’s Preface, which functionality of the system lends itself to be implemented as an event-sourced domain model? 回顾书中前言部分描述的WolfDesk公司,该系统的哪些功能适合作为基于事件源的领域模型来实现?
答案:The ticket lifecycle algorithm is a good candidate to be implemented as an event-sourced domain model. Generating domain events for all state transitions can make it more convenient to project additional state representations optimized for the fraud detection algorithm and the support autopilot functionality. 工单生命周期算法是一个很好的候选者,适合作为基于事件源的领域模型来实现。为所有状态转换生成领域事件可以更方便地投影出针对欺诈检测算法和支持自动支持功能的优化状态表示。
1 Brooks, F. P. Jr. (1974). The Mythical Man-Month: Essays on Software Engineering. Reading, MA: Addison-Wesley. 小布鲁克斯(1974)人月神话: 《软件工程论文集》马萨诸塞州雷丁: 艾迪生-韦斯利。
2 Except for exceptional cases, such as data migration. 除了例外情况,例如数据迁移。
3 General Data Protection Regulation. (n.d.) Retrieved June 14, 2021, from Wikipedia. 《一般数据保护条例》 ,2021年6月14日,维基百科。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号