烂翻译系列之学习领域驱动设计——第六章:处理复杂的业务逻辑
The previous chapter discussed two patterns addressing cases of relatively simple business logic: transaction script and active record. This chapter continues the topic of implementing business logic and introduces a pattern oriented for complicated business logic: the domain model pattern.
前一章讨论了处理相对简单的业务逻辑案例的两种模式: 事务脚本和活动记录。本章继续讨论实现业务逻辑的主题,并介绍了一种针对复杂业务逻辑的模式: 领域模型模式。
History
历史
As with both the transaction script and active record patterns, the domain model pattern was introduced initially in Martin Fowler’s book Patterns of Enterprise Application Architecture. Fowler concluded his discussion of the pattern by saying, “Eric Evans is currently writing a book on building Domain Models.” The referenced book is Evans’s seminal work, Domain-Driven Design: Tackling Complexity in the Heart of Software.
与事务脚本和活动记录模式一样,领域模型模式最初也是由Martin Fowler在他的著作《企业应用架构模式》中提出的。Fowler在结束对该模式的讨论时表示:“Eric Evans目前正在撰写一本关于构建领域模型的书。” 所引用的书籍是Evans的开创性著作《领域驱动设计:软件核心复杂性应对之道》。
In his book, Evans presents a set of patterns aimed at tightly relating the code to the underlying model of the business domain: aggregate, value objects, repositories, and others. These patterns closely follow where Fowler left off in his book and resemble an effective set of tools for implementing the domain model pattern.
在《领域驱动设计:软件核心复杂性应对之道》一书中,Evans 提出了一组模式,旨在将代码与业务领域的底层模型紧密关联起来: 聚合、值对象、仓储等。这些模式严格遵循了Fowler 在其著作中提出的模式,并形成了一套有效的工具集,用于实现领域模型模式。
The patterns that Evans introduced are often referred to as tactical domain-driven design. To eliminate the confusion of thinking that implementing domain-driven design necessarily entails the use of these patterns to implement business logic, I prefer to stick with Fowler’s original terminology. The pattern is “domain model,” and the aggregates and value objects are its building blocks.
翻译:Evans 提出的模式通常被称为战术领域驱动设计。为了避免误解(认为实现领域驱动设计必然需要使用这些模式来实现业务逻辑),我更喜欢坚持使用 Fowler 的原始术语。此模式是“领域模型”,而聚合和值对象是该模式的构建块。
Domain Model
领域模型
The domain model pattern is intended to cope with cases of complex business logic. Here, instead of CRUD interfaces, we deal with complicated state transitions, business rules, and invariants: rules that have to be protected at all times.
领域模型模式旨在处理复杂的业务逻辑情况。在这里,我们处理的不是 CRUD(创建、读取、更新、删除)接口,而是复杂的状态转换、业务规则和不变性(式):这些规则必须始终得到保护。
Let’s assume we are implementing a help desk system. Consider the following excerpt from the requirements that describes the logic controlling the lifecycles of support tickets:
假设我们正在实现一个帮助台系统。请思考以下需求摘录,其中描述了控制支持工单生命周期的逻辑
- Customers open support tickets describing issues they are facing. 客户打开支持工单,描述他们所面临问题。
- Both the customer and the support agent append messages, and all the correspondence is tracked by the support ticket. 客户和客服都会添加加消息,所有通信都由支持工单进行跟踪。
- Each ticket has a priority: low, medium, high, or urgent. 每个工单都有优先级: 低、中、高或紧急。
- An agent should offer a solution within a set time limit (SLA) that is based on the ticket’s priority. 客服应该根据工单的优先级在设定的时间限制(SLA)内提供解决方案。
- If the agent doesn’t reply within the SLA, the customer can escalate the ticket to the agent’s manager. 如果客服没有在限制时间内回复,客户可以将工单升级(递交)到客服经理。
- Escalation reduces the agent’s response time limit by 33%. 升级使客服的响应时间限制减少了33% 。
- If the agent didn’t open an escalated ticket within 50% of the response time limit, it is automatically reassigned to a different agent. 如果客服没有在响应时间限制的50% 内打开升级了的工单,工单将自动重新分配给另一个客服。
- Tickets are automatically closed if the customer doesn’t reply to the agent’s questions within seven days. 如果客户在七天内没有回复客服的问题,工单就会自动关闭。
- Escalated tickets cannot be closed automatically or by the agent, only by the customer or the agent’s manager. 升级后的工单不能自动关闭或由客服关闭,只能由客户或客服经理关闭。
- A customer can reopen a closed ticket only if it was closed in the past seven days. 只有在过去七天内关闭的工单,客户才能重新打开。
These requirements form an entangled net of dependencies among the different rules, all affecting the support ticket’s lifecycle management logic. This is not a CRUD data entry screen, as we discussed in the previous chapter. Attempting to implement this logic using active record objects will make it easy to duplicate the logic and corrupt the system’s state by misimplementing some of the business rules.
这些需求形成了一个复杂的依赖网络,这些不同的规则之间都存在依赖关系,它们共同影响着支持票据的生命周期管理逻辑。这不是我们前一章所讨论的 CRUD 数据入口。尝试使用活动记录对象来实现这一逻辑,会很容易使逻辑重复,并因错误地实现某些业务规则而破坏系统的状态。
Implementation
实现
A domain model is an object model of the domain that incorporates both behavior and data. DDD’s tactical patterns—aggregates, value objects, domain events, and domain services—are the building blocks of such an object model.
领域模型是领域的对象模型,它结合了行为和数据。DDD(领域驱动设计)的战术模式——聚合、值对象、领域事件和领域服务——是这种对象模型的构建块。
All of these patterns share a common theme: they put the business logic first. Let’s see how the domain model addresses different design concerns.
所有这些模式都有一个共同的主题: 它们将业务逻辑放在首位。让我们看看领域模型如何解决不同的设计问题。
Complexity
复杂性
The domain’s business logic is already inherently complex, so the objects used for modeling it should not introduce any additional accidental complexities. The model should be devoid of any infrastructural or technological concerns, such as implementing calls to databases or other external components of the system. This restriction requires the model’s objects to be plain old objects, objects implementing business logic without relying on or directly incorporating any infrastructural components or frameworks.
领域的业务逻辑本身就已经很复杂了,因此用于建模的对象不应该引入任何额外的偶然复杂性。模型应该不包含任何基础设施或技术方面的关注点,比如实现对数据库或系统其他外部组件的调用。这个限制要求模型的对象是纯老式对象(Plain Old Objects),这些对象实现业务逻辑,而不依赖或直接包含任何基础设施组件或框架。
Ubiquitous language
通用语言
The emphasis on business logic instead of technical concerns makes it easier for the domain model’s objects to follow the terminology of the bounded context’s ubiquitous language. In other words, this pattern allows the code to “speak” the ubiquitous language and to follow the domain experts’ mental models.
强调业务逻辑而不是技术关注点,使得领域模型的对象更容易遵循有界上下文(bounded context)的通用语言(ubiquitous language)的术语。换句话说,这种模式允许代码“说”通用语言,并遵循领域专家的思维模型。
Building Blocks
构建块
Let’s look at the central domain model building blocks, or tactical patterns, offered by DDD: value objects, aggregates, and domain services.
让我们来看看DDD提供的核心领域模型构建块或战术模式:值对象、聚合和领域服务。
Value object
值对象
A value object is an object that can be identified by the composition of its values. For example, consider a color object:
值对象是可以通过其值的组合来识别的对象。例如,思考一个Color对象:
1 class Color 2 { 3 int _red; 4 int _green; 5 int _blue; 6 }
The composition of the values of the three fields red, green, and blue defines a color. Changing the value of one of the fields will result in a new color. No two colors can have the same values. Also, two instances of the same color must have the same values. Therefore, no explicit identification field is needed to identify colors.
红色、绿色和蓝色三个字段值的组合定义了一种颜色。更改其中一个字段的值将生成新颜色。任何两种颜色都不可能有相同的值。此外,相同Color的两个实例必须具有相同的值。因此,不需要明确的标识字段来识别颜色。
The ColorId field shown in Figure 6-1 is not only redundant, but actually creates an opening for bugs. You could create two rows with the same values of red, green, and blue, but comparing the values of ColorId would not reflect that this is the same color.
图6-1中显示的ColorId字段不仅多余,实际上还可能导致错误。您可以创建两行具有相同的红色、绿色和蓝色值,但是比较 ColorId 的值并不能反映这是相同的color。
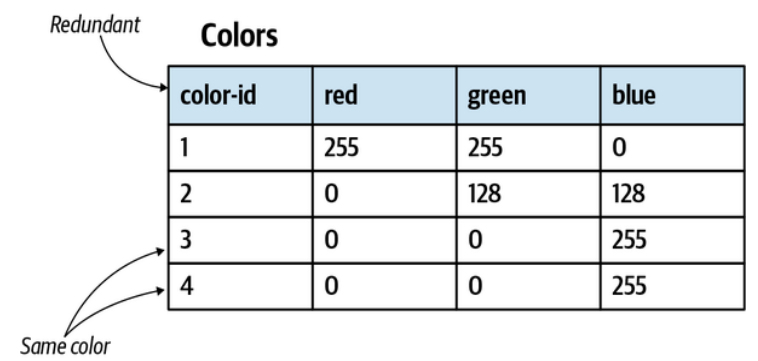
Figure 6-1. Redundant ColorId field, making it possible to have two rows with the same values
图6-1. 冗余的ColorId字段,使得有可能存在两行具有相同值的记录
Ubiquitous language
通用语言
Relying exclusively on the language’s standard library’s primitive data types—such as strings, integers, or dictionaries—to represent concepts of the business domain is known as the primitive obsession code smell. For example, consider the following class:
仅依赖语言的标准库中的基本数据类型(如字符串、整数或字典)来表示业务领域的概念,被称为“原始痴迷”的代码异味。例如,考虑以下类:
1 class Person 2 { 3 private int _id; 4 private string _firstName; 5 private string _lastName; 6 private string _landlinePhone; 7 private string _mobilePhone; 8 private string _email; 9 private int _heightMetric; 10 private string _countryCode; 11 public Person(...) {...} 12 } 13 static void Main(string[] args) 14 { 15 var dave = new Person( 16 id: 30217, 17 firstName: "Dave", 18 lastName: "Ancelovici", 19 landlinePhone: "023745001", 20 mobilePhone: "0873712503", 21 email: "dave@learning-ddd.com", 22 heightMetric: 180, 23 countryCode: "BG"); 24 }
In the preceding implementation of the Person class, most of the values are of type String and they are assigned based on convention. For example, the input to the landlinePhone should be a valid landline phone number, and the countryCode should be a valid, two-letter, uppercased country code. Of course, the system cannot trust the user to always supply correct values, and as a result, the class has to validate all input fields.
在前面的Person类的实现中,大多数值都是 String 类型的,并且它们是根据约定分配的。例如,landlinePhone 的输入应该是一个有效的固定电话号码,而 countryCode 应该是一个有效的、两个大写字母的国家代码。当然,系统不能信任用户总是提供正确的值,因此这个类(Person类)必须验证所有输入字段。
This approach presents multiple design risks. First, the validation logic tends to be duplicated. Second, it’s hard to enforce calling the validation logic before the values are used. It will become even more challenging in the future, when the codebase will be evolved by other engineers.
这种方法存在多个设计风险。首先,验证逻辑往往会重复。其次,很难在值被使用之前强制执行验证逻辑。在未来,当其他工程师对代码库进行扩展时,这一点将变得更加具有挑战性。
Compare the following alternative design of the same object, this time leveraging value objects:
对比以下该对象的另一种设计,这次利用了值对象:
1 class Person { 2 private PersonId _id; 3 private Name _name; 4 private PhoneNumber _landline; 5 private PhoneNumber _mobile; 6 private EmailAddress _email; 7 private Height _height; 8 private CountryCode _country; 9 public Person(...) { ... } 10 } 11 static void Main(string[] args) 12 { 13 var dave = new Person( 14 id: new PersonId(30217), 15 name: new Name("Dave", "Ancelovici"), 16 landline: PhoneNumber.Parse("023745001"), 17 mobile: PhoneNumber.Parse("0873712503"), 18 email: Email.Parse("dave@learning-ddd.com"), 19 height: Height.FromMetric(180), 20 country: CountryCode.Parse("BG")); 21 }
First, notice the increased clarity. Take, for example, the country variable. There is no need to elaborately call it “countryCode” to communicate the intent of it holding a country code and not, for example, a full country name. The value object makes the intent clear, even with shorter variable names.
首先,注意清晰度的提高。以country变量为例。没有必要详细地将其命名为“countryCode”来传达它持有的是国家代码而不是完整的国家名称的意图。值对象使得意图变得清晰,即使变量名更短。
Second, there is no need to validate the values before the assignment, as the validation logic resides in the value objects themselves. However, a value object’s behavior is not limited to mere validation. Value objects shine brightest when they centralize the business logic that manipulates the values. The cohesive logic is implemented in one place and is easy to test.
其次,在赋值之前无需验证值,因为验证逻辑位于值对象本身中。但是,值对象的行为不仅限于验证。当值对象集中了操纵值的业务逻辑时,它们的作用最为显著。这种内聚的逻辑在一个地方实现,并且易于测试。
Most importantly, value objects express the business domain’s concepts: they make the code speak the ubiquitous language.
最重要的是,值对象表达了业务领域的概念:它们使代码能够“说”通用语言。
Let’s see how representing the concepts of height, phone numbers, and colors as value objects makes the resultant type system rich and intuitive to use.
让我们看看如何将身高、电话号码和颜色的概念表示为值对象,从而使得最终的类型系统更加丰富和直观。
Compared to an integer-based value, the Height value object both makes the intent clear and decouples the measurement from a specific measurement unit. For example, the Height value object can be initialized using both metric and imperial units, making it easy to convert from one unit to another, generating string representation, and comparing values of different units:
与基于整数的值相比,Height值对象既明确了意图,又将测量值与特定的测量单位解耦。例如,Height值对象可以使用公制和英制单位进行初始化,从而轻松地从一个单位转换到另一个单位,生成字符串表示形式,并比较不同单位的值:
1 var heightMetric = Height.Metric(180); 2 var heightImperial = Height.Imperial(5, 3); 3 var string1 = heightMetric.ToString(); // "180cm" 4 var string2 = heightImperial.ToString(); // "5 feet 3 5 inches" 6 var string3 = heightMetric.ToImperial().ToString(); // "5 feet 11 7 inches" 8 var firstIsHigher = heightMetric > heightImperial; // true
The PhoneNumber value object can encapsulate the logic of parsing a string value, validating it, and extracting different attributes of the phone number; for example, the country it belongs to and the phone number’s type —landline or mobile:
PhoneNumber 值对象可以封装解析string值、验证字符串值和提取电话号码的不同特性的逻辑; 例如,它所属的国家和电话号码的类型——固定电话或移动电话:
1 var phone = PhoneNumber.Parse("+359877123503"); 2 var country = phone.Country; // "BG" 3 var phoneType = phone.PhoneType; // "MOBILE" 4 var isValid = PhoneNumber.IsValid("+972120266680"); // false
The following example demonstrates the power of a value object when it encapsulates all of the business logic that manipulates the data and produces new instances of the value object:
下面的示例演示了值对象在封装操纵数据和生成值对象的新实例的所有业务逻辑时的强大功能:
1 var red = Color.FromRGB(255, 0, 0); 2 var green = Color.Green; 3 var yellow = red.MixWith(green); 4 var yellowString = yellow.ToString(); // "#FFFF00"
As you can see in the preceding examples, value objects eliminate the need for conventions—for example, the need to keep in mind that this string is an email and the other string is a phone number—and instead makes using the object model less error prone and more intuitive.
正如你在前面的示例中所看到的,值对象消除了对约定的需求——例如,需要记住这个字符串是电子邮件,而另一个字符串是电话号码——相反,它使对象模型的使用更加不易出错且更直观。
Implementation
实现
Since a change to any of the fields of a value object results in a different value, value objects are implemented as immutable objects. A change to one of the value object’s fields conceptually creates a different value—a different instance of a value object. Therefore, when an executed action results in a new value, as in the following case, which uses the MixWith method, it doesn’t modify the original instance but instantiates and returns a new one:
由于值对象的任何字段的更改都会导致不同的值,因此值对象被实现为不可变对象。对值对象字段之一的更改在概念上创建了一个不同的值——即值对象的一个不同实例。因此,当一个执行的操作产生一个新值时,如下例所示,使用MixWith方法时,它不会修改原始实例,而是实例化并返回一个新的实例:
1 public class Color 2 { 3 public readonly byte Red; 4 public readonly byte Green; 5 public readonly byte Blue; 6 public Color(byte r, byte g, byte b) 7 { 8 this.Red = r; 9 this.Green = g; 10 this.Blue = b; 11 } 12 public Color MixWith(Color other) 13 { 14 return new Color( 15 r: (byte) Math.Min(this.Red + other.Red, 255), 16 g: (byte) Math.Min(this.Green + other.Green, 255), 17 b: (byte) Math.Min(this.Blue + other.Blue, 255) 18 ); 19 } 20 ... 21 }
Since the equality of value objects is based on their values rather than on an id field or reference, it’s important to override and properly implement the equality checks. For example, in C#:
由于值对象的相等性是基于它们的值,而不是基于 id 字段或引用,因此重写并正确实现相等性检查非常重要。例如,在 C # 中:
1 public class Color 2 { 3 ... 4 public override bool Equals(object obj) 5 { 6 var other = obj as Color; 7 return other != null && 8 this.Red == other.Red && 9 this.Green == other.Green && 10 this.Blue == other.Blue; 11 } 12 public static bool operator == (Color lhs, Color rhs) 13 { 14 if (Object.ReferenceEquals(lhs, null)) { 15 return Object.ReferenceEquals(rhs, null); 16 } 17 return lhs.Equals(rhs); 18 } 19 public static bool operator != (Color lhs, Color rhs) 20 { 21 return !(lhs == rhs); 22 } 23 public override int GetHashCode() 24 { 25 return ToString().GetHashCode(); 26 } 27 28 ... 29 }
Although using a core library’s Strings to represent domain-specific values contradicts the notion of value objects, in .NET, Java, and other languages the string type is implemented exactly as a value object. Strings are immutable, as all operations result in a new instance. Moreover, the string type encapsulates a rich behavior that creates new instances by manipulating the values of one or more strings: trim, concatenate multiple strings, replace characters, substring, and other methods.
尽管使用核心库的String来表示特定领域的值违背了值对象的概念,但在.NET、Java和其他语言中,String类型正是作为值对象实现的。String是不可变的,因为所有操作都会生成一个新的实例。此外,String类型封装了丰富的行为,这些行为通过操纵一个或多个String的值来创建新实例:修剪、连接多个字符串、替换字符、子字符串和其他方法。
When to use value objects
何时使用值对象
The simple answer is, whenever you can. Not only do value objects make the code more expressive and encapsulate business logic that tends to spread apart, but the pattern makes the code safer. Since value objects are immutable, the value objects’ behavior is free of side effects and is thread safe.
简单的回答是,只要可能就应该使用值对象。值对象不仅使代码更具表达力,封装了容易分散的业务逻辑,而且这种模式使代码更安全。由于值对象是不可变的,因此值对象的行为没有副作用,并且是线程安全的。
From a business domain perspective, a useful rule of thumb is to use value objects for the domain’s elements that describe properties of other objects. This namely applies to properties of entities, which are discussed in the next section. The examples you saw earlier used value objects to describe a person, including their ID, name, phone numbers, email, and so on. Other examples of using value objects include various statuses, passwords, and more business domain–specific concepts that can be identified by their values and thus do not require an explicit identification field. An especially important opportunity to introduce a value object is when modeling money and other monetary values. Relying on primitive types to represent money not only limits your ability to encapsulate all money-related business logic in one place, but also often leads to dangerous bugs, such as rounding errors and other precision-related issues.
从业务领域的角度来看,一个有用的经验法则是使用值对象来描述其他对象的属性。这特别适用于实体的属性,这将在下一节中讨论。你之前看到的示例使用了值对象来描述一个人,包括他们的ID、姓名、电话号码、电子邮件等。使用值对象的其他示例包括各种状态、密码以及更多可以通过其值来识别的业务领域特定概念,因此不需要明确的(显式的)标识字段。引入值对象的一个特别重要的时机是在对货币和其他货币值进行建模时。依赖原始类型来表示货币不仅限制了你在一个地方封装所有与货币相关的业务逻辑的能力,而且经常导致危险的bug,如舍入错误和其他与精度相关的问题。
Entities
实体
An entity is the opposite of a value object. It requires an explicit identification field to distinguish between the different instances of the entity. A trivial example of an entity is a person. Consider the following class:
实体与值对象相反。它需要一个明确的(显式的)标识字段来区分实体的不同实例。下面的Person类是一个简单的实体示例:
1 class Person 2 { 3 public Name Name { get; set; } 4 5 public Person(Name name) 6 { 7 this.Name = name; 8 } 9 }
The class contains only one field: name (a value object). This design, however, is suboptimal because different people can be namesakes and can have exactly the same names. That, of course, doesn’t make them the same person. Hence, an identification field is needed to properly identify people:
该类只包含一个字段: name (值对象)。然而,这种设计并不是最优的,因为不同的人可能同名,可能有完全相同的名字。当然,这并不意味着他们就是同一个人,因此,需要一个识别字段来正确识别人:
1 class Person 2 { 3 public readonly PersonId Id; 4 public Name Name { get; set; } 5 6 public Person(PersonId id, Name name) 7 { 8 this.Id = id; 9 this.Name = name; 10 } 11 }
In the preceding code, we introduced the identification field Id of type PersonId. PersonId is a value object, and it can use any underlying data types that fit the business domain’s needs. For example, the Id can be a GUID, a number, a string, or a domain-specific value such as a Social Security number.
在前面的代码中,我们引入了类型为PersonId的标识字段Id。PersonId是一个值对象,它可以使用任何符合业务领域需求的底层数据类型。例如,Id可以是一个GUID、一个数字、一个字符串或一个特定于领域的值,如社会保险号。
The central requirement for the identification field is that it should be unique for each instance of the entity: for each person, in our case (Figure 6-2). Furthermore, except for very rare exceptions, the value of an entity’s identification field should remain immutable throughout the entity’s lifecycle. This brings us to the second conceptual difference between value objects and entities.
标识字段的核心要求是,它对于实体的每个实例都应该是唯一的:在我们这个例子中,对于每个人(图6-2)都是如此。此外,除了非常罕见的例外情况,实体的标识字段的值应该在整个实体的生命周期中保持不变。这就引出了值对象和实体在概念上的第二个区别。
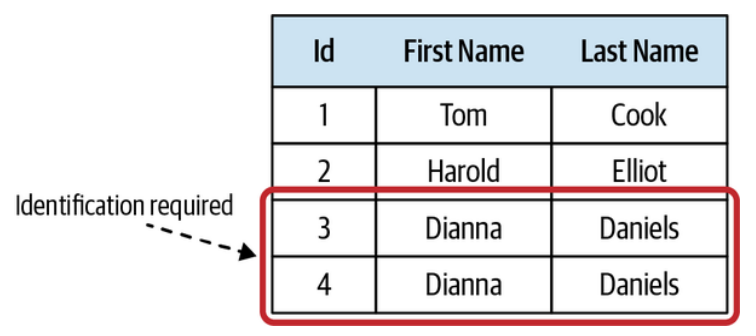
Figure 6-2. Introducing an explicit identification field, allowing differentiating instances of the object even if the values of all other fields are identical
图6-2. 引入一个明确的标识字段,即使所有其他字段的值都相同,也能区分对象的实例。
Contrary to value objects, entities are not immutable and are expected to change. Another difference between entities and value objects is that value objects describe an entity’s properties. Earlier in the chapter, you saw an example of the entity Person and it had two value objects describing each instance: PersonId and Name.
与值对象相反,实体不是不可变的,并且预计会发生变化。实体和值对象之间的另一个区别是,值对象描述实体的属性。在本章的前面部分,你看到了一个Person实体的示例,它有两个值对象来描述每个实例:PersonId和Name。
Entities are an essential building block of any business domain. That said, you may have noticed that earlier in the chapter I didn’t include “entity” in the list of the domain model’s building blocks. That’s not a mistake. The reason “entity” was omitted is because we don’t implement entities independently, but only in the context of the aggregate pattern.
实体是任何业务领域的基本构建块。不过,你可能已经注意到,在本章的前面部分,我并没有在领域模型的构建块列表中包含“实体”。这不是一个错误。之所以省略“实体”,是因为我们不会独立实现实体,而只是在聚合模式的上下文中实现它们。
Aggregates
聚合
An aggregate is an entity: it requires an explicit identification field and its state is expected to change during an instance’s lifecycle. However, it is much more than just an entity. The goal of the pattern is to protect the consistency of its data. Since an aggregate’s data is mutable, there are implications and challenges that the pattern has to address to keep its state consistent at all times.
聚合是一个实体:它需要一个明确的标识字段,并且其实体状态(非标识字段)在其实例的生命周期内会发生变化。然而,聚合不仅仅是一个实体。聚合模式的目标是保护其数据的一致性。由于聚合的数据是可变的,因此该模式必须应对一些影响和挑战,以确保其状态始终一致。
Consistency enforcement
强一致性
Since an aggregate’s state can be mutated, it creates an opening for multiple ways in which its data can become corrupted. To enforce consistency of the data, the aggregate pattern draws a clear boundary between the aggregate and its outer scope: the aggregate is a consistency enforcement boundary. The aggregate’s logic has to validate all incoming modifications and ensure that the changes do not contradict its business rules.
由于聚合的状态可以发生变化,这就为数据可能被破坏的多种方式创造了条件。为了强制数据的一致性,聚合模式在聚合与其外部范围之间划定了明确的边界:聚合是一致性强制边界。聚合的逻辑必须验证所有传入的修改,并确保这些修改不违反其业务规则。
From an implementation perspective, the consistency is enforced by allowing only the aggregate’s business logic to modify its state. All processes or objects external to the aggregate are only allowed to read the aggregate’s state. Its state can only be mutated by executing corresponding methods of the aggregate’s public interface.
从实现的角度来看,一致性是通过仅允许聚合的业务逻辑修改其状态来强制执行的。聚合外部的所有进程或对象只允许读取聚合的状态。聚合的状态只能通过执行聚合公共接口中的相应方法来修改。
The state-modifying methods exposed as an aggregate’s public interface are often referred to as commands, as in “a command to do something.” A command can be implemented in two ways. First, it can be implemented as a plain public method of the aggregate object:
作为聚合公共接口公开的修改状态的方法通常被称为命令,就像“执行某个操作的命令”一样。命令可以通过两种方式实现。首先,命令可以作为聚合对象的普通公共方法来实现:
1 public class Ticket 2 { 3 ... 4 public void AddMessage(UserId from, string body) 5 { 6 var message = new Message(from, body); 7 _messages.Append(message); 8 } 9 ... 10 }
Alternatively, a command can be represented as a parameter object that encapsulates all the input required for executing the command:
另外,命令也可以表示为一个参数对象,该对象封装了执行命令所需的所有输入:
1 public class Ticket 2 { 3 ... 4 public void Execute(AddMessage cmd) 5 { 6 var message = new Message(cmd.from, cmd.body); 7 _messages.Append(message); 8 } 9 ... 10 }
How commands are expressed in an aggregate’s code is a matter of preference. I prefer the more explicit way of defining command structures and passing them polymorphically to the relevant Execute method.
在聚合的代码中如何表达命令是一个偏好问题。我更喜欢更明确地定义命令结构,并将它们多态地传递给相关的Execute方法。
An aggregate’s public interface is responsible for validating the input and enforcing all of the relevant business rules and invariants. This strict boundary also ensures that all business logic related to the aggregate is implemented in one place: the aggregate itself.
聚合的公共接口负责验证输入并强制执行所有相关的业务规则和不变性。这种严格的边界还确保与聚合相关的所有业务逻辑都在一个地方实现:即聚合本身。
This makes the application layer that orchestrates operations on aggregates rather simple: all it has to do is load the aggregate’s current state, execute the required action, persist the modified state, and return the operation’s result to the caller:
这使得编排聚合操作的应用层相对简单:它只需要加载聚合的当前状态,执行所需的操作,持久化修改后的状态,并将操作结果返回给调用者:
01 public ExecutionResult Escalate(TicketId id, EscalationReason reason) 02 { 03 try 04 { 05 var ticket = _ticketRepository.Load(id); 06 var cmd = new Escalate(reason); 07 ticket.Execute(cmd); 08 _ticketRepository.Save(ticket); 09 return ExecutionResult.Success(); 10 } 11 catch (ConcurrencyException ex) 12 { 13 return ExecutionResult.Error(ex); 14 } 15 }
Pay attention to the concurrency check in the preceding code (line 11). It’s vital to protect the consistency of an aggregate’s state. If multiple processes are concurrently updating the same aggregate, we have to prevent the latter transaction from blindly overwriting the changes committed by the first one. In such a case, the second process has to be notified that the state on which it had based its decisions is out of date, and it has to retry the operation.
注意前面代码中的并发检查(第11行)。保护聚合状态的一致性是至关重要的。如果多个进程同时更新同一个聚合,我们必须防止后一个事务盲目地覆盖第一个事务提交的更改。在这种情况下,第二个进程必须被告知它基于的决策状态已经过时,并且第二个进程必须重试操作。
Hence, the database used for storing aggregates has to support concurrency management. In its simplest form, an aggregate should hold a version field that will be incremented after each update:
因此,用于存储聚合的数据库必须支持并发管理。在最简单的形式中,聚合应该包含一个version(版本号)字段,该字段在每次更新后都会递增:
1 class Ticket 2 { 3 TicketId _id; 4 int _version; 5 ... 6 }
When committing a change to the database, we have to ensure that the version that is being overwritten matches the one that was originally read. For example, in SQL:
在将更改提交到数据库时,我们必须确保正在覆盖的version与最初读取的version相匹配。例如,在SQL中:
01 UPDATE tickets 02 SET ticket_status = @new_status, 03 agg_version = agg_version + 1 04 WHERE ticket_id=@id and agg_version=@expected_version;
This SQL statement applies changes made to the aggregate instance’s state (line 2), and increases its version counter (line 3) but only if the current version equals the one that was read prior to applying changes to the aggregate’s state (line 4).
这条SQL语句应用了对聚合实例状态所做的更改(第2行),并增加了其版本计数器(第3行),但前提是只有当当前版本与在对聚合状态应用更改之前读取的版本相同时(第4行)才执行此操作。
Of course, concurrency management can be implemented elsewhere besides a relational database. Furthermore, document databases lend themselves more toward working with aggregates. That said, it’s crucial to ensure that the database used for storing an aggregate’s data supports concurrency management.
当然,除了关系型数据库外,还可以在其他地方实现并发管理。此外,文档数据库更适合使用聚合。尽管如此,确保用于存储聚合数据的数据库支持并发管理是至关重要的。
Transaction boundary
事务边界
Since an aggregate’s state can only be modified by its own business logic, the aggregate also acts as a transactional boundary. All changes to the aggregate’s state should be committed transactionally as one atomic operation. If an aggregate’s state is modified, either all the changes are committed or none of them is.
由于聚合的状态只能由其自身的业务逻辑修改,所以聚合也充当事务边界。对聚合状态的所有更改都应作为一个原子操作以事务方式提交。如果修改了聚合的状态,则要么提交所有更改,要么不提交任何更改。
Furthermore, no system operation can assume a multi-aggregate transaction. A change to an aggregate’s state can only be committed individually, one aggregate per database transaction.
此外,任何系统操作都不能假设存在跨多个聚合的事务。对聚合状态的更改只能单独提交,每个数据库事务对应一个聚合。
The one aggregate instance per transaction forces us to carefully design an aggregate’s boundaries, ensuring that the design addresses the business domain’s invariants and rules. The need to commit changes in multiple aggregates signals a wrong transaction boundary, and hence, wrong aggregate boundaries.
每个事务的一个聚合实例迫使我们仔细设计聚合的边界,确保设计解决了业务域的不变性和规则。提交多个聚合中的更改的需要预示着存在错误的事务边界,因此也就是错误的聚合边界。
翻译:每个事务只能有一个聚合实例这一事实迫使我们仔细设计聚合的边界,确保设计符合业务域的不变性和规则。如果需要提交在多个聚合中的更改,则预示着存在错误的事务边界,从而聚合边界也错误。
This seems to impose a modeling limitation. What if we need to modify multiple objects in the same transaction? Let’s see how the pattern addresses such situations.
这似乎强加了一个建模限制。如果我们需要在同一个事务中修改多个对象,该怎么办?让我们看看这个模式(聚合模式)如何处理这种情况。
Hierarchy of entities
实体的层次结构
As we discussed earlier in the chapter, we don’t use entities as an independent pattern, only as part of an aggregate. Let’s see the fundamental difference between entities and aggregates, and why entities are a building block of an aggregate rather than of the overarching domain model.
正如我们在本章前面所讨论的,我们不将实体作为一个独立的模式使用,而只是将其作为聚合的一部分。让我们看看实体和聚合之间的根本区别,以及为什么实体是聚合的构建块,而不是总体领域模型的构建块。
There are business scenarios in which multiple objects should share a transactional boundary; for example, when both can be modified simultaneously or the business rules of one object depend on the state of another object.
在一些业务场景中,多个对象应该共享一个事务边界;例如,当两个对象都可以同时修改时,或者一个对象的业务规则依赖于另一个对象的状态时。
DDD prescribes that a system’s design should be driven by its business domain. Aggregates are no exception. To support changes to multiple objects that have to be applied in one atomic transaction, the aggregate pattern resembles a hierarchy of entities, all sharing transactional consistency, as shown in Figure 6-3.
DDD(领域驱动设计)规定,系统的设计应由其业务领域驱动。聚合也不例外。为了支持需要在一个原子事务中应用的多个对象的变化,聚合模式类似于一个实体层次结构,所有实体共享事务一致性,如图6-3所示。
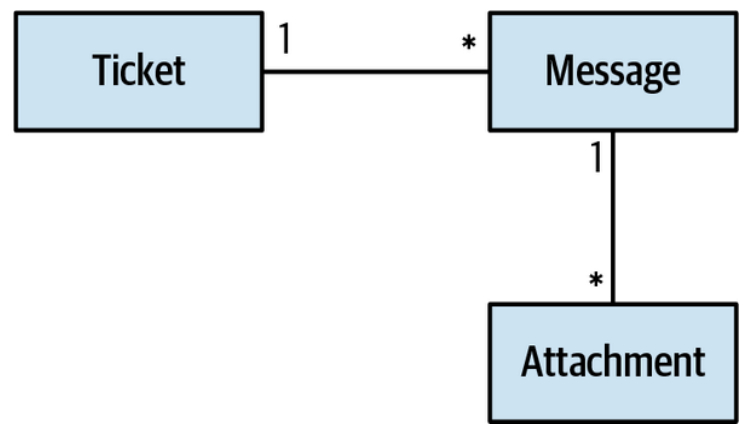
Figure 6-3. Aggregate as a hierarchy of entities
图6-3. 作为实体层次结构的聚合
The hierarchy contains both entities and value objects, and all of them belong to the same aggregate if they are bound by the domain’s business logic.
这个层次结构包含实体和值对象,如果它们受到领域业务逻辑的约束,则它们都属于同一个聚合。
That’s why the pattern is named “aggregate”: it aggregates business entities and value objects that belong to the same transaction boundary.
这就是为什么这个模式被称为“聚合”的原因:它将属于相同事务边界的业务实体和值对象聚合在一起。
The following code sample demonstrates a business rule that spans multiple entities belonging to the aggregate’s boundary—“If an agent didn’t open an escalated ticket within 50% of the response time limit, it is automatically reassigned to a different agent”:
以下代码示例演示了一个跨越聚合边界的多个实体的业务规则——“如果客服没有在响应时间限制的50% 内打开已升级工单,工单将自动重新分配给另一个客服”:
01 public class Ticket 02 { 03 ... 04 List<Message> _messages; 05 ... 06 07 public void Execute(EvaluateAutomaticActions cmd) 08 { 09 if (this.IsEscalated && this.RemainingTimePercentage < 0.5 && 10 GetUnreadMessagesCount(for: AssignedAgent) > 0) 11 { 12 _agent = AssignNewAgent(); 13 } 14 } 15 16 public int GetUnreadMessagesCount(UserId id) 17 { 18 return _messages.Where(x => x.To == id && !x.WasRead).Count(); 19 } 20 21 ... 22 }
The method checks the ticket’s values to see whether it is escalated and whether the remaining processing time is less than the defined threshold of 50% (line 9). Furthermore, it checks for messages that were not yet read by the current agent (line 10). If all conditions are met, the ticket is requested to be reassigned to a different agent.
该方法检查工单的值,以确定工单是否被升级,以及剩余的处理时间是否小于定义的阈值50%(第9行)。此外,它还检查当前客服尚未读取的消息(第10行)。如果所有条件都满足,则请求将工单重新分配给另一个客服。
The aggregate ensures that all the conditions are checked against strongly consistent data, and it won’t change after the checks are completed by ensuring that all changes to the aggregate’s data are performed as one atomic transaction.
聚合确保所有条件都是基于强一致性数据进行检查的,并且一旦检查完成,聚合的数据就不会更改,因为它确保对聚合数据的所有更改都作为一个原子事务执行。
Referencing other aggregates
引用其它聚合
Since all objects contained by an aggregate share the same transactional boundary, performance and scalability issues may arise if an aggregate grows too large.
由于聚合中包含的所有对象共享相同的事务边界,因此如果聚合变得过大,可能会出现性能和可扩展性问题。
The consistency of the data can be a convenient guiding principle for designing an aggregate’s boundaries. Only the information that is required by the aggregate’s business logic to be strongly consistent should be a part of the aggregate. All information that can be eventually consistent should reside outside of the aggregate’s boundary; for example, as a part of another aggregate, as shown in Figure 6-4.
数据的一致性可以作为一个方便、实用的原则来指导聚合边界的设计。只有聚合的业务逻辑要求具有强一致性的信息才应该是聚合的一部分。所有可以最终一致的信息都应该位于聚合边界之外;例如,作为另一个聚合的一部分,如图6-4所示。
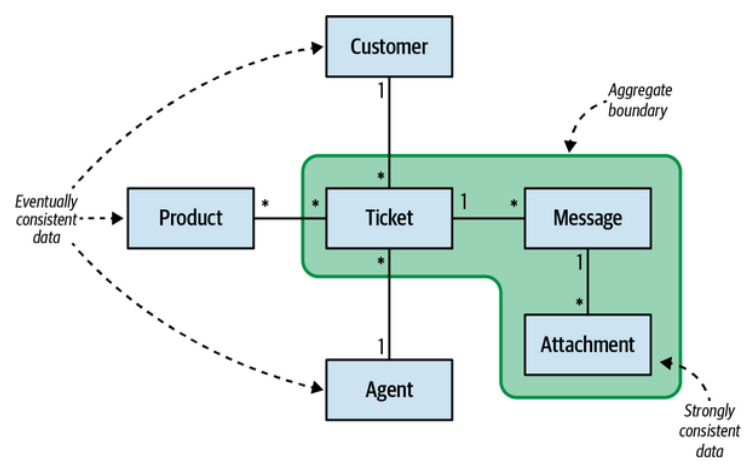
Figure 6-4. Aggregate as consistency boundary
图6-4. 聚合作为一致性边界
The rule of thumb is to keep the aggregates as small as possible and include only objects that are required to be in a strongly consistent state by the aggregate’s business logic:
经验法则是保持聚合尽可能小,并且只包括聚合的业务逻辑要求处于强一致状态的对象:
1 public class Ticket 2 { 3 private UserId _customer; 4 private List<ProductId> _products; 5 private UserId _assignedAgent; 6 private List<Message> _messages; 7 ... 8 }
In the preceding example, the Ticket aggregate references a collection of messages, which belong to the aggregate’s boundary. On the other hand, the customer, the collection of products that are relevant to the ticket, and the assigned agent do not belong to the aggregate and therefore are referenced by its ID.
在前面的示例中,Ticket 聚合引用属于聚合边界内的messages集合。另一方面,customer、与工单相关的products集合以及分配的agent 不属于工单聚合,因此它们是通过其ID被引用的。
The reasoning behind referencing external aggregates by ID is to reify that these objects do not belong to the aggregate’s boundary, and to ensure that each aggregate has its own transactional boundary.
通过ID引用外部聚合的原因是为了明确这些对象不属于聚合的边界,并确保每个聚合都有自己的事务边界。
To decide whether an entity belongs to an aggregate or not, examine whether the aggregate contains business logic that can lead to an invalid system state if it will work on eventually consistent data. Let’s go back to the previous example of reassigning the ticket if the current agent didn’t read the new messages within 50% of the response time limit. What if the information about read/unread messages would be eventually consistent? In other words, it would be reasonable to receive reading acknowledgment after a certain delay. In that case, it’s safe to expect a considerable number of tickets to be unnecessarily reassigned. That, of course, would corrupt the system’s state. Therefore, the data in the messages belongs to the aggregate’s boundary.
要决定一个实体是否属于一个聚合,需要检查聚合是否包含可能导致系统状态无效(最终一致的数据工作时出现的状态)的业务逻辑。让我们回到前面的示例,即如果当前客服没有在响应时间限制的50% 内读取新消息,则重新分配工单。如果关于已读/未读消息的信息是最终一致的会怎么样?换句话说,在一定的延迟后收到阅读确认是合理的。在这种情况下,可以预料到会有相当数量的工单被不必要地重新分配。这当然会破坏系统的状态。因此,消息中的数据属于聚合边界内。
The aggregate root
聚合根
We saw earlier that an aggregate’s state can only be modified by executing one of its commands. Since an aggregate represents a hierarchy of entities, only one of them should be designated as the aggregate’s public interface— the aggregate root, as shown in Figure 6-5.
我们之前看到,聚合的状态只能通过执行其命令之一进行修改。由于聚合代表了一个实体层次结构,因此只有其中一个应该被指定为聚合的公共接口——聚合根,如图6-5所示。
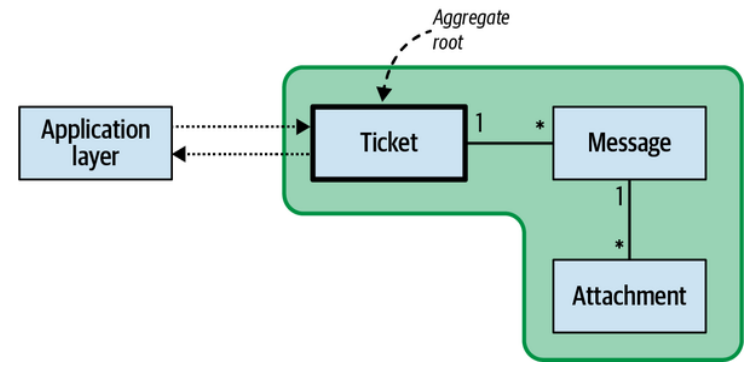
Figure 6-5. Aggregate root
图6-5. 聚合根
Consider the following excerpt of the Ticket aggregate:
思考下面的Ticket聚合的摘录:
1 public class Ticket 2 { 3 ... 4 List<Message> _messages; 5 ... 6 public void Execute(AcknowledgeMessage cmd) 7 { 8 var message = _messages.Where(x => x.Id == cmd.id).First(); 9 message.WasRead = true; 10 } 11 ... 12 }
In this example, the aggregate exposes a command that allows marking a specific message as read. Although the operation modifies an instance of the Message entity, it is accessible only through its aggregate root: Ticket.
在此示例中,聚合公开了一个允许将特定消息标记为已读的命令。尽管该操作修改了 Message 实体的实例,但是只能通过其聚合根: Ticket 来访问它。
In addition to the aggregate root’s public interface, there is another mechanism through which the outer world can communicate with aggregates: domain events.
除了聚合根的公共接口之外,还有一种机制可以让外部世界与聚合进行通信:领域事件。
Domain events
领域事件
A domain event is a message describing a significant event that has occurred in the business domain. For example:
领域事件是一个描述业务领域中发生的重大事件的消息。例如:
- Ticket assigned 工单指派
- Ticket escalated 工单升级
- Message received 消息接收
Since domain events describe something that has already happened, their names should be formulated in the past tense.
因为领域事件描述的是已经发生的事情,所以它们的名字应该用过去式来表述。
The goal of a domain event is to describe what has happened in the business domain and provide all the necessary data related to the event. For example, the following domain event communicates that the specific ticket was escalated, at what time, and for what reason:
领域事件的目标是描述业务域中发生的事情,并提供与该事件相关的所有必要数据。例如,下面的领域事件传达特定的工单在什么时间、出于什么原因被升级:
1 { 2 "ticket-id": "c9d286ff-3bca-4f57-94d4-4d4e490867d1", 3 "event-id": 146, 4 "event-type": "ticket-escalated", 5 "escalation-reason": "missed-sla", 6 "escalation-time": 1628970815 7 }
As with almost everything in software engineering, naming is important. Make sure the names of the domain events succinctly reflect exactly what has happened in the business domain.
与软件工程中的几乎所有事情一样,命名也很重要。确保领域事件的名称能够简洁明了地反映业务域中发生的事情。
Domain events are part of an aggregate’s public interface. An aggregate publishes its domain events. Other processes, aggregates, or even external systems can subscribe to and execute their own logic in response to the domain events, as shown in Figure 6-6.
领域事件是聚合的公共接口的一部分。聚合发布其领域事件。其他进程、聚合甚至外部系统可以订阅并执行自己的逻辑以响应领域事件,如图6-6所示。
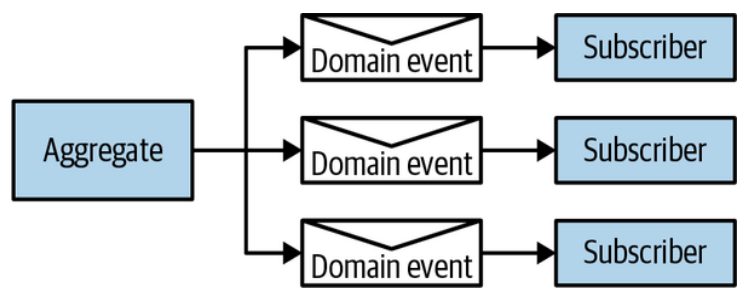
Figure 6-6. Domain events publishing flow
图6-6. 领域事件发布流程
In the following excerpt from the Ticket aggregate, a new domain event is instantiated (line 12) and appended to the collection of the ticket’s domain events (line 13):
下面是来自 Ticket 聚合的摘录,将实例化一个新的领域事件(第12行)并将其添加到工单的领域事件集合中(第13行):
01 public class Ticket 02 { 03 ... 04 private List<DomainEvent> _domainEvents; 05 ... 06 07 public void Execute(RequestEscalation cmd) 08 { 09 if (!this.IsEscalated && this.RemainingTimePercentage <= 0) 10 { 11 this.IsEscalated = true; 12 var escalatedEvent = new TicketEscalated(_id, cmd.Reason); 13 _domainEvents.Append(escalatedEvent); 14 } 15 } 16 17 ... 18 }
In Chapter 9, we will discuss how domain events can be reliably published to interested subscribers.
在第9章中,我们将讨论如何将领域事件可靠地发布给感兴趣的订阅者。
Ubiquitous language
通用语言
Last but not least, aggregates should reflect the ubiquitous language. The terminology that is used for the aggregate’s name, its data members, its actions, and its domain events all should be formulated in the bounded context’s ubiquitous language. As Eric Evans put it, the code must be based on the same language the developers use when they speak with one another and with domain experts. This is especially important for implementing complex business logic.
最后但同样重要的是,聚合应该反映通用语言。用于聚合的名称、其数据成员、其操作和其领域事件的术语都应该使用有界上下文的通用语言来表述。正如 Eric Evans 所说,代码必须基于开发人员彼此之间以及与领域专家交流时使用的相同语言。这对于实现复杂的业务逻辑尤其重要。
Now let’s take a look at the third and final building block of a domain model.
现在让我们来看一下领域模型的第三个也是最后一个构建块。
Domain services
领域服务
Sooner or later, you may encounter business logic that either doesn’t belong to any aggregate or value object, or that seems to be relevant to multiple aggregates. In such cases, domain-driven design proposes to implement the logic as a domain service.
迟早,你可能会遇到一些业务逻辑,这些逻辑要么不属于任何聚合或值对象,要么似乎与多个聚合相关。在这种情况下,领域驱动设计建议将这些逻辑实现为领域服务。
A domain service is a stateless object that implements the business logic. In the vast majority of cases, such logic orchestrates calls to various components of the system to perform some calculation or analysis.
领域服务是实现业务逻辑的无状态对象。在绝大多数情况下,这种逻辑编排对系统各个组件的调用,以执行某些计算或分析。
Let’s go back to the example of the ticket aggregate. Recall that the assigned agent has a limited time frame in which to propose a solution to the customer. The time frame depends not only on the ticket’s data (its priority and escalation status), but also on the agent’s department policy regarding the SLAs for each priority and the agent’s work schedule (shifts) —we can’t expect the agent to respond during off-hours.
让我们回到Ticket聚合的例子。回想一下,被分配的客服需要在一个有限的时间范围内向客户提出解决方案。这个时间范围不仅取决于工单的数据(其优先级和升级状态) ,还取决于客服部门针对每个优先级的SLA(服务级别协议)和客服的工作时间表(班次)——我们不能期望客服在非工作时间做出响应。
The response time frame calculation logic requires information from multiple sources: the ticket, the assigned agent’s department, and the work schedule. That makes it an ideal candidate to be implemented as a domain service:
响应时间范围的计算逻辑需要从多个来源获取信息:工单、被分配客服的部门和工作时间表。这使它成为作为领域服务实现的理想候选者:
1 public class ResponseTimeFrameCalculationService 2 { 3 ... 4 public ResponseTimeframe 5 CalculateAgentResponseDeadline(UserId agentId, 6 Priority priority, bool escalated, DateTime startTime) 7 { 8 var policy = 9 _departmentRepository.GetDepartmentPolicy(agentId); 10 var maxProcTime = policy.GetMaxResponseTimeFor(priority); 11 if (escalated) { 12 maxProcTime = maxProcTime * policy.EscalationFactor; 13 } 14 var shifts = 15 _departmentRepository.GetUpcomingShifts(agentId, 16 startTime, 17 startTime.Add(policy.MaxAgentResponseTime)); 18 19 return CalculateTargetTime(maxProcTime, shifts); 20 } 21 ... 22 }
Domain services make it easy to coordinate the work of multiple aggregates. However, it is important to always keep in mind the aggregate pattern’s limitation of modifying only one instance of an aggregate in one database transaction. Domain services are not a loophole around this limitation. The rule of one instance per transaction still holds true. Instead, domain services lend themselves to implementing calculation logic that requires reading the data of multiple aggregates.
领域服务使得多个聚合的协同工作变得容易。但是,始终要牢记聚合模式的限制,即在一次数据库事务中只能修改一个聚合实例。领域服务并不是绕开这个限制的漏洞。每次事务只操作一个实例的规则仍然适用。相反,领域服务适合于实现需要读取多个聚合数据的计算逻辑。
It is also important to point out that domain services have nothing to do with microservices, service-oriented architecture, or almost any other use of the word service in software engineering. It is just a stateless object used to host business logic.
还有一点很重要,即领域服务与微服务、面向服务的架构或软件工程中“服务”一词的几乎所有其他用法都没有关系。它只是一个用于承载业务逻辑的无状态对象。
Managing Complexity
管理复杂性
As noted in this chapter’s introduction, the aggregate and value object patterns were introduced as a means for tackling complexity in the implementation of business logic. Let’s see the reasoning behind this.
正如在本章的引言中指出的那样,聚合和值对象模式的引入,是作为解决业务逻辑实现中的复杂性的一种手段。让我们看看背后的原因。
In his book The Choice, business management guru Eliyahu M. Goldratt outlines a succinct yet powerful definition of system complexity. According to Goldratt, when discussing the complexity of a system we are interested in evaluating the difficulty of controlling and predicting the system’s behavior. These two aspects are reflected by the system’s degrees of freedom.
在《选择》(The Choice)一书中,企业管理大师Eliyahu M. Goldratt为系统复杂性给出了一个简洁而有力的定义。按照 Goldratt 的说法,当讨论系统的复杂性时,我们关注的是评估控制和预测系统行为的难度。这两个方面由系统的自由度来体现。
A system’s degrees of freedom are the data points needed to describe its state. Consider the following two classes:
系统的自由度是描述其状态所需的数据点。思考以下两个类:
1 public class ClassA 2 { 3 public int A { get; set; } 4 public int B { get; set; } 5 public int C { get; set; } 6 public int D { get; set; } 7 public int E { get; set; } 8 } 9 public class ClassB 10 { 11 private int _a, _d; 12 public int A 13 { 14 get => _a; 15 set { 16 _a = value; 17 B = value / 2; 18 C = value / 3; 19 } 20 } 21 public int B { get; private set; } 22 23 public int C { get; private set; } 24 25 public int D 26 { 27 get => _d; 28 set { 29 _d = value; 30 E = value * 2 31 } 32 } 33 public int E { get; private set; } 34 }
At first glance, it seems that ClassB is much more complex than ClassA. It has the same number of variables, but on top of that, it implements additional calculations. Is it more complex than ClassA?
乍一看,似乎ClassB比ClassA复杂得多。它拥有相同数量的变量,但除此之外,它还实现了额外的计算。它比ClassA更复杂吗?
Let’s analyze both classes from the degrees-of-freedom perspective. How many data elements do you need to describe the state of ClassA? The answer is five: its five variables. Hence, ClassA has five degrees of freedom.
让我们从自由度的角度来分析这两个类。描述 ClassA 的状态需要多少数据成员?答案是五个: 它的五个变量。因此,ClassA 有五个自由度。
How many data elements do you need to describe the state of ClassB? If you look at the assignment logic for properties A and D, you will notice that the values of B, C, and E are functions of the values of A and D. If you know what A and D are, then you can deduce the values of the rest of the variables. Therefore, ClassB has only two degrees of freedom. You need only two values to describe its state.
描述 ClassB 的状态需要多少数据成员?如果查看属性 A 和 D 的赋值逻辑,您将注意到 B、 C 和 E 的值是 A 和 D 的值的函数。如果你知道 A 和 D 是什么,那么你就可以推导出其余变量的值。因此,ClassB 只有两个自由度,只需要两个值来描述它的状态。
Going back to the original question, which class is more difficult in terms of controlling and predicting its behavior? The answer is the one with more degrees of freedom, or ClassA. The invariants introduced in ClassB reduce its complexity. That’s what both aggregate and value object patterns do: encapsulate invariants and thus reduce complexity.
回到最初的问题,哪个类在控制和预测它的行为方面更困难?答案是自由度更高的那个,即ClassA。在 ClassB 中引入的不变性降低了它的复杂性。这就是聚合模式和值对象模式所做的: 封装不变性,从而降低复杂性。
All the business logic related to the state of a value object is located in its boundaries. The same is true for aggregates. An aggregate can only be modified by its own methods. Its business logic encapsulates and protects business invariants, thus reducing the degrees of freedom.
所有与值对象状态相关的业务逻辑都位于其边界内。对于聚合来说也是如此。聚合只能通过其自身的方法来修改。其业务逻辑封装并保护了业务不变性,从而降低了自由度。
Since the domain model pattern is applied only for subdomains with complex business logic, it’s safe to assume that these are core subdomains —the heart of the software.
由于领域模型模式仅适用于具有复杂业务逻辑的子域,因此可以安全地假设这些子域是核心子域——软件的核心。
Conclusion
总结
The domain model pattern is aimed at cases of complex business logic. It consists of three main building blocks:
领域模型模式针对的是复杂的业务逻辑情况。它由三个主要构建块组成:
Value objects
值对象
Concepts of the business domain that can be identified exclusively by their values and thus do not require an explicit ID field. Since a change in one of the fields semantically creates a new value, value objects are immutable.
业务领域的概念,这些概念可以仅通过其值来唯一标识,因此不需要明确的(显式的)ID字段。由于任一字段的变化在语义上会创建一个新值,因此值对象是不可变的。
Value objects model not only data, but behavior as well: methods manipulating the values and thus initializing new value objects.
值对象不仅建模数据,还建模行为:处理值的方法,从而初始化新的值对象。
Aggregates
聚合
A hierarchy of entities sharing a transactional boundary. All of the data included in an aggregate’s boundary has to be strongly consistent to implement its business logic.
共享事务边界的实体层次结构。包含在聚合边界内的所有数据都必须具有强一致性,以实现其业务逻辑。
The state of the aggregate, and its internal objects, can only be modified through its public interface, by executing the aggregate’s commands.
聚合的状态及其内部对象只能通过其公共接口来修改,即执行聚合的命令。
The data fields are read-only for external components for the sake of ensuring that all the business logic related to the aggregate resides in its boundaries.
为了确保与聚合相关的所有业务逻辑都位于其边界内,聚合边界内的数据字段对于外部组件来说是只读的。
The aggregate acts as a transactional boundary. All of its data, including all of its internal objects, has to be committed to the database as one atomic transaction.
聚合充当事务边界。它的所有数据,包括它的所有内部对象,都必须作为一个原子事务提交到数据库。
An aggregate can communicate with external entities by publishing domain events—messages describing important business events in the aggregate’s lifecycle. Other components can subscribe to the events and use them to trigger the execution of business logic.
聚合可以通过发布领域事件(描述聚合生命周期中重要业务事件的消息)与外部实体进行通信。其他组件可以订阅这些事件,并使用它们来触发业务逻辑的执行。
Domain services
领域服务
A stateless object that hosts business logic that naturally doesn’t belong to any of the domain model’s aggregates or value objects.
一个无状态对象,承载不自然属于领域模型的任何聚合或值对象的业务逻辑。
The domain model’s building blocks tackle the complexity of the business logic by encapsulating it in the boundaries of value objects and aggregates. The inability to modify the objects’ state externally ensures that all the relevant business logic is implemented in the boundaries of aggregates and value objects and won’t be duplicated in the application layer.
领域模型的构建块通过将业务逻辑封装在值对象和聚合的边界中来解决业务逻辑的复杂性。无法从外部修改对象的状态可以确保所有相关的业务逻辑都在聚合和值对象的边界内实现,并且不会在应用层中重复。
In the next chapter, you will learn the advanced way to implement the domain model pattern, this time making the dimension of time an inherent part of the model.
在下一章中,您将学习实现领域模型模式的更高级方法,这次将时间的维度作为模型的一个固有部分。
Exercises
练习
1. Which of the following statements is true? 下列哪个陈述是正确的?
a. Value objects can only contain data. 值对象只能包含数据。
b. Value objects can only contain behavior. 值对象只能包含行为。
c. Value objects are immutable. 值对象是不可变的。
d. Value objects’ state can change. 值对象的状态可以更改。
答案:c。Also, they can contain both data and behavior. 此外,它们还可以包含数据和行为。
2. What is the general guiding principle for designing the boundary of an aggregate? 设计聚合边界的一般指导原则是什么?
a. An aggregate can contain only one entity as only one instance of an aggregate can be included in a single database transaction. 一个聚合只能包含一个实体,因为单个数据库事务中只能包含一个聚合的实例。
b. Aggregates should be designed to be as small as possible, as long as the business domain’s data consistency requirements are intact. 只要业务领域的数据一致性要求得到满足,就应该将聚合设计得尽可能小。
c. An aggregate represents a hierarchy of entities. Therefore, to maximize the consistency of the system’s data, aggregates should be designed to be as wide as possible. 聚合表示实体的层次结构。因此,为了最大限度地提高系统数据的一致性,聚合的设计应该尽可能广泛(聚合的边界尽可能地大)。
d. It depends: for some business domains small aggregates are best, while in others it’s more efficient to work with aggregates that are as large as possible.- 这取决于具体的情况:在某些业务领域,小的聚合是最好的选择,而在其他情况下,使用尽可能大的聚合则更为高效。
答案:b。
3. Why can only one instance of an aggregate be committed in one transaction? 为什么一次事务中只能提交一个聚合的实例?
a. To ensure that the model can perform under high load. 确保模型能够在高负荷下运行。
b. To ensure correct transactional boundaries. 确保正确的事务边界。
c. There is no such requirement; it depends on the business domain. 没有这样的要求; 它取决于业务领域。
d. To make it possible to work with databases that do not support multirecord transactions, such as key–value and document stores. 为了使不支持多记录事务的数据库(如键值存储和文档存储)能够工作。
答案:b。
4. Which of the following statements best describes the relationships between the building blocks of a domain model? 以下哪个陈述最能描述领域模型构建块之间的关系?
a. Value objects describe entities’ properties. 值对象描述实体的属性。
b. Value objects can emit domain events. 值对象可以发出领域事件。
c. An aggregate contains one or more entities. 聚合包含一个或多个实体。
d. A and C. A 和 C。
答案:d。
5. Which of the following statements is correct about differences between active records and aggregates? 关于活动记录和聚合之间的差异,下列哪个语句是正确的?
a. Active records contain only data, whereas aggregates also contain behavior. 活动记录只包含数据,而聚合也包含行为。
b. An aggregate encapsulates all of its business logic, but business logic manipulating an active record can be located outside of its boundary. 聚合封装了它的所有业务逻辑,但是处理活动记录的业务逻辑可以位于其边界之外。
c. Aggregates contain only data, whereas active records contain both data and behavior. 聚合只包含数据,而活动记录既包含数据又包含行为。
d. An aggregate contains a set of active records. 聚合包含一组活动记录。
答案:b。
1 Fowler, M. (2002). Patterns of Enterprise Application Architecture. Boston: Addison-Wesley. 企业应用架构模式。
2 All the code samples in this chapter will use an object-oriented programming language. However, the discussed concepts are not limited to OOP and are as relevant for the functional programming paradigm. 本章中的所有代码示例都将使用面向对象的编程语言。然而,所讨论的概念并不局限于面向对象编程(OOP),并且对函数式编程范式也同样适用。
3 POCOs in .NET, POJOs in Java, POPOs in Python, etc.
4 “Primitive Obsession.” (n.d.) Retrieved June 13, 2021, from https://wiki.c2.com/? PrimitiveObsession.
5 In C# 9.0, the new type record implements value-based equality and thus doesn’t require overriding the equality operators. 在C# 9.0中,新的record类型实现了基于值的相等性,因此不需要重写相等运算符。
6 Also known as a service layer, the part of the system that forwards public API actions to the domain model. 也称为服务层,系统中将公共 API 操作转发到领域模型的部分。
7 In essence, the application layer’s operations implement the transaction script pattern. It has to orchestrate the operation as an atomic transaction. The changes to the whole aggregate either succeed or fail, but never commit a partially updated state. 本质上,应用层的操作实现了事务脚本模式。它必须作为一个原子事务来编排操作。对整个聚合的更改要么全部成功,要么全部失败,但绝不会提交部分更新的状态。
8 Recall that the application layer is a collection of transaction scripts, and as we discussed in Chapter 5, concurrency management is essential to prevent competing updates from corrupting the system’s data. 请记住,应用层是一组事务脚本,正如我们在第5章中讨论的那样,并发管理对于防止竞争性更新破坏系统数据至关重要。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号