Django模型层(2)
多表操作
创建模型
假定有下面这些概念,字段和关系
作者模型:一个作者有姓名和年龄。
作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等信息。作者详情模型和作者模型之间是一对一的关系(one-to-one)
出版商模型:出版商有名称,所在城市以及email。
书籍模型: 书籍有书名和出版日期,一本书可能会有多个作者,一个作者也可以写多本书,所以作者和书籍的关系就是多对多的关联关系(many-to-many);一本书只应该由一个出版商出版,所以出版商和书籍是一对多关联关系(one-to-many)。
模型建立如下:
from django.db import models # Create your models here. class Author(models.Model): nid = models.AutoField(primary_key=True) name=models.CharField( max_length=32) age=models.IntegerField() # 与AuthorDetail建立一对一的关系 authorDetail=models.OneToOneField(to="AuthorDetail",on_delete=models.CASCADE) class AuthorDetail(models.Model): nid = models.AutoField(primary_key=True) birthday=models.DateField() telephone=models.BigIntegerField() addr=models.CharField( max_length=64) class Publish(models.Model): nid = models.AutoField(primary_key=True) name=models.CharField( max_length=32) city=models.CharField( max_length=32) email=models.EmailField() class Book(models.Model): nid = models.AutoField(primary_key=True) title = models.CharField( max_length=32) publishDate=models.DateField() price=models.DecimalField(max_digits=5,decimal_places=2) # 与Publish建立一对多的关系,外键字段建立在多的一方 publish=models.ForeignKey(to="Publish",to_field="nid",on_delete=models.CASCADE) # 与Author表建立多对多的关系,ManyToManyField可以建在两个模型中的任意一个,自动创建第三张表 authors=models.ManyToManyField(to='Author',)
生成表如下:
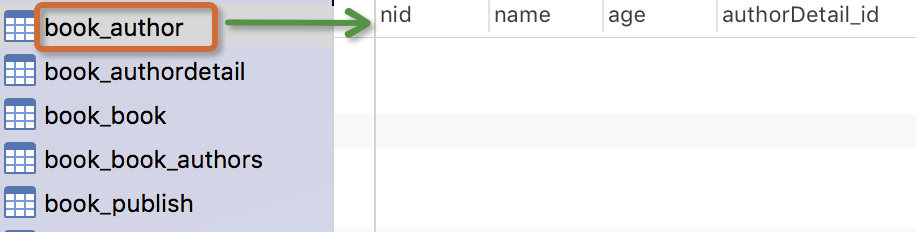

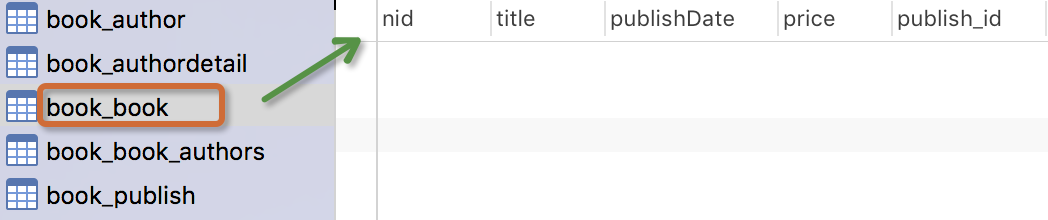
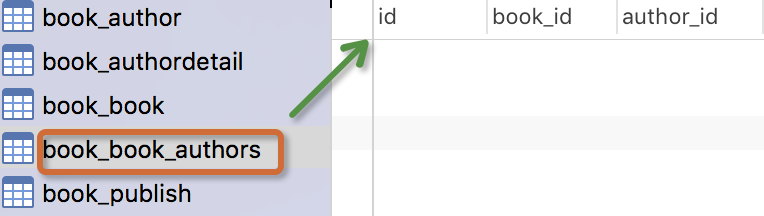
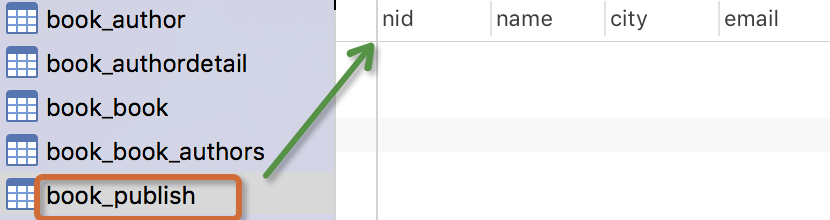
注意事项:
1 表的名称myapp_modelName是根据模型中的元数据自动生成的,也可以写为别的名称. 2 3 id字段是自动添加的 4 5 对于外键字段,Django会在字段名上添加"_id"来创建数据库中的列名 6 7 这个例子中的CREATE TABLE SQL语句使用PostgreSQL语法格式,要注意的是Django会根据settings中指定的数据库类型来使用响应的SQL语句. 8 9 定义好模型之后,需要告诉Django使用这些模型,需要做的就是修改配置文件中的INSTALL_APPS中的设置,在其中添加models.py所在应用的名称. 10 11 外键字段ForeignKey有一个null=True的设置(它允许外键接收空值),可以赋给它空值None.
添加表记录
publish表:

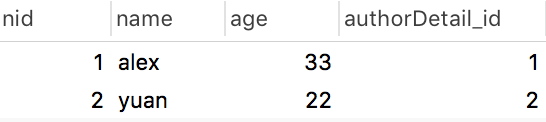
author表:
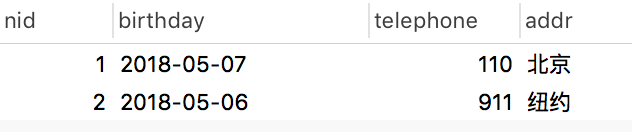
authordetail表:
一对多 方式1: publish_obj = Publish.objects.get(nid=1) book_obj = Book.objects.create(title="金平美",publishDate="2012-12-12",price=100,publish=publish_obj) 方式2: book_obj = Book.objects.create(title="金平美",publishDate="2012-12-12",price=100,publish=publish_obj) 多对多: # 当前生成的书籍对象 book_obj=Book.objects.create(title="追风筝的人",price=200,publishDate="2012-11-12",publish_id=1) # 为书籍绑定的做作者对象 yuan=Author.objects.filter(name="yuan").first() # 在Author表中主键为2的纪录 egon=Author.objects.filter(name="alex").first() # 在Author表中主键为1的纪录 # 绑定多对多关系,即向关系表book_authors中添加纪录 book_obj.authors.add(yuan,egon) # 将某些特定的 model 对象添加到被关联对象集合中。 ======= book_obj.authors.add(*[])
数据库表记录生成如下:
book表

book_authors表

多对多关系其他常用API
book_obj.authors.remove() 将某个特定的对象从被关联对象集合中去除
book_obj.authors.clear() 清空被关联对象集合
book_obj.authors.set() 先清空再设置
基于对象的跨表查询
一对多查询(Publish 与 Book)
正向查询按字段:
#查询主键为1的书籍的出版社所在的城市 book_obj = Book.objects.filter(pk=1).first() #book_obj.publish是主键为1的书籍对象关联的出版社对象 print(book_obj.publish.city)
反向查询按relate_name,如果没设置按表名小写_set(book_set)
publish = Publish.objects.get(name="苹果出版社") #publish.book_set.all() 与苹果出版社关联的所有书籍对象集合 book_list = publish.book_set.all() for book in book_list: print(book.title)
一对一查询(Author 与 AuthorDetail)
正向查询安字段:
author = Author.objects.filter(name="dasabi").first() print(author.authorDetail.telephone)
反向查询按relate_name,如果没设置按表名
author = ad.author.objects.all()
多对多查询(Author 与 Book)
正向查询按字段
1 #金平美所有作者的名字以及手机号 2 book_obj = Book.objects.filter(title="金平美").first() 3 authors = book_obj.authors.all() 4 for author in authors: 5 print(author.name,author.authorDetail.telephone)
反向查询按relate_name,如果没设置按表名_set
1 #查询dmh出版过得所有书籍的名字 2 author_obj = Author.objects.get(name="dmh") 3 book_list = author_obj.book_set.all() 4 for book in book_list: 5 print(book_obj.title)
基于双下划线的跨表查询
Django还提供了一种直观而高效的方式在查询中表示关联关系,它能自动确认SQL JOIN练习,要做跨关系查询,就使用两个下划线来链接模型间关联字段的名称,直到最终链接到想要的model为止.
一对多查询
# 练习: 查询苹果出版社出版过的所有书籍的名字与价格(一对多) # 正向查询 按字段:publish queryResult=Book.objects .filter(publish__name="苹果出版社") .values_list("title","price") # 反向查询 按表名:book queryResult=Publish.objects .filter(name="苹果出版社") .values_list("book__title","book__price")
多对多查询
# 练习: 查询dmh出过的所有书籍的名字(多对多) # 正向查询 按字段:authors: queryResult=Book.objects .filter(authors__name="dmh") .values_list("title") # 反向查询 按表名:book queryResult=Author.objects .filter(name="dmh") .values_list("book__title","book__price")
一对一查询
#查询dmh的手机号 #正向查询 book = Book.objects.filter(publish__name="人民出版社").values_list("title","authors__name") #反向查询 book = Publish.objects.filter(name="人民出版社").value_list("book__tite","book__authors__name")
聚合查询与分组查询
聚合:aggregate(*args,**kwargs)
#计算所有图书的平均价格 from django.db.models import Avg Book.objects.all().aggregate(Avg("price"))
aggregate()是QuerySet的一个终止子句,意思是说,它返回一个包含一些键值对的字典.键的名称是聚合值的标识符,
值是计算出来的聚合值,键的名称是按照字段和聚合函数的名称自动生成出来的,如果想要为聚合值指定一个名称,
可以向聚合子句提供它.
Book.objects.aggregate(avg_price=Avg("price"))
如果希望生成不止一个聚合,可以向aggregate()子句中添加另一个参数,所以,如果也想直到所有图书价格的
最大值和最小值,可以这样查询:
from django.db.models import Avg,Max,Min
Book.objects.aggregate(Avg("price"),Max("price"),Min("price"))
分组
###################################--单表分组查询--####################################################### 查询每一个部门名称以及对应的员工数 emp: id name age salary dep alex 12 2000 销售部 egon 22 3000 人事部 wen 22 5000 人事部 sql语句: select dep,Count(*) from emp group by dep; ORM: emp.objects.values("dep").annotate(c=Count("id") ###################################--多表分组查询--########################### 多表分组查询: 查询每一个部门名称以及对应的员工数 emp: id name age salary dep_id alex 12 2000 1 egon 22 3000 2 wen 22 5000 2 dep id name 销售部 人事部 emp-dep: id name age salary dep_id id name alex 12 2000 1 1 销售部 egon 22 3000 2 2 人事部 wen 22 5000 2 2 人事部 sql语句: select dep.name,Count(*) from emp left join dep on emp.dep_id=dep.id group by dep.id ORM: dep.objetcs.values("id").annotate(c=Count("emp")).values("name","c")
class Emp(models.Model): name=models.CharField(max_length=32) age=models.IntegerField() salary=models.DecimalField(max_digits=8,decimal_places=2) dep=models.CharField(max_length=32) province=models.CharField(max_length=32)
annotate()为调用的QuerySet中每一个对象都生成一个独立的统计值(统计方法用聚合函数).
总结:跨表分组查询本质就是将关联表join成一张表,再按单表的思路进行分组查询.
F查询与Q查询
F查询
如果要对两个字段的值做比较,Django提供F()来作比较.F()的实例可以在查询中引用字段,来比较同一个model实例中两个不同字段的值.
#查询评论数大于收藏数的书籍 from django.db.models import F Book.objects.filter(commentNum__lt=F("keepNum"))
Q查询
filter()等方法中的关键字参数查询都是一起进行"AND"的,如果需要执行更复杂的查询(例如OR语句),可以使用Q对象.
from django.db.models import Q Q(title__startswith="py")
Q对象可以使用 & 和 | 操作符组合起来,当一个操作符在两个Q对象上使用时,它产生一个新的Q对象.
book_list = Book.objects.filter(Q(authors__name="abc")|Q(authors__name="def"))
同时,Q对象可以使用~操作符取反,这允许组合正常的查询和取反(NOT)查询
book_list = Book.objects.filter(Q(authors__name="abc")& ~Q(publishDate__year=2017)).value_list("title")
查询函数可以混合使用Q对象和关键字参数.所提供给查询函数的参数(关键字参数或Q对象)都将"AND"在一起.但是,如果出现Q对象,它必须位于所有关键字参数的前面.例如:
book_list = Book.objects.filter(Q(publishDate__year=2016)|Q(publishDate__year=2017),title__icontains="python")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号